









文章目录
1. Dalvik 虚拟机
Dalvik 虚拟机(Dalvik Virtual Machine),简称 DVM。它并没有遵循 JVM 规范来实现,因此 DVM 并不是一个 Java 虚拟机。
1.1. 与 JVM 的区别
1.1.1. 架构区别
【JVM 基于栈】
- 以零地址指令为主,执行过程依赖于操作栈。指令数更多,指令集更小,编译器易实现。
- 设计和实现更简单,适用于资源受限的系统。
- 不需要硬件支持,可移植性好,更好实现跨平台。
【DVM 基于寄存器】
- 以多地址指令为主,执行过程依赖于寄存器。指令数更少,指令集更大,执行性能好。
- 没有大量的出入栈指令,且指令更紧凑简洁。
- 指令集架构完全依赖硬件,可移植性差,难跨平台。
【指令对比】
int x = 4; int y = 2; 计算 (x + y) * (x - y) :
// JVM 字节码指令(基于栈)
0: iload_1 // 从局部变量1号槽位读取变量x的值到操作数栈 [4
1: iload_2 // 从局部变量2号槽位读取变量y的值到操作数栈 [4,2
2: iadd // 栈顶两个元素相加并保存到操作数栈(x+y) [6
3: iload_1 // 从局部变量1号槽位读取变量x的值到操作数栈 [6,4
4: iload_2 // 从局部变量2号槽位读取变量y的值到操作数栈 [6,4,2
5: isub // 栈顶两个元素相减并保存到操作数栈(x-y) [6,2
6: imul // 栈顶两个元素相乘并保存到操作数栈 [12
// DVM 字节码指令(基于寄存器)
0000: add-int v0, v3, v4 // 将v3和v4寄存器的值相加并保存到v0寄存器(x+y)
0002: sub-int v1, v3, v4 // 将v3和v4寄存器的值相减并保存到v1寄存器(x-y)
0004: mul-int/2addr v0, v1 // 将v0和v1寄存器的值相乘并保存到v0寄存器
1.1.2. 字节码区别
- Java 类被编译成一个或多个 .class 文件。
- 每个 .class 文件里面包含了该类的常量池、类信息、属性等信息。
【JVM 执行 class 字节码】
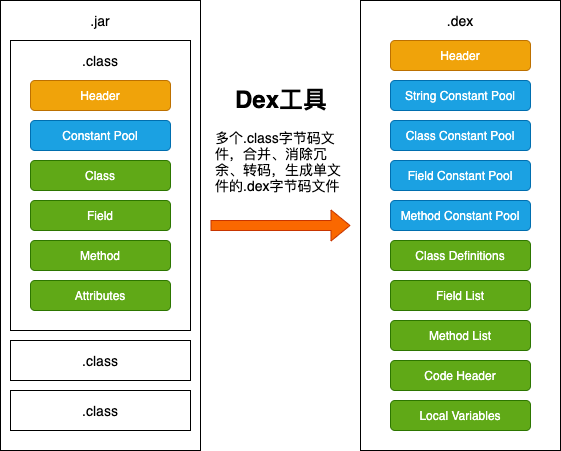
- 多个 .class 文件打包成 .jar 文件。
- 加载 .jar 文件时会加载里面的全部 .class 文件,比较慢。
- .jar 文件是一个打包压缩文件,I/O 操作频繁,类的查比较慢。
【DVM 执行 dex 字节码】
- 多个 .class 文件打包成 .dex 文件,并把包含的信息全部整合在一起,并去除冗余信息。
- 加载 .dex 文件时会加载里面的全部信息。
- .dex 文件是一个整合文件,I/O 操作少,类的查比较快。
1.1.3. 其他区别
- DVM 允许在有限的内存中同时运行多个进程。
- Android 中的每一个应用都运行在一个 DVM 实例中,拥有独立的进程空间,可以防止虚拟机崩溃时所有程序都被关闭。
- DVM 由 Zygote 创建和初始化。
- 每当系统需要创建一个应用程序时,Zygote 就会 fock 自身,快速地创建和初始化一个 DVM 实例,用于应用程序的运行。
- DVM 有共享机制。
- 不同应用之间在运行时可以共享相同的类,拥有更高的效率。
- DVM 在2.2版本以前只使用解释器,没有使用 JIT 编译器。
- 早期的 DVM 每次执行代码都需要解释器将 dex 代码编译成机器码后再处理,效率不高。
- JIT 编译器会对多次运行的代码(热点代码)进行编译,生成相当精简的本地机器码(NativeCode),下次执行到相同逻辑的时候,直接使用编译之后的本地机器码, 而不需要再编译。
1.2. DVM 运行时堆
1.2.1. COW 策略
COW(copy-on-write)即写时复制。
- 当多个调用者同时请求一个数据时,会同时获取同一个指针指向该数据。
- 当任意一个调用者想对数据内容进行修改时,会复制一份数据给该调用者,其他调用者仍然指向原来的数据。
- 如果全部调用者都只读不写数据,则数据不会被复制,永远只有一份,节省存储空间。
1.2.2. 运行时堆
Android 系统启动后,第一个进程 Zygote 会创建第一个 Dalvik 虚拟机,维护了一个 Zygote 堆。第一个应用程序进程创建(从 Zygote 进程 fork)时,会使用 COW 策略,创建 Active 堆并把 Zygote 堆中的内容复制进去。
- Zygote 堆:Zygote 进程在启动过程中预加载的类、资源和对象,可以在 Zygote 进程和应用程序进程中长期共享,节约内存。
- Active 堆:创建以后,为 Zygote 进程和应用程序进程分配内存空间,非进程共享,每个进程独立一份,减少对 Zygote 堆写,减少 COW 的发生。
- Card Table:用于 DVM Concurrtent GC,当第一次进行垃圾标记后,记录垃圾信息。
- Heap Bitmap:分为两个,Live Bitmap 用来记录上次 GC 存活的对象,Mark Bitmap 用来记录这次 GC 存活的对象。
- Mark Stack:在 GC 的标记阶段使用的,用来遍历存活的对象。
1.2.3. 垃圾回收
Zygote 堆中不会触发 GC,Active 堆使用并发标记清除(Concurrent-Mark-Sweep)算法进行 GC。
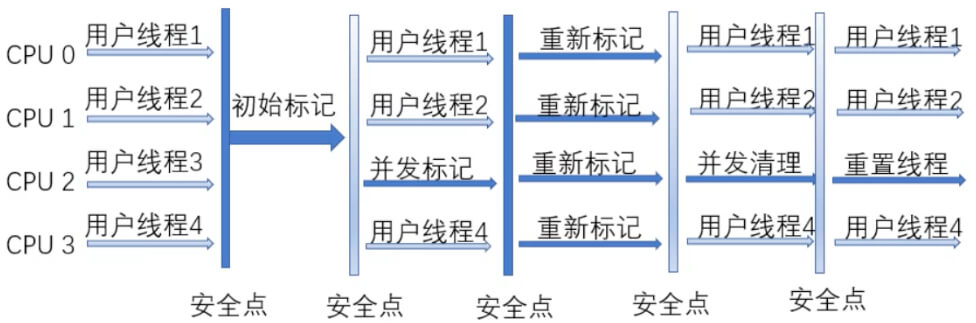
【Mark 阶段】
通过递归,从 GC Roots 开始标记被引用的对象。为了避免 Stop-The-World,采用 GC 线程和其他线程并发执行,分为两步:
- 只标记 GC Roots 对象(在 GC 过程开始的时刻,被全局变量、栈变量、寄存器对象引用的对象)。
- 这个阶段会短时间 Stop-The-World,防止这些 GC Roots 对象在此过程中再去引用其他对象。
- 通过这些 GC Roots 对象的引用关系,找到并标记其他正在使用的对象。
- 这个阶段并发执行,需要把其他线程对对象的修改记录到 Card Table(未修改为 clean,修改过为 dirty)。
- 执行结束后,需要再次使用 GC 线程对这些发生修改的对象再次标记(Stop-The-World,量少,速度快)。
【Sweep 阶段】
- GC 线程和用户线程同时并发执行,同时 GC 线程开始对为标记的区域做清扫,回收所有的垃圾对象。
- 清除 Live Bitmap 中有,Mark Bitmap 中没有的对象,即为垃圾对象。
【缺点】
- 对 CPU 资源敏感:在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说 CPU 资源)而导致应用程序变慢,总吞吐量会降低。
- 无法处理浮动垃圾:在并发清除时,用户线程新产生的垃圾,称为浮动垃圾。
1.3. GC 日志
在 DVM 中每次垃圾收集都会将 GC 日志打印到 logcat 中,具体格式为:
<GC_Reason> <Amount_freed>, <Heap_stats>, <External_memory_stats>, <Pause_time>
1.3.1. GC 原因
GC_Reason 指的是引起 GC 的原因,有以下几种。
GC_CONCURRENT:当堆开始填充时,并发 GC 可以释放内存。GC_FOR_MALLOC:当堆内存已满时, App尝试分配内存而引起的 GC,系统必须停止 App 并回收内存。GC_HPROF_DUMP_HEAP:当你请求创建 HPROF 文件来分析堆内存时出现的 GC。GC_EXPLICIT:显式的 GC,例如调用System.gc()(应该避免调用显式的 GC,信任 GC 会在需要时运行)。GC_EXTERNAL_ALLOC:仅适用于 API 级别小于等于 10,且用于外部分配内存的 GC。
1.3.2. 其他字段
Amount_freed:本次 GC 释放内存的大小。
Heap_stats:堆的空闲内存百分比(已用内存 / 堆总内存)。
External_memory_stats:API 小于等于级别 10 的内存分配(已分配的内存 / 引起 GC 的阈值)。
Pause_time:暂停时间,堆越大暂停时间越长。并发暂停时间会显示两个,一个是垃圾收集开始时, 另一个是垃圾收集快要完成时。
1.3.3. 日志示例
D/dalvikvm: GC_CONCURRENT freed 2012K, 63% free 3213K/9291K, external 4501K/5161K, paused 2ms+2ms
本次 GC 原因是 GC_CONCURRENT;释放内存 2012KB;堆空闲内存占比 63%,已用3213KB,总内存为 9291KB;暂停总时长 4ms。
2. ART 虚拟机
ART(Android Runtime)虚拟机于 Android 4.4 发布,Android 5.0 中默认使用,用来代替 Dalvik 虚拟机。
2.1. 与 DVM 的区别
2.1.1. 运行机制区别
【DVM 基于 JIT 运行】
运行程序时使用解释器执行,同时将热点代码通过 JIT 编译器编译成机器码,并缓存到 jit code cache ,再执行时就无需解释直接运行。
【ART 基于 AOT 运行】
- **Android 7.0 以前:**安装 APK 时把全部字节码进行 AOT 编译成机器码
.oat文件,并存储到磁盘,程序运行时不需要编译直接使用。 - **Android 7.0 开始:**安装 APK 时不进行全量编译,运行程序时使用解释器执行。
- 将热点代码进行 JIT 编译成机器码,并缓存到
jit code cache,再执行时就无需解释直接运行。 - 把经过 JIT 编译的热点方法记录到 Profile 配置文件中。
- 当设备闲置和充电时,会启动编译守护进程,根据 Profile 文件把热点方法进行 AOT 编译成机器码
.oat文件,并存储到磁盘待下次运行时直接使用。
- 将热点代码进行 JIT 编译成机器码,并缓存到
2.1.2. CPU 区别
- DVM 只支持 32位 CPU。
- ART 支持 64位 CPU 并兼容 32位 CPU。
2.2. 解释器、JIT 和 AOT
Java 为了实现“一次编写,随处运行”,将 java 代码编译成与本地平台无关的字节码文件,让字节码文件在不同平台、不同系统的不同虚拟机上运行,从而实现跨平台。而虚拟机运行字节码文件有多种不同方式:解释器、JIT 和 AOT。
2.2.1. 简介
- **【解释器】:**解释器一次编译一行字节码并运行,实现成本低,性能低。
- **【 JIT 】:**即时编译(Just-in-time)
- 一次编译一个方法然后缓存到
jit code cache,再次执行相同方法时就无需解释器编译,而直接运行,性能一般。 - JIT 只会对经常执行的字节码(循环、高频方法)进行编译,以减少编译器负担。
- 程序运行结束后,已编译并缓存的机器码将会被清除,下次运行会再次编译。
- 一次编译一个方法然后缓存到
- **【 AOT 】:**提前编译(Ahead-of-time)
- 将全部字节码一次性编译成本地机器码,生成
.oat文件并存储到磁盘空间,程序运行时不需要编译直接使用,性能好。 - 由于会对全部字节码进行编译,因此安装 APK 时速度慢、安装之后占用的空间较大。
- 将全部字节码一次性编译成本地机器码,生成
⭐️ **注意:**尽管 JIT 和 AOT 使用相同的编译器,且进行的一系列优化也较相似,但它们生成的代码可能会有所不同。JIT 会利用运行时类型信息,可以更高效地进行内联,并可让堆栈替换 (OSR) 编译成为可能,而这一切都会使其生成的代码略有不同。
2.2.2. 三者的配合
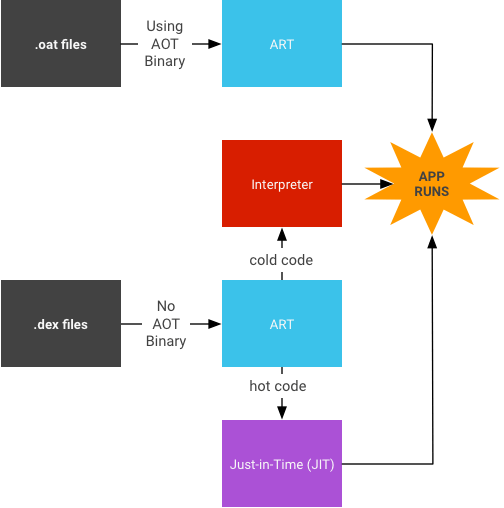
- 已编译完成的机器码
.oat文件,ART 虚拟机直接运行。 - 未编译的字节码
.dex文件,ART 虚拟机先判断是否热点代码:- 非热点代码:使用解释器解释运行。
- 热点代码:使用 JIT 编译运行。
2.2.3. method 的编译运行
在 ART 中 ,执行一个方法前,可以在 ArtMethod 结构体中判断改方法是否已经被编译过了,从而使用不同的策略来执行方法。
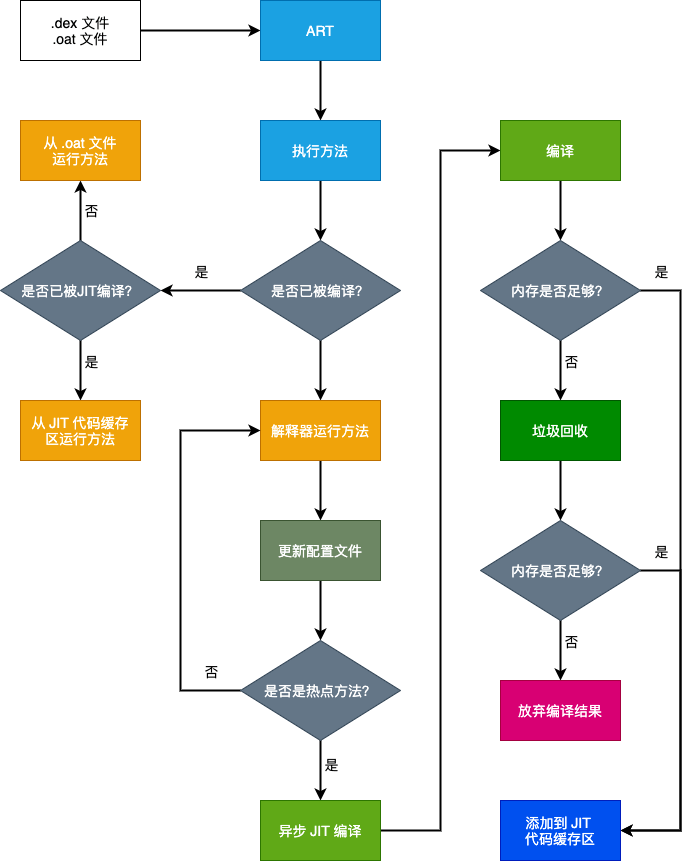
当设备空闲且在充电时,AOT 编译守护程序(dex2oat)将解析 JIT 配置文件来编译热点方法。
- 唤醒并分析全部 APK。
- 判断该 app 是否被其他 app 所依赖使用:如果是,则全量编译该 apk 中的字节码,生成
.oat文件。 - 否则判断对应的配置文件数据是否有意义:如果是,则根据配置文件中的描述,编译部分字节码,生成
.oat文件。
2.3. 垃圾回收
不同版本,垃圾回收器不同,运行时堆也不同。而 ART 同时包含多种方案,OEM 厂商可以更改 GC 类型。
2.3.1. Android 8 之前
默认采用并发标记清除(CMS)方案。
支持内存压缩,但是有条件,进行的次数不多,可能会产生内存碎片。
- 应用进入后台之前,它会避免执行压缩。
- 应用进入后台之后,它会暂停应用线程以执行压缩(Stop-The-World)。
- 如果对象分配因内存碎片而失败,则必须执行压缩操作,应用可能会短时间无响应。
2.3.2. Android 8 开始
默认采用并发复制(CC)方案。
- 支持使用名为“RegionTLAB”的触碰指针分配器。此分配器可以向每个应用线程分配一个线程本地分配缓冲区 (TLAB),这样,应用线程只需触碰“栈顶”指针,而无需任何同步操作,即可从其 TLAB 中将对象分配出去。
- 依靠读取屏障拦截来自堆的引用读取,并发复制对象来执行堆碎片整理,从而不用暂停用户线程。
- GC 只有一次很短的暂停,对于堆大小而言,该次暂停在时间上是一个常量。
2.3.3. Android 10 开始
默认采用并发复制(CC)方案,但是增加了分代处理。
- 支持快速回收存留期较短的对象,提高 GC 吞吐量,并降低全堆 GC 的执行。
2.4. GC 日志
ART 会在主动请求 GC 时或认为 GC 速度慢(暂停超过5ms或者持续超过100ms,且暂停可以被察觉)时才会打印 GC 日志,具体格式为:
<GC_Reason> <GC_Name> <Objects_freed>(<Size>) AllocSpace Objects, <Large_objects_freed>(<size>) <Heap_stats> LOS objects , <Pause_time> <Total_time>
2.4.1. GC 原因
GC_Reason 指的是引起 GC 的原因,有以下几种。
Concurrent:并发 GC,不会使 App 的线程暂停,该 GC 在后台线程运行,不会阻止内存分配。Alloc:当堆内存已满时,App 尝试分配内存引起的 GC,这个 GC 会发生在正在分配内存的线程中。Explicit:App显式的请求垃圾回收,例如调用System.gc()。NativeAlloc:Native 内存分配时,触发的 GC。CollectorTransition:由堆转换引起的回收,运行时切换 GC 引起的。将所有对象从空闲列表空间复制到碰撞指针空间,反之亦然。仅出现在内存较小的设备上App将进程从可察觉的暂停状态更改为可察觉的非暂停状态。HomogeneousSpaceCompact:齐性空间压缩是指空闲列表到压缩的空闲列表空间,通常发生在App移动到可察觉的暂停进程状态。以此来减小内存使用并对堆内存进行碎片整理。DisableMovingGc:不是真正触发 GC 的原因。发生并发堆压缩时,由于使用了GetPrimitiveArrayCritical,收集会被阻塞。HeapTrim:不是触发 GC 的原因。收集会一直被阻塞,直到堆内存整理完毕。
2.4.2. 垃圾收集器名称
GC_Name 指的是垃圾收集器名称,有以下几种。
Concurrent Mark Sweep:CMS 收集器,采用标记清除算法实现,收集暂停时间短。完整的堆垃圾收集器,能释放除了 Image Space 外的所有空间。Concurrent Partial Mark Sweep:局部收集器,能释放除了 Image Space 和 Zygote Space 外的所有空间。Concurrent Sticky Mark Sweep:粘性收集器,基于分代的垃圾收集思想,只能释放自上次 GC 以来分配的对象。比完整或局部垃圾收集器扫描更频繁、更快且暂停时间更短。Marksweep + Semispace:非并发的 GC,复制 GC 用于堆转换以及碎片整理。
2.4.3. 其他字段
Objects_freed:从非 Large Object Space 中回收的对象的数量。Size_freed:从非 Large Object Space 中回收的字节数。Large_objects_freed:从 Large O同ect Space 中回收的对象的数量。Large_object_size_freed:从 Large Object Space 中回收的字节数。Heap_stats:堆的空闲内存百分比,即(已用内存 / 堆的总内存)。Pause_times:暂停时间,暂停时间与在 GC 运行时修改的对象引用的数量成比例。目前, ART 的 CMS 收集器仅有一次暂停,它出现在 GC 的结尾附近。移动的垃圾收集器暂停时间会很长,会在大部分垃圾回收期间持续出现 。















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









