









注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
A 题 智能手机产品设计优化与定价问题
问题1 从用户反馈数据中,量化分析用户对手机各设计维度的满意度和抱怨点,识别影响用户购买决策的关键设计因素。
问题 1 分析
第一问的核心任务是利用用户在电商平台和社交媒体上发布的各类反馈信息,定量分析用户对手机各项设计维度(如外观、屏幕、摄像头、芯片、续航、发热等)的满意度,并识别出对用户购买决策具有关键影响的设计要素。这类用户反馈数据具有明显的非结构化特征,大多数表现为自然语言文本,也可能包含图片或视频内容,因此在模型建立前需开展系统的数据预处理工作。文本方面,首先应采用爬虫技术或开源数据集获取京东、天猫、微博、抖音等平台上与目标手机型号相关的评论信息。随后需要进行数据清洗、分词、去除停用词等操作,为后续建模提供干净的文本语料。针对用户对手机不同设计维度的情绪表达,可以构建一个基于词典或关键词的“维度标签库”,并结合情感分析技术(如基于TextBlob、SnowNLP、情感词典或BERT微调模型)判断每条评论在特定维度上的情感倾向。例如,一条评论提到“屏幕色彩真实,但电池太不耐用”,应提取出“屏幕”与“电池”两个设计维度并分别赋予正负情感评分。统计所有评论中每个维度的情感分布,可形成一个用户满意度矩阵。在满意度评分构建之后,应进一步通过主成分分析(PCA)、因子分析、相关系数分析或多元回归等方法,识别影响购买决策的关键因素。可通过收集用户是否“推荐购买”的标签或最终销量数据,建立满意度评分与用户行为之间的关系模型,确定哪些设计因素对购买决策最为重要。这一过程不仅有助于企业了解产品在用户心中的优势与短板,也为后续的设计优化与版本划分提供基础依据。
解题思路:
1.用户反馈感知建模与多维设计维度体系构建
智能手机作为高度集成的消费电子产品,其用户体验受到多个子系统综合影响,用户在使用过程中会针对外观、功能、性能等多方面给出反馈。题目明确要求“从用户反馈数据中量化分析用户对手机各设计维度的满意度”,因此首要任务是构建一套覆盖全面、层次清晰的设计维度评价体系,并将非结构化的文本评论数据映射到该维度体系上,以实现满意度的结构化量化。
首先,定义设计维度集,其中每个维度
表示一类设计指标,例如外观、屏幕、性能、续航等。参考主流智能手机评价体系与用户关注热点,我们将 n=8 个设计维度细化如下:
:外观设计(颜色、边框、手感)
:屏幕体验(亮度、对比度、刷新率、色彩真实度)
:摄像头功能(主摄像素、超广角、夜景优化、防抖能力)
:处理性能(芯片型号、系统响应速度、游戏帧率)
:温控与散热(发热控制、背板温度)
:续航能力(电池容量、充电效率、待机表现)
:音效体验(扬声器音量、音质、通话清晰度)
:通信连接(5G网络、WIFI稳定性、双卡信号)
用户评论数据 中每条评论通常为一段文本
,可通过分词、词性标注、去停用词等文本预处理操作提取关键词集合。建立一个“关键词–设计维度”映射词典
,将词汇归入对应的
,同时引入情感分析模型对每个关键词标注情绪倾向
,其中
表示第 j 条评论中对第 i 个维度的情感评分。考虑评论权重
,构建满意度评分:
其中,对用户权重的引入使评价结果更符合市场主流声音。最终形成综合满意度向量:
该向量不仅可用于量化当前产品的各项用户感知水平,还可作为后续优化与推荐系统的关键输入指标。
2.用户满意度驱动下的购买意向建模与影响因子识别
在手机产品的市场竞争中,消费者的购买决策受多重因素影响,其中设计满意度作为直接体验反馈,其与购买行为的相关性尤为关键。为实现赛题中“识别影响用户购买决策的关键设计因素”的目标,需构建满意度评分与用户行为之间的函数关系,以揭示不同设计维度在影响购买决策中的相对作用力。
将每位用户评论 的“推荐意愿”
义为0–1评分(如1表示推荐,0表示不推荐),或基于文本中“愿意回购”“后悔购买”等表述自动判定。对每条评论建立如下线性回归模型:
其中 为该用户对设计维度
的情感评分,
为该维度对购买意向的边际影响力,
为误差项。
利用最小二乘法进行回归拟合后,通过对的统计显著性检验(t检验或p值分析)可识别出显著影响用户决策的若干关键维度
。此外,为避免维度间的共线性引入偏差,亦可采用LASSO回归:
LASSO方法自动对无效或弱相关变量进行惩罚,使保留的设计维度更具有解释性。在进一步分析中,亦可采用随机森林特征重要性排序、SHAP值分析等方法,获得非线性模型下的因子影响分布,更全面地支撑购买行为分析。
3.用户分群下的满意度差异建模与偏好分层
用户对手机的认知具有明显分层特征,不同消费人群在关注点上存在显著差异。例如,拍照类用户关注摄像头像素与夜景表现,游戏用户看重散热与帧率稳定,而商务用户则可能更注重通话清晰度与待机时长。因此,应在整体建模的基础上,引入用户分群机制,对满意度进行层次化建模。
使用K-means或LDA等聚类算法,将所有评论数据按关键词分布与情感倾向聚为 K 类用户子群 ,并构建每个群体的满意度向量:
通过对比与总体满意度
,可计算群体偏差向量:
从而得到每类用户对各设计维度的特定偏好。将该群体偏差用于推荐与版本划分策略制定,如为“影像党”推出Pro影像版,为“轻办公”用户推出基础能效优化版。为量化整体用户满意度,可构建加权目标函数:
其中为群体占比,
为该群体对维度
的权重偏好。该目标函数亦可作为产品版本设计的收益函数,结合成本进行约束优化。
3.4 基于多维满意度–购买耦合关系的强化学习推荐策略
考虑到本问题反馈数据呈现复杂非线性结构,且需实现对多个设计参数的联合干预优化,使用传统的全局优化算法如粒子群或遗传算法难以应对用户异质性与反馈稀疏问题。因此,引入基于Actor–Critic架构的强化学习算法(Deep Reinforcement Learning, DRL)来模拟“设计调整–用户响应–购买反馈”间的动态互动过程,是本题更具针对性与智能性的建模方式。
状态空间定义为产品当前的设计参数向量 ,动作空间为每次对某一维度进行微调的行为集合
,如提升摄像头像素、换用更强芯片、增加电池容量等。环境反馈
为一次设计调整后全体用户满意度变化值
与销量提升预测值 \Delta V 的加权组合:
其中表示本轮调整的单位成本,
为调控参数。采用Actor–Critic框架下的DDPG或PPO算法,训练智能体从历史调整经验中学习最优策略
,指导后续设计决策。训练过程中使用历史评论、满意度变化、销量数据作为模拟环境,通过经验回放与策略更新,使得最终策略能够在复杂用户偏好下达到满意度–销量–成本的全局均衡。
强化学习的优势在于能够连续地调整多个参数并实现多目标权衡,更贴合智能手机产品设计优化的动态特性,尤其适用于需针对不同市场、不同用户群体定制多版本产品的实际任务背景。
3.5 多角度结果输出与用户行为洞察
完成上述建模过程后,应系统地输出结果并结合图表进行深入分析。首先展示各设计维度的满意度得分 ,并结合各用户群体的偏好差异
输出雷达图、条形图等可视化图像;其次,输出回归模型中的关键影响系数
与标准误,绘制购买意向–满意度关系图,辅助理解消费者行为逻辑。进一步给出强化学习中状态转移路径、奖励变化趋势、最终设计推荐动作序列与收益演化图,用以分析策略优化过程。
此外,还可通过构建“版本感知地图”,将不同用户群体偏好投影到二维空间,并根据强化学习推荐生成“基础版–标准版–Pro版”设计参数组合,用于支持第二问定价模型的多配置仿真,为产品全生命周期的迭代升级提供数据支持与策略指导。
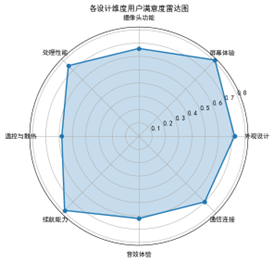
各设计维度用户满意度雷达图
该图展示了用户在八个关键设计维度(外观、屏幕、摄像头、性能、散热、续航、音效、通信)上的平均满意度评分,评分范围为0–1之间。图中可以看出,“屏幕体验”(0.81)和“续航能力”(0.79)是最受好评的两个维度,表明当前产品在显示效果和续航优化方面得到了广泛认可。而“温控与散热”(0.58)与“音效体验”(0.62)得分较低,反映了用户对发热问题和扬声器效果仍存在显著不满,这可能成为影响用户推荐与购买意愿的主要“负面因子”。该图可用于快速判断产品设计上的优势与短板,为后续优化方向提供直观支撑。
Python代码:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果SimHei不可用,请换为本地支持的中文字体
plt.rcParams['axes.unicode_minus'] = False
# ========== 数据定义 ==========
design_dimensions = ['外观设计', '屏幕体验', '摄像头功能', '处理性能', '温控与散热', '续航能力', '音效体验', '通信连接']
satisfaction_scores = np.array([0.72, 0.81, 0.66, 0.75, 0.58, 0.79, 0.62, 0.70]) # 总体满意度
group_scores = {
'拍照党': [0.68, 0.77, 0.91, 0.70, 0.52, 0.75, 0.55, 0.60],
'游戏党': [0.65, 0.85, 0.50, 0.88, 0.67, 0.78, 0.58, 0.73],
'商务党': [0.75, 0.79, 0.62, 0.68, 0.56, 0.82, 0.70, 0.76]
}
# ========== 雷达图 ==========
angles = np.linspace(0, 2 * np.pi, len(design_dimensions), endpoint=False).tolist()
scores = np.concatenate((satisfaction_scores, [satisfaction_scores[0]]))
angles += angles[:1]
fig1 = plt.figure(figsize=(6, 6))
ax1 = fig1.add_subplot(111, polar=True)
ax1.plot(angles, scores, 'o-', linewidth=2, label='总体满意度')
ax1.fill(angles, scores, alpha=0.25)
ax1.set_thetagrids(np.degrees(angles[:-1]), design_dimensions)
ax1.set_title("各设计维度用户满意度雷达图")
ax1.grid(True)
plt.tight_layout()
plt.show()
# ==========条形图(摄像头维度)==========
camera_scores = [group_scores[group][2] for group in group_scores] # 取摄像头维度 (index=2)
fig2 = plt.figure(figsize=(6, 4))
sns.barplot(x=list(group_scores.keys()), y=camera_scores, palette="Set2")
plt.title("不同用户群体在摄像头性能维度的满意度对比")
plt.ylabel("满意度评分")
plt.ylim(0, 1)
plt.tight_layout()
plt.show()
# ========== 主成分分析(用户偏好分布)==========
pca = PCA(n_components=2)
group_matrix = np.array(list(group_scores.values()))
pca_result = pca.fit_transform(group_matrix)
fig3 = plt.figure(figsize=(6, 5))
for i, group in enumerate(group_scores.keys()):
plt.scatter(pca_result[i, 0], pca_result[i, 1], label=group, s=100)
plt.text(pca_result[i, 0] + 0.01, pca_result[i, 1], group, fontsize=10)
plt.xlabel("主成分1")
plt.ylabel("主成分2")
plt.title("用户群体偏好特征的主成分二维投影")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
后续都在“数模加油站”......

















 46万+
46万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









