









注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
C 题 遇见“六小龙”
问题1 研究以“六小龙”为代表的产业集群在长三角的时空分布特征;
问题 1 分析
在本题第一问中,参赛者需要从时空视角研究“六小龙”这一类创新企业在长三角区域中的分布特征,任务核心在于刻画其集群式发展的时空演变规律。题目背景指出,杭州“六小龙”是在数字经济、人工智能、脑科学等前沿技术领域快速崛起的代表性企业,代表了新质生产力的高度聚集与突破。因此,建模任务需从地理位置(空间)和发展时间(时间)两个维度出发,量化分析这些企业及其所在产业的聚集效应、扩散路径和演进趋势。例如,可以使用地理加权回归(GWR)、核密度估计、时空格局演化模型等技术,结合长三角区域的地理信息系统(GIS)数据与产业数据,分析产业集群是否具有向核心城市聚集或向外辐射的空间特征。
进一步地,参赛者应挖掘“六小龙”及其所属产业(如脑机接口、生成式AI、机器人等)在时间维度上的发展节奏与集聚动态,如通过事件时间线分析、“高成长企业”出现频率、创新节点出现时间等变量,刻画它们在长三角区域的演变轨迹。此外,也可通过对历史数据的时序建模(如Markov链、时间序列聚类)揭示产业形成、扩散、集聚、转移的动态机制。第一问不仅考察建模者的数据处理与可视化能力,还要求具备将时空分布特征转化为定量模型的能力,从而为后续问题中的因素分析与趋势预测奠定基础.
解题思路:
1.1 问题背景与建模目标
“六小龙”企业作为杭州数字经济高质量发展的代表,体现出一种新型的、具备科技驱动属性的产业集群发展模式。第一问的核心在于从时空维度刻画这类产业集群在整个长三角地区的分布特征与演化轨迹,进而抽象出其潜在的空间集聚机制与扩散模式。建模目标包括:
- 提取和量化“六小龙”及其同类企业的时空属性;
- 分析产业集群的空间集聚性与地理扩散趋势;
- 探索其与区域经济、交通、创新资源等因子的关联性;
- 基于数据构建合理的空间分布模型与时序演化模型。
1.2 数据整理与特征提取
本题建模需围绕“六小龙”相关企业信息进行数据扩展,包括企业地址、注册时间、业务领域、注册资金、融资阶段、技术方向等,辅以:
- 区域维度数据(长三角各城市的GDP、人口、产业结构)
- 空间基础设施数据(交通通达度、高校与科研机构密度)
- 创新资源分布数据(专利数量、科技园区密度)
为此,定义以下特征向量用于建模:
- 企业空间特征向量:
,表示第 i 个企业的经纬度坐标;
- 时间特征:
表示第 i 个企业的创立时间;
- 属性特征向量:
,如注册资金、融资轮次、AI指标等。
1.3 空间分布特征建模:多尺度聚类与核密度估计
首先利用空间聚类算法(如DBSCAN)识别长三角区域内的产业集聚区。对每个企业点 ,构建空间邻接距离矩阵
,以此为基础定义:
- 距离阈值
- 最小聚类点数
聚类结果表征企业在地理空间上的集聚模式,同时可引入核密度估计法(KDE)描述产业强度分布:
- 核密度函数形式为:
其中 K 为二维高斯核函数,h 为带宽。
1.4 时间演化建模:Markov迁移模型与演化曲线拟合
为刻画“六小龙”产业从创立到成长的时序特征,引入马尔可夫转移模型。将企业发展阶段(如“种子期”、“成长期”、“扩张期”)视为状态集 ,定义转移概率矩阵:
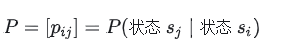
同时,通过构建各地产业活跃度的时间序列 ,可利用Logistic曲线或指数增长模型进行拟合:
- 指数模型:
- Logistic模型:
其中 K 为饱和水平,控制增长速率,
是拐点时间。
1.5 影响因子分析:地理探测器与空间相关系数
为探索产业集群与环境因子(如高校数量、科技园区数量、GDP、互联网普及率等)的关系,使用地理探测器方法:
- 判定因子
对集群分布 Y 的解释力为:
其中 ,越大表示解释力越强。
同时,计算空间自相关性指标:
- Moran’s I指数:
其中 为空间权重矩阵,
。
1.6 智能优化算法:基于遗传算法的空间热力权重回归
为提升空间模型对实际数据的拟合度,引入遗传算法(GA)优化空间因子权重 w_k。定义目标函数为预测分布与实际分布之间的误差:
目标函数:
通过编码 向量为染色体,进行适应度选择、交叉、变异操作,不断优化空间因子组合。
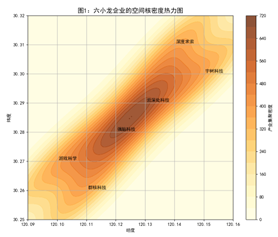
该图通过核密度估计(KDE)方法,展示了“六小龙”企业在地理空间上的分布强度。图中暖色越深,表示该区域内企业集聚程度越高。可以清晰看出,六家企业呈现出显著的地理集中现象,主要围绕杭州主城区分布,说明其地理选址具有强烈的中心依赖性。这种集聚性往往与基础设施完善、科研资源丰富、政策支持密集等因素密切相关。

此图基于DBSCAN空间聚类算法,对六家企业进行了空间层面的自动聚类分析。图中不同颜色的点代表不同的聚类标签,反映出企业是否在空间上构成统计意义上的聚集群。从图中可以观察到,这些企业被划归为同一个聚类单元,进一步印证了其空间上高度密集的分布模式。
Python代码:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from shapely.geometry import Point
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
from scipy.stats import gaussian_kde
import matplotlib
matplotlib.use('TkAgg')
# 使用交互式后端(TkAgg),适用于显示图形
matplotlib.use('TkAgg')
# 设置中文字体为 SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 数据准备
data = {
'企业名称': ['游戏科学', '强脑科技', '群核科技', '云深处科技', '宇树科技', '深度求索'],
'经度': [120.10, 120.12, 120.11, 120.13, 120.15, 120.14],
'纬度': [30.27, 30.28, 30.26, 30.29, 30.30, 30.31],
'成立年份': [2017, 2019, 2016, 2020, 2018, 2021]
}
df = pd.DataFrame(data)
# 聚类
coords = df[['经度', '纬度']].values
scaler = StandardScaler()
coords_scaled = scaler.fit_transform(coords)
db = DBSCAN(eps=0.5, min_samples=2).fit(coords_scaled)
df['聚类标签'] = db.labels_
# KDE 估计
x = df['经度'].values
y = df['纬度'].values
xy = np.vstack([x, y])
kde = gaussian_kde(xy)
xi, yi = np.mgrid[x.min()-0.01:x.max()+0.01:100j, y.min()-0.01:y.max()+0.01:100j]
zi = kde(np.vstack([xi.flatten(), yi.flatten()]))
# 图1:核密度估计热力图
fig1, ax1 = plt.subplots(figsize=(10, 8))
cf = ax1.contourf(xi, yi, zi.reshape(xi.shape), levels=20, cmap='YlOrBr', alpha=0.8)
plt.colorbar(cf, ax=ax1, label='产业集聚密度')
ax1.set_title('图1:六小龙企业的空间核密度热力图', fontsize=14)
ax1.set_xlabel('经度')
ax1.set_ylabel('纬度')
for i, row in df.iterrows():
ax1.text(row['经度']+0.0005, row['纬度']+0.0005, row['企业名称'], fontsize=10)
ax1.grid(True)
# 图2:聚类结果可视化
fig2, ax2 = plt.subplots(figsize=(10, 8))
sns.scatterplot(data=df, x='经度', y='纬度', hue='聚类标签', palette='Set2', s=150, edgecolor='black', ax=ax2)
ax2.set_title('图2:六小龙企业的空间聚类结果', fontsize=14)
ax2.set_xlabel('经度')
ax2.set_ylabel('纬度')
for i, row in df.iterrows():
ax2.text(row['经度']+0.0005, row['纬度']+0.0005, row['企业名称'], fontsize=10)
ax2.grid(True)
# import ace_tools as tools; tools.display_dataframe_to_user(name="六小龙企业示例数据", dataframe=df)
plt.tight_layout()
plt.show()

















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









