






注:该内容由“数模加油站”原创,无偿分享,可以领取参考但不要利用该内容倒卖,谢谢!
B 题道路路面维护需求综合预测
道路路面维护需求综合预测 道路路面维护需求综合预测 道路维护是保障交通系统安全、高效运行的关键任务,也是城市基础设施管理中的重要环、 节。随着现代交通网络规模的持续扩大和车辆保有量的快速增长,道路养护需求与有限的人力 物力、财力资源之间的矛盾日益凸显。传统的道路维护决策通常依赖人工经验或单一指标(如 路面破损程度),缺乏对多源数据的综合分析,容易导致资源浪费或维护滞后。例如,部分路 段因过度维护造成资金浪费,而另一些高隐患路段却因未及时检测而引发交通事故;同时,不 同区域的道路特征(如交通流量、气候条件、材料类型)差异较大,单一维护标准难以适应复 杂场景。因此,如何基于多维度数据(如路面状况指数、交通荷载、气候环境、历史维护记录 等)构建科学预测模型,并结合预测结果优化资源分配策略,成为交通管理部门亟待解决的核 心问题。 本赛题提供某地区真实道路检查数据集,包含路段ID、路面状况指数(PCI)、道路类型、 年平均日交通量、沥青类型、上次大修年份、平均降雨量、车辙深度、国际粗糙度指数(IRI) 等多维度信息,以及目标标签(是否需要维护)。参赛队伍需通过数学建模与数据分析技术, 设计高效、精准的预测模型和资源分配方案,为道路维护决策提供科学依据。
问题1 路面维护需求预测回归分析问题
为实现对道路是否需要维护的科学判断,我们将该问题抽象为一个二分类监督学习建模任务,目标是利用提供的道路结构、使用与环境等特征变量,构建判别模型,对给定路段的维护状态进行预测。具体地,我们以样本数据集中给出的9个特征变量作为输入,以“是否需要维护”(Needs Maintenance,取值为0或1)作为输出标签,通过数学建模过程构建分类函数 \hat{y} = f(x),实现对未知样本的预测判别。
问题1思路框架:
首先,设训练集共有 n 个样本,每个样本含 d 个特征变量,记为:
对应的标签为:
目标是构建一个分类器 f_\theta(x),使得其在输入特征 x 下输出预测类别:
我们从逻辑回归与树模型两个方向建立数学模型,并结合模型输出概率与性能指标进行评估与优化。
数学模型构建:
1. 特征变量处理
由于数据中既包含连续变量(如PCI、AADT、IRI等),又包含类别变量(如道路类型、沥青类型),为提高模型适应性,需进行如下处理:
对类别变量采用独热编码(One-Hot Encoding),设原始分类变量 C 含 k 类,转换为 k 维向量 (0, 0, ..., 1, ..., 0);
对时间变量(上次维护年份)转换为“服役年限”:![]()
\text{Age} = \text{当前年份} - \text{Last Maintenance};
对数值变量进行标准化处理:
其中为样本均值,
为标准差。
2. 逻辑回归模型(可解释性强)
逻辑回归是一种广泛使用的广义线性模型,适用于二分类问题。其模型形式为:
其中,为特征权重,b 为偏置项,
为Sigmoid函数。
损失函数采用对数似然函数(交叉熵):
最优参数通过梯度下降法求解:
该模型可输出每个特征的权重,解释各变量对维护判断的正负影响。
3. 梯度提升树模型(如 XGBoost)
为提升模型预测精度,引入非线性模型 XGBoost。该方法以加性方式集成多个回归树,构造强分类器:
其中,\mathcal{F} 为回归树空间,f_k(x) 表示第 k 棵树的输出。模型通过迭代优化目标函数获得最优结构与叶节点值。
目标函数:
正则项控制模型复杂度,定义为:
其中 T 为树的叶节点数,为第 j 个叶节点的输出值。
每轮迭代引入一棵新树,最小化当前损失的二阶泰勒展开:
其中 g_i = \partial_{\hat{y}^{(t-1)}} l(y_i, \hat{y}_i) 为一阶导,h_i 为二阶导数。
最终模型输出为:
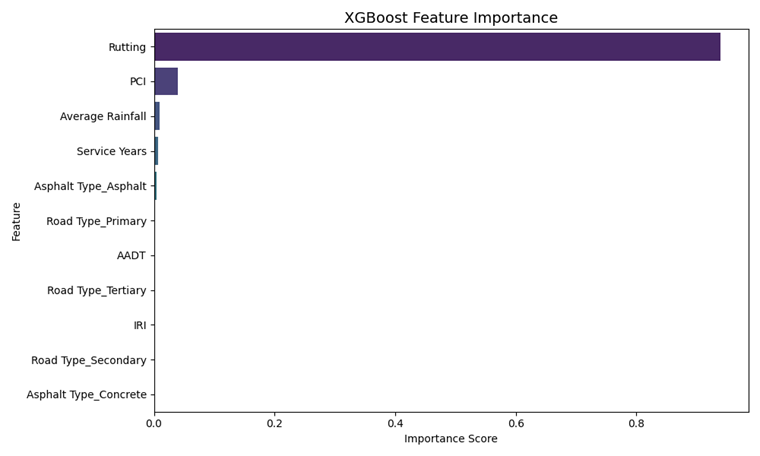
XGBoost 能有效捕捉变量之间的非线性关系与交叉作用,且具备特征重要性输出机制,便于后续解释。
模型算法求解:
模型训练
我们将数据划分为训练集与验证集,采用交叉验证方式调参,提升模型泛化能力。
性能评估指标
分类模型性能以以下指标评估:
准确率(Accuracy):
召回率(Recall):
F1分数(F1-score):
其中:
TP:正确预测为需要维护的数量;
FP:错误预测为需要维护的数量;
FN:漏判未识别出需要维护的数量。
模型目标是在尽可能高的准确率基础上提升对“需要维护”类别的召回率,从而降低漏判风险。
Python代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score, f1_score, classification_report
import os
# 创建保存图片的目录
os.makedirs("figures", exist_ok=True)
# 1. 加载数据
df = pd.read_csv("数据挖掘:train_data.csv")
# 2. 构造新特征:服役年限 = 2025 - Last Maintenance
df["Service Years"] = 2025 - df["Last Maintenance"]
# 3. 定义特征与标签
features = ['PCI', 'Road Type', 'AADT', 'Asphalt Type',
'Average Rainfall', 'Rutting', 'IRI', 'Service Years']
target = 'Needs Maintenance'
X = df[features]
y = df[target]
# 4. 特征预处理
numerical_features = ['PCI', 'AADT', 'Average Rainfall', 'Rutting', 'IRI', 'Service Years']
categorical_features = ['Road Type', 'Asphalt Type']
preprocessor = ColumnTransformer(transformers=[
('num', StandardScaler(), numerical_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
# 5. 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 6. 构建XGBoost模型管道
xgb_clf = xgb.XGBClassifier(
objective='binary:logistic',
eval_metric='logloss',
use_label_encoder=False,
random_state=42
)
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', xgb_clf)
])
# 7. 模型训练
pipeline.fit(X_train, y_train)
# 8. 模型预测与评估
y_pred = pipeline.predict(X_test)
acc = accuracy_score(y_test, y_pred)
rec = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
# 打印并保存分类报告
report = classification_report(y_test, y_pred, output_dict=True)
report_df = pd.DataFrame(report).transpose()
report_df.to_csv("figures/classification_report.csv")
# 9. 提取特征重要性(XGBoost 内部计算)
model = pipeline.named_steps['classifier']
ohe = pipeline.named_steps['preprocessor'].named_transformers_['cat']
encoded_cat_features = list(ohe.get_feature_names_out(categorical_features))
all_feature_names = numerical_features + encoded_cat_features
importance_df = pd.DataFrame({
'Feature': all_feature_names,
'Importance': model.feature_importances_
}).sort_values(by='Importance', ascending=False)
importance_df.to_csv("figures/xgboost_feature_importance.csv", index=False)
# 10. 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x="Importance", y="Feature", data=importance_df, palette="viridis")
plt.title("XGBoost Feature Importance", fontsize=14)
plt.xlabel("Importance Score")
plt.ylabel("Feature")
plt.tight_layout()
plt.savefig("figures/xgboost_feature_importance.png")
plt.close()
# 11. 保存模型评估指标文本
with open("figures/metrics_summary.txt", "w") as f:
f.write(f"Accuracy: {acc:.4f}\n")
f.write(f"Recall: {rec:.4f}\n")
f.write(f"F1-score: {f1:.4f}\n")
print("模型训练与分析完成,结果保存在 figures/ 目录中。")
后续都在“数模加油站”......


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









