






再熟悉KMP算法之前需要先了解KMP算法出现的原因
简单字符串匹配算法
从主串s中pos位置开始查找子串p的过程称为字符串模式匹配,被查找的子串p也称为模式串。模式匹配最常见的应用就是在文本文件中进行内容查找,如Word文档中快捷键ctrl+F的查找功能。
模式匹配中最简单的做法是从主串s的pos位置开始进行逐趟匹配,每趟匹配都与模式串p依次比较各个字符,发生失配时,本趟匹配失败,从主串的下一个位置和模式串的第一个位置开始下一次匹配。
复杂度计算:假设主串的长度为n,模式串的长度为m。
在简单字符串匹配算法中,完后一趟匹配至少要进行1次比较,最多进行m次比较。
简单字符串匹配算法最多进行n-m+1趟匹配,因此最坏情况下一共进行m(n-m+1)次比较,时间复杂度为O(m*n)。最坏的情况发生在每一趟匹配都在最后一个字符发生失配。
简单字符串匹配算法的效率不高,原因是存在不必要的回溯:
①每趟匹配,游标i都会回溯到字符串新的位置s_start开始匹配,这个s_start相比于上一趟只前进了一个位置
②游标j一定会回溯到模式串的位置0开始匹配
由此发现,当一趟失败匹配后,可以根据模式串匹配失败的位置,以及模式串本身可提取的信息,快速计算出下一趟匹配游标i和j的开始位置。
#include<stdio.h>
#include<string.h>
#include<stdbool.h>
#define MaxSize 256
typedef struct string
{
char str[MaxSize];
int length,mxaLength
}string;
int Index(string s,string p,int pos)
{
int s_start, p_start = 0, s_fail, p_fail;
for (s_start=pos;s_start<=s.length-p.length;s_start++)
{
if (Match(s, p, s_start, p_start, &s_fail, &p_fail))
{
return s_start;
}
}
return -1;
}
bool Match(string s,string p,int s_start,int p_start,int* s_fail,int* p_fail)
{
int i = s_start, j = p_start;
for (;j<p.length;i++,j++)
{
if (s.str[i]!=p.str[j])
{
*s_fail = i;//s_fail记录主串失配位置
*p_fail = j;//p_fail记录模式串失配位置
return false;
}
}
return true;
}KMP算法
在认识KMP算法之前同样需要了解一些必备的名词概念
前缀子串:给定一个长度为n的字符串,它的前缀子串是s的一个子串,至少包含主串中的第一个字符,长度不超过n-1。长度为1的字符串没有前缀子串。以字符串“ABCDA”为例,前缀子串包括A,AB,ABC,ABCD
后缀子串:给定一个长度为n的字符串,它的后缀子串是s的一个子串,至少包含主串中的最后一个字符,长度不能超过n-1。长度为1的字符串没有后缀子串。以字符串“ABCDA”为例,后缀子串包括A,DA,CDA,BCDA
相等的前缀与后缀子串:给定一个长度为n的字符串,如果存在k,使得前k个元素构成的前缀子串,与后k个元素构成的后缀子串相等,则前k个元素与后k个元素称为相等的前缀与后缀子串。以字符串“ABCDA”为例,前缀子串A与后缀子串A相等,长度为1。以字符串“ababa”为例,前缀子串a与后缀子串a;前缀子串aba与后缀子串aba,长度分别为1和3。
最长相等的前缀与后缀子串:给定一个长度为n的字符串,其所有相等的前缀与后缀子串中长度最长的那对子串。以字符串“ABCDA”为例,前缀子串A与后缀子串A相等,长度为1,最长相等的前缀与后缀子串为1。以字符串“ababa”为例,前缀子串a与后缀子串a;前缀子串aba与后缀子串aba,长度分别为1和3。最长相等的前缀和后缀子串为3。
设定一个主串p为“ABCDAB ABCDABCDABDE”,模式串q为“ABCDABD”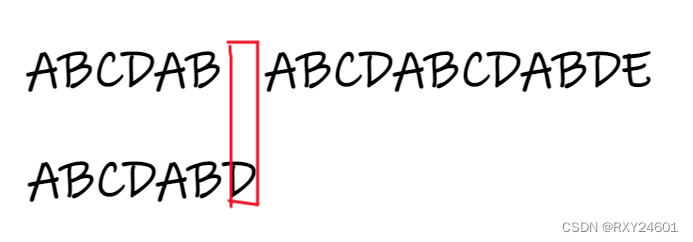
如图所示,对于主串来说,主串与模式串唯一的不同就在于p[6]与q[6]不相同。通过看图我们可以知道,主串p的前缀子串“ABCDAB”与模式串q的前缀子串“ABCDAB”相同,所以认为pq有最长相等前缀子串,且最长相等的前缀子串长度为6。同时主串与模式串相等的前缀与后缀子串都为“AB”。
也就是说下一次比较无需从主串的p[1] 元素也就是B开始进行,模式串的q[0]必定与主串p[0]--p[3]都不相同。由此可知下一次应该从主串p[4]开始匹配。
又因为6-2=4,所以我们可以通过这个推广到普遍情况。
代码实现:
void Fail(string p,int* fail)
{
int j = 0, k = -1;
fail[0] = -1;
while (j<p.length)
{
if (k==-1||p.str[j]==p.str[k])
{
j++;
k++;
fail[j] = k;
}
else
{
k = fail[k];
}
}
}这个Fail函数的目的是为了计算出在那个位置主串与模式串开始出现差异,这里的fail与上图中的next相同
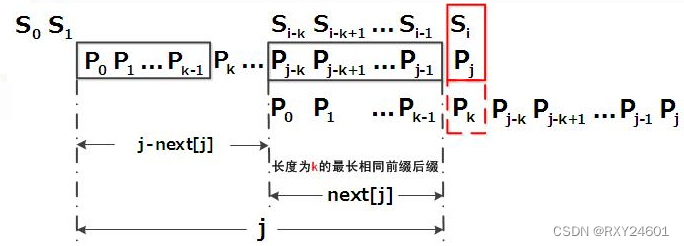
综上,KMP的next 数组相当于告诉我们:当模式串中的某个字符跟文本串中的某个字符匹配失配时,模式串下一步应该跳到哪个位置。如模式串中在j 处的字符跟文本串在i 处的字符匹配失配时,下一步用next [j] 处的字符继续跟文本串i 处的字符匹配,相当于模式串向右移动 j - next[j] 位。
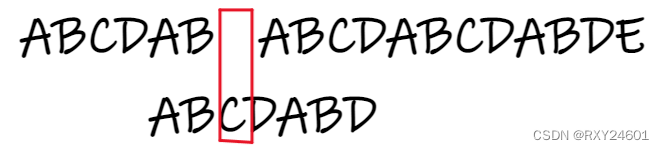
所以下一次模式串将直接从p[4]开始进行匹配
代码实现:
int KPMIndex(string s,string p,int pos,int* fail)
{
int s_start = 0, p_start = 0, s_fail, p_fail;
while (s_start<=s.length-p.length)//主串与模式串对比的元素数不能少于模式串
{
if (Match(s,p,s_start,p_start,&s_fail,&p_fail))//如果遍历无误,返回
{
return s_start - p_start;
}
else//匹配失败,通过失败函数计算下一趟主串与模式串开始匹配位置
{
p_start = fail[p_fail];//模式串从匹配失败的位置开始下一次匹配
s_start = s_fail;//主串从匹配失败的位置开始匹配
if (p_start==-1)
{
p_start = 0;
s_start++;
}
}
}
return -1;
}
复杂度:
















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









