







目录
一、模型介绍
生产者消费者模型是一种经典的并发编程模型,它描述的是一个共享资源池的问题。在这个模型中,生产者负责生产数据并将数据放入队列中,消费者线程则负责从队列中取出数据并消费。这个队列通常被设计成是线程安全的,以保证生产者和消费者能够同时操作它而不会出现数据错乱的问题。
生产者消费者模型是一种非常重要的并发编程模型,它可以广泛应用于各种场景中,比如生产者线程生产数据,消费者线程处理数据,可以用于异步消息处理、多线程数据处理等。
在Java中,主要可以使用以下两种方式实现生产者消费者模型:
1.使用等待/通知机制:通过使用Java的Object的wait()和notify()或notifyAll()等方法来实现线程的等待和通知操作。
2.使用阻塞队列:通过使用Java中的阻塞队列来实现生产者和消费者之间的数据交换和同步。
无论使用哪种方式,生产者和消费者都需要加锁来保证线程安全,避免出现竞争和不一致的情况。同时,也需要注意避免死锁和饥饿等问题的发生。
二、模型特点
生产者消费者模型有以下特点:
1. 生产者和消费者都是独立的线程,它们之间不存在直接的调用关系。
2. 生产者和消费者之间共享缓冲区。
3. 生产者线程在缓冲区未满时可以继续生产数据,否则需要等待。
4. 消费者线程在缓冲区不为空时可以继续消费数据,否则需要等待。
5. 生产者和消费者之间需要进行同步,避免出现数据竞争或者缓冲区溢出的问题。
三、实现原理
生产者消费者模型是基于共享缓冲区和线程同步机制这两大手段共同实现的。
1. 共享缓冲区:生产者线程将生产的数据放入共享缓冲区中,消费者线程从共享缓冲区中取出数据并进行处理。共享缓冲区可以是线程安全的队列,比如ConcurrentLinkedQueue、ArrayBlockingQueue等,也可以自己实现一个线程安全的队列。
2. 线程同步机制:为了避免生产者线程向已经满了的缓冲区中不断插入数据,或者消费者线程从空缓冲区中不断取出数据,需要使用线程同步机制来控制生产者和消费者线程的行为。常用的线程同步机制包括:
- wait()/notify():使用wait()/notify()方法实现线程同步,当共享队列为空时,消费者线程调用wait()方法阻塞自己,当有新数据加入时,生产者线程调用notify()方法唤醒消费者线程。
- Lock/Condition:使用Lock/Condition实现线程同步,与wait()/notify()方法不同的是,Condition对象可以创建多个,一个Lock对象可以对应多个Condition对象。生产者和消费者线程共同对应一个Lock对象,当共享队列为空时,消费者线程调用Condition对象的await()方法阻塞自己,当有新数据加入时,生产者线程调用Condition对象的signal()方法唤醒一个消费者线程。
- Semaphore:Semaphore是一种计数信号量,可用于控制同时访问共享资源的线程数。当一个线程访问共享资源时,它需要获取一个许可证,如果许可证不可用,则线程将被阻塞。Semaphore可以用来实现生产者消费者模型,当共享队列为空时,消费者线程获取不到许可证,会被阻塞,当有新数据加入时,生产者线程释放一个许可证,唤醒一个消费者线程。
除了以上三种线程同步机制以外,还有很多方法都可以用于实现生产者消费者模型,具体使用哪种,可以根据实际情况选择。
四、代码实现
本文将使用wait()/notify()方法来实现生产者消费者模型(笔者知道这是最简单的,没办法,谁让这个省事呢,别骂了别骂了QAQ)
4.1先创建一个Storage类实现缓冲区
/**
* 对应生产者消费者模型中的缓冲区
*
* @date: 2023/8/4
*/
public class Storage {
private int mMaxCount=20;
private int mCount=0;
/**
* @description 生产商品,同步方法,注意synchronized关键字
* @time 2023/8/4 14:25
*/
public synchronized void produce(){
// 判断缓冲区里数据是否达到最大值
// 达到最大值则需要发出提示并令当前线程wait
while(mCount==mMaxCount){
// 线程wait操作注意捕获InterruptedException
try {
System.out.println("库存已经满了,停止生产");
this.wait();
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
}
// 生产产品,产品数量加1
mCount++;
System.out.println("生产线程"+Thread.currentThread().getName()+"生产了一件产品" +
",当前库存数量:"+mCount);
// 唤醒其它处于wait的线程
// 要注意notify方法执行后不会立即释放对象锁,而是在当前synchronized代码块
// 执行完毕之后才释放(虽然该方法中notify后面没有语句了)
this.notifyAll();
}
/**
* @description 消耗商品,同步方法,注意synchronized关键字
* take方法基本可以说就是produce相反的实现,看懂produce这个就很好理解
* @time 2023/8/4 14:32
*/
public synchronized void take(){
// 判断当前数据是否为0
// 为0则需要发出提示并令当前线程wait
while (mCount==0){
try {
System.out.println("库存为0,停止消耗");
this.wait();
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
}
mCount--;
System.out.println("消耗线程"+Thread.currentThread().getName()+"消耗了一件产品" +
",当前库存数量:"+mCount);
this.notifyAll();
}
}4.2再创建生产者和消费者类
/**
* 生产者类
* @date: 2023/8/4
*/
public class Producer implements Runnable{
private Storage mStorage;
public Producer(Storage storage) {
mStorage = storage;
}
@Override
public void run() {
while(true){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
// 调用Storage类里的produce方法实现生产产品功能
mStorage.produce();
}
}
}
/**
* 消费者类
* @date: 2023/8/4
*/
public class Consumer implements Runnable{
private Storage mStorage;
public Consumer(Storage storage) {
mStorage = storage;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(700);
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
// 调用Storage类里的take方法实现消耗产品功能
mStorage.take();
}
}
}4.3在主函数中开始执行
public class MySynTest {
public static void main(String[] args) {
Storage mStorage=new Storage();
Producer mProducer=new Producer(mStorage);
Consumer mConsumer=new Consumer(mStorage);
// 分别新建三个生产者线程和消费者线程
Thread producer1=new Thread(mProducer,"Producer1");
Thread producer2=new Thread(mProducer,"Producer2");
Thread producer3=new Thread(mProducer,"Producer3");
Thread consumer1=new Thread(mConsumer,"Consumer1");
Thread consumer2=new Thread(mConsumer,"Consumer2");
Thread consumer3=new Thread(mConsumer,"Consumer3");
producer1.start();
producer2.start();
producer3.start();
consumer1.start();
consumer2.start();
consumer3.start();
}
}4.4代码执行结果
截取了部分运行结果如下所示:
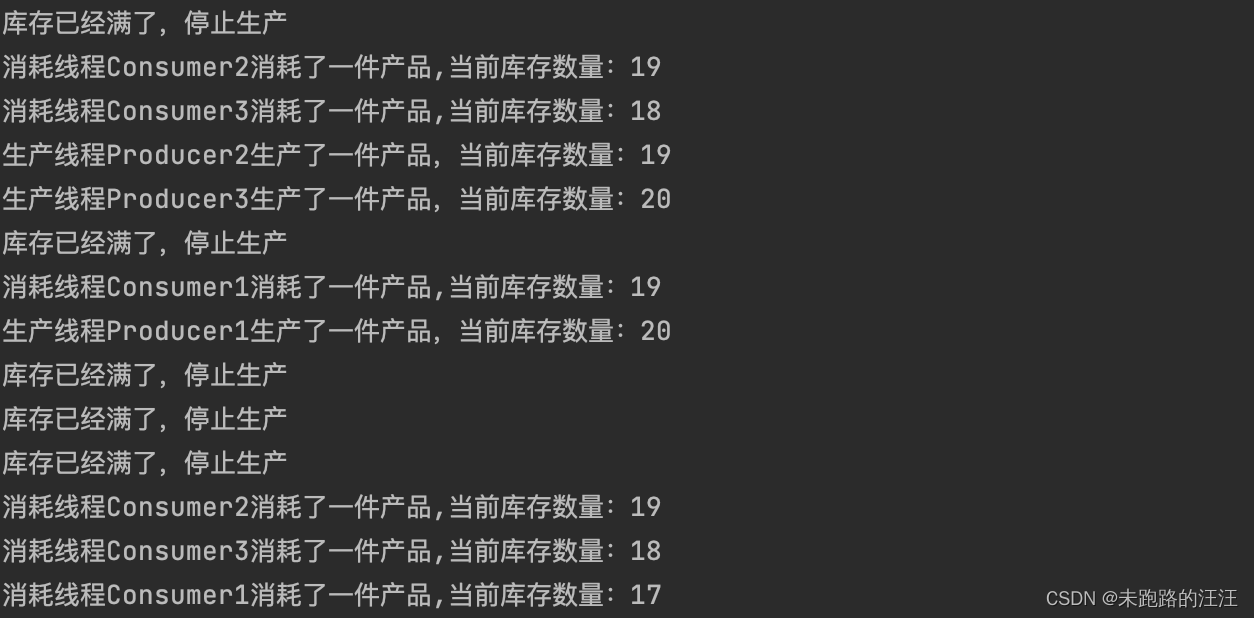
可以看出,代码成功实现了生产者消费者模型,并没有出现数据竞争和缓冲区数据溢出的现象。
五、要点解析
5.1用while而不是if
关于produce方法和take方法中,判断缓冲区数据是否溢出或为0时,为什么要用while而不是常用的条件判断语句if,网络上有很多解答,笔者在这里只谈谈自己的一点浅显的理解,有不当之处还望包涵。
// 关键代码在这
while(mCount==mMaxCount){
// 线程wait操作注意捕获InterruptedException
try {
System.out.println("库存已经满了,停止生产");
this.wait();
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
}理解这个问题之前,首先要明确,当线程执行了wait方法,然后被其它线程通过notify唤醒后,是会继续执行wait方法后面的语句的;知道这个前提后我们再来分析此处为何要用while而不是if
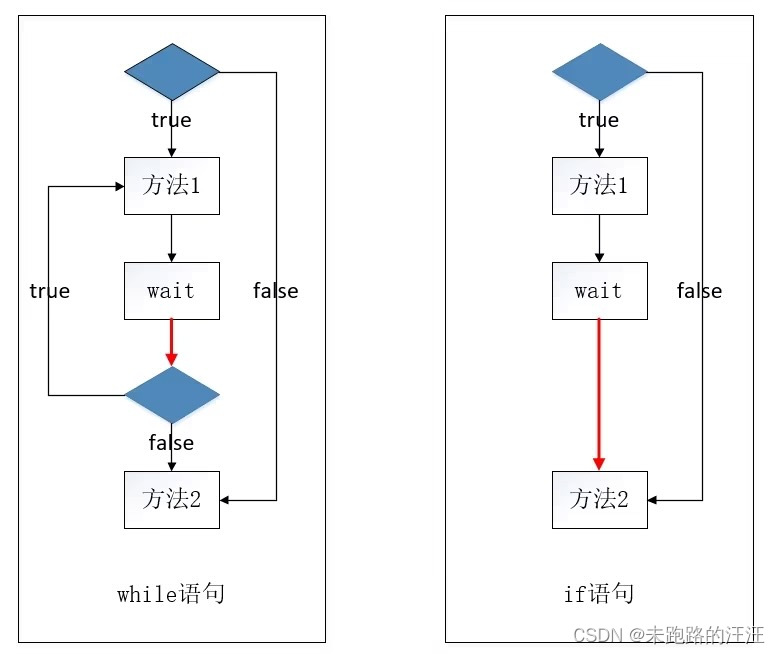
从上图中可以看出,使用while时,wait方法执行后还需要再次判断一下while中的条件,而使用if时,wait方法执行完成后直接进入了后面的mCount++语句。
在当前线程处于等待状态期间,若有其它生产线程进行了mCount++操作导致产品数量恰好达到了最大值,使用while的线程会再次判断该条件并停止生产,而使用if的线程则由于没有再次判断该条件会继续生产产品,导致缓冲区数据溢出。这也就是为什么此处需要使用while而不是if作为条件pan
5.2关于sleep的说明
wait方法和sleep方法的区别网络上有很多介绍的,大致意思是:sleep方会令当前线程休眠,释放CPU资源但并不释放锁,此时其他线程无法访问该对象;而wait方法则会令当前线程进入阻塞状态并释放锁,此时其它处于就绪状态线程会竞争该锁。
但是上面的前提在于sleep方法要写在synchronized代码块里面才有上述作用,写在synchronized代码块外面的时候,sleep就和锁没什么关系了,单纯只是让当前线程休眠指定时间,其他线程此时可以访问当前对象。
比如这里producer和comsumer类里面的Thread.sleep就只是让线程休眠一段时间,用来模拟生产(或消耗)产品所需的时间,并不涉及到对锁的控制。
while(true){
try {
Thread.sleep(500);
} catch (InterruptedException e) {
System.out.println(e.getMessage());
throw new RuntimeException(e);
}
// 调用Storage类里的produce方法实现生产产品功能
mStorage.produce();
}六、后记
本文实现java生产者消费者模型的方式比较简单,用到了最基础的wait和notify方法,其它更加复杂一些的实现方式笔者也还在学习中,读者可以先自行探索。
笔者萌新一枚,如有错漏之处还望多多包涵。
本文参考文章如下:















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









