







Part1 - REPL的简介和设置
思考目录中的问题——简而言之就是数据库是如何工作的。为了搞清楚这些问题,我正在从头开始编写一个数据库,它模仿了sqlite,因此它更小而且功能更少。整个数据库被存储在一个文件中(便于理解)。
sqlite
sqlite的网站上有很多文档,这里我给出一个sqlite的设计与实现的架构图。
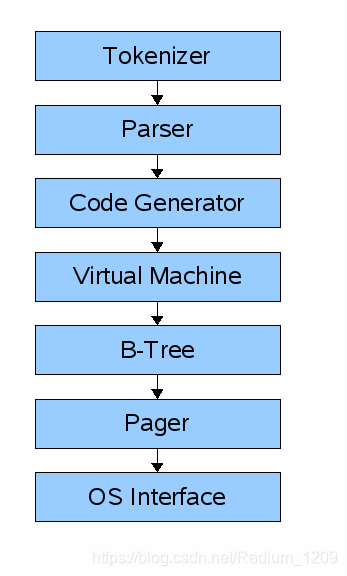
一个查询(query)通过一系列的组件来实现检索或修改数据。
前端(front-end) 组成:
- 分词器(tokenizer)
- 语法分析器(parser)
- 代码生成器(code generator)
前端的输入是一个SQL查询,输出是sqlite虚拟机字节码(实际上是一个可以对数据库进行操作的的已编译程序)
后端(back-end) 组成:
- 虚拟机(virtual machine)
- B树(B-tree)
- 寻呼机(pager)
- 操作系统接口(os interface)
虚拟机 以前端生成的字节码作为指令。然后它可以对一个或多个表索引执行操作,每个表或索引都存储在称为B树的数据结构中。虚拟机本质上是一个关于字节码指令类型的大型switch语句。
每个 B树 由许多节点组成,每个节点的长度为一页。B树可以从磁盘检索页面,也可以通过向寻呼机发出命令将其保存回磁盘。
寻呼机 接受命令以读取或写入数据页。它负责以适当的偏移量在数据库文件中进行读取/写入。它还在内存中保留了最近访问页面的缓存,并确定何时需要将这些页面写回到磁盘。
操作系统接口 是根据不同的操作系统对sqlite进行不同的编译的层。本教程中,将不支持多平台。
让我们从更直接的东西开始:REPL。
实现一个简单的REPL
从命令行启动时,sqlite将会启动一个“读取-执行-打印”的循环(这个就是REPL)
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~
所以我们的主函数将有一个无限循环,它打印提示符,获取一行输入,然后处理这一行输入。
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
// 无限循环
while (true) {
// 打印提示符
print_prompt();
// 获取一行输入
read_input(input_buffer);
// 处理这一行输入,为.exit时退出
if (strcmp(input_buffer->buffer, ".exit") == 0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









