







 本文详述了Longhorn的架构和关键功能,包括数据复制(Replication)、备份(Backup)以及如何利用这些特性实现高可用性和容灾恢复。Longhorn作为一个为Kubernetes设计的分布式存储系统,通过跨节点的Replica确保数据安全,同时支持将数据备份到外部存储,以实现集群级别的容灾。文章还介绍了Longhorn的GUI界面,便于用户管理和监控存储状态。使用案例展示了Longhorn如何解决传统云存储如EBS的局限性,以及如何通过备份和DR集群实现快速恢复服务。
本文详述了Longhorn的架构和关键功能,包括数据复制(Replication)、备份(Backup)以及如何利用这些特性实现高可用性和容灾恢复。Longhorn作为一个为Kubernetes设计的分布式存储系统,通过跨节点的Replica确保数据安全,同时支持将数据备份到外部存储,以实现集群级别的容灾。文章还介绍了Longhorn的GUI界面,便于用户管理和监控存储状态。使用案例展示了Longhorn如何解决传统云存储如EBS的局限性,以及如何通过备份和DR集群实现快速恢复服务。
作者简介
吴硕,SUSE Senior Software Development Engineer,已为 Longhorn 项目工作近四年,是项目 maintainer 之一。
本文将介绍 Longhorn 的基本功能和架构,replica 和 backup 这两个最重要的特性以及使用案例,帮助大家了解 Longhorn 的价值所在以及使用方法。
Longhorn 介绍
Longhorn 是一个轻量的、可靠易用的、为 Kubernetes 设计的分布式存储系统,100% 开源,现已成为 CNCF 孵化项目。
Longhorn 作为存储系统,最重要、最基本的功能就是为 Kubernetes 的工作负载提供持久存储,我们称为 Longhorn volume。它利用集群工作节点本身的存储设备实现存储,这种超聚合的方式是 Longhorn 的设计理念之一,也可以很好地和 SUSE 另外一个项目——Harvester 集成。
为了保证高可用性,Longhorn 首先支持跨节点或跨可用区(AZ)的数据复制,即 Replication。如果整个集群或者恰好 volume 的所有 replica 都突然不可用,就需要将数据进一步备份(backup)到集群外部了。
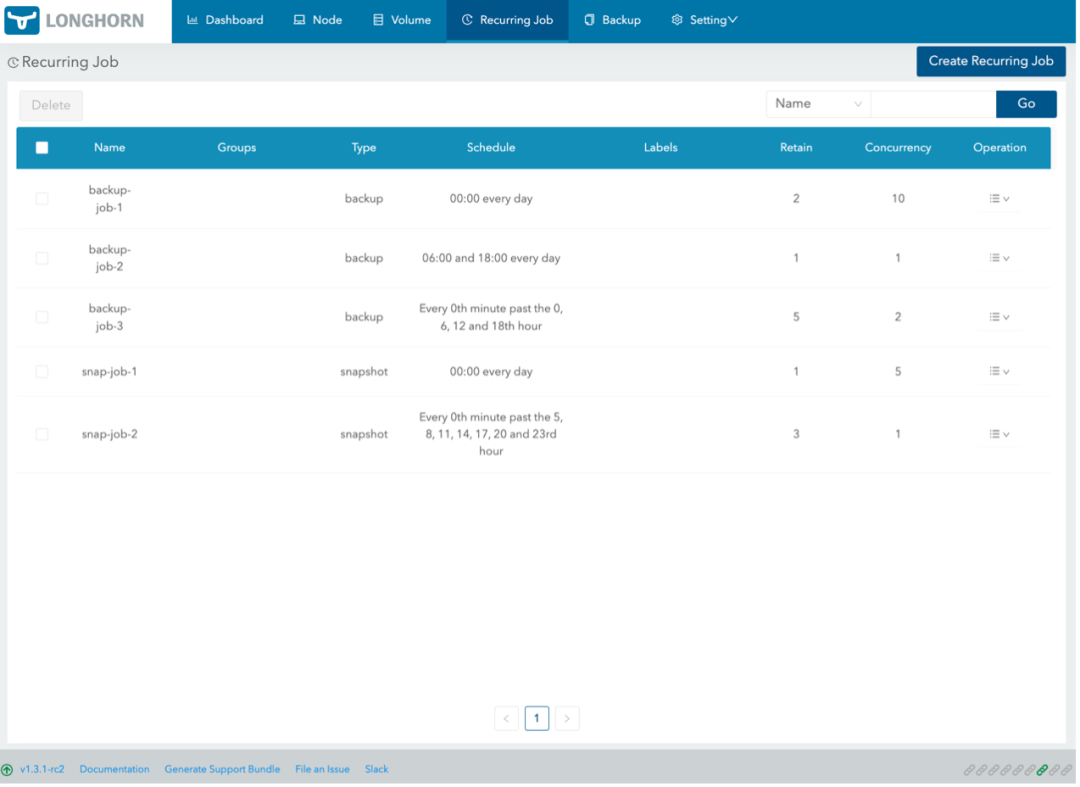
Longhorn 支持将数据上传到 NFS 或者 S3 compatible 的存储方案。利用外部的备份数据,Longhorn 可以做集群级别的容灾恢复。关于数据备份本身,用户不可能每次手动发起请求,所以 Longhorn 支持周期性的 backup 和 snapshot,这个功能一般称为 cron job 或者 recurring job。
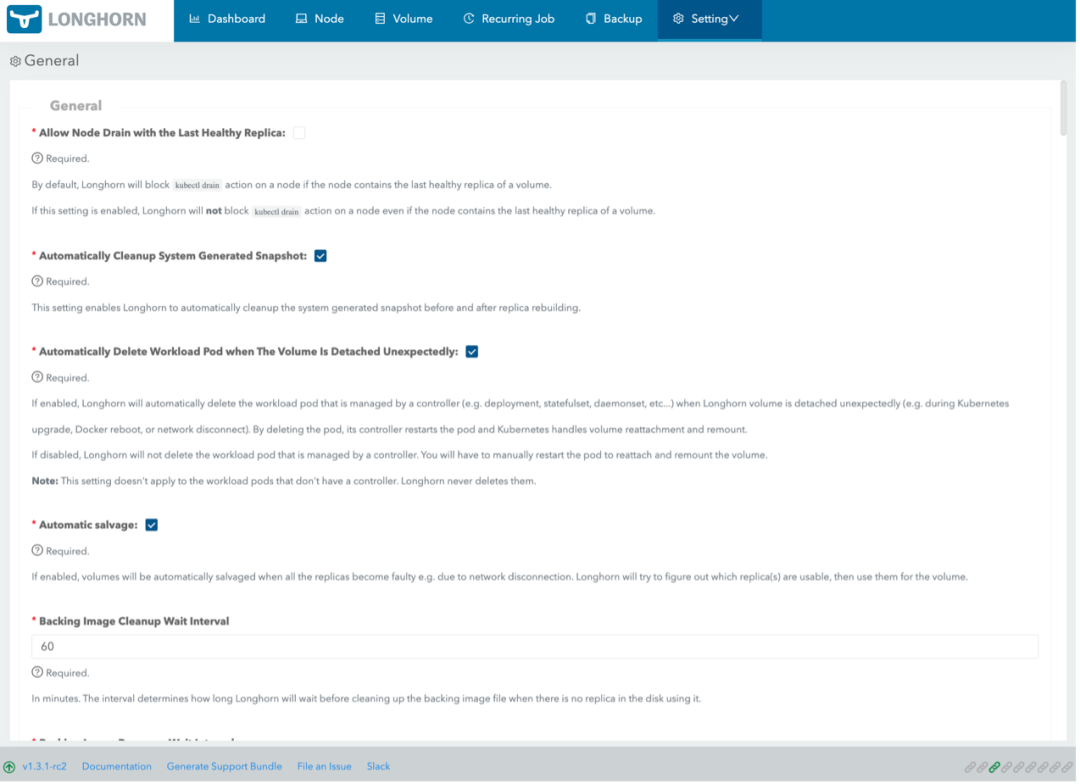
关于 Longhorn 升级,我们的要求是不能够影响用户或者已经运行的 volume 读写,所以每次 Longhorn 版本升级都是无中断升级。
今年 Longhorn 面向 VM 推出了新功能 backing image。假如用户想要起数十个或者上百个 VM,为每个 VM 单独下载一份一模一样的 SLES 或 Ubuntu 等 image,是非常浪费时间和空间的。在这一场景下,客户只需下载一份 image 作为只读的底层文件,并让所有 VM 共用即可。
此外,Longhorn 还有更多扩展功能,在此就不一一赘述了。

Longhorn 提供了一套 GUI 界面,如下图。用户可以通过 GUI 查看整体存储状况,管理可用的节点及相应的磁盘空间。
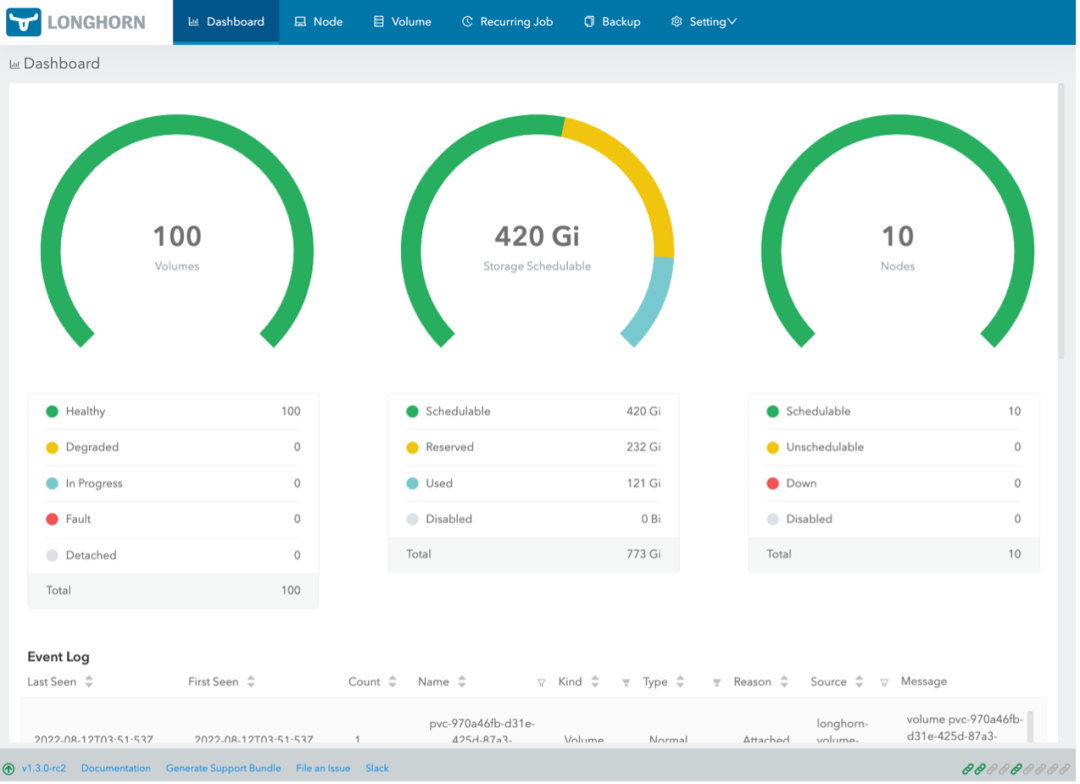
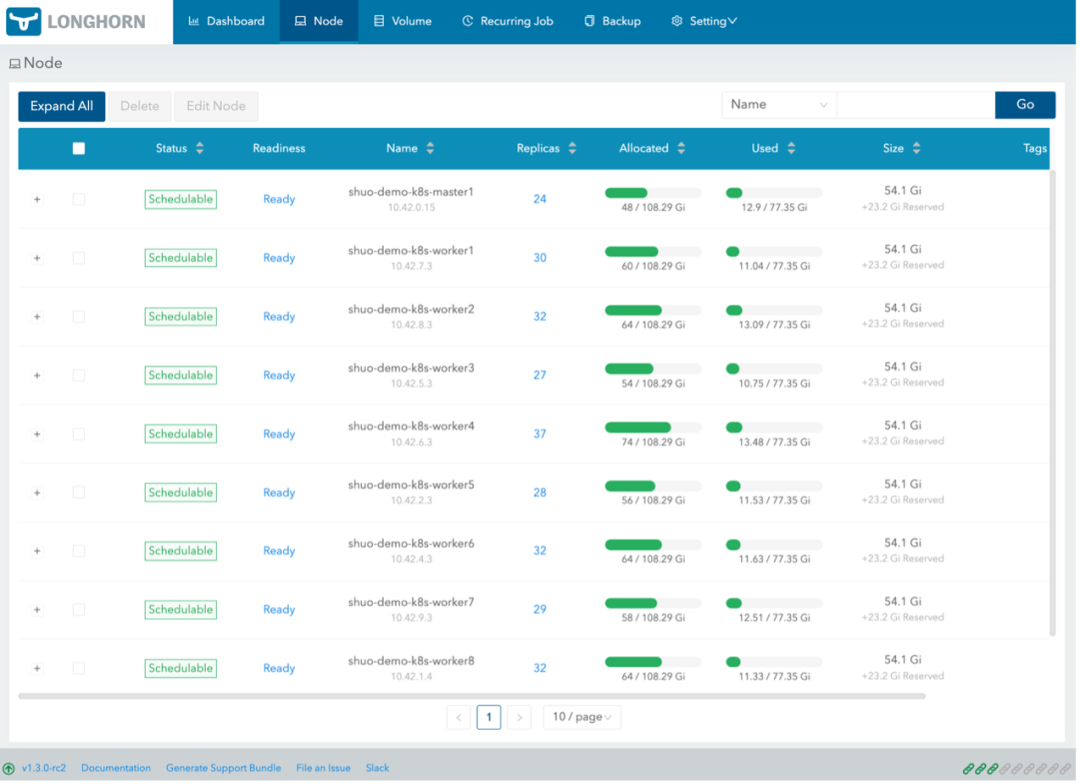
最重要的还是 volume 相关界面。打开 Longhorn 详细界面可以看到 volume 状态、应用信息以及 snapshot 相关信息。
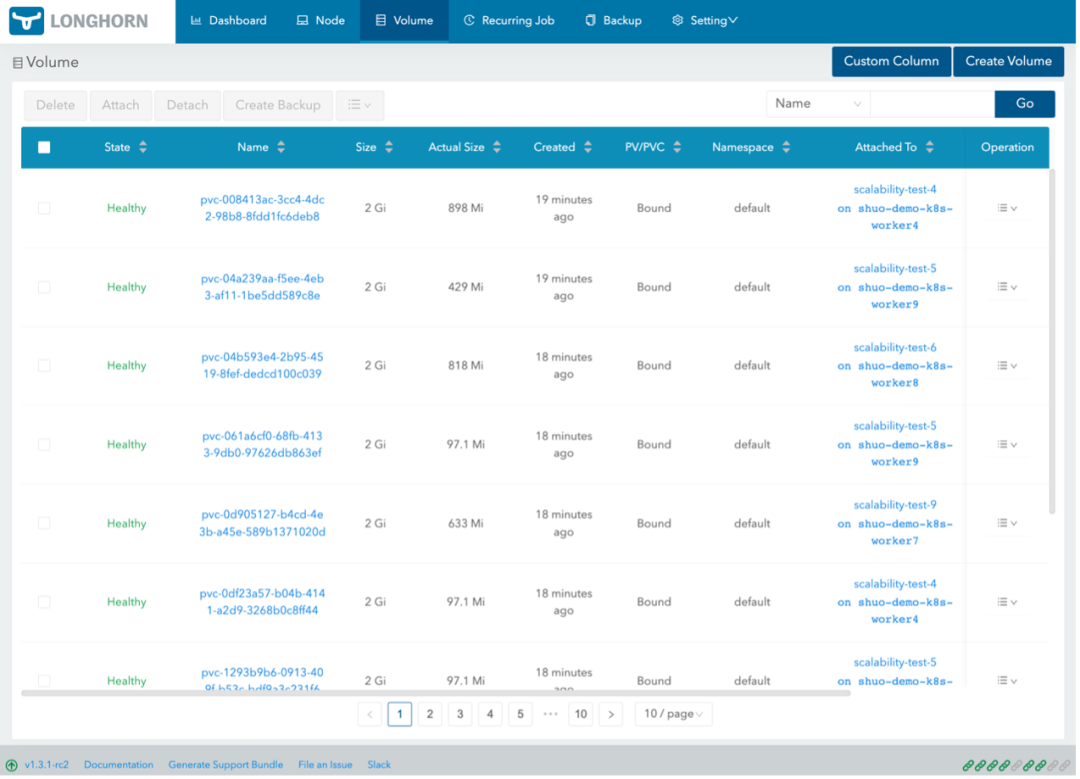
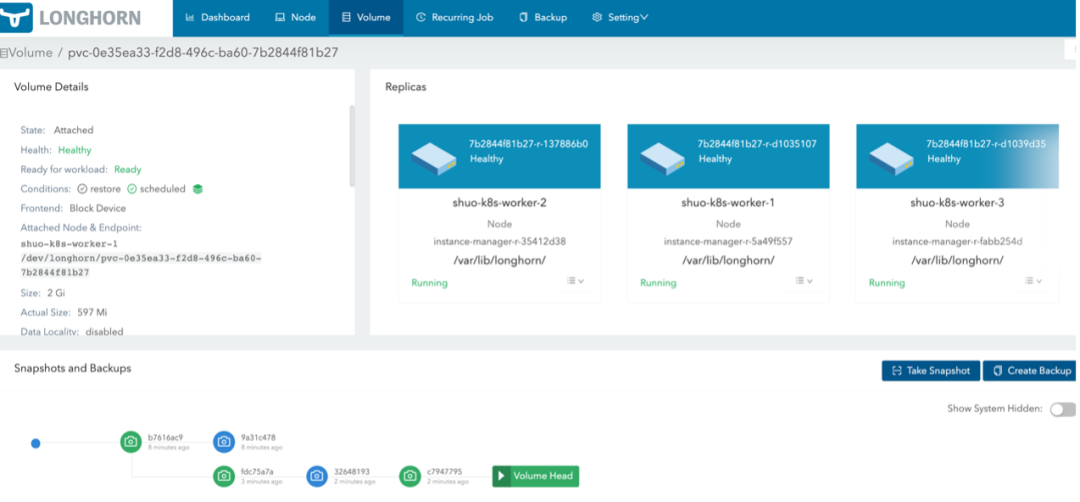
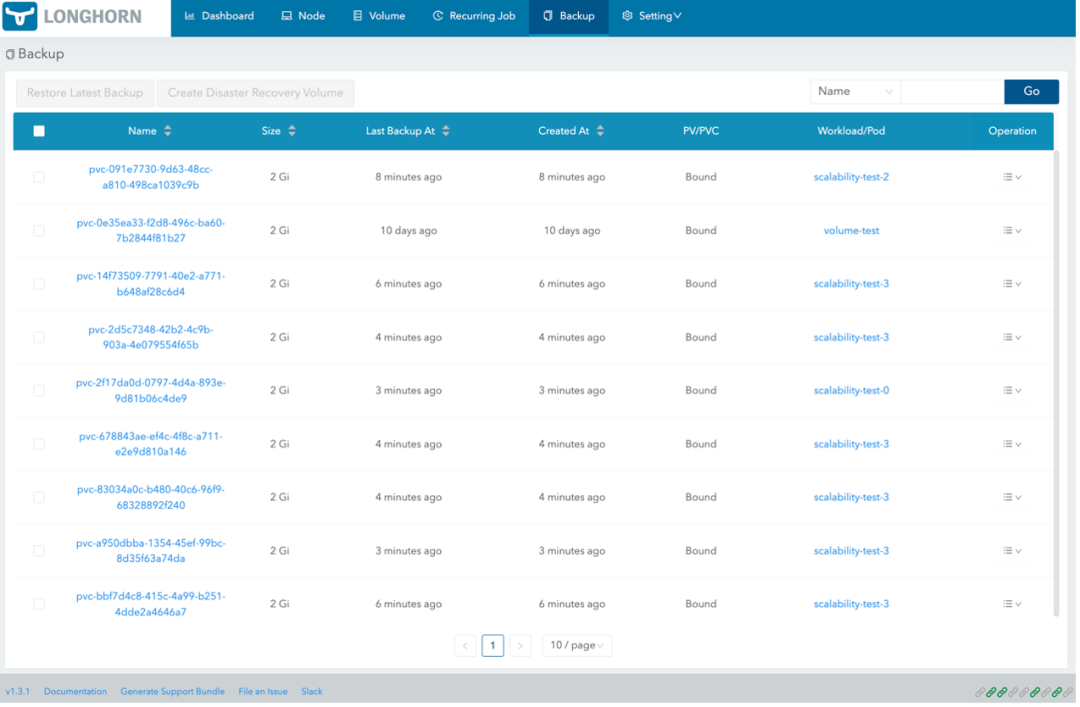
此外,还有 backup、recurring job、setting 等界面,绝大部分 Longhorn 本身相关配置都可以在 GUI 中完成。
关于更多 Longhorn 的功能和特点,大家可以自行根据官方网站的文档进行部署体验。如之前所说,Longhorn 的部署和使用非常简单直接。
Longhorn 的架构
整体架构和工作流程
当用户在 Kubernetes 创建一个新的应用(Pod)并需要持久性存储时,Kubernetes 就会通过 CSI(Container Storage Interface) API 向实现了这套接口的 Longhorn CSI Plugin 发送请求;而这个 Longhorn CSI Plugin 则利用 Longhorn API,去和中间的 Longhorn Manager 交互并完成请求。
Longhorn Manager 是负责将系统抽象成 Kubernetes 资源(Custom Resource Definition) 并进行协调管理的组件。比如 volume 的创建和挂载(Attachment),就是 Longhron Manager 协调好相应的 Kuberntes 资源 (Custom Resource)后,启动相应的进程来实现的。
一个 Longhorn Volume 是由一个 engine 与多个 replica 组成的。每一个 replica 都是 volume 数据的完整复制体。Engine 负责连接和控制这些 replica,并向 workload 提供 block device。
此外,Longhorn UI 也是通过 Longhorn API 完成所有的操作和功能。
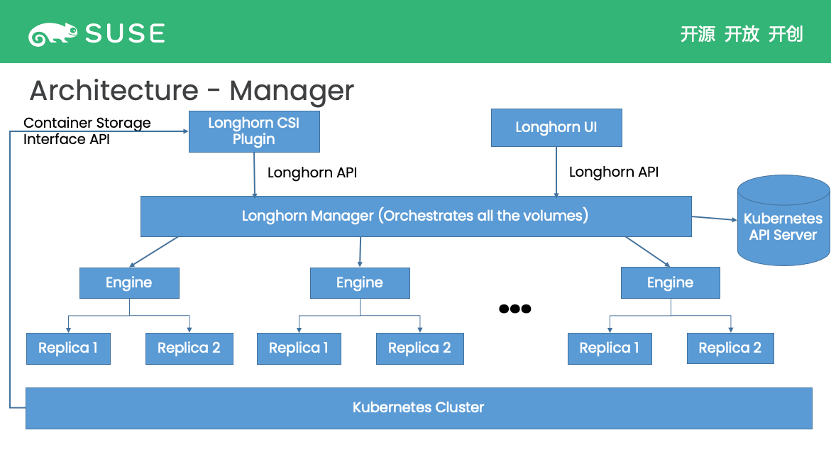
Longhorn Volume 如何工作
假设有三个工作节点,每个节点都有相应的硬件,比如 CPU、Memory 和 SSD 磁盘。如前文提到,Replica 会直接利用同节点上的 SSD 来存储数据,而 engine 则负责连接和控制 replica,并处理一些操作,volume 是对 engine 和所有 replica 的总结抽象。
一个 volume 通常有多个 replica 分布在不同节点上,所以当一个节点宕掉时,其他节点上仍有完好可用的 replica。利用剩余的完好 replica,我们可以快速重启 volume 并恢复服务。如下图,节点 1 宕机后,节点 2 上的 repica 仍然可用,因此我们可以快速在节点 3 上重启 engine 并恢复 Pod A。由于节点 2 本身没有宕掉,其中的 Pod B 和 Pod C,及其相应 Volume 的功能不会受到影响,受影响的只有 Volume 的高可用程度。
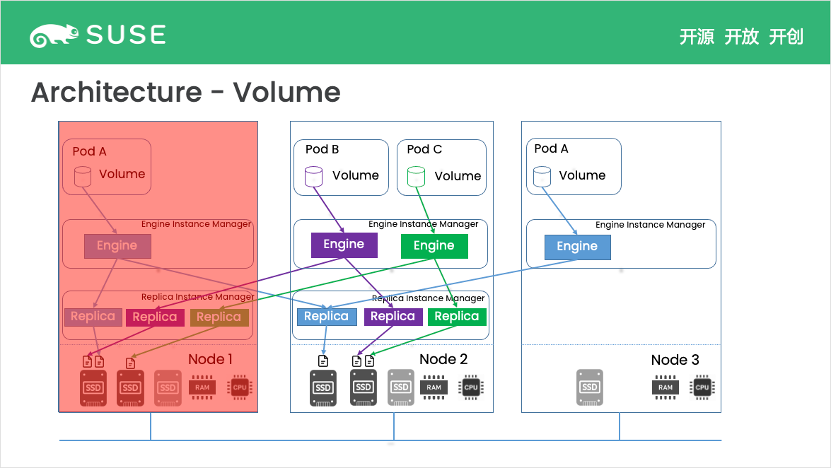
此外,Volume/Engine 的架构图还反应了两个事实。
其一,对于每一个节点来说,所有的 replica 都是由一个 Replica Instance Manager 管理的,engine 同理。这样可以保证一个节点上可以运行多个 engine 或 replica。而 Instance Manager 之中的 engine/replica 互不干扰,独立运行。
其二,每一个 volume 的 engine,和其 workload/pod 始终运行在同一个节点上。Instance Manager 功能比较稳定简单,一般不会导致 engine 崩溃掉。所以一般 volume 或 engine 崩溃掉的的主要原因是所有 replica 同时崩溃,或当前节点突然不可用。换句话说,engine 和 workload 的生命周期通常是相同的,这样 Longhorn 避免了在多个节点启动多个 engine 来保障一个 volume 的高可用性。
关于更具体的细节,有兴趣的读者可以访问 Longhorn 文档。
使用案例 1
Longhorn 有何非用不可的理由?毕竟使用 Longhorn 意味着在存储栈上额外加了一层,性能不可避免地会受到影响。Longhorn 是保证 crash consistency 这种强一致性的,这种强一致性会导致额外的 latency 和写性能上的损失(不过读性能反而会有所增加)。
当用户使用公有云比如 AWS 时,他为什么不直接使用 EBS Volume,转而使用Longhorn 呢?因为 EBS 有一个很重要的问题——它无法跨可用区(AZ)做迁移。
如下图,一个 EKS 在三个 zone 上面部署了工作节点,在 zone 1a 上的节点部署了一个 Pod 并使用了一个 EBS。当这个节点不可用导致 Pod 停掉时,想恢复这个 Pod,用户就必须在其他两个 zone 节点上重新部署 Pod,并重新挂载之前的 EBS Volume。这个时候的问题是,EBS Volume 无法跨区迁移,所以直接使用 EBS Volume,是无法处理这种情况的。
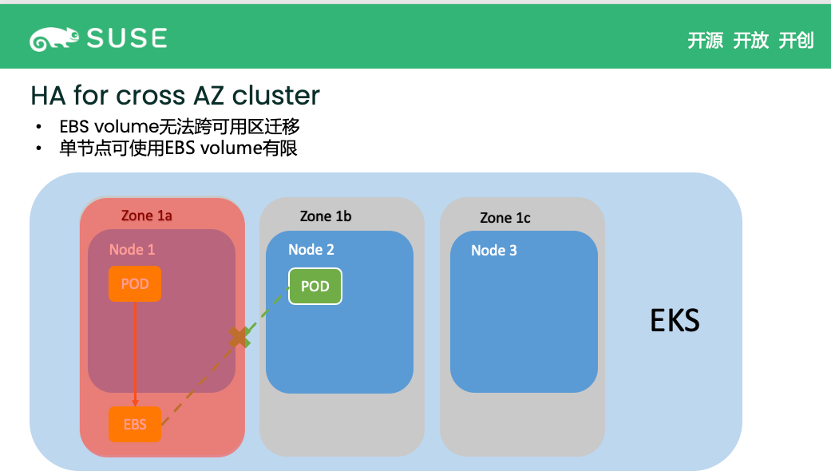
第二个痛点则是 AWS 的单个 instance 上可以挂载的 EBS Volume 是有限的,可能就十几个。在现在容器化的应用场景里,一个节点可能运行几十或者上百个容器/pod,其中每个容器/pod 可能需要几个持久性的存储(或许单个存储不需要太大),在这种情况下 EBS Volume 是远远不够用的。
其三,EBS Volume 的 attachment/detachment 相对比较慢,大概是分钟级,不能完美适用 Pod 经常迁移变动的情景。
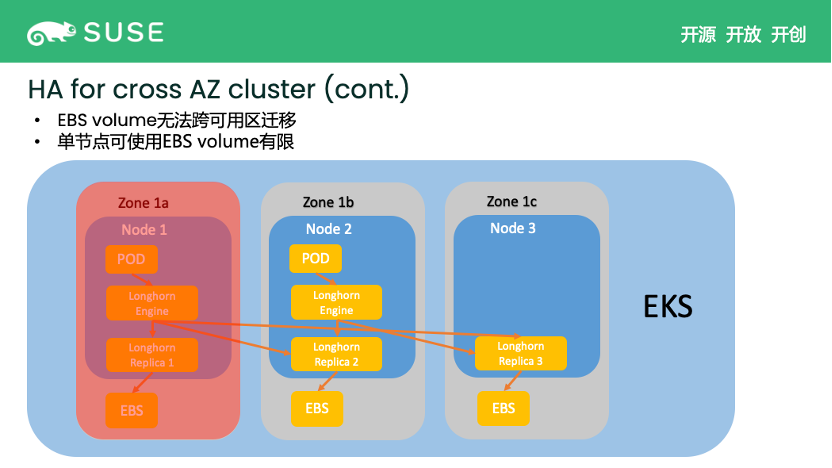
如果使用 Longhorn,上述问题就不再是问题。首先,Longhorn volume 的 replica 是可以跨 AZ 来保障高可用性的。当 Zone 1a 节点挂掉时,Longhorn 可以马上在 zone 1b 上重启 engine 并直接连接剩余的 replica,这样 Pod 可以即刻恢复服务。
另一方面,Longhorn 也通过了 scalability 测试——在 10个节点的 cluster 挂载并使用 2000 个 Volume,即每个节点运行 200个 Volume 是没有问题的。
最后 Longhorn Volume 的 attachment/detachment 相比 EBS Volume 非常快,通常 3~10 秒就够了。
使用案例 2
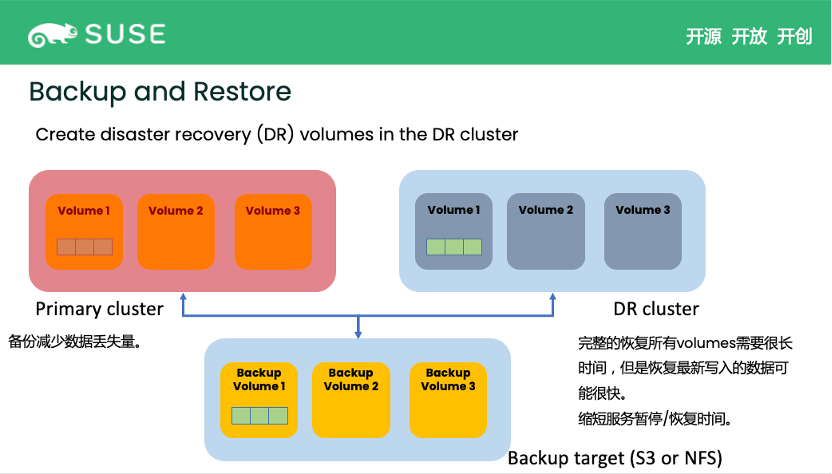
有时候单集群内的高可用是不太够用的。如上文提到,当集群宕机或者节点大规模掉线恰好导致 volume 的所有 replica 都不可用时,Longhorn 也需要确保尽快恢复服务。这时候我们就需要 backup。Backup 是指将 Volume 数据备份到外部的存储空间,比如 NFS 或者 S3 相兼容的存储方案。
如下图,当前 Primary Cluster (主集群,正在提供服务的集群)内有服务正在使用Longhorn volume,用户就可以把 Volume 数据备份到 Backup Target 这个外部存储中。而一旦有了 Backup Volume,用户可以设置一个 Disaster Recovery Cluster(DR Cluser,灾难恢复集群, 当 Primary Cluster 挂掉时可以快速切换到此集群以快速恢复服务),连接到同一个 Backup Target,并及时地将 Backup 恢复到集群内的 DR volume 中备用。此时,Primary Cluster 内的 Volume 在被持续使用,会有新的数据写入。Longhorn 就会仅将新写入的数据继续备份到之前的 Backup Volume,这称之为 incremental backup (增量备份)。
一旦有新的数据被备份,DR Cluster 会检测到变化,将新的数据继续恢复到之前的 DR Volume。这样即使存在延迟,但 DR volume 的数据基本是相应的 Volume 保持一致的。稍后,如果 Primary Cluster 突然宕机,用户就可以立即启用 DR cluster 并激活 DR Volume,以达到快速恢复服务的目的。
RPO 和 RTO:衡量整个灾难恢复速度/能力的指标
RPO(Recovery Point Objective)即恢复点目标,指从上次备份到灾难发生中间隔了多长时间,这个指标反映了(能容忍的)数据的丢失量。该指标实际由 backup 间隔决定,Backup 创建的间隔有多久,RPO 就有多久。
RTO(Recovery Time Objective)即恢复时间目标,指从灾难发生到服务恢复需要多少时间。DR cluster 与 DR volume 的存在,就是为了尽可能地减少这个时间。假如没有 DR cluster 或者 DR Volume,灾难发生时,我们想尽快恢复服务,就要把所有的 Backup Volume 一口气恢复到新的 ctuster 中。对于企业来说大概是 PB 级的数据,短时间恢复这么大的数据所需要的时间非常长,可能几个小时,或者几天的时间,这对于企业来说是不太能接受的。
但是假设有一个 DR cluster,由于它会周期性地自动拉取最新备份的数据到 DR Volume 里,只要检测拉取的间隔合理,大部分情况下 DR Volume 里都是含有最新的数据的,或者跟相应的 Volume 只差了一个备份周期以内的数据,恢复这部分数据可能仅需几分钟或者几十分钟。相比几个小时或者几天,恢复时间缩短了一个数量级,这就是为什么说 DR Cluster 和 DR Volume 能缩短 RTO。简而言之,通过配置 backup 和 restore 的间隔,用户就能控制 RTO 和 RPO。
backup 是如何创建或者删除的,以及 backup 本身的结构
如下图,左边是 Volume 的结构。这里说一下,snapshot 本质是保存了某个时间段的历史数据,volume head 里则是最新写入的数据。所以读取 volume 中某段数据,就是从最新的 volume head 开始,查找这部分空间最近写入的数据(在 volume head 或者某个 snapshot 中)。
简而言之,我们读取数据,包括备份时的数据读取,都是从右往左读。这时要为 snapshot2 创建 backup,首先要确定 snapshot2 这个点上 volume 的数据是什么样子的。以 snapshot2 为最右边或者最近的文件,从右往左看,能看到的数据是第一个 data block 在 snapshot1,后面两个 data block 是在 snapshot2。这样我们找到了 backup 对应的 snapshot,了解了包含这些 snapshot 中的哪些 data block,剩下的就是把数据上传到 backup target 即可。
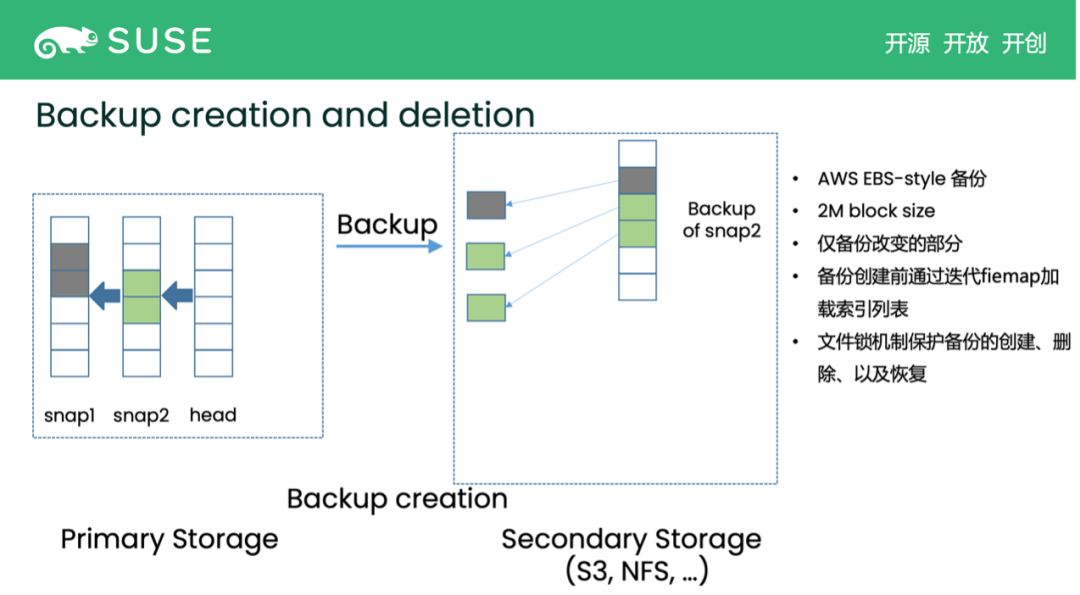
稍后,新的数据被写入了,我们想要创建新的 backup,就先需要把当前的 volume head 变成 snapshot3 并基于 snapshot3 做 backup。这时候就重新从右往左看,也就是从 snapshot3,整个 Volume 就包含 5 个 data block。跟之前的 backup 相比,所差的数据就是 snapshot3 的数据。强调这个 delta 部分的原因是,之前 backup 过的数据是不需要重新上传的,也就是只需要备份新的数据,即 snapshot3 中的数据就可以。
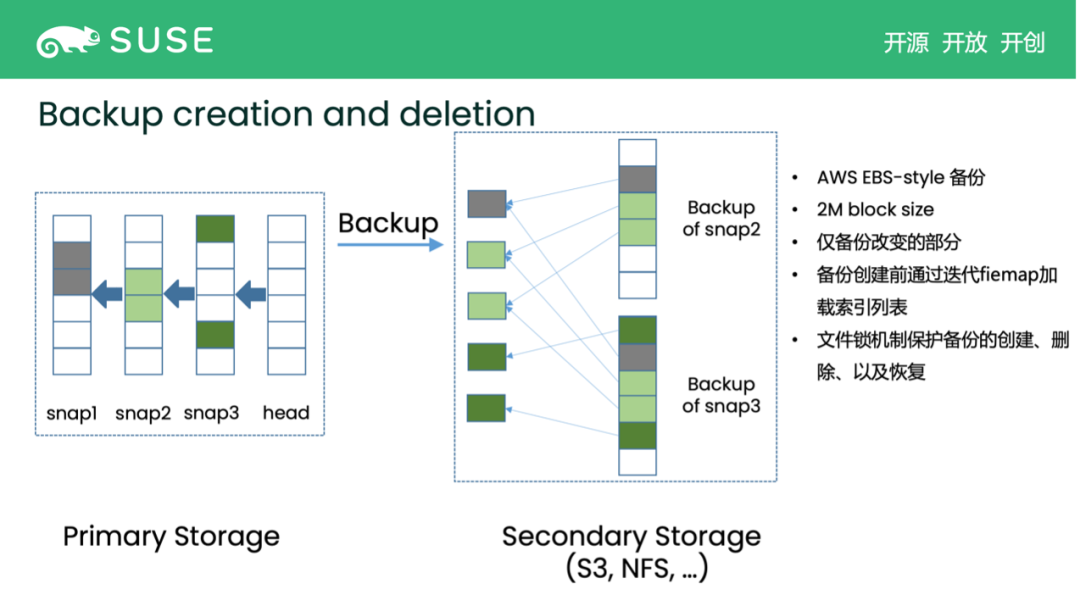
backup deletion 也类似。比如我们要删掉 snapshot 对应的 backup,就需要和前一个 backup 做对比。我们发现,有几个 data block 是被前一个 backup 正在使用的,所以只能删掉那些孤立的、仅被当前 backup 所指的 data block,这样其他的 backup 不会被影响,这就是 deletion 的机制。当然这些 backup 相关操作都有一个文件锁来保护,所以不需要担心 race condition 的问题。
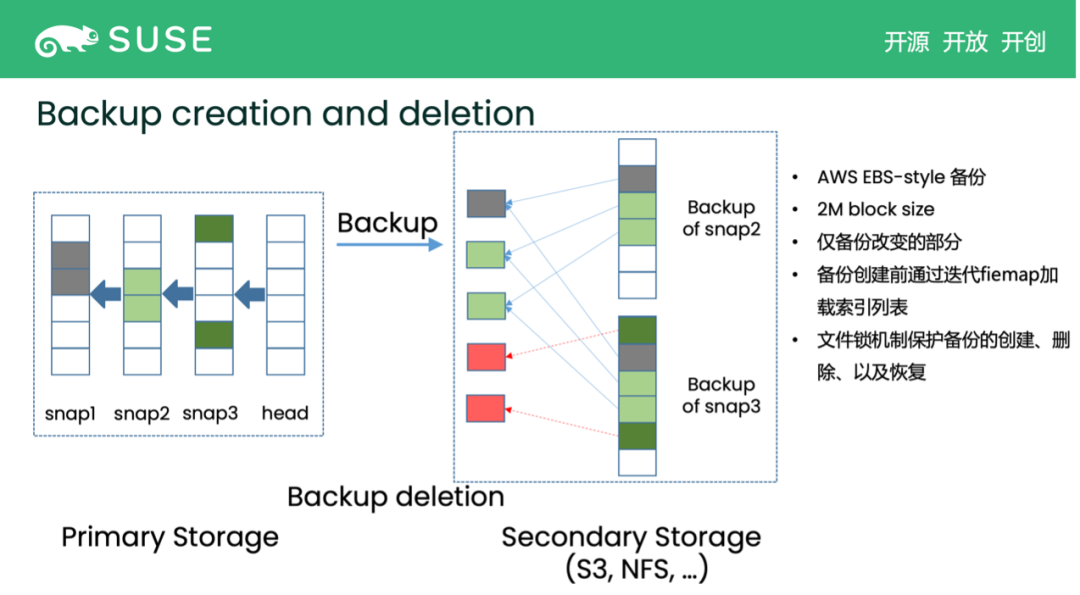
最后,restore 也是类似的原理。如果是直接根据 snapshot2 的 backup 创建 DR volume,我们发现三个 data block 后,直接把它们恢复到对应的 DR Volume 里就可以。而如果是拉取最新的(incremental) backup 数据,则是对比上一个 restore 过的 backup,把新增的 data block 拉取下来即可。
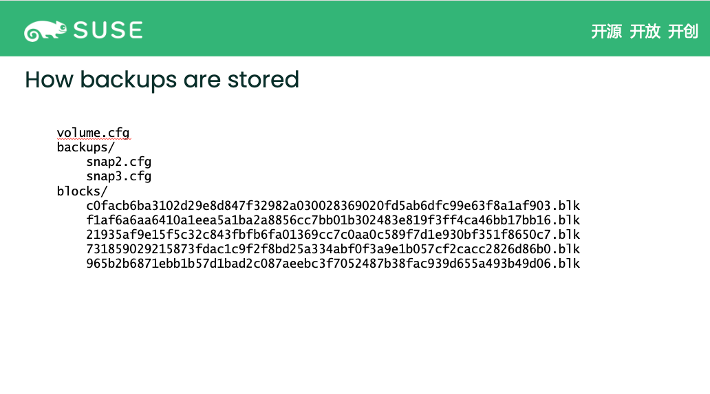
backup 在服务器里是什么样子?我们怎么管理文件呢?如下图,由于这个 backup volume 可能有很多的 backup,每个 backup 就有一个对应的元数据文件 snap.cfg,主要记录这些 backup 由哪些 data block 组成。剩下的就是 data block,可能是被一个或者多个 backup 引用。这就是关于 backup 和 restore 的全部基本介绍。


















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









