







完整代码在文末
概述
Apriori算法需要多次扫描数据,庞大的I/O次数是很大的瓶颈,FP Tree算法(也称FP Growth算法)采用了一些技巧,无论多少数据,只需要扫描两次数据集,因此提高了算法运行的效率
我先概述一下这个算法的数据结构,你只需要知道是啥就行,如果你现在一眼能看懂来龙去脉,可以直接点个赞然后溜了;第一眼看不懂也正常,慢慢来往下看…
数据结构
为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据。这个数据结构包括三部分,如下图所示:
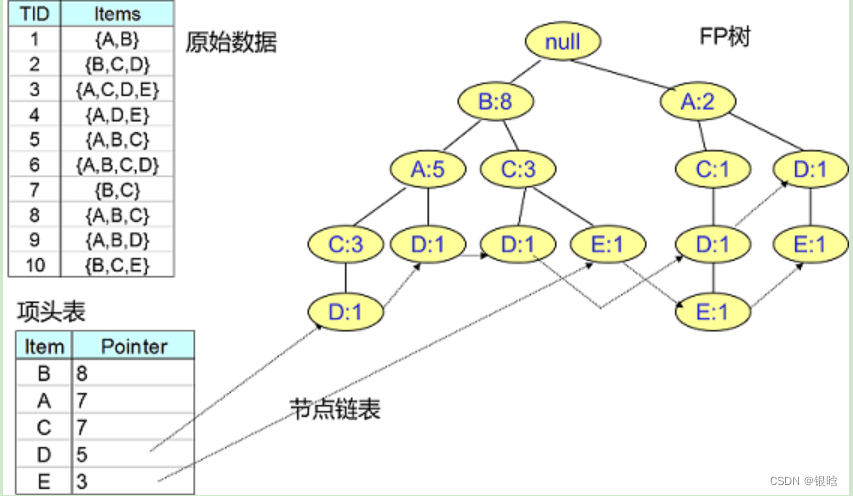
- 项头表。里面记录了所有的单项频繁集出现的次数,按照次数降序排列
- FP Tree,它将我们的原始数据集映射到了内存中的一颗FP树,这个FP树比较难理解,后面再讲
- 节点链表。所有项头表里的单项频繁集都是一个节点链表的头,它依次指向FP树中该单项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新,也好理解
项头表的建立
FP树的建立需要首先依赖项头表的建立。那看看怎么建立项头表
官方描述:第一次扫描数据,得到所有频繁单项集的的计数。然后删除支持度低于阈值的项,将单项频繁集放入项头表,并按照支持度降序排列。接着第二次也是最后一次扫描数据,将读到的原始数据剔除非频繁单项集,并按照支持度降序排列
- 这是我们的数据

有10条数据,首先第一次扫描数据并对单项集计数,我们发现O,I,L,J,P,M, N都只出现一次,支持度低于20%的阈值,因此他们不会出现在下面的项头表中。剩下的A,C,E,G,B,D,F按照支持度的大小降序排列,组成了我们的项头表
-
项头表如下:
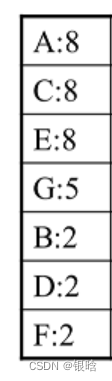
接着我们第二次扫描数据,对于每条数据剔除非频繁1项集,并按照支持度降序排列。比如数据项ABCEFO,里面O是非频繁1项集,因此被剔除,只剩下了ABCEF。按照支持度的顺序排序,它变成了ACEBF。其他的数据项以此类推 -
删除过程如下:

- 然后对删除后的每一项集进行排序(按单项集的频率进行排序,参照项头表)

OKay 长征第一步已经成功了!
FP Tree的建立
有了项头表和排序后的数据集,我们就可以开始FP树的建立了。开始时FP树没有数据,建立FP树时我们一条条的读入排序后的数据集,插入FP树
插入规则:
- 插入时按照排序后的顺序,插入FP树中
- 排序靠前的节点是祖先节点,而靠后的是子孙节点
- 如果有共用的祖先,则对应的公用祖先节点计数加1
- 插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点
- 直到所有的数据都插入到FP树后,FP树的建立完成
妈耶!敢不敢再抽象一点!!!
唉,什么疾苦,那就一条数据一条数据的来吧
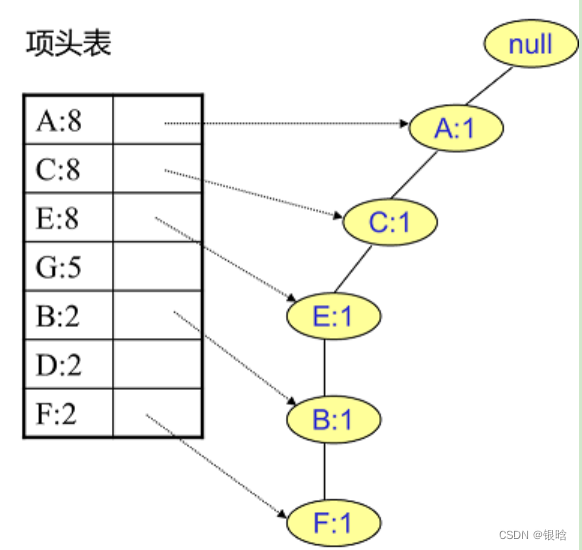
- 首先,我们插入第一条数据ACEBF,如下图所示。此时FP树没有节点,因此ACEBF是一个独立的路径,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点。
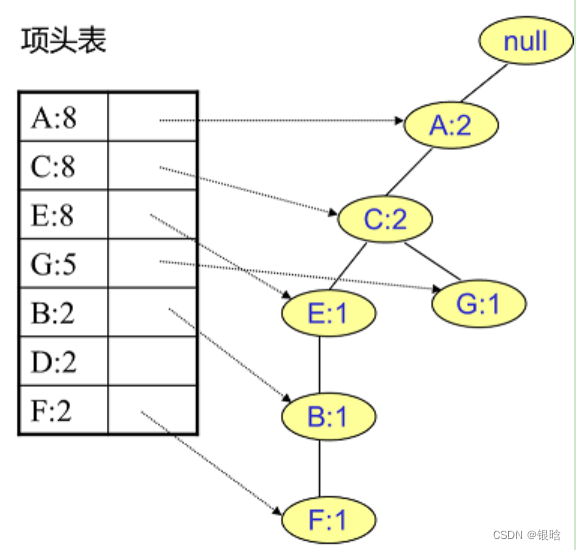
- 接着我们插入数据ACG,如下图所示。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。
后面的8条数据都这样插入,注意有公共的祖先节点一定要走那条路,然后祖先节点次数+1
最后的FP tree结构:
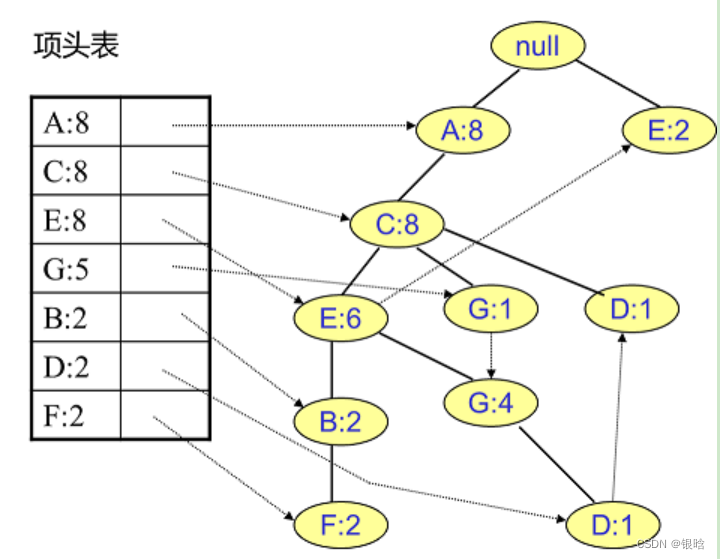
ojbk,长征第二步差不多了
挖掘FP tree
挖掘规则
- 得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘
对于项头表对应于FP树的每一项,我们要找到它的条件模式基。
条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。
得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集了。
码字说了也是白说,那就纸上谈一下兵吧
- 挖掘F节点
- 从最底下的F节点开始,我们先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}
- 叶子节点是F,F的计数是2,那么这一整条路径计数都是2,即{A:2,C:2,E:2,B:2, F:2}
- F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2};频繁3项集为{A:2,C:2,F:2},{A:2,E:2,F:2},…就不写了。最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
- 挖掘D节点
D节点比F节点复杂一些,因为它有两个叶子节点,因此首先得到的FP子树如下图
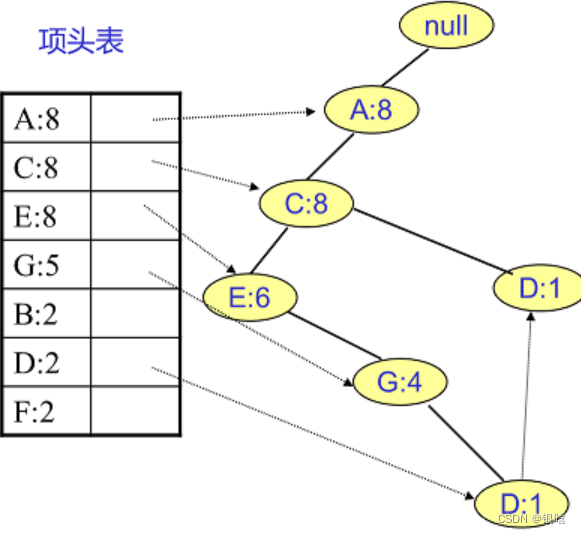
- 叶子节点是D,计数为1,变成{A:2, C:2,E:1 G:1,D:1, D:1} ; 解释一下,有两条路ACEGD和ACD ,所以AC同时在两条路上,所以是2
- E节点和G节点由于在条件模式基里面的支持度低于阈值,被我们删除
- 最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}
注意特例:至于A,由于它的条件模式基为空,因此可以不用去挖掘了
- 其他的都依次类推…
得到的条件模式基就是频繁项集
算法归纳
-
扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
-
扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
-
读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
-
从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集(可以参见第4节对F的条件模式基的频繁二项集到频繁5五项集的挖掘)。
-
如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。
超市数据集挖掘

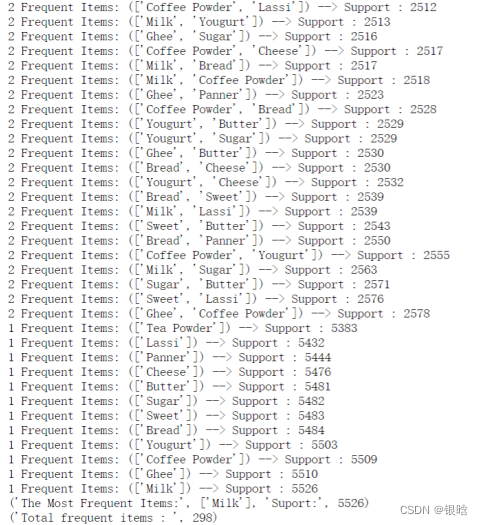
- Fp-growth算法返回的频繁项集,即条件模式基已经可以发现,Lassi不论在单频繁项集、二频繁项集、三频繁项集中,都占有很高的支持度
可以对比参考另一篇文章:Apriori算法挖掘
数据挖掘的学习笔记:数据挖掘学习
代码
python版本为Python2
- 使用命令行启动
python fp_growth.py 数据集 -s 最小支持度
from collections import defaultdict, namedtuple
from itertools import imap
def find_frequent_itemsets(transactions, minimum_support, include_support=False):
items = defaultdict(lambda: 0) # mapping from items to their supports
for transaction in transactions:
for item in transaction:
items[item] += 1
# Remove infrequent items from the item support dictionary.
items = dict((item, support) for item, support in items.iteritems()
if support >= minimum_support)
def clean_transaction(transaction):
transaction = filter(lambda v: v in items, transaction)
transaction.sort(key=lambda v: items[v], reverse=True)
return transaction
master = FPTree()
for transaction in imap(clean_transaction, transactions):
master.add(transaction)
def find_with_suffix(tree, suffix):
for item, nodes in tree.items():
support = sum(n.count for n in nodes)
if support >= minimum_support and item not in suffix:
# New winner!
found_set = [item] + suffix
yield (found_set, support) if include_support else found_set
# Build a conditional tree and recursively search for frequent
# itemsets within it.
cond_tree = conditional_tree_from_paths(tree.prefix_paths(item))
for s in find_with_suffix(cond_tree, found_set):
yield s # pass along the good news to our caller
# Search for frequent itemsets, and yield the results we find.
for itemset in find_with_suffix(master, []):
yield itemset
class FPTree(object):
Route = namedtuple('Route', 'head tail')
def __init__(self):
# The root node of the tree.
self._root = FPNode(self, None, None)
# A dictionary mapping items to the head and tail of a path of
# "neighbors" that will hit every node containing that item.
self._routes = {}
@property
def root(self):
"""The root node of the tree."""
return self._root
def add(self, transaction):
"""Add a transaction to the tree."""
point = self._root
for item in transaction:
next_point = point.search(item)
if next_point:
# There is already a node in this tree for the current
# transaction item; reuse it.
next_point.increment()
else:
# Create a new point and add it as a child of the point we're
# currently looking at.
next_point = FPNode(self, item)
point.add(next_point)
# Update the route of nodes that contain this item to include
# our new node.
self._update_route(next_point)
point = next_point
def _update_route(self, point):
"""Add the given node to the route through all nodes for its item."""
assert self is point.tree
try:
route = self._routes[point.item]
route[1].neighbor = point # route[1] is the tail
self._routes[point.item] = self.Route(route[0], point)
except KeyError:
# First node for this item; start a new route.
self._routes[point.item] = self.Route(point, point)
def items(self):
for item in self._routes.iterkeys():
yield (item, self.nodes(item))
def nodes(self, item):
"""
Generate the sequence of nodes that contain the given item.
"""
try:
node = self._routes[item][0]
except KeyError:
return
while node:
yield node
node = node.neighbor
def prefix_paths(self, item):
"""Generate the prefix paths that end with the given item."""
def collect_path(node):
path = []
while node and not node.root:
path.append(node)
node = node.parent
path.reverse()
return path
return (collect_path(node) for node in self.nodes(item))
def inspect(self):
print 'Tree:'
self.root.inspect(1)
print
print 'Routes:'
for item, nodes in self.items():
print ' %r' % item
for node in nodes:
print ' %r' % node
def conditional_tree_from_paths(paths):
"""Build a conditional FP-tree from the given prefix paths."""
tree = FPTree()
condition_item = None
items = set()
for path in paths:
if condition_item is None:
condition_item = path[-1].item
point = tree.root
for node in path:
next_point = point.search(node.item)
if not next_point:
# Add a new node to the tree.
items.add(node.item)
count = node.count if node.item == condition_item else 0
next_point = FPNode(tree, node.item, count)
point.add(next_point)
tree._update_route(next_point)
point = next_point
assert condition_item is not None
# Calculate the counts of the non-leaf nodes.
for path in tree.prefix_paths(condition_item):
count = path[-1].count
for node in reversed(path[:-1]):
node._count += count
return tree
class FPNode(object):
"""A node in an FP tree."""
def __init__(self, tree, item, count=1):
self._tree = tree
self._item = item
self._count = count
self._parent = None
self._children = {}
self._neighbor = None
def add(self, child):
"""Add the given FPNode `child` as a child of this node."""
if not isinstance(child, FPNode):
raise TypeError("Can only add other FPNodes as children")
if not child.item in self._children:
self._children[child.item] = child
child.parent = self
def search(self, item):
try:
return self._children[item]
except KeyError:
return None
def __contains__(self, item):
return item in self._children
@property
def tree(self):
"""The tree in which this node appears."""
return self._tree
@property
def item(self):
"""The item contained in this node."""
return self._item
@property
def count(self):
"""The count associated with this node's item."""
return self._count
def increment(self):
"""Increment the count associated with this node's item."""
if self._count is None:
raise ValueError("Root nodes have no associated count.")
self._count += 1
@property
def root(self):
"""True if this node is the root of a tree; false if otherwise."""
return self._item is None and self._count is None
@property
def leaf(self):
"""True if this node is a leaf in the tree; false if otherwise."""
return len(self._children) == 0
@property
def parent(self):
"""The node's parent"""
return self._parent
@parent.setter
def parent(self, value):
if value is not None and not isinstance(value, FPNode):
raise TypeError("A node must have an FPNode as a parent.")
if value and value.tree is not self.tree:
raise ValueError("Cannot have a parent from another tree.")
self._parent = value
@property
def neighbor(self):
"""
The node's neighbor; the one with the same value that is "to the right"
of it in the tree.
"""
return self._neighbor
@neighbor.setter
def neighbor(self, value):
if value is not None and not isinstance(value, FPNode):
raise TypeError("A node must have an FPNode as a neighbor.")
if value and value.tree is not self.tree:
raise ValueError("Cannot have a neighbor from another tree.")
self._neighbor = value
@property
def children(self):
"""The nodes that are children of this node."""
return tuple(self._children.itervalues())
def inspect(self, depth=0):
print (' ' * depth) + repr(self)
for child in self.children:
child.inspect(depth + 1)
def __repr__(self):
if self.root:
return "<%s (root)>" % type(self).__name__
return "<%s %r (%r)>" % (type(self).__name__, self.item, self.count)
if __name__ == '__main__':
from optparse import OptionParser
import csv
p = OptionParser(usage='%prog data_file')
p.add_option('-s', '--minimum-support', dest='minsup', type='int',
help='Minimum itemset support (default: 2)')
p.add_option('-n', '--numeric', dest='numeric', action='store_true',
help='Convert the values in datasets to numerals (default: false)')
p.set_defaults(minsup=2)
p.set_defaults(numeric=False)
options, args = p.parse_args()
if len(args) < 1:
p.error('must provide the path to a CSV file to read')
transactions = []
with open(args[0]) as database:
for row in csv.reader(database):
if options.numeric:
transaction = []
for item in row:
transaction.append(long(item))
transactions.append(transaction)
else:
transactions.append(row)
result = []
for itemset, support in find_frequent_itemsets(transactions, options.minsup, True):
result.append((itemset,support))
result = sorted(result, key=lambda i: i[0])
for itemset, support in result:
print str(itemset) + ' ' + str(support)
















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









