



 本文探讨了如何通过KV缓存技术、多查询注意力机制以及内存管理策略(如FlashAttention和PageAttention)来优化Transformer模型的计算效率,特别是针对大规模模型和显存限制的问题,同时介绍了推测性解码方法以提高推理速度。
本文探讨了如何通过KV缓存技术、多查询注意力机制以及内存管理策略(如FlashAttention和PageAttention)来优化Transformer模型的计算效率,特别是针对大规模模型和显存限制的问题,同时介绍了推测性解码方法以提高推理速度。
-
https://zhuanlan.zhihu.com/p/659770503
-
https://zhuanlan.zhihu.com/p/638468472
KV cache
Decoder 每次前向,当前 timestep 计算 Attention 要用到的部分,如之前 timestep 的 KV (Key 和 Value)值都计算过的,只是之前每次前向完后给计算结果都丢掉,只保留最后输出。
于是一个很自然的想法就是 Cache。这很像斐波那契递归函数,naive 版本,也会出现不断重复计算问题,加个 cache 瞬间提速。
- 每次前向完,给 KV 都保留下来,用于之后计算。
模型规模小还好,一旦模型规模很大长度很长时,KV 根本就存不进缓存!!!
比如 Llama 7B 模型,hidden size 是 4096,那么每个 timestep 需缓存参数量为 4096232=262144,假设半精度保存就是 512KB,1024 长度那就要 512MB. 而现在英伟达最好的卡 H100 的 SRAM 缓存大概是 50MB,而 A100 则是 40MB. 而 7B 模型都这样,175B 模型就更不用说了。
MQA/GQA/MHA

- multiHead 其实就是single-query attention,一个query一个key一个value
- group-query attention,应用参数共享的想法,多个query共享一个key和value
- Multi-query attention , 所有的query公用一个key和value
MQA提高了30%-40% 的吞吐量,主要就是由降低了 KV cache 带来的。实际上 MQA 运算量和 MHA 是差不多的,可理解为读取一组 KV 头之后,给所有 Q 头用,但因为之前提到的内存和计算的不对称,所以是有利的。
MQA 和 GQA 形式在推理加速方面,主要是通过两方面来完成:
- 降低了从内存中读取的数据量,所以也就减少了计算单元等待时间,提高了计算利用率;
- KV cache 变小了 head_num 倍,也就是显存中需要保存的 tensor 变小了,空出来空间就可以加大 batch size,从而又能提高利用率。
MLA
MLA和RMSNorm搭配使用
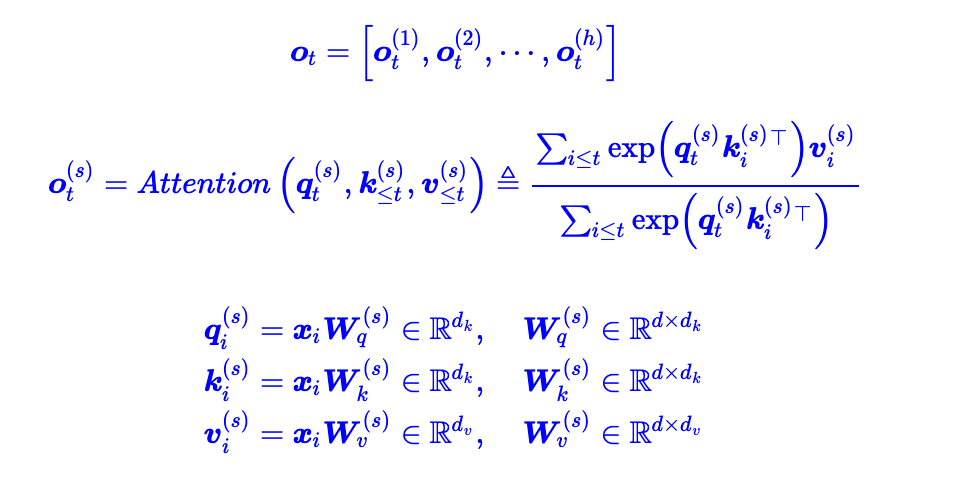
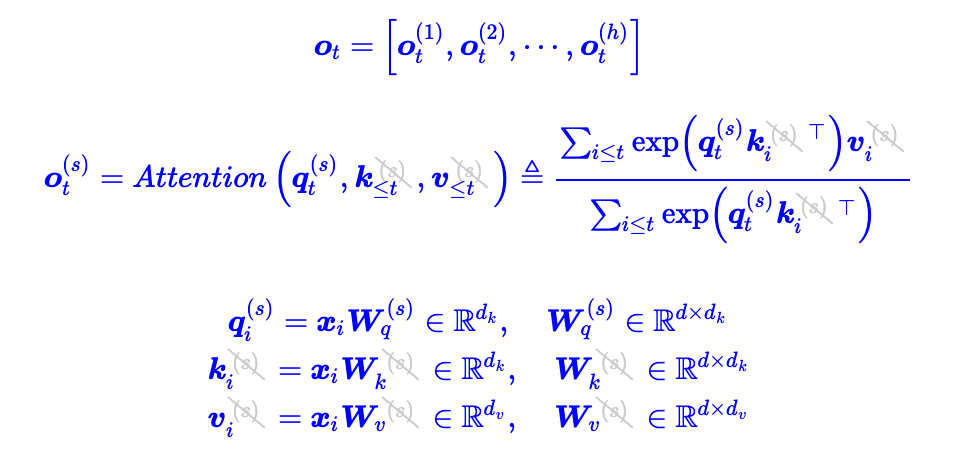
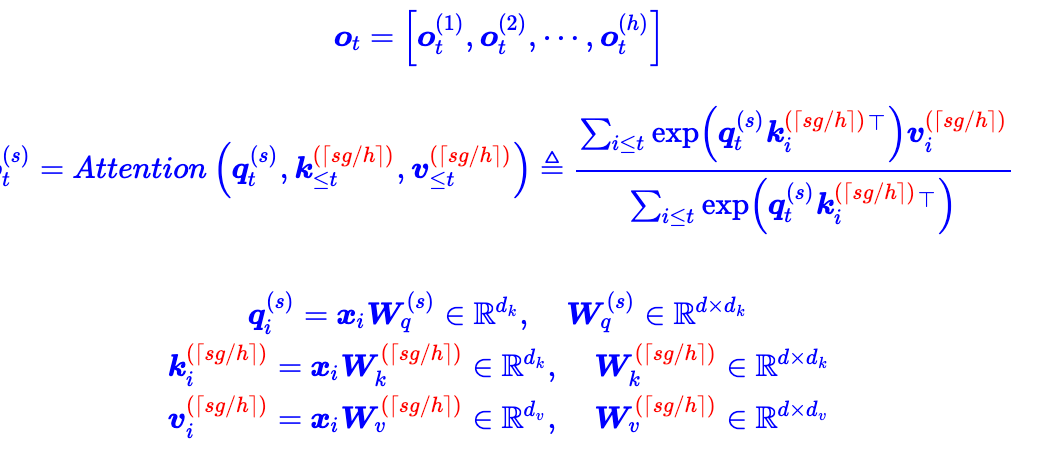
- 通过点积的方式,将低秩投影c替换v,达到减少kv cache的目的

- 不兼容RoPE问题


DeepSeek-R1 知识蒸馏
FlashAttention
名词解释:SRAM(静态随机存取存储器)、HBM(高带宽存储器)
SRAM的优势在于速度快
HBM的优势在于高带宽和低功耗
- 关键点:删除冗余的HBM读/写,高效利用SRAM提速
直观的想法:将多个操作融合在一起。所以只从HBM加载一次,执行融合的op,然后将结果写回来。这样做可以减少通信开销。
FlashAttention旨在避免从 HBM(High Bandwidth Memory)中读取和写入注意力矩阵,这需要做到:
目标一:
目标二:在后向传播中。
Flash attention基本上可以归结为两个主要观点:
-
Tiling (在向前和向后传递时使用,在不访问整个输入的情况下计算softmax函数的缩减;)
- 基本上将NxN softmax/scores矩阵分块成块。
- 随机初始化矩阵,Q,K,V都放在HBM上,在SRAM上进行计算,通过累加更新最终的矩阵O
-
Recomputation (仅在向后传递中不存储中间注意力矩阵)

标准Attention算法由于要计算softmax,而softmax都是按行来计算的,即在和V做矩阵乘之前,需要让 Q、K 的各个分块完成整一行分块的计算得到Softmax的结果后,再和矩阵V分块做矩阵乘。
而在Flash Attention中,将输入分割成块,并在输入块上进行多次传递,从而以增量方式(做加法,避免copy)执行softmax缩减。
目标二:重计算,重新计算比存储中间结果然后读取要快
在后向传播中不存储中间注意力矩阵,通过对比标准Attention算法在实现过程中,标准Attention算法的实现需要将计算过程中的S、P写入到HBM中,而这些中间矩阵的大小与输入的序列长度有关且为二次型
- 因此Flash Attention就提出了不使用中间注意力矩阵,通过存储
softmax归一化因子来减少HBM内存的消耗。 - Flash Attention算法并没有将S、P写入HBM中去,而是通过分块写入到HBM中去,存储前向传递的 softmax 归一化因子,
在后向传播中快速重新计算片上注意力,这比从HBM中读取中间注意力矩阵的标准方法更快。
PageAttention
LLM 的推理,最大的瓶颈在于显存。
- 自回归模型的 keys 和 values 通常被称为 KV cache,这些 tensors 会存在 GPU 的显存中,用于生成下一个 token。
- 这些 KV cache 都很大,并且大小是动态变化的,难以预测。已有的系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。
内存分块
改进思路:受到操作系统中,虚拟内存和分页经典思想的启发,PagedAttention 允许在不连续的内存空间中存储连续的 keys 和 values。
具体做法:
- PagedAttention 会将每个序列的 KV cache 划分为块,每个块包含固定数量 tokens 的 keys 和 values。 在注意力计算过程中,PagedAttention 内核有效地识别并获取这些块。
- **分块之后,这些 KV cache 不再需要连续的内存,**从而可以像在操作系统的虚拟内存中一样,更灵活地对这些 KV cache 进行管理。
内存共享
当用单个 prompt 产出多个不同的序列时,可以共享计算量和显存。
- 通过将不同序列的 logical blocks 映射到同一个 physical blocks,可以实现显存共享。
- 为了保证共享的安全性,对于 physical blocks 的引用次数进行统计,并实现了 Copy-on-Write 机制。
这种内存共享机制,可以大幅降低复杂采样算法对于显存的需求(最高可下降55%),从而可以提升2.2倍的吞吐量。
推测性解码
推测性解码这一概念由 Google 的 Yaniv Leviathan 等人在 《通过推测性解码实现 Transformer 快速推理》中首次提出。
- 这种方法基于一个假设:一个速度更快的助理模型 往往可以生成与更大的主模型相同的 Token。
Step 1 :


Step 2:


Step 3:

Step 4:


- 助理模型的工作:大约 70-80% 的预测 Token 较为简单,这种权衡更倾向于选择速度更快的模型而非准确度更高的模型,助理模型的速度至少应是主模型的 3 倍(越快越好),能够准确预测所有简单的 Token。
- 选择助理模型时,唯一的限制是它必须与主模型共用相同的词汇库。也就是说,助理模型需要使用与主模型完全相同的 Tokenizer。
链接:https://baoyu.io/translations/huggingface/whisper-speculative-decoding

















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









