






李宏毅机器学习HW6
一、任务介绍
1、GAN
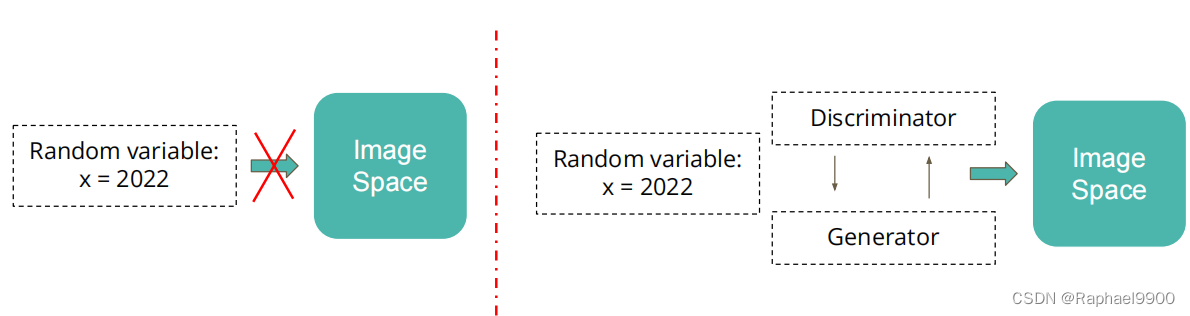
(1)当你想将一些随机变量投射到特定的空间中时
(2)GAN架构: Generator 和 Discriminator
2、动漫面孔生成
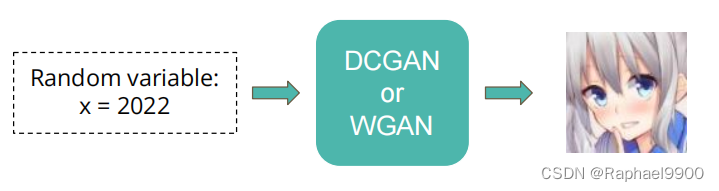
(1)输入:随机数字
(2)输出:动漫面孔图片
(3)实现要求: DCGAN & WGAN & WGAN-GP
(4)目标:生成1000个动画人脸图像
3、评估指标
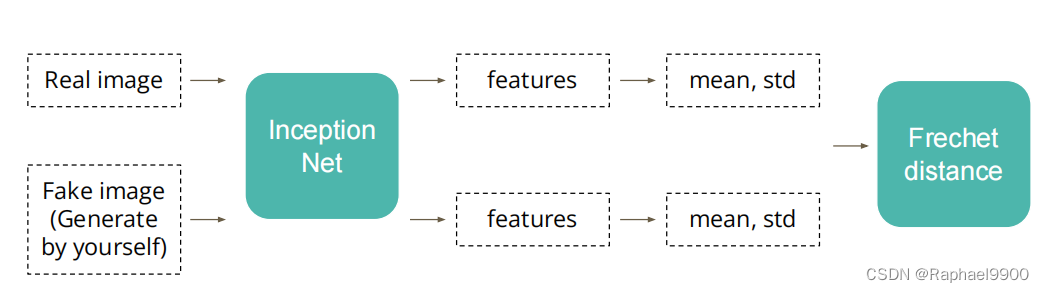
(1)FID(Frechet Inception Distance)得分
·使用另一个模型来为真实的和虚假的图像创建特性
·计算两个特征分布之间的 Frechet distance
(2)评估指标AFD率(动漫人脸检测)
·来检测在你的提交中有多少个动画面孔
·该值越高越好
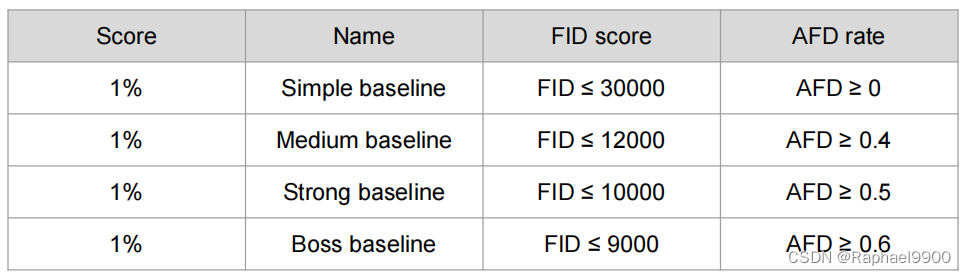
因为作业提交已截止,所以这些分数不能提交得到,这里就做简单的分析吧。可以看到从不同的baseline里面,分数会有差异,BOSS baseline可能是最好的,也就是说BOSS baseline更有可能生成更多的人脸。从FID看,可以看出两个数据样本的差异在随着baseline的提高而减小,也就是说两个样本的数据越来越接近。也就是说我们希望GAN训练一个FID score比较低,AFD rate比较高的模型。
4、数据集
数据集:Crypko
(1)数据集链接在colab中。
(2)数据集格式如图。
(3)在文件夹中有71,314张图片。
(4)您可以使用其他数据来提高性能。


报告问题
1、描述WGAN*和GAN**之间的区别,列出至少两个区别
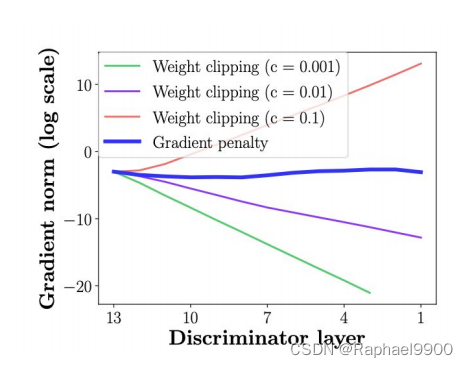
2、请绘制出“梯度范数”的结果
a.使用训练数据集,将鉴别器层数设置为4(最低要求)
b.画出图中的两个设置:i.重量剪裁weight clipping ii.梯度惩罚gradient penalty
c.Y轴:梯度标准数(对数尺度),X轴:discriminator层数(从低到高)
介绍
DCGAN
例程所用就是DCGAN,使用连续卷积层生成图像:

WGAN
a.从DCGAN a中进行修改。从鉴别器中删除最后一个s型图层。
b.在计算损失时,不要取对数。
c.将鉴别器的权值夹取到一个常数(1 ~ -1)。
d.使用RMSProp或SGD作为优化器。
WGAN-GP
从WGAN中进行修改
a.使用梯度惩罚来替换重量裁剪
b.梯度惩罚从一个插值的图像累积梯度
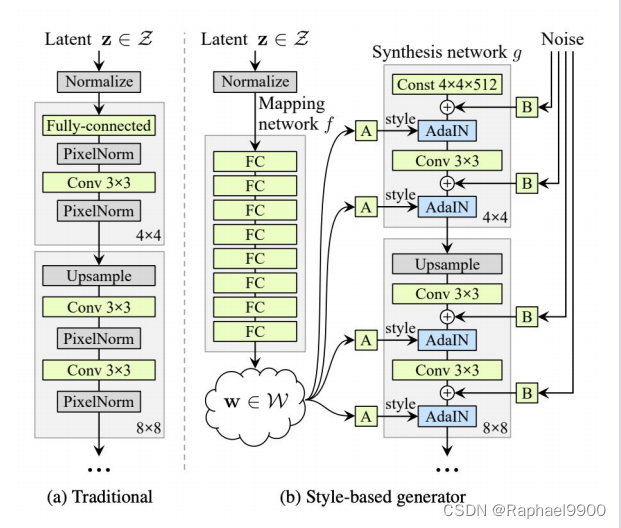
StyleGAN
a.首先将潜变量z变换为w
b.在生成器的不同阶段使用w(处理不同的分辨率)
二、实验结果
1、Simple Baseline (score>14.58)
不修改初始参数,直接运行助教代码:
config = {
"model_type": "GAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 1,
"n_critic": 1,
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
}
一个epoch,生成的图片很模糊,而且有很多重复图片。loss_D=0.216,loss_G=7.75。可以看出来generator的错误率比较高,但是discriminator错误率低,generator大概率不能打败descriminator。

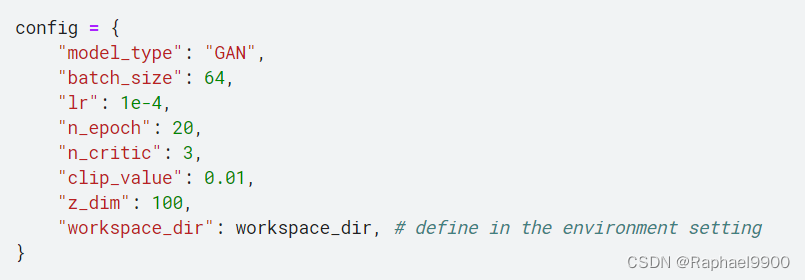
2、Medium Baseline (score>18.04)
修改n_epoch和n_critic。上面的simple baseline是运行一个epoch结果不是很理想。那我尝试运行更多的epoch,在config中设置epoch=50。每更新一次generator,更新三次discriminator,即设置n_critic=3。
config = {
"model_type": "GAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 50,
"n_critic": 3,
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
}

















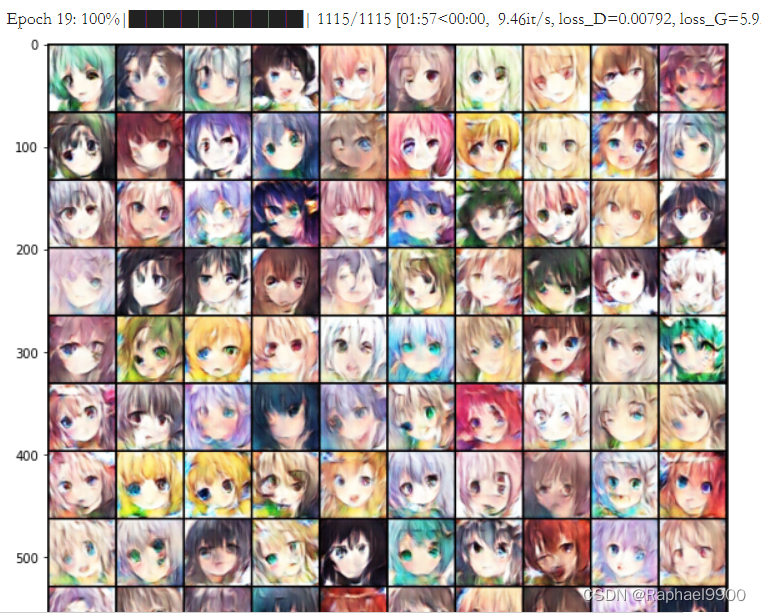
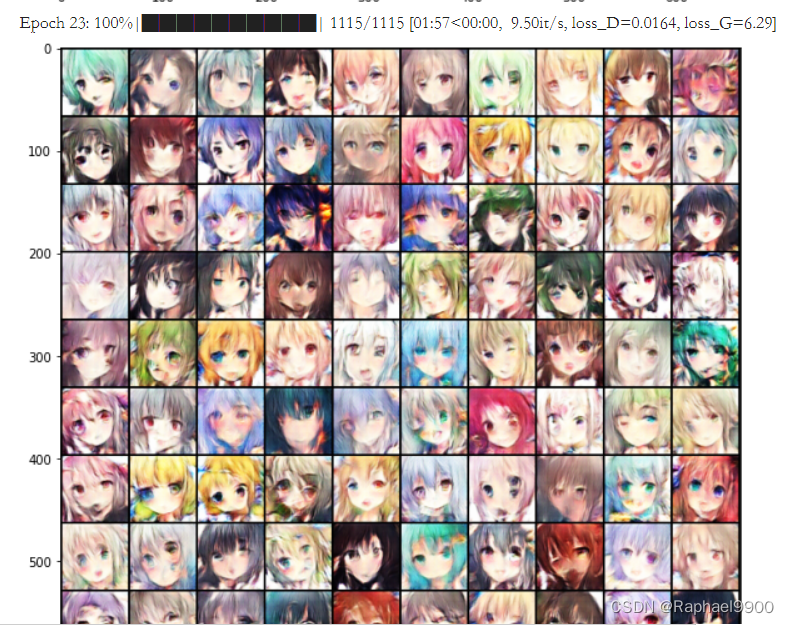
前面的训练虽然在波动,但是情况还是在变好的。有一些生成的脸很奇怪,会有三个眼睛,而descriminator能一直保持loss在都小于1,但是generator的loss就在0-10之间。generator生成的图片大概率不能瞒过discriminator的眼睛。
而下面第24次epoch,loss_D很接近0,而loss_G达到了34.2!用肉眼也可以看见每张图片都有相似的模糊。
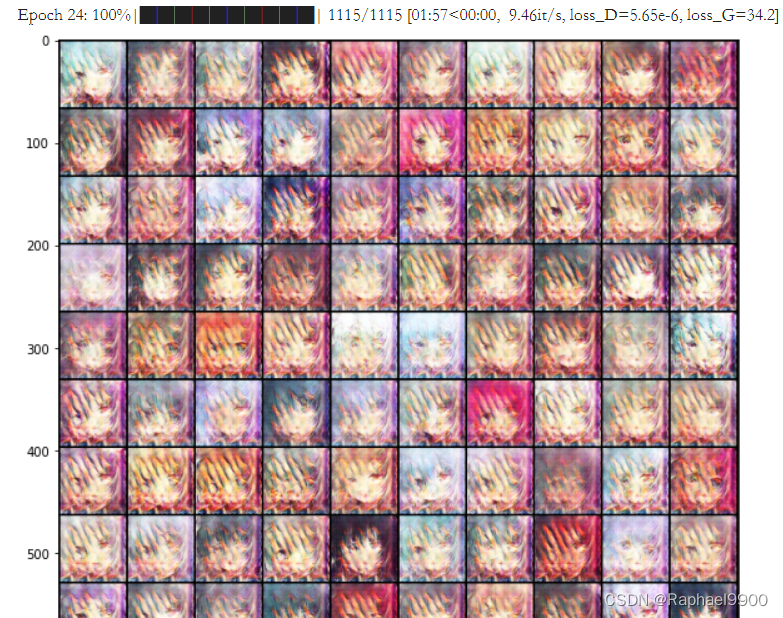
再训练之后,可以看到G的loss变小了,图片也逐渐清晰。
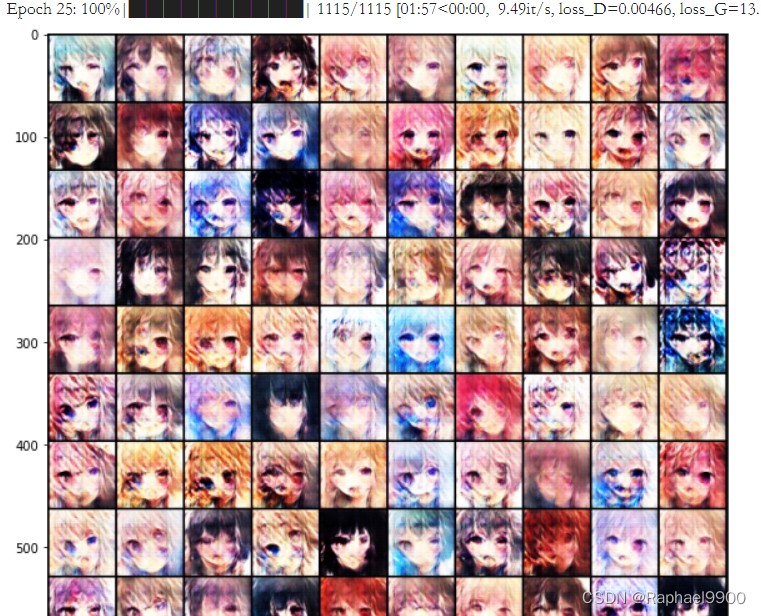



然而到了32 epoch,训练又出现很大的错误,之后就训练不起来了。

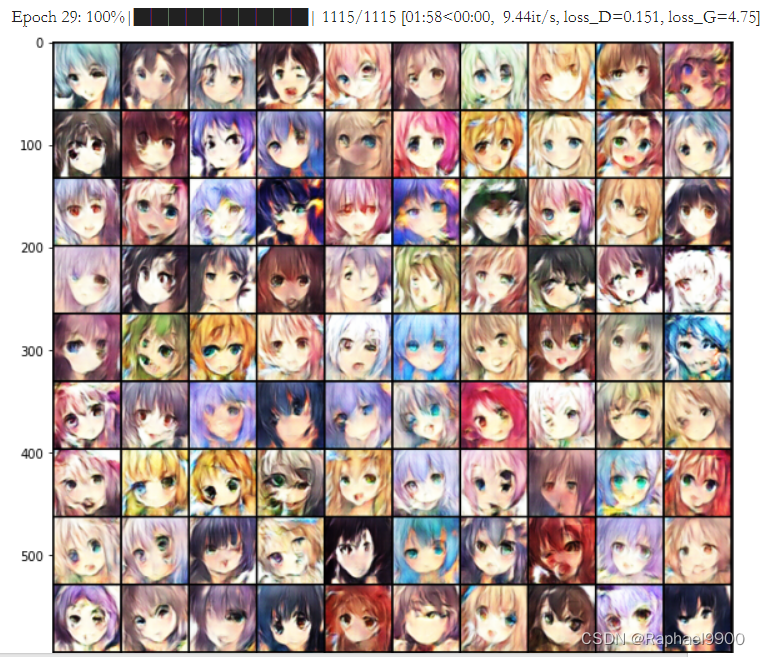
3、Strong Baseline (score>25.20)
使用WGAN weight clipping,需要修改discriminator+修改RMSprop optimizer+修改loss_D、loss_G+增加weight clipping+增加epoch+设置clip_value。
(1)因为WGAN的思路是将discriminator训练为距离函数,所以discriminator不需要最后的非线性sigmoid层。
self.l1 = nn.Sequential(
nn.Conv2d(in_dim, feature_dim, kernel_size=4, stride=2, padding=1), #(batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), #(batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), #(batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), #(batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
#nn.Sigmoid()
)
(2)WGAN
weight clipping优化器一般使用RMSprop效果较好。

(3)将generator和discriminator中的loss函数改为距离。


(4)做weight clipping操作。

(5)第五需要在config中设置clip_value项,同时增加epoch,修改descriminator每次做3个。
结果比DCGAN好,但是生成结果也不稳定。
三、代码
Generative Adversarial Network------HW6
1、环境设置
# import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import numpy as np
import logging
from tqdm import tqdm
# seed setting
def same_seeds(seed):
# Python built-in random module
random.seed(seed)
# Numpy
np.random.seed(seed)
# Torch
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
same_seeds(2022)
workspace_dir = '.'
**为Pytorch准备数据集 **
为了统一图像信息,我们使用变换函数来:
1.将图像大小调整为64x64
2.标准化图像
使用这个CrypkoDataset类
#prepare for CrypkoDataset
class CrypkoDataset(Dataset):
def __init__(self, fnames, transform):
self.transform = transform
self.fnames = fnames
self.num_samples = len(self.fnames)
def __getitem__(self,idx):
fname = self.fnames[idx]
img = torchvision.io.read_image(fname)
img = self.transform(img)
return img
def __len__(self):
return self.num_samples
def get_dataset(root):
fnames = glob.glob(os.path.join(root, '*'))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = CrypkoDataset(fnames, transform)
return dataset
2、创建模型(generator和discriminator)
#Generator
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
#input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU()
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(feature_dim * 8, feature_dim * 4), #(batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(feature_dim * 4, feature_dim * 2), #(batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(feature_dim * 2, feature_dim), #(batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(feature_dim, 3, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False),
nn.Tanh()
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False), #double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True)
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y
# Discriminator
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
#input: (batch, 3, 64, 64)
"""
NOTE FOR SETTING DISCRIMINATOR:
Remove last sigmoid layer for WGAN
"""
self.l1 = nn.Sequential(
nn.Conv2d(in_dim, feature_dim, kernel_size=4, stride=2, padding=1), #(batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), #(batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), #(batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), #(batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
"""
NOTE FOR SETTING DISCRIMINATOR:
You can't use nn.Batchnorm for WGAN-GP
Use nn.InstanceNorm2d instead
"""
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y
# setting for weight init function
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
3、创建trainer
将创建一个包含以下功能的trainer:
1.prepare_environment:准备整体环境,构建模型,为日志和检查点创建目录
2.train:训练生成器和鉴别器,你可以试着修改这里的代码来构造WGAN或WGAN-GP
3.inference:训练之后,您可以将生成器ckpt路径传递给它,函数将为您保存结果
class TrainerGAN():
def __init__(self, config):
self.config = config
self.G = Generator(100)
self.D = Discriminator(3)
self.loss = nn.BCELoss()
"""
NOTE FOR SETTING OPTIMIZER:
GAN: use Adam optimizer
WGAN: use RMSprop optimizer
WGAN-GP: use Adam optimizer
"""
self.opt_D = torch.optim.Adam(self.D.parameters(), lr=self.config["lr"], betas=(0.5, 0.999))
self.opt_G = torch.optim.Adam(self.G.parameters(), lr=self.config["lr"], betas=(0.5, 0.999))
self.dataloader = None
self.log_dir = os.path.join(self.config["workspace_dir"], 'logs')
self.ckpt_dir = os.path.join(self.config["workspace_dir"], 'checkpoints')
FORMAT = '%(asctime)s - %(levelname)s: %(message)s'
logging.basicConfig(level=logging.INFO,
format=FORMAT,
datefmt='%Y-%m-%d %H:%M')
self.steps = 0
self.z_samples = Variable(torch.randn(100, self.config["z_dim"])).cuda()
def prepare_environment(self):
"""
Use this funciton to prepare function
"""
os.makedirs(self.log_dir, exist_ok=True)
os.makedirs(self.ckpt_dir, exist_ok=True)
# update dir by time
time = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
self.log_dir = os.path.join(self.log_dir, time+f'_{self.config["model_type"]}')
self.ckpt_dir = os.path.join(self.ckpt_dir, time+f'_{self.config["model_type"]}')
os.makedirs(self.log_dir)
os.makedirs(self.ckpt_dir)
# create dataset by the above function
dataset = get_dataset(os.path.join(self.config["workspace_dir"], 'faces'))
self.dataloader = DataLoader(dataset, batch_size=self.config["batch_size"], shuffle=True, num_workers=2)
# model preparation
self.G = self.G.cuda()
self.D = self.D.cuda()
self.G.train()
self.D.train()
def gp(self):
"""
Implement gradient penalty function
"""
pass
def train(self):
"""
Use this function to train generator and discriminator
"""
self.prepare_environment()
for e, epoch in enumerate(range(self.config["n_epoch"])):
progress_bar = tqdm(self.dataloader)
progress_bar.set_description(f"Epoch {e+1}")
for i, data in enumerate(progress_bar):
imgs = data.cuda()
bs = imgs.size(0)
# *********************
# * Train D *
# *********************
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
r_imgs = Variable(imgs).cuda()
f_imgs = self.G(z)
r_label = torch.ones((bs)).cuda()
f_label = torch.zeros((bs)).cuda()
# Discriminator forwarding
r_logit = self.D(r_imgs)
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING DISCRIMINATOR LOSS:
GAN:
loss_D = (r_loss + f_loss)/2
WGAN:
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
WGAN-GP:
gradient_penalty = self.gp(r_imgs, f_imgs)
loss_D = -torch.mean(r_logit) + torch.mean(f_logit) + gradient_penalty
"""
# Loss for discriminator
r_loss = self.loss(r_logit, r_label)
f_loss = self.loss(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
# Discriminator backwarding
self.D.zero_grad()
loss_D.backward()
self.opt_D.step()
"""
NOTE FOR SETTING WEIGHT CLIP:
WGAN: below code
"""
# for p in self.D.parameters():
# p.data.clamp_(-self.config["clip_value"], self.config["clip_value"])
# *********************
# * Train G *
# *********************
if self.steps % self.config["n_critic"] == 0:
# Generate some fake images.
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
f_imgs = self.G(z)
# Generator forwarding
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING LOSS FOR GENERATOR:
GAN: loss_G = self.loss(f_logit, r_label)
WGAN: loss_G = -torch.mean(self.D(f_imgs))
WGAN-GP: loss_G = -torch.mean(self.D(f_imgs))
"""
# Loss for the generator.
loss_G = self.loss(f_logit, r_label)
# Generator backwarding
self.G.zero_grad()
loss_G.backward()
self.opt_G.step()
if self.steps % 10 == 0:
progress_bar.set_postfix(loss_G=loss_G.item(), loss_D=loss_D.item())
self.steps += 1
self.G.eval()
f_imgs_sample = (self.G(self.z_samples).data + 1) / 2.0
filename = os.path.join(self.log_dir, f'Epoch_{epoch+1:03d}.jpg')
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10,10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
self.G.train()
if (e+1) % 5 == 0 or e == 0:
# Save the checkpoints.
torch.save(self.G.state_dict(), os.path.join(self.ckpt_dir, f'G_{e}.pth'))
torch.save(self.D.state_dict(), os.path.join(self.ckpt_dir, f'D_{e}.pth'))
logging.info('Finish training')
def inference(self, G_path, n_generate=1000, n_output=30, show=False):
"""
1. G_path is the path for Generator ckpt
2. You can use this function to generate final answer
"""
self.G.load_state_dict(torch.load(G_path))
self.G.cuda()
self.G.eval()
z = Variable(torch.randn(n_generate, self.config["z_dim"])).cuda()
imgs = (self.G(z).data + 1) / 2.0
os.makedirs('output', exist_ok=True)
for i in range(n_generate):
torchvision.utils.save_image(imgs[i], f'output/{i+1}.jpg')
if show:
row, col = n_output//10 + 1, 10
grid_img = torchvision.utils.make_grid(imgs[:n_output].cpu(), nrow=row)
plt.figure(figsize=(row, col))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
训练
config = {
"model_type": "GAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 1,
"n_critic": 1,
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
}
trainer = TrainerGAN(config)
trainer.train()














 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









