






源代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR
writer = SummaryWriter(log_dir='runs/Log_SGDAndSchedulers_3')
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints')
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)")
args = parser.parse_args()
# 超参数设置
EPOCH = 50
pre_epoch = 0 # 添加 pre_epoch 的定义
BATCH_SIZE = 128
LR = 0.1
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 初始化学习率调度器
scheduler = CosineAnnealingLR(optimizer, T_max=EPOCH)
# 训练
if __name__ == "__main__":
best_acc = 85
print("Start Training, Resnet-18!")
with open("acc.txt", "w") as f:
with open("log.txt", "w") as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
scheduler.step() # 更新学习率(余弦退火)
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
test_loss = 0.0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
test_loss /= len(testloader)
acc = 100. * correct / total
print('测试分类准确率为:%.3f%%' % acc)
print('测试平均损失为:%.3f' % test_loss)
writer.add_scalar("Accuracy/test", acc, epoch)
writer.add_scalar("Loss/test", test_loss, epoch)
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
writer.close()
将SGD优化器改为Adam
代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
from torch.utils.tensorboard import SummaryWriter
import random
import time
writer = SummaryWriter(log_dir='runs/Adam')
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #输出结果保存路径
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") #恢复训练时的模型路径
args = parser.parse_args()
# 超参数设置
EPOCH = 50 #遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
BATCH_SIZE = 128 #批处理尺寸(batch_size)
LR = 0.01 #学习率
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
validset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform_test)
validloader = torch.utils.data.DataLoader(validset, batch_size=100, shuffle=False, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# Cifar-10的标签
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=LR, weight_decay=5e-4) # 使用Adam优化器
# 记录初始学习率
for param_group in optimizer.param_groups:
writer.add_scalar("Learning Rate", param_group['lr'], 0)
# 训练
if __name__ == "__main__":
best_acc = 85
print("Start Training, Resnet-18!")
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
test_loss = 0.0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
test_loss /= len(testloader)
acc = 100. * correct / total
print('测试分类准确率为:%.3f%%' % acc)
print('测试平均损失为:%.3f' % test_loss)
writer.add_scalar("Accuracy/test", acc, epoch)
writer.add_scalar("Loss/test", test_loss, epoch)
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
# 关闭writer
writer.close()
图像
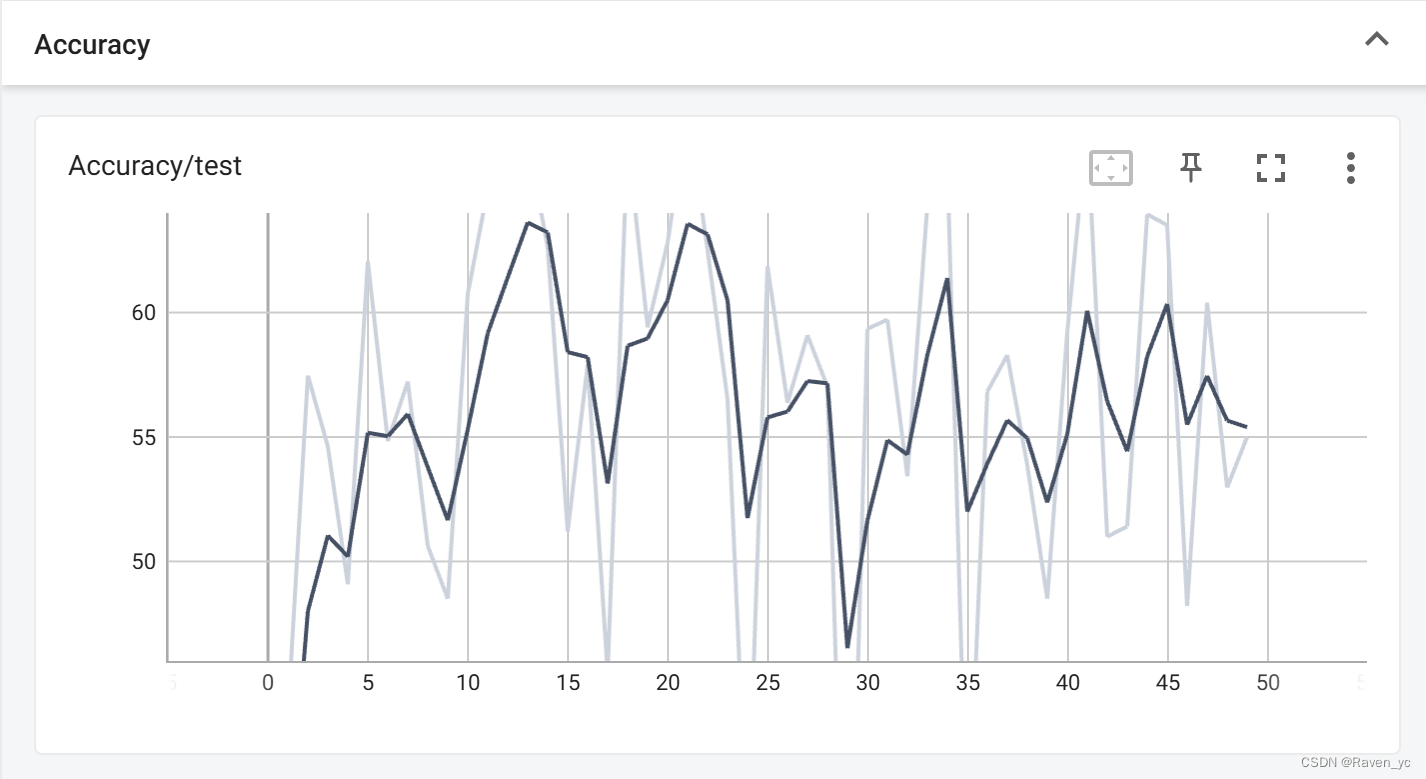
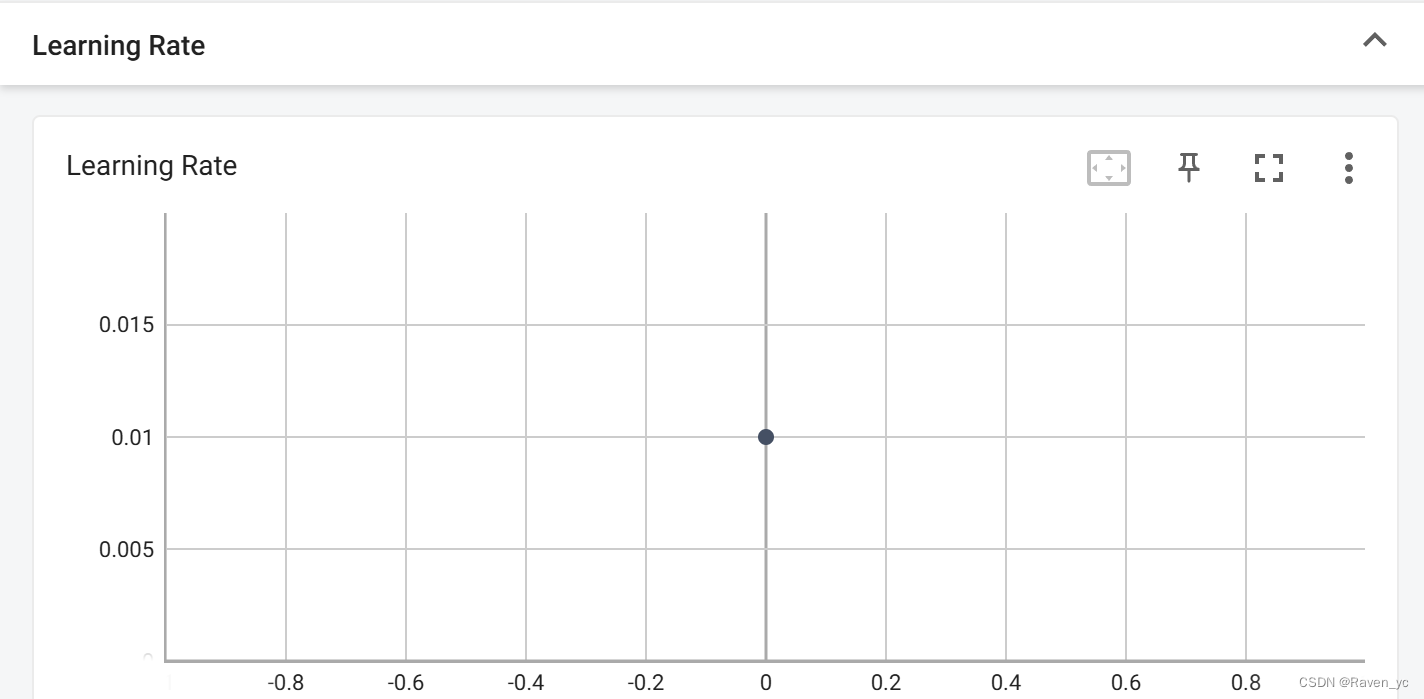
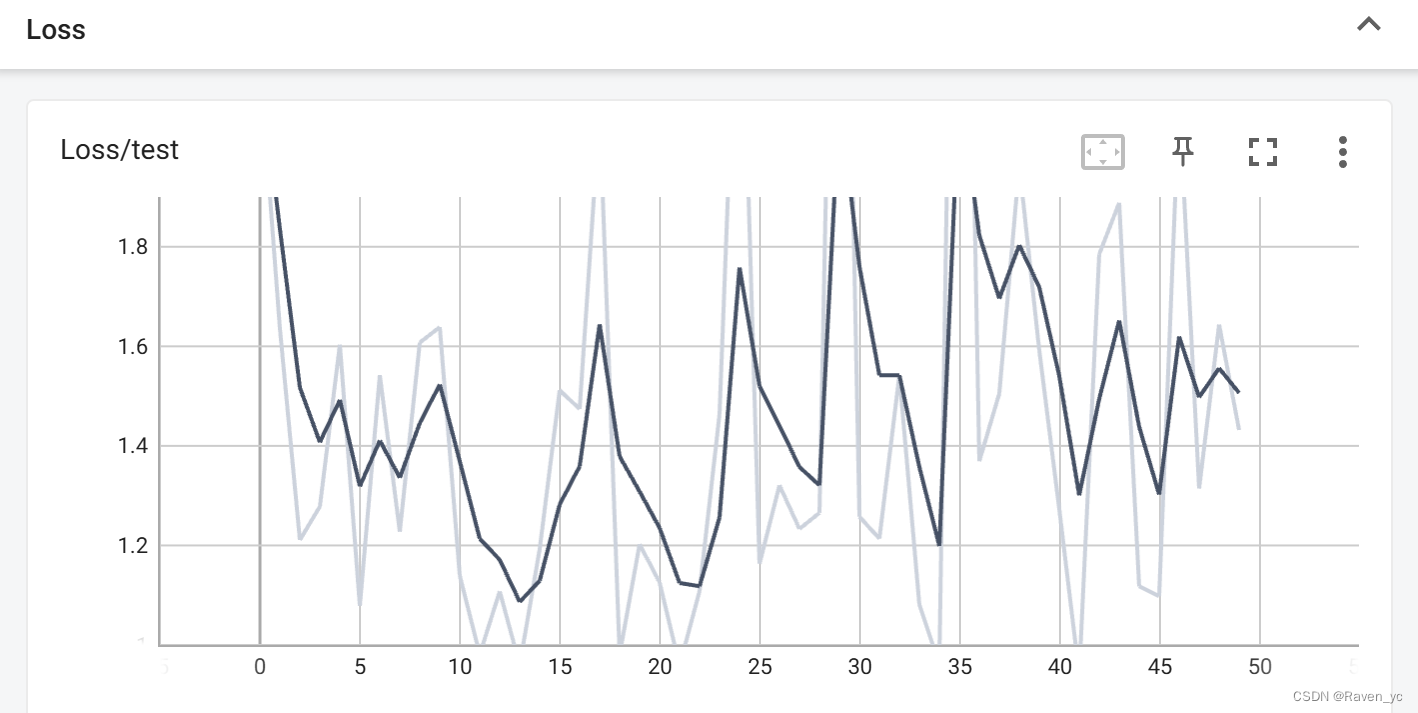
SGD优化器并使用CosineAnnealingLR 和 ReduceLROnPlateau调整学习率
代码
在这段代码中,我使用了 SGD 优化器,并设置了动量。同时,结合了 CosineAnnealingLR 和 ReduceLROnPlateau 两种调度器,前者根据余弦曲线自动调整学习率,后者根据验证集的性能(如损失不再下降)调整学习率。这种组合有助于在训练过程中适应不同阶段的需求。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR, ReduceLROnPlateau
writer = SummaryWriter(log_dir='runs/Log_SGDAndSchedulers_3')
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints')
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)")
args = parser.parse_args()
# 超参数设置
EPOCH = 50
pre_epoch = 0 # 添加 pre_epoch 的定义
BATCH_SIZE = 128
LR = 0.1
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 初始化学习率调度器
scheduler_cosine = CosineAnnealingLR(optimizer, T_max=EPOCH)
scheduler_plateau = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10)
# 训练
if __name__ == "__main__":
best_acc = 85
print("Start Training, Resnet-18!")
with open("acc.txt", "w") as f:
with open("log.txt", "w") as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
scheduler_cosine.step() # 更新学习率(余弦退火)
scheduler_plateau.step(sum_loss) # 每个epoch结束后检查是否需要通过plateau调整学习率
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
test_loss = 0.0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
test_loss /= len(testloader)
acc = 100. * correct / total
print('测试分类准确率为:%.3f%%' % acc)
print('测试平均损失为:%.3f' % test_loss)
writer.add_scalar("Accuracy/test", acc, epoch)
writer.add_scalar("Loss/test", test_loss, epoch)
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
writer.close()
结果
EPOCH=001,Accuracy= 39.310%
EPOCH=002,Accuracy= 47.420%
EPOCH=003,Accuracy= 56.670%
EPOCH=004,Accuracy= 66.260%
EPOCH=005,Accuracy= 66.380%
EPOCH=006,Accuracy= 73.890%
EPOCH=007,Accuracy= 76.840%
EPOCH=008,Accuracy= 75.420%
EPOCH=009,Accuracy= 80.520%
EPOCH=010,Accuracy= 79.710%
EPOCH=011,Accuracy= 79.330%
EPOCH=012,Accuracy= 74.160%
EPOCH=013,Accuracy= 82.560%
EPOCH=014,Accuracy= 78.710%
EPOCH=015,Accuracy= 77.590%
EPOCH=016,Accuracy= 79.860%
EPOCH=017,Accuracy= 84.960%
EPOCH=018,Accuracy= 84.780%
EPOCH=019,Accuracy= 84.370%
EPOCH=020,Accuracy= 85.880%
EPOCH=021,Accuracy= 85.250%
EPOCH=022,Accuracy= 84.260%
EPOCH=023,Accuracy= 83.670%
EPOCH=024,Accuracy= 84.290%
EPOCH=025,Accuracy= 87.520%
EPOCH=026,Accuracy= 87.210%
EPOCH=027,Accuracy= 85.560%
EPOCH=028,Accuracy= 88.210%
EPOCH=029,Accuracy= 87.010%
EPOCH=030,Accuracy= 88.680%
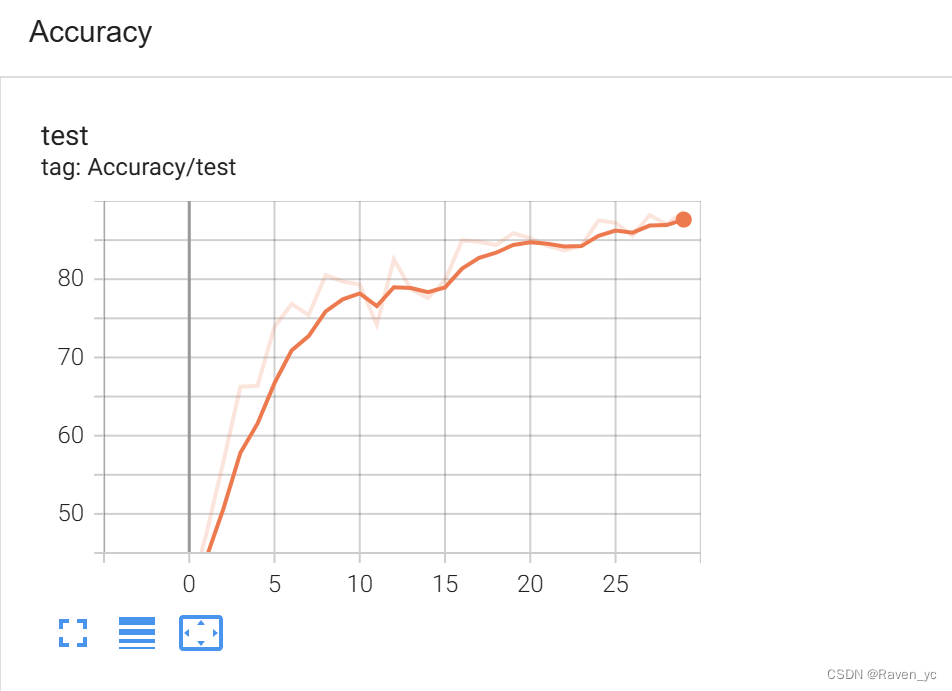
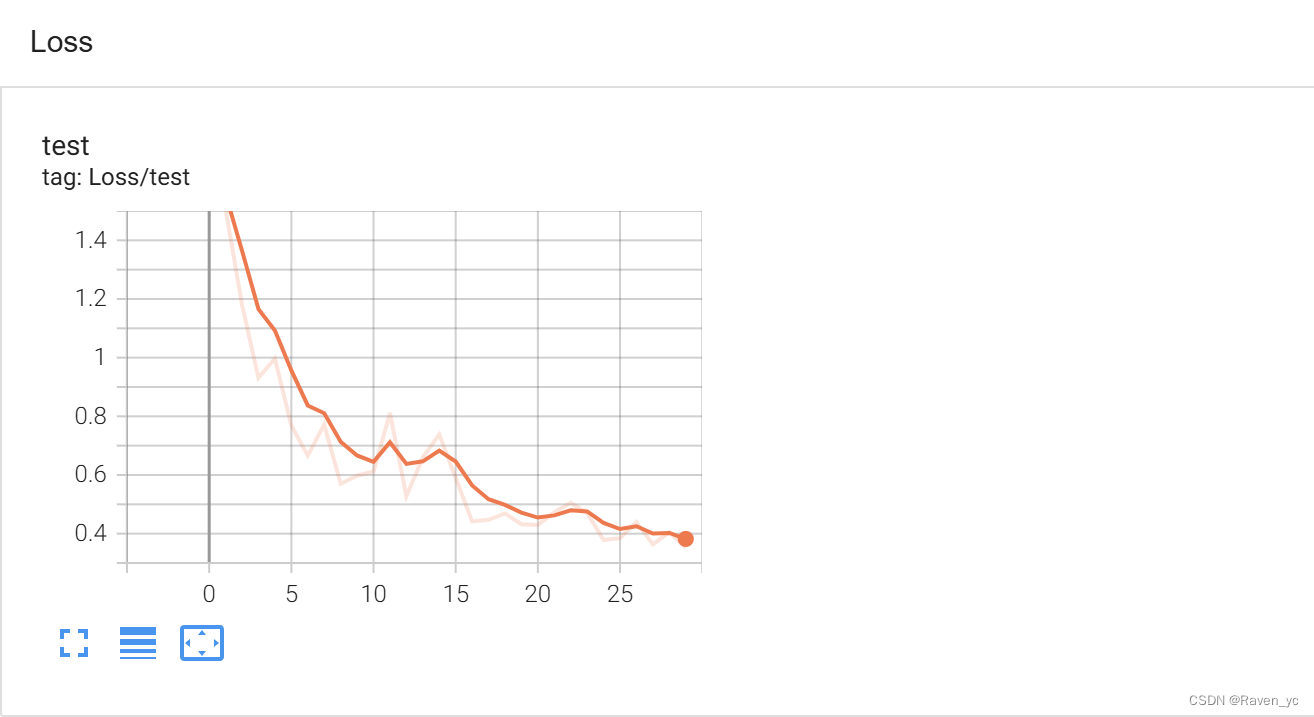
SGD优化器+ 只使用 CosineAnnealingLR学习率调度器
代码
- 删除了
ReduceLROnPlateau调度器的初始化和相关代码,只保留CosineAnnealingLR调度器。 - 确保
scheduler只使用CosineAnnealingLR并在每个 epoch 结束后调用scheduler.step()进行更新。
通过这段代码,你可以仅使用 CosineAnnealingLR 调度器来实验模型的效果。运行代码并观察 TensorBoard 中记录的准确率和损失,以评估使用该调度器时的性能表现。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import CosineAnnealingLR
writer = SummaryWriter(log_dir='runs/Log_SGDAndSchedulers_3')
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints')
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)")
args = parser.parse_args()
# 超参数设置
EPOCH = 50
pre_epoch = 0 # 添加 pre_epoch 的定义
BATCH_SIZE = 128
LR = 0.1
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 初始化学习率调度器
scheduler = CosineAnnealingLR(optimizer, T_max=EPOCH)
# 训练
if __name__ == "__main__":
best_acc = 85
print("Start Training, Resnet-18!")
with open("acc.txt", "w") as f:
with open("log.txt", "w") as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
scheduler.step() # 更新学习率(余弦退火)
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
test_loss = 0.0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
test_loss /= len(testloader)
acc = 100. * correct / total
print('测试分类准确率为:%.3f%%' % acc)
print('测试平均损失为:%.3f' % test_loss)
writer.add_scalar("Accuracy/test", acc, epoch)
writer.add_scalar("Loss/test", test_loss, epoch)
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
writer.close()
结果
EPOCH=001,Accuracy= 42.310%
EPOCH=002,Accuracy= 47.890%
EPOCH=003,Accuracy= 64.050%
EPOCH=004,Accuracy= 65.870%
EPOCH=005,Accuracy= 67.530%
EPOCH=006,Accuracy= 74.500%
EPOCH=007,Accuracy= 75.850%
EPOCH=008,Accuracy= 77.010%
EPOCH=009,Accuracy= 75.640%
EPOCH=010,Accuracy= 80.280%
EPOCH=011,Accuracy= 78.570%
EPOCH=012,Accuracy= 78.440%
EPOCH=013,Accuracy= 81.430%
EPOCH=014,Accuracy= 78.180%
EPOCH=015,Accuracy= 81.310%
EPOCH=016,Accuracy= 81.330%
EPOCH=017,Accuracy= 82.780%
EPOCH=018,Accuracy= 84.130%
EPOCH=019,Accuracy= 86.330%
EPOCH=020,Accuracy= 85.930%
EPOCH=021,Accuracy= 83.240%
EPOCH=022,Accuracy= 85.170%
EPOCH=023,Accuracy= 84.940%
EPOCH=024,Accuracy= 87.320%
EPOCH=025,Accuracy= 85.530%
EPOCH=026,Accuracy= 87.830%
EPOCH=027,Accuracy= 88.000%
EPOCH=028,Accuracy= 86.530%
EPOCH=029,Accuracy= 86.850%
EPOCH=030,Accuracy= 88.650%
EPOCH=031,Accuracy= 88.960%
EPOCH=032,Accuracy= 89.220%
EPOCH=033,Accuracy= 89.670%
EPOCH=034,Accuracy= 90.310%
EPOCH=035,Accuracy= 90.220%
EPOCH=036,Accuracy= 90.890%
EPOCH=037,Accuracy= 91.430%
EPOCH=038,Accuracy= 91.570%
EPOCH=039,Accuracy= 92.370%
EPOCH=040,Accuracy= 92.770%
EPOCH=041,Accuracy= 92.960%
EPOCH=042,Accuracy= 93.420%
EPOCH=043,Accuracy= 93.540%
EPOCH=044,Accuracy= 93.810%
EPOCH=045,Accuracy= 93.930%
EPOCH=046,Accuracy= 94.010%
EPOCH=047,Accuracy= 94.110%
EPOCH=048,Accuracy= 94.060%
EPOCH=049,Accuracy= 93.970%
EPOCH=050,Accuracy= 94.120%
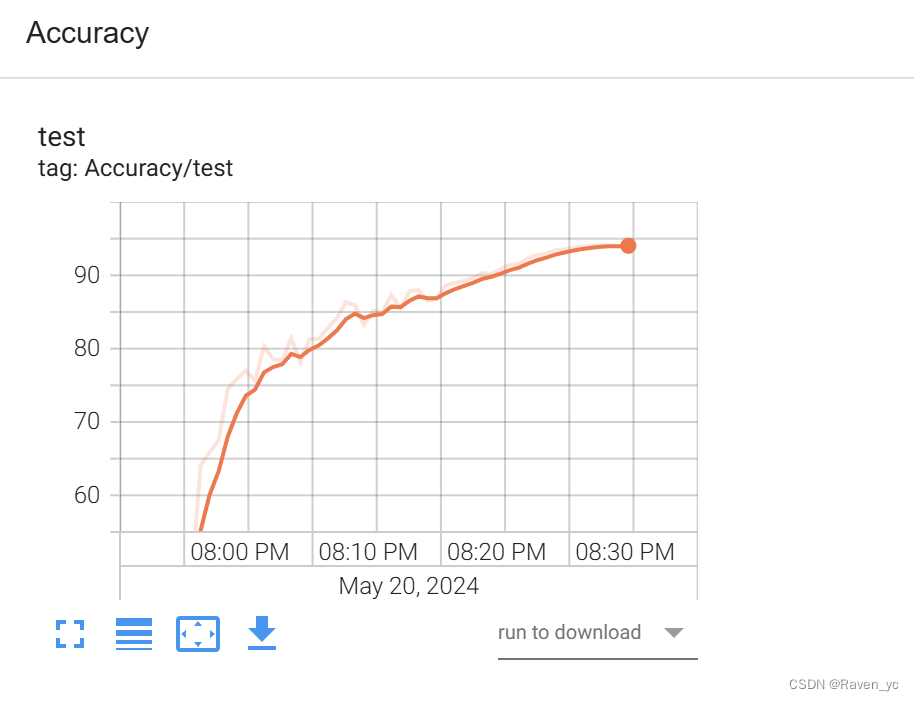
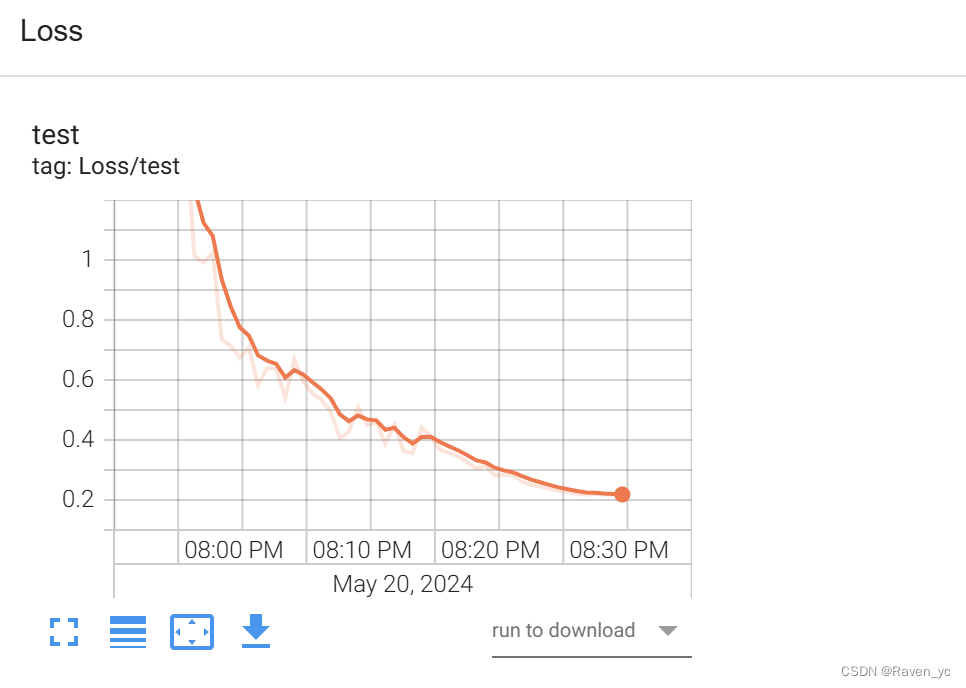
SGD优化器+只使用 ReduceLROnPlateau 学习率调度器
代码
在这段代码中,我们只使用了 ReduceLROnPlateau 学习率调度器。每个 epoch 结束后,根据 sum_loss 调整学习率。其他部分保持不变。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
from torch.utils.tensorboard import SummaryWriter
from torch.optim.lr_scheduler import ReduceLROnPlateau
writer = SummaryWriter(log_dir='runs/Log_SGDAndSchedulers_3')
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints')
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)")
args = parser.parse_args()
# 超参数设置
EPOCH = 50
pre_epoch = 0 # 添加 pre_epoch 的定义
BATCH_SIZE = 128
LR = 0.1
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 初始化学习率调度器
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10)
# 训练
if __name__ == "__main__":
best_acc = 85
print("Start Training, Resnet-18!")
with open("acc.txt", "w") as f:
with open("log.txt", "w") as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * len(trainloader)), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每个epoch结束后检查是否需要通过plateau调整学习率
scheduler.step(sum_loss)
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
test_loss = 0.0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
test_loss /= len(testloader)
acc = 100. * correct / total
print('测试分类准确率为:%.3f%%' % acc)
print('测试平均损失为:%.3f' % test_loss)
writer.add_scalar("Accuracy/test", acc, epoch)
writer.add_scalar("Loss/test", test_loss, epoch)
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
writer.close()

















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









