






书生浦语第二期实战营系列—综述加技术报告研读
书生浦语第二期实战营系列—Tutorial1:demo体验
书生浦语第二期实战营系列—Tutorial2:RAG
书生浦语第二期实战营系列—Tutorial3:Xtuner微调
书生浦语第二期实战营系列—Tutorial4:Lmdeploy量化部署
书生浦语第二期实战营系列—Tutorial5:Agent
书生浦语第二期实战营系列—Tutorial6:OpenCompass
书生浦语第二期实战营学习笔记(作业)(第七节课)
1 模型能力评测和OpenCompass2.0简介
1.1 模型能力评测的意义

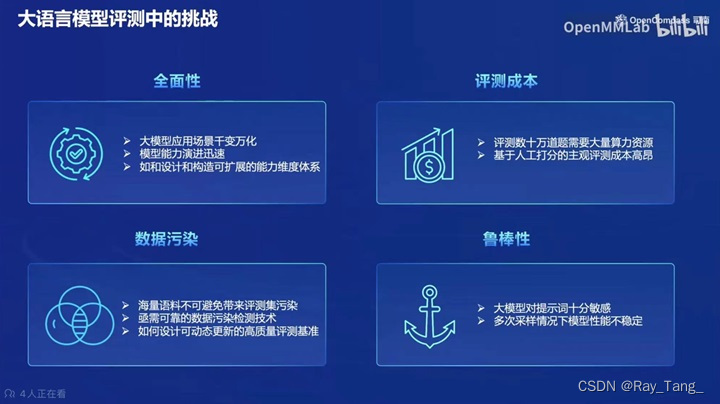
1.2 LLM模型评测的挑战
1.如何全面的评测LLM
2.LLM的评测成本非常高
3.评测的数据污染问题
4.LLM评测结果的鲁棒性
1.3 评测工具OpenCompass2.0

1.3.1 OpenCompass2.0评测方法
OpenCompass可评测
1.基座模型;
2.对话模型;
3.开源模型;
4.开放API的模型;

1.3.2 OpenCompass2.0可主客观评测

1.3.3 OpenCompass2.0提示词工程
OpenCompass2.0对提示词进行改造,以方便得到更准确的结果


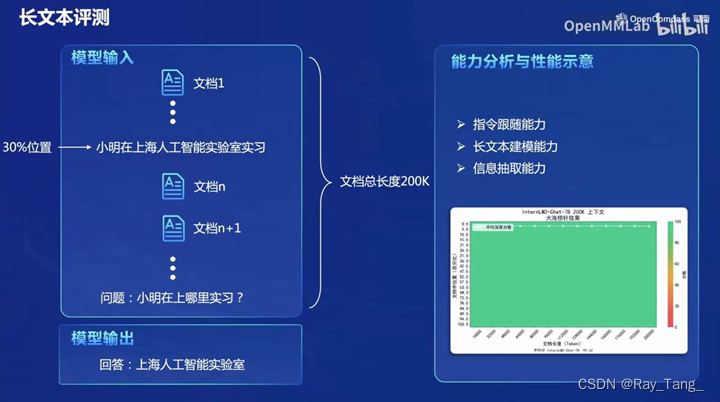
1.3.4 OpenCompass2.0长文本评测
OpenCompass还对模型的长文本能力进行了评测
1.3.4 OpenCompass2.0构建大模型评测全栈工具链
1.数据污染的检查工具;
2.长文本评测工具;
3.丰富的模型推理接口;
4.中英双语主观评测工具;
5.多模态能力评测工具;
6.代码能力评测工具;
7.MoE模型入门工具;


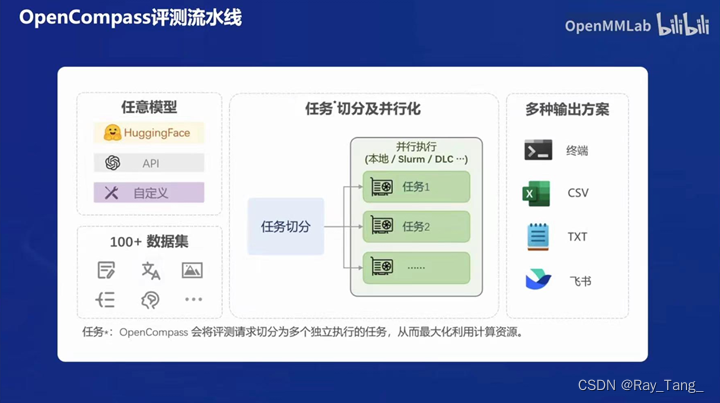
1.3.5 OpenCompass2.0评测pipeline
1.加载模型和评测数据集
2.评测任务切分和并行化
3.评测结果输出
1.3.6 OpenCompass2.0评测基准CompassHub
CompassHub是个开源开放,共建的大模型评测基准社区

1.3.7 OpenCompass2.0评测基准数据集介绍
OpenCompass拥有高质量的大模型评测基准
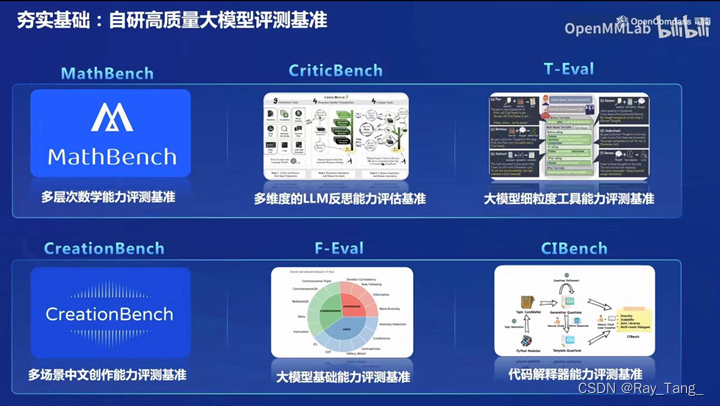
1.MathBench
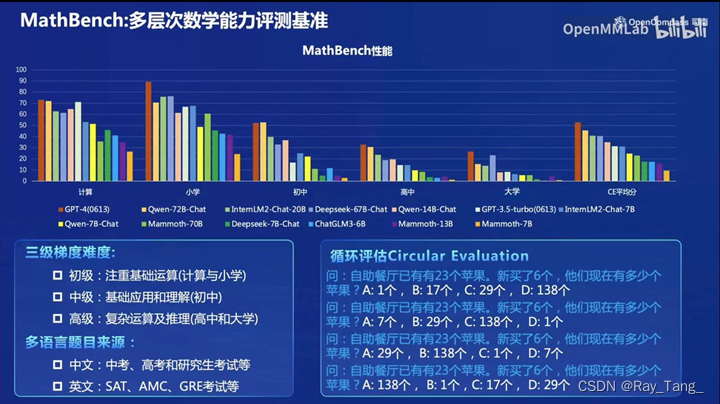
2.CIBench
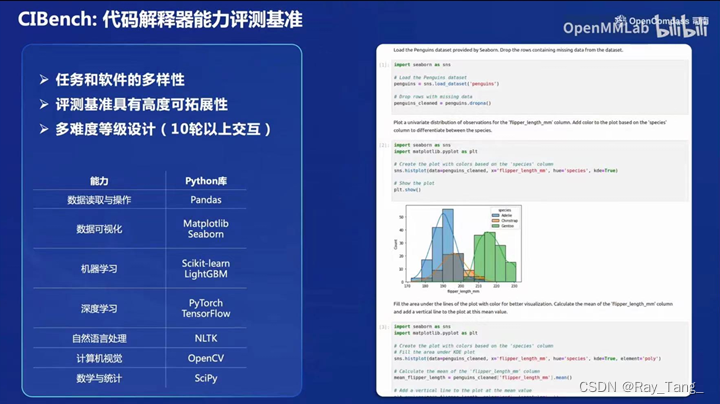
3.T-Eval
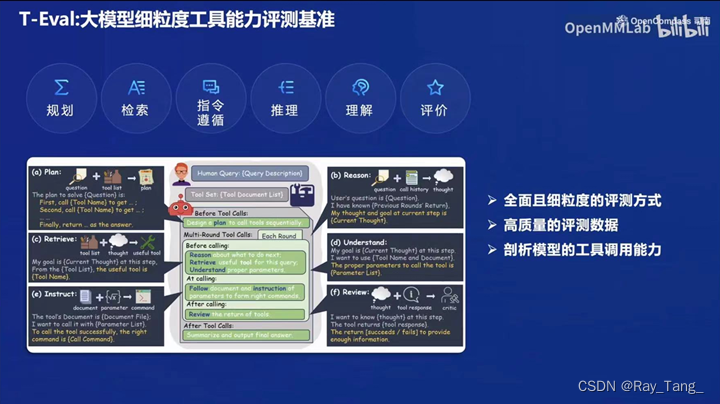
4.OpenFinData、LawBench、MedBench、SecBench

2 OpenCompass 评测 internlm2-chat-1_8b 模型(基础作业)
使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能
2.1 安装环境
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
2.2 准备数据
解压后数据放在data目录下
cp xxx/OpenCompassData-core-20231110.zip ./
unzip OpenCompassData-core-20231110.zip
查看支持的数据集和模型
#列出所有跟 InternLM 及 C-Eval 相关的配置
python tools/list_configs.py internlm ceval
2.3开始评测
2.3.1 创建run.sh脚本
touch run.sh
将下面脚本写入run.sh,放在run.py的同级目录
vim run.sh
#评测脚本
python run.py
--datasets ceval_gen \
--hf-path xxx/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace 模型路径
--tokenizer-path xxx/Shanghai_AI_Laboratory/internlm2-chat-1_8b \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数,pad和truncation方式
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 1024 \ # 模型可以接受的最大序列长度,最大读入的序列
--max-out-len 16 \ # 生成的最大 token 数,做主观题可以加长,客观题开得比较小
--batch-size 2 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
2.3.2 数据软连接
将2.2解压的数据软连接到run.sh同级目录
ln -s xxx/data ./data
2.3.3 启动脚本
chmod 777 -R run.sh
./run.sh
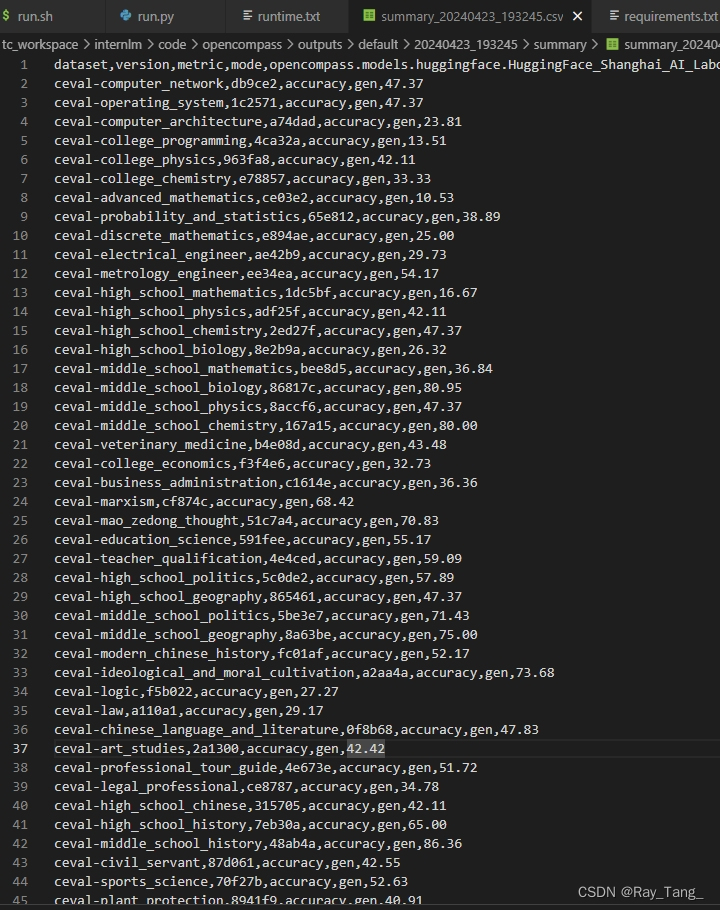
3 将自定义数据集提交至OpenCompass官网(进阶作业)
3.1 建立自己数据集(客观题)
3.1.1 建立数据集文件
在run.sh同级目录data下,执行一下命令
mkdir -p opencompass/data/petEval/dev
mkdir -p opencompass/data/petEval/val
mkdir -p opencompass/data/petEval/test
touch opencompass/data/petEval/dev/pet_dev.csv
touch opencompass/data/petEval/val/pet_val.csv
touch opencompass/data/petEval/test/pet_test.csv
3.1.2 修改数据集文件
1.建立dev数据
vim opencompass/data/petEval/dev/pet_dev.csv

2.建立val数据
vim opencompass/data/petEval/val/pet_val.csv
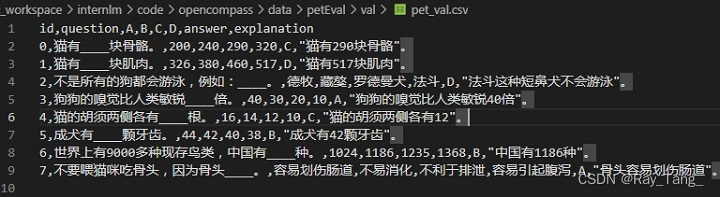
3.建立test数据
vim opencompass/data/petEval/test/pet_test.csv

3.2 建立自己数据集的评测代码
3.2.1 修改opencompass/configs/datasets下代码
mkdir -p opencompass/configs/datasets/pet_knowledge_eval/
vim opencompass/configs/datasets/pet_knowledge_eval/petEval_gen_20240424.py
from opencompass.openicl.icl_prompt_template import PromptTemplate
from opencompass.openicl.icl_retriever import FixKRetriever
from opencompass.openicl.icl_inferencer import GenInferencer
from opencompass.openicl.icl_evaluator import AccEvaluator
from opencompass.datasets import CEvalDataset
from opencompass.datasets import PetEvalDataset
from opencompass.utils.text_postprocessors import first_capital_postprocess
petEval_subject_mapping = {
'pet': ['pet', '宠物', 'STEM'],
}
ceval_all_sets = list(petEval_subject_mapping.keys())
pet_eval_datasets = []
for _split in ["val"]:
for _name in ceval_all_sets:
_ch_name = petEval_subject_mapping[_name][1]
petEval_infer_cfg = dict(
ice_template=dict(
type=PromptTemplate,
template=dict(
begin="</E>",
round=[
dict(
role="HUMAN",
prompt=
f"以下是中国的{_ch_name}考试的单项选择题,请选出其中的正确答案。\n{{question}}\nA. {{A}}\nB. {{B}}\nC. {{C}}\nD. {{D}}\n答案: "
),
dict(role="BOT", prompt="{answer}"),
]),
ice_token="</E>",
),
retriever=dict(type=FixKRetriever, fix_id_list=[]),
inferencer=dict(type=GenInferencer),
)
petEval_eval_cfg = dict(
evaluator=dict(type=AccEvaluator),
pred_postprocessor=dict(type=first_capital_postprocess))
pet_eval_datasets.append(
dict(
type=PetEvalDataset,
path="./data/petEval/",
name=_name,
abbr="petEval-" + _name if _split == "val" else "petEval-test-" +
_name,
reader_cfg=dict(
input_columns=["question", "A", "B", "C", "D"],
output_column="answer",
train_split="dev",
test_split=_split),
infer_cfg=petEval_infer_cfg,
eval_cfg=petEval_eval_cfg,
))
del _split, _name, _ch_name
vim opencompass/configs/datasets/pet_knowledge_eval/petEval_gen.py
from mmengine.config import read_base
with read_base():
from .petEval_gen_20240424 import pet_eval_datasets # noqa: F401, F403
3.2.2 修改opencompass/opencompass/datasets下代码
1.实现这个类中的load方法
import csv
import json
import os.path as osp
from datasets import Dataset, DatasetDict
from opencompass.registry import LOAD_DATASET
from .base import BaseDataset
@LOAD_DATASET.register_module()
class PetEvalDataset(BaseDataset):
@staticmethod
def load(path: str, name: str):
dataset = {}
for split in ['dev', 'val', 'test']:
filename = osp.join(path, split, f'{name}_{split}.csv')
# if not (osp.exists(filename)):
# continue
with open(filename, encoding='utf-8') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
item = dict(zip(header, row))
item.setdefault('explanation', '')
item.setdefault('answer', '')
dataset.setdefault(split, []).append(item)
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
return DatasetDict(dataset)
class PetEvalDatasetClean(BaseDataset):
# load the contamination annotations of CEval from
# https://github.com/liyucheng09/Contamination_Detector
@staticmethod
def load_contamination_annotations(path, split='val'):
import requests
assert split == 'val', 'Now we only have annotations for val set'
annotation_cache_path = osp.join(
path, split, 'ceval_contamination_annotations.json')
if osp.exists(annotation_cache_path):
with open(annotation_cache_path, 'r') as f:
annotations = json.load(f)
return annotations
link_of_annotations = 'https://github.com/liyucheng09/Contamination_Detector/releases/download/v0.1.1rc/ceval_annotations.json' # noqa
annotations = json.loads(requests.get(link_of_annotations).text)
with open(annotation_cache_path, 'w') as f:
json.dump(annotations, f)
return annotations
@staticmethod
def load(path: str, name: str):
dataset = {}
for split in ['dev', 'val', 'test']:
if split == 'val':
annotations = PetEvalDatasetClean.load_contamination_annotations(
path, split)
filename = osp.join(path, split, f'{name}_{split}.csv')
with open(filename, encoding='utf-8') as f:
reader = csv.reader(f)
header = next(reader)
for row_index, row in enumerate(reader):
item = dict(zip(header, row))
item.setdefault('explanation', '')
item.setdefault('answer', '')
if split == 'val':
row_id = f'{name}-{row_index}'
if row_id in annotations:
item['is_clean'] = annotations[row_id][0]
else:
item['is_clean'] = 'not labeled'
dataset.setdefault(split, []).append(item)
dataset = {i: Dataset.from_list(dataset[i]) for i in dataset}
return DatasetDict(dataset)
2.将实现的类添加在init文件的最后
vim opencompass/opencompass/datasets/__init__.py
···
from .xsum import * # noqa: F401, F403
from .petEval import * # noqa: F401, F403
3.3 在自定义的数据集上评测 internlm2-chat-1_8b 模型
3.3.1 调整一下run.sh脚本
设置–datasets petEval_gen
#!/bin/bash
python run.py --datasets petEval_gen --hf-path /data0/tc_workspace/internlm/model/internlm2-chat-1.8b/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /data0/tc_workspace/internlm/model/internlm2-chat-1.8b/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 1 --num-gpus 1 --debug
3.3.2 运行run.sh脚本
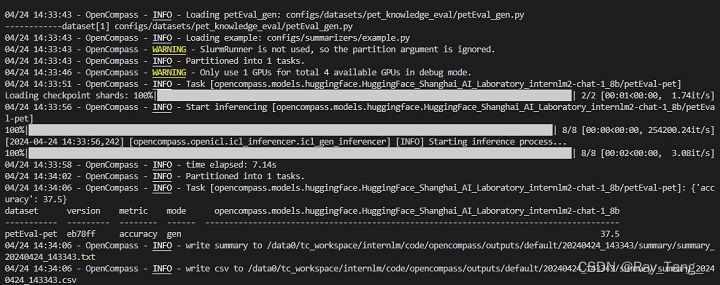
./run.sh
八中三,acc:37.5
3.4 上传自定义数据集
参考链接1、2
---
name: Pet-knowledge-eval
desc: This is a review set of pet encyclopedia knowledge
language:
- cn # Example: fr
dimension:
- language
sub_dimension:
- language
website:
github:
paper:
release_date: 2024-04-20
tag:
- text
download_url: https://code.openxlab.org.cn/raytang88/internlm2-1_8b-pet-knowledge-assistant-eval.git
cn: # optional, for chinese version website
name: 宠物百科知识验证集
desc: 宠物百科知识验证集
---
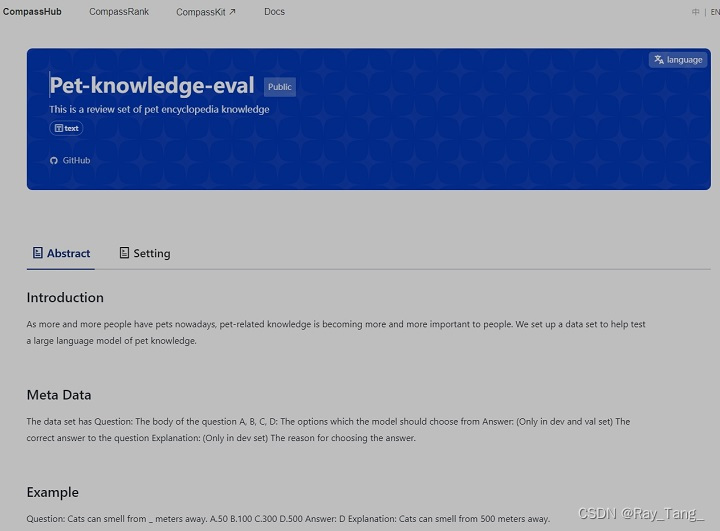
## Introduction
As more and more people have pets nowadays, pet-related knowledge is becoming more and more important to people. We set up a data set to help test a large language model of pet knowledge.
## Meta Data
The data set has
Question: The body of the question
A, B, C, D: The options which the model should choose from
Answer: (Only in dev and val set) The correct answer to the question
Explanation: (Only in dev set) The reason for choosing the answer.
## Example
Question: Cats can smell from _ meters away.
A.50
B.100
C.300
D.500
Answer: D
Explanation: Cats can smell from 500 meters away.
## Citation
@article{
}
附录
报错:
1.
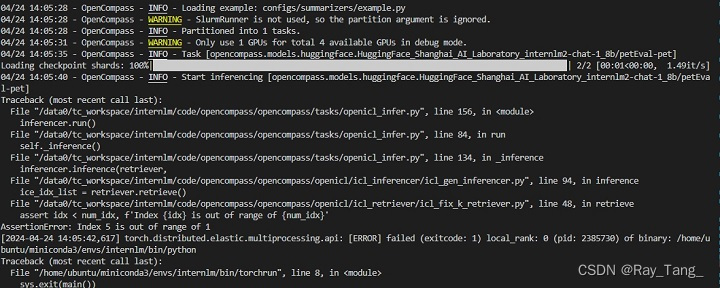
解决思路:3.2.1节中retriever=dict(type=FixKRetriever, fix_id_list=[])这一行,这是在评测的时候将之前dev的数据加在后面的val的数据前面做固定的上下文放入prompt,如果dev的数据比较少,则要根据相应的数据修改 fix_id_list=[],中的id索引,或者直接删掉,不加入prompt
参考链接:
1.https://hub.opencompass.org.cn/dataset-submit?lang=[object%20Object]
2.https://mp.weixin.qq.com/s/_s0a9nYRye0bmqVdwXRVCg
3.https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









