






书生浦语第二期实战营系列—综述加技术报告研读
书生浦语第二期实战营系列—Tutorial1:demo体验
书生浦语第二期实战营系列—Tutorial2:RAG
书生浦语第二期实战营系列—Tutorial3:Xtuner微调
书生浦语第二期实战营系列—Tutorial4:Lmdeploy量化部署
书生浦语第二期实战营系列—Tutorial5:Agent
书生浦语第二期实战营系列—Tutorial6:OpenCompass
书生浦语第二期实战营学习笔记(第一节课)
1 大模型和书生浦语系列概述
1.1 大模型的发展历程
陈恺老师首先回顾了深度学习的发展历程,分析了专用模型到通用模型的变迁过程
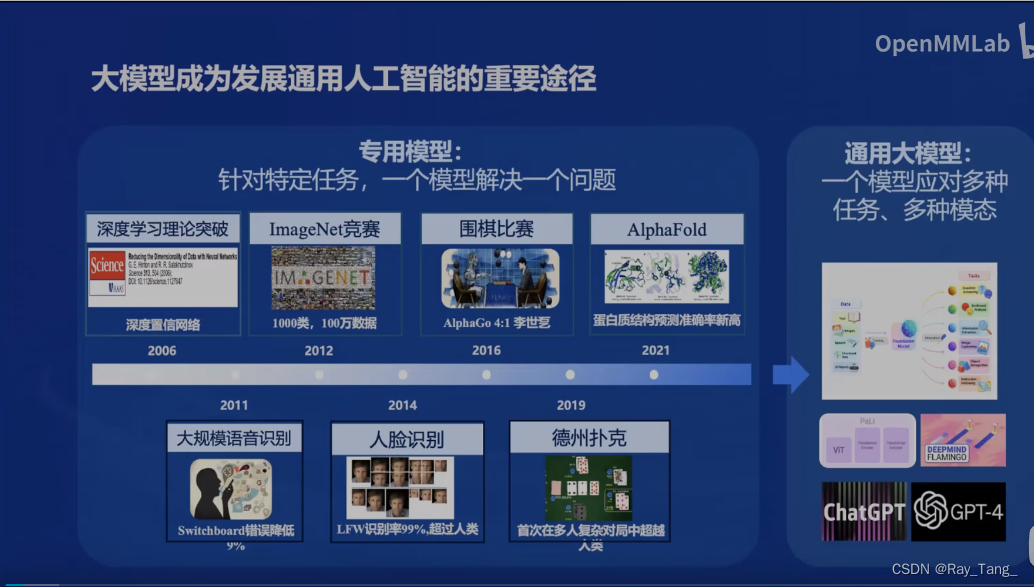
1.2 书生浦语系列大模型的发展历程
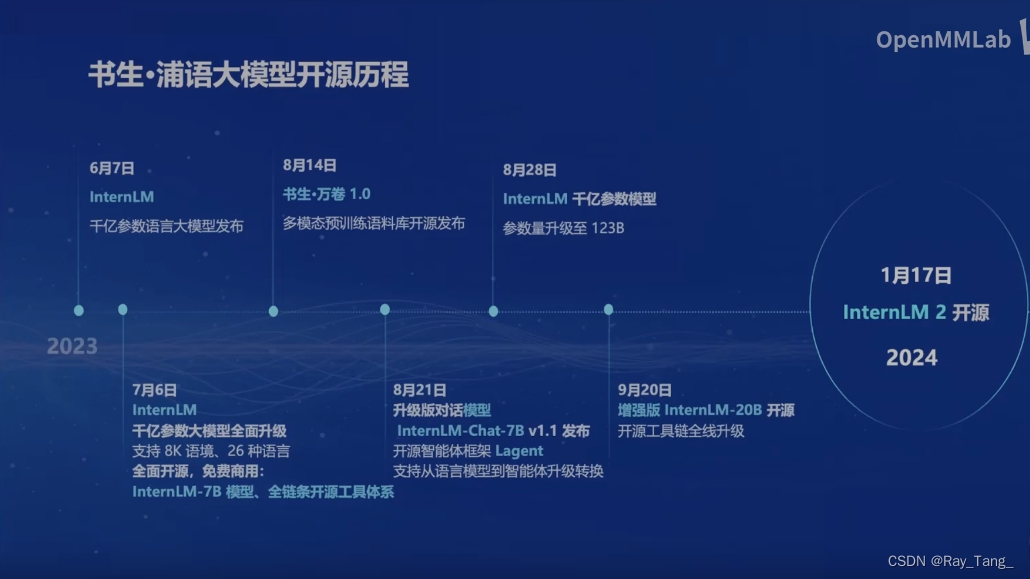
1.3 开源的书生浦语2.0大模型内容介绍
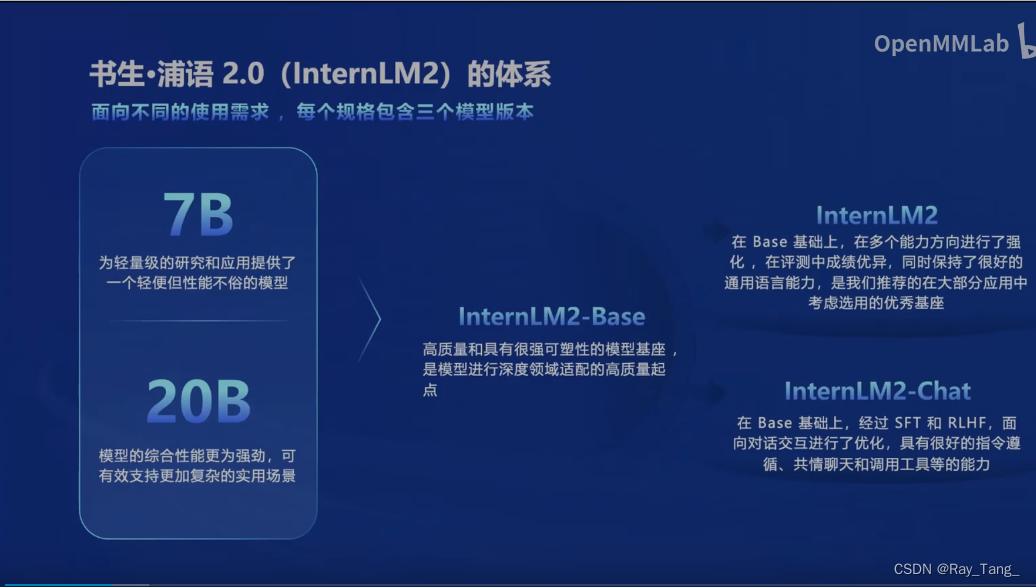
1.3.1 书生浦语2.0大模型整体体系
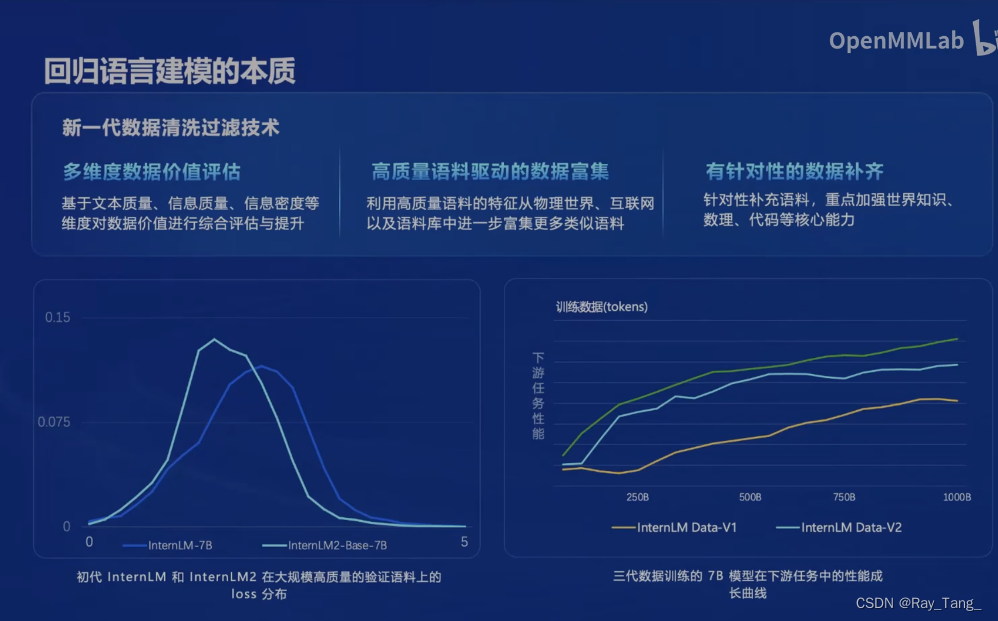
1.3.2 IternLM2训练过程中的数据清洗过滤技术
数据质量决定模型的上限,IternLM2在这一块也做了不少工作,这绝对是苦活,干过嘛都知道
1.3.3 IternLM2的主要亮点展示
很亮啊,注意眼睛

1.3.4 IternLM2性能提升分析
咱书生全方位包裹别人,yylx

1.3.5 IternLM2应用举例
有温度,有创造力,强大且实用啊


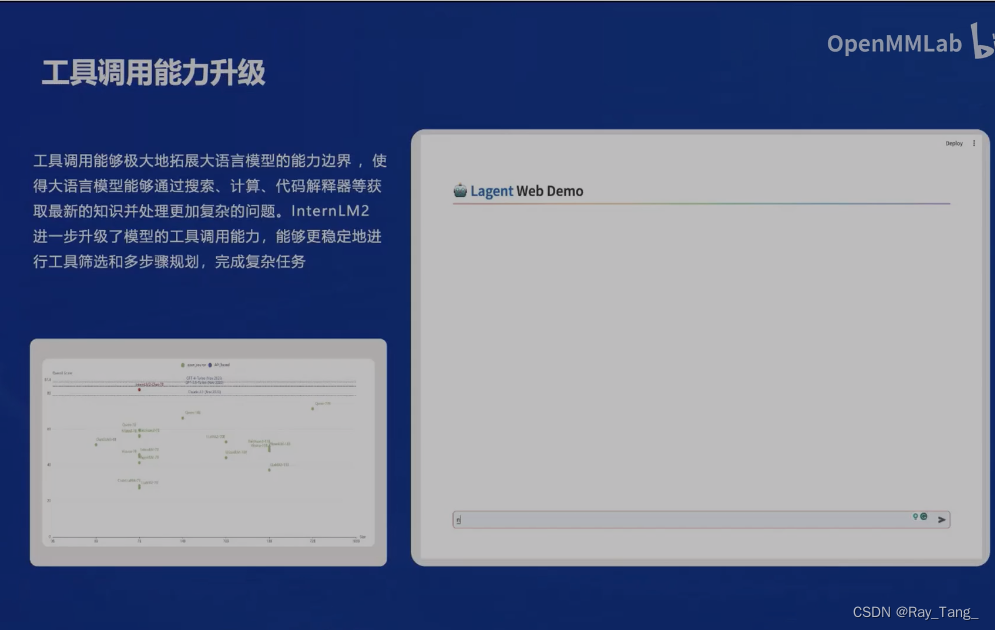
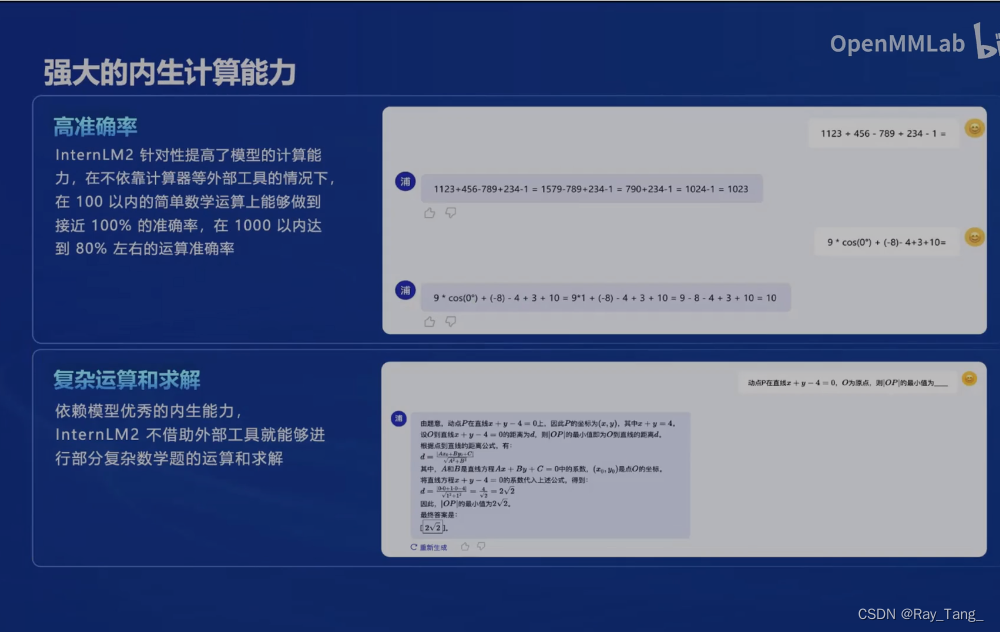

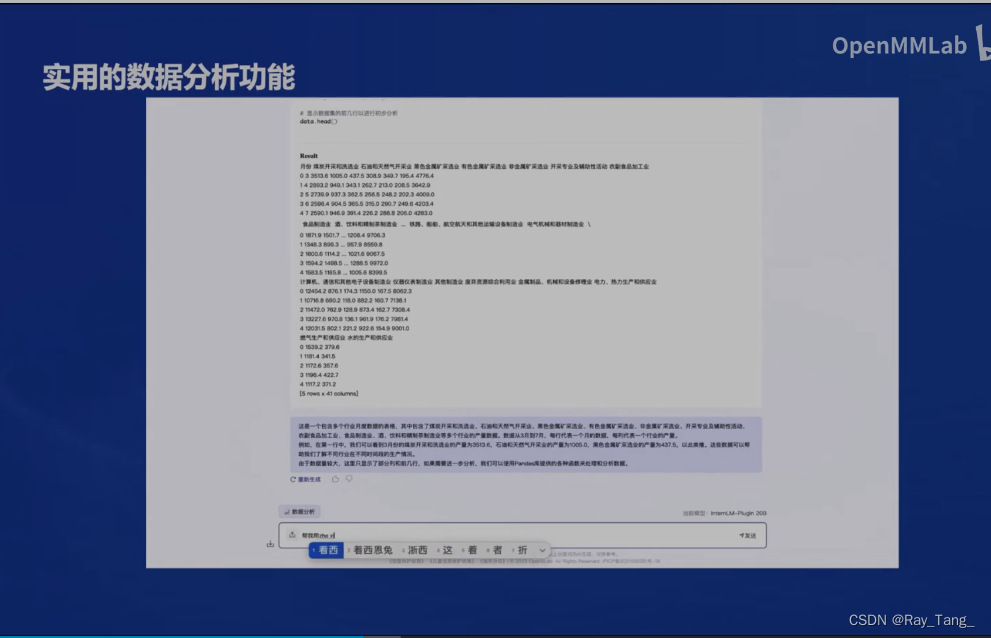

1.4 经典的应用流程
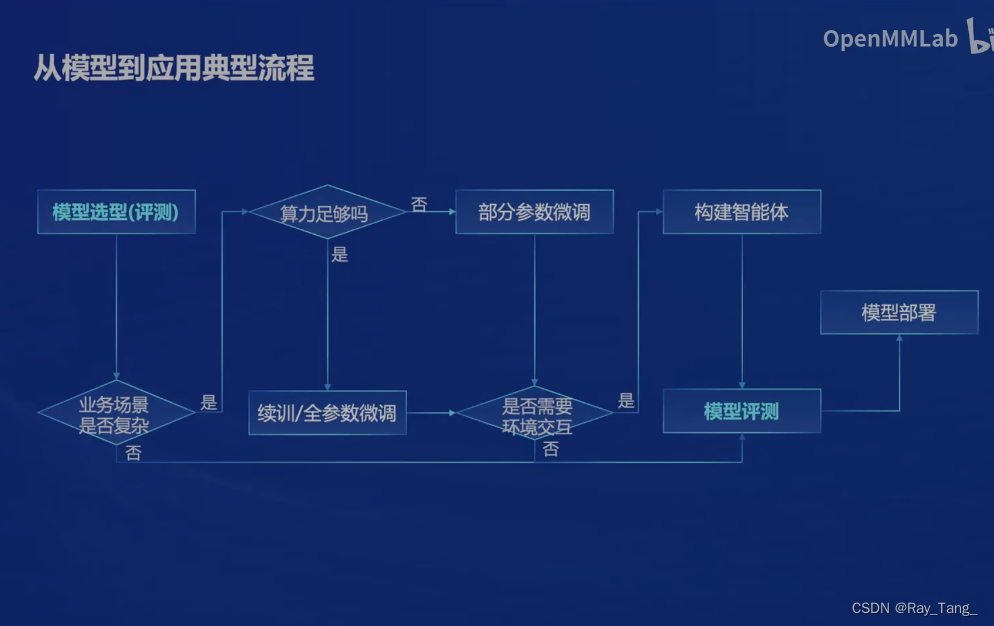
这么多模型(屌丝的福利啊),就问问,咱应该怎么选怎么用啊,流程图告诉你?
1.5 开源的书生浦语全链条开方体系
上面讲了 IternLM2如此优秀的能力。那咱能拥有一个吗?答案是可以的,虽然有点难,不,是很难。书生浦语开放的这些工具is all we need!

1.5.1 书生万卷
老规矩,数据是模型能力的上限
1.5.2 基座训练工具
有了数据,高效的训练工具必不可少
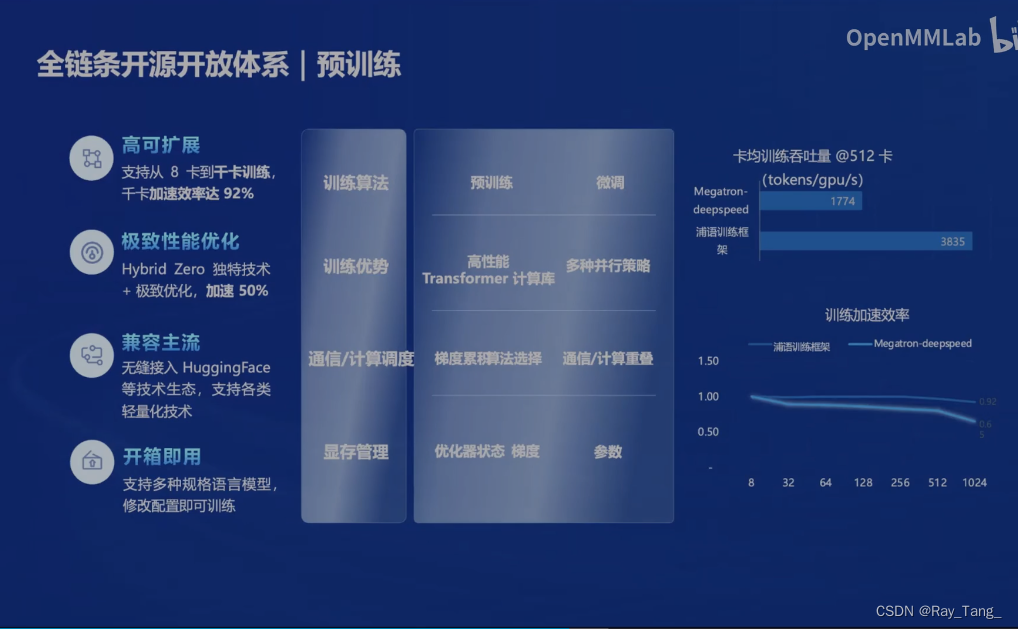
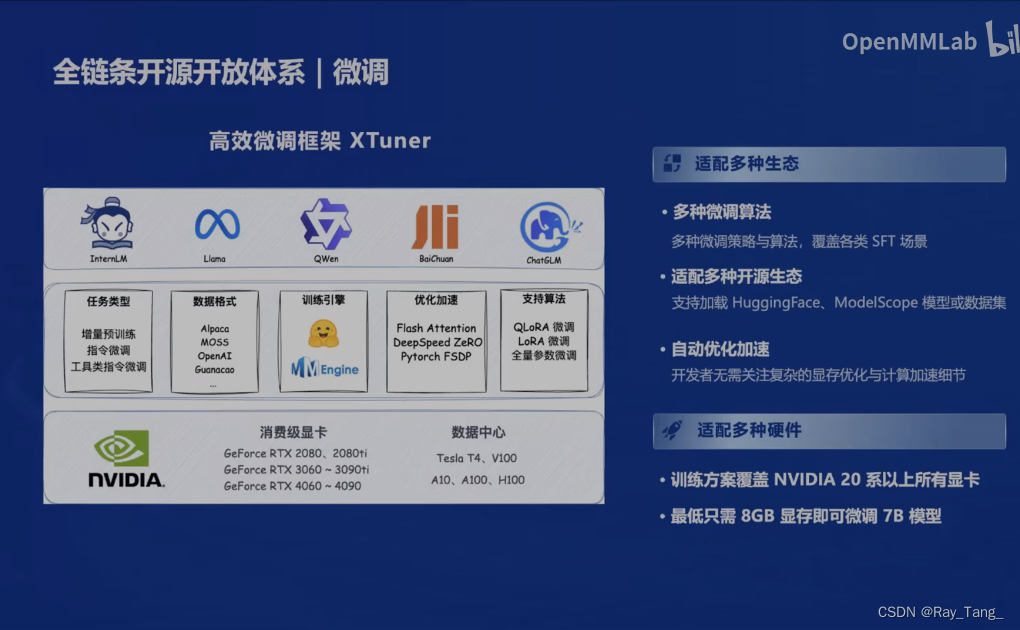
1.5.3 模型微调工具
当然了不是随都能玩转全量训练,高效的微调工具也来了 XTuner

1.5.4 模型评测工具
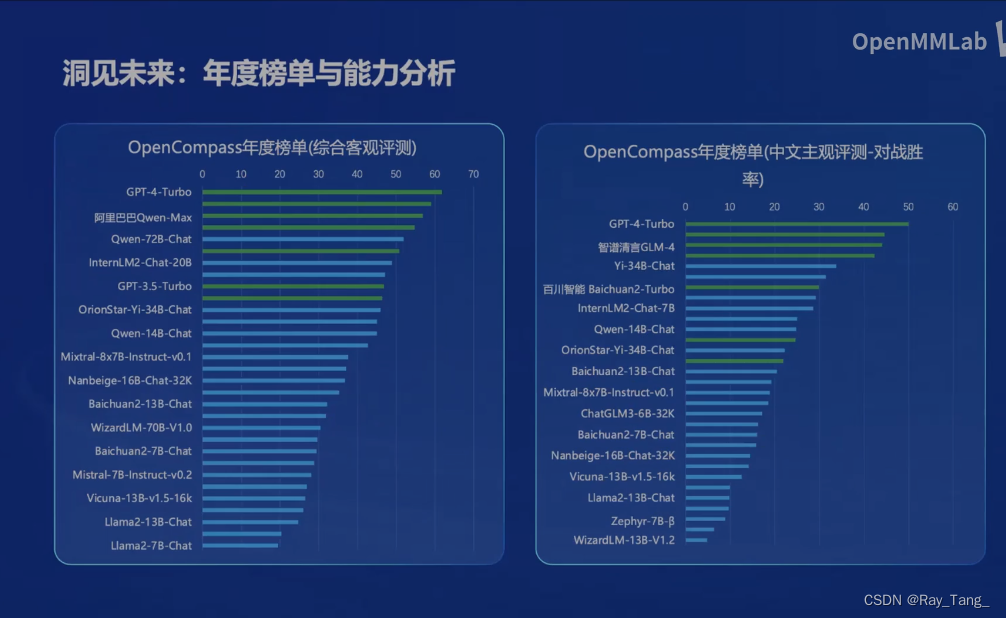
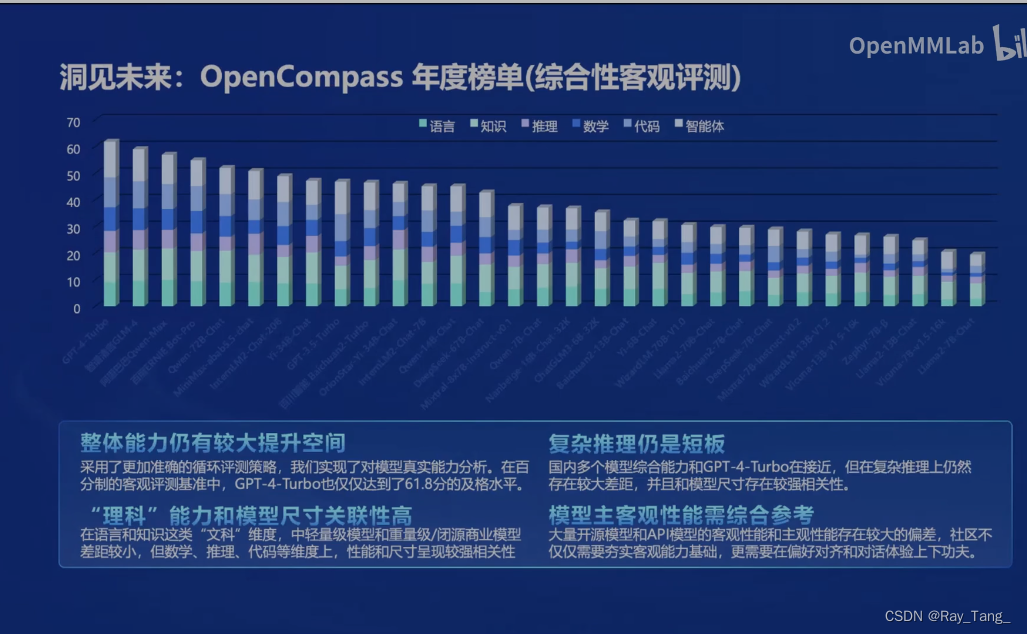
模型训练(微调)好了,是骡子是马,咱得溜溜啊,客观公正的OpenCompass来也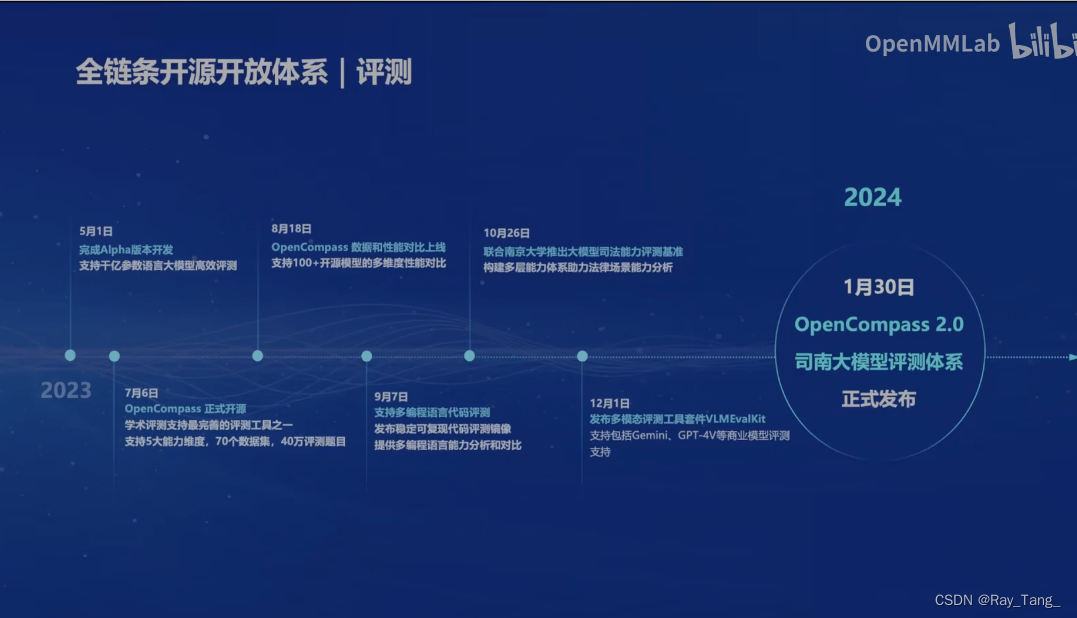

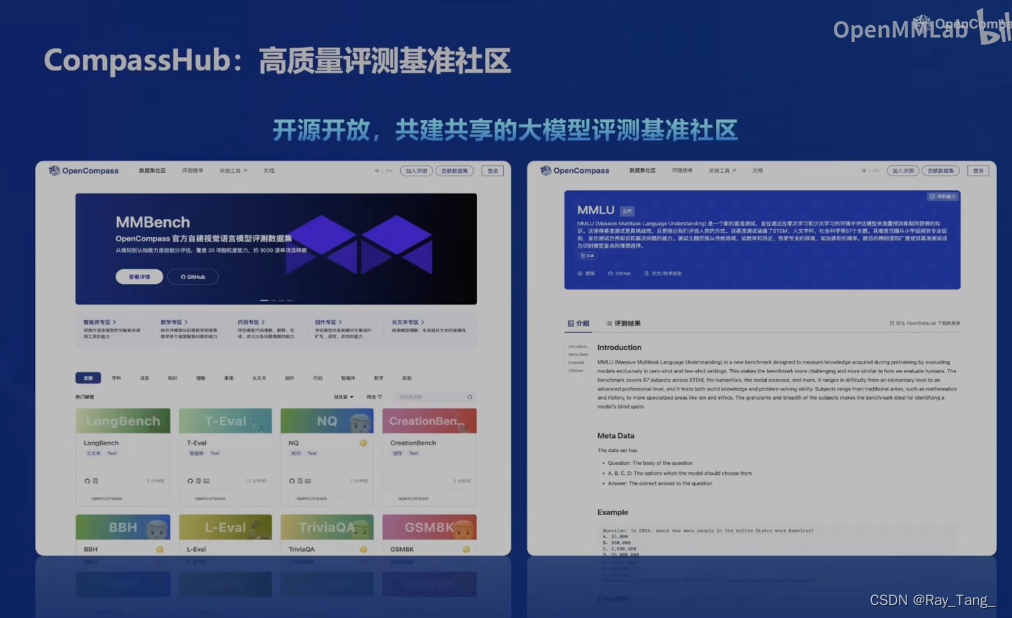
你看大家都在用!

1.5.5 模型部署工具
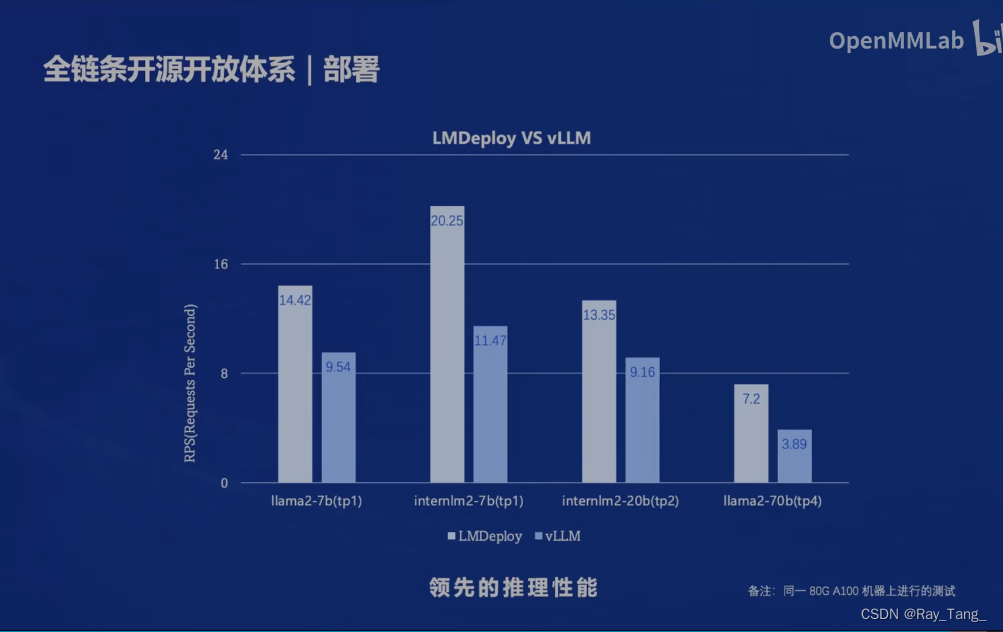
模型评测好了,嗯是个好东西,咱得把它用起来呀,几十亿参数,跑不动,得量化,啥工具呀,LMDeploy很强,turbomind据说优化的很好诶!

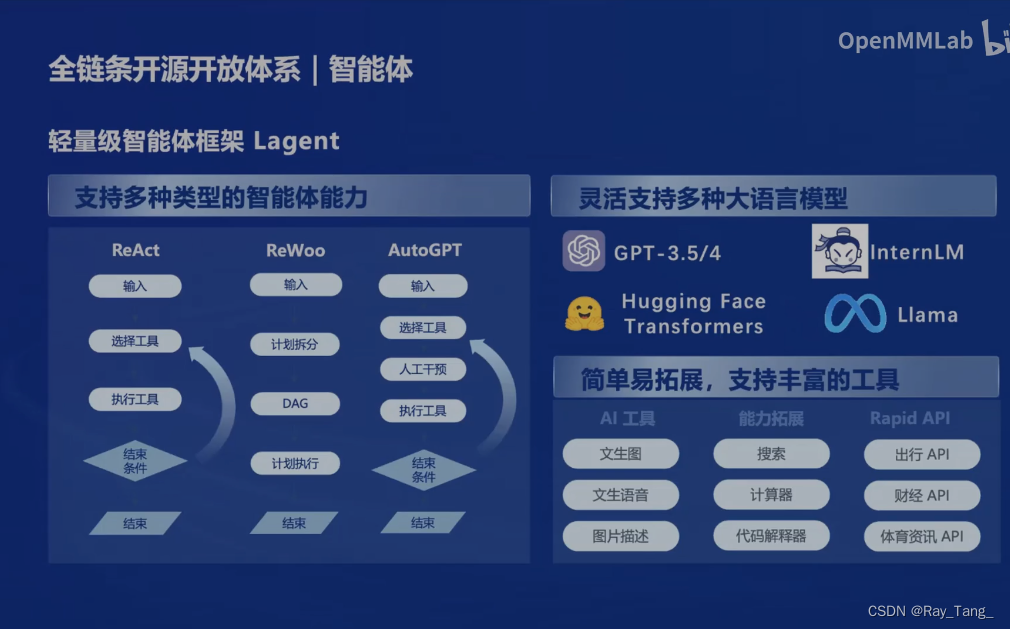
1.5.6 智能体
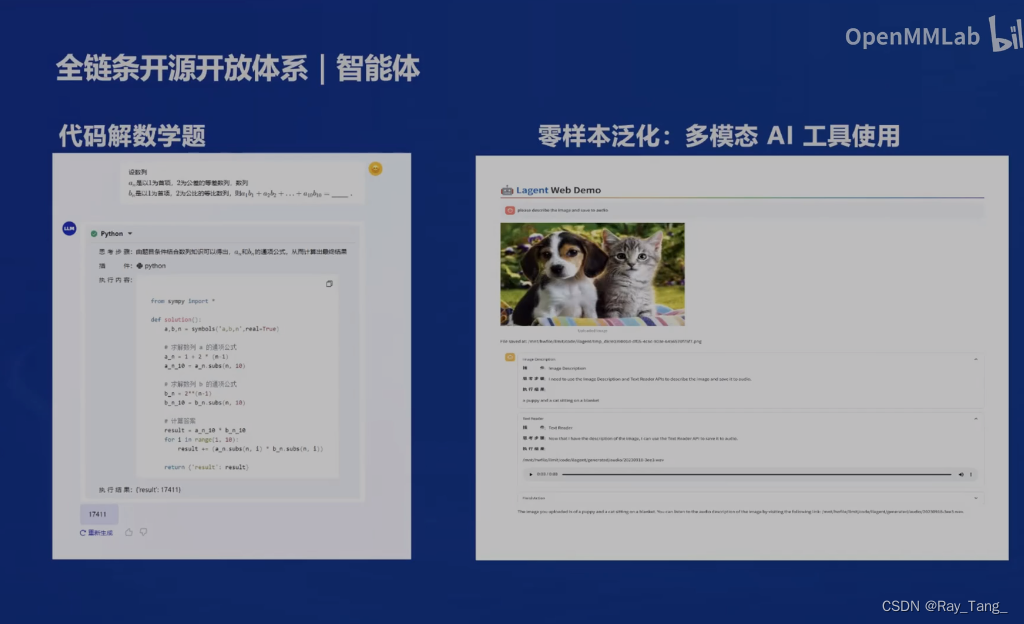
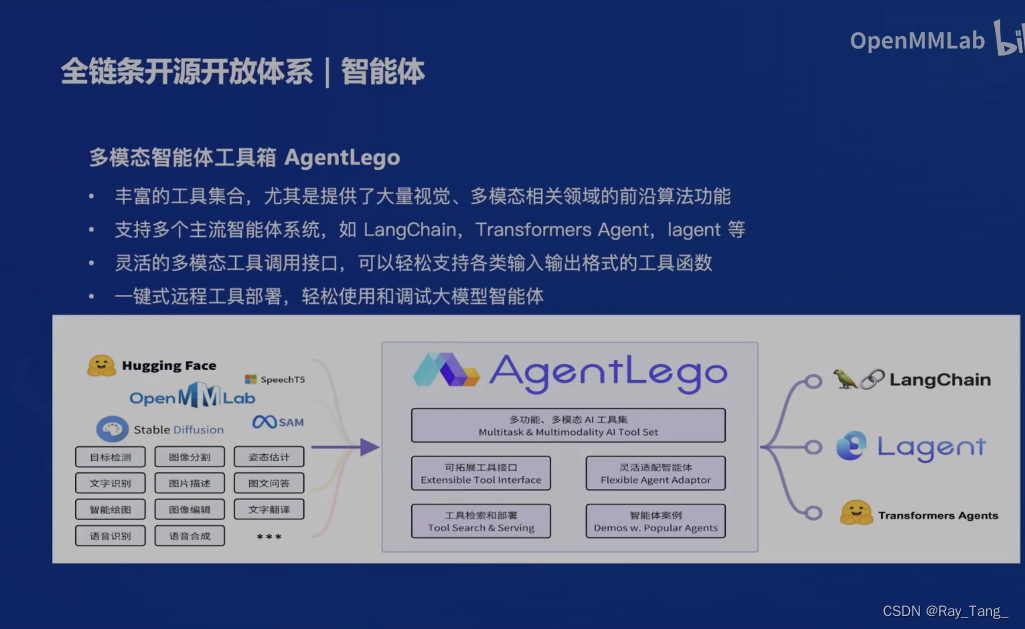
1.6 总结
总分总,经典格式啊!
2 internLM2技术报告研读
2.1 介绍
自GPT-4的出现以来,出现了LLaMA 、Qwen 、Mistral 和Deepseek等一些显著的开源大语言模型。在这篇论文中,介绍了InternLM2,它有以下关键点:
- 开源InternLM2模型展现卓越性能: 开源了不同规模的模型包括1.8B、7B和20B,它们在主观和客观评估中都表现出色。此外,还发布了不同阶段的模型,以促进社区分析SFT和RLHF训练后的变化。
- 设计带有200k上下文窗口: InternLM2在长序列任务中表现出色,在带有200k上下文的“大海捞针”实验中,几乎完美地识别出所有的“针”。此外,提供了所有阶段包括预训练、SFT和RLHF的长文本语言模型的经验。
- 综合数据准备指导: 本文详细阐述了为大语言模型(LLM)准备数据的方法,包括预训练数据、特定领域增强数据、监督微调(SFT)和基于人类监督的强化学习(RLHF)数据。这些细节将有助于社区更好地训练LLM。
- 创新的RLHF训练技术: 本文引入了条件在线RLHF(COOL RLHF)来调整各种偏好,显著提高了InternLM2在各种主观对话评估中的表现。本文还对RLHF的主观和客观结果进行了初步分析和比较,为社区提供对RLHF的深入理解。
2.2 基础设施
2.2.1 InternEvo
- 减少通信开销:通过实现一系列自适应分片技术(如Full-Replica、FullSharding和Partial-Sharding)来应对通信挑战,以实现强大的扩展性能;
- 通信-计算重叠:InternEvo高效地预加载即将到来的层的完整参数集,同时计算当前层。生成的梯度在参数分片组内通过ReduceScatter进行同步,然后通过AllReduce跨参数分片组同步。这些通信过程巧妙地与反向计算重叠,最大化训练管道的效率;
- 长序列训练:InternEvo将GPU内存管理分解为四个并行维度(数据、 张量、 序列和管道)和三个分片维度(参数、梯度和优化器状态)。我们对每个维度的内存和通信成本进行了详尽分析,并使用执行模拟器来识别和实施最优的并行化策略。根据训练规 模、序列长度、模型大小和批量大小,可以自动搜索最优执行计划;
- 容错性 :引入了两个系统努力:一个容错的预训练系统,通过诊断大模型相关的故障并自动恢复来提高容错性;以及一个为评估任务设计的解耦调度系统,提供及时的模型性能反馈;
2.2.2 模型结构
为了确保我们的模型InternLM2能无缝融入这个成熟的生态系统,InternLM2选择遵循LLaMA的结构设计原则。为了提高效率,InternLM2将Wk 、Wq和Wv矩阵合并,这在预训练阶段带来了超过5%的训练加速。此外,为了更好地支持多样化的张量并行(tp)变换,InternLM2重新配置了矩阵布局。对于每个head的Wk 、Wq和Wv,InternLM2采用了交错的方式。这种设计修改使得可以通过分割或沿最后一个维度连接矩阵来调整张量并行大小,从而增强了模型在不同分布式计算环境中的灵活性。InternLM2的目标是处理超过32K的上下文,因此InternLM2系列模型都采用了分组查询注意力(GQA),以实现高速度和低GPU内存下的长序列推理。

2.3 预训练
2.3.1 预训练数据
InternLM2根据数据来源对预训练数据集中的文档数量、存储容量和容量占比进行了统计分析,结果如表1所示。其中,主要来源是中文和英文网页,占总量的86.46%。数据分布如下:
2.3.1.1 文本数据
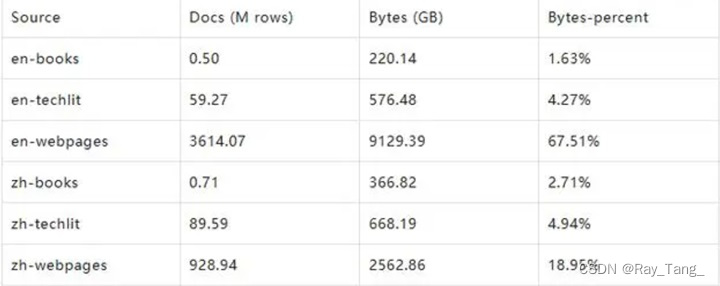
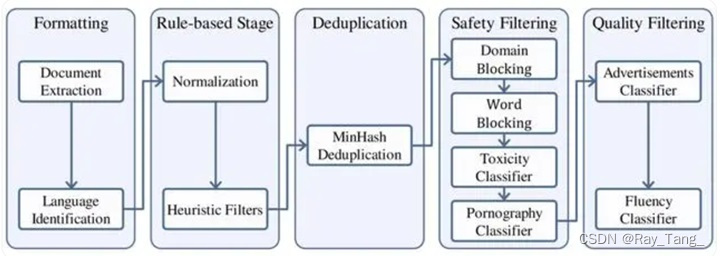
文本数据处理方式:
- 整个数据处理流程首先将来自不同来源的数据标准化以获得格式化数据;
- 使用启发式统计规则对数据进行过滤以获得干净数据;
- 使用局部敏感哈希(LSH)方法对数据去重以获得去重数据。
- 我们应用一个复合安全策略对数据进行过滤,得到安全数据。我们对不同来源的数据采用了不同的质量过滤策略,最终获得高质量预训练数据
2.3.1.2 代码数据
代码数据的来源有GitHub、公共数据集以及一些与编程相关的在线资源:如问答论坛、教程网站和API文档等,分布如下: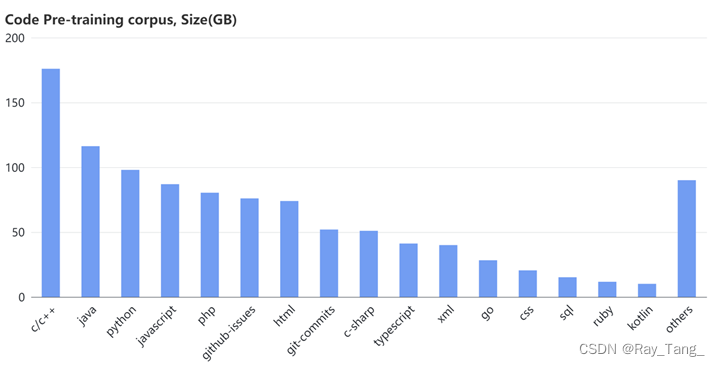
代码数据处理方式:
- 格式清理
- 数据去重
- 质量过滤
- 依赖排序
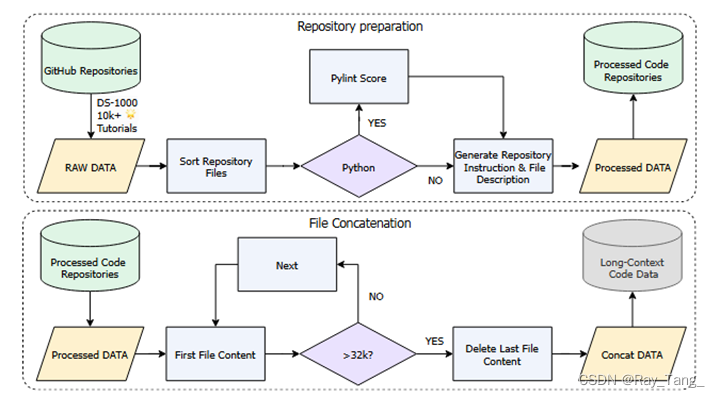
2.3.1.3 长上下文
过滤前长文本数据的统计
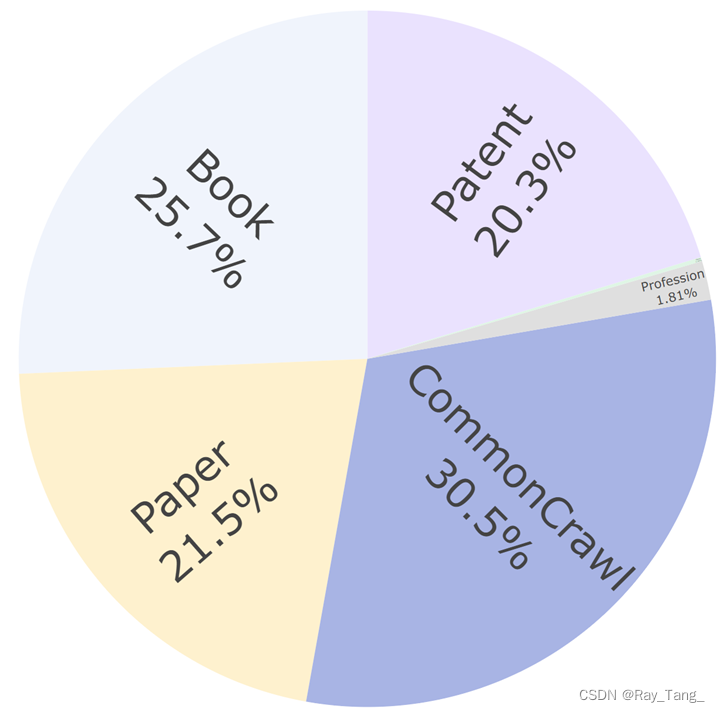
长上下文数据处理方式:
- 长度选择,这是一个基于规则的过滤器,选取超过32K字节的样本;
- 统计过滤器,利用统计特征来识别和移除异常数据;
- 困惑度过滤器,利用困惑度的差异来评估文本片段之间的连贯性,过滤掉上下文不连贯的样本
2.3.2 预训练设置
2.3.2.1 分词(Tokenization)
选择使用GPT-4的tokenization方法,参考是cl100K词汇表,它主要包含英语和编程语言的 token,共计100,256条。
2.3.2.2 预训练超参数
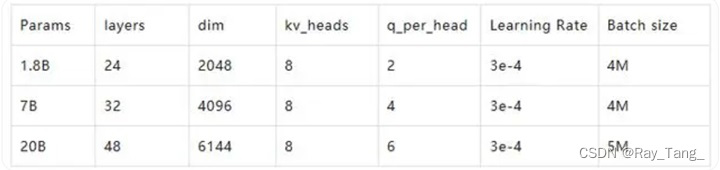
2.4 对齐
2.4.1 监督微调
在监督微调(SFT)阶段,使用了包含1000万个指令数据实例的数据集,数据样本转换为ChatML(Cha)格式。7B和20B模型都使用AdamW优化器进行了一轮训练,初始学习率设为4e-5。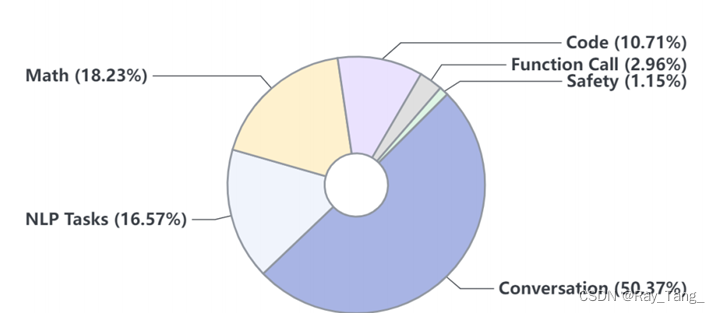
2.4.2 基于人类反馈的条件在线强化学习COOL RLHF
- 条件奖励模型:条件奖励模型为不同类型的偏好引入不同的系统提示,从而有效地在一个奖励模型中模拟各种偏好;
- Online RLHF:快速路径(Fast Path) Online RLHF中的快速路径专注于通过有针对性的补丁快速识别和纠正奖励滥用事件,以提高奖励模型的可靠性;慢速路径(Fast Path) 与专注于修复奖励滥用的快速路径相比,慢速路径旨在通过包含来自最新且能力最强的模型的LLMs生成的响应,对奖励模型的上界进行全面改进,特别是奖励模型在高奖励区域的可靠性和鲁棒性。
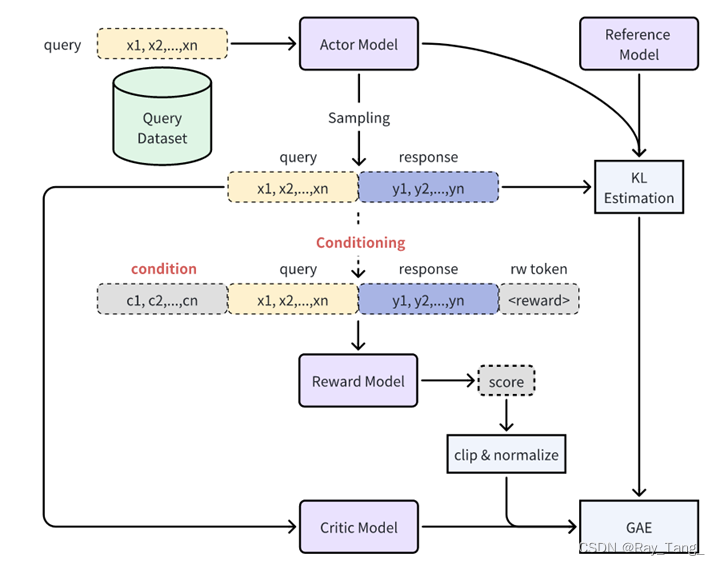
2.4.3 长文本微调
为了在微调和RLHF之后保留LLM的长上下文能力,采用长上下文预训练语料库的SFT工作
2.5 评测分析
参考链接:
-
https://arxiv.org/pdf/2403.17297.pdf
主题:InternLM2英文技术报告 -
Training language models to follow instructions with human feedback
地址:https://arxiv.org/pdf/2203.02155.pdf
主题:openai RLHF -
https://aicarrier.feishu.cn/wiki/Xarqw88ZkimmDXkdTwBcuxEfnHe
主题:InternLM2中文技术报告 -
https://zhuanlan.zhihu.com/p/689967866
-
https://zhuanlan.zhihu.com/p/690493899
主题:强化学习相关














 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









