







 本文探讨了在Redis Cluster模式下如何实现在两个机房间的容灾切换。详细介绍了集群搭建、主从选举机制,通过模拟测试分析了不同故障场景下的切换策略,包括网络中断和单个Master宕机的情况,最后提出了可行的切换方案。
本文探讨了在Redis Cluster模式下如何实现在两个机房间的容灾切换。详细介绍了集群搭建、主从选举机制,通过模拟测试分析了不同故障场景下的切换策略,包括网络中断和单个Master宕机的情况,最后提出了可行的切换方案。
Redis的cluster集群模式能够自动实现主从之间的自由切换,所以在单个机房中Redis cluster集群中,当Master宕机后,Slave会被其他Master投票选举为新的Master,从而实现故障切换。今天我们要探讨的问题是相距两地的机房中怎么实现Redis cluster集群模式的容灾切换。
目录
一、redis的集群搭建
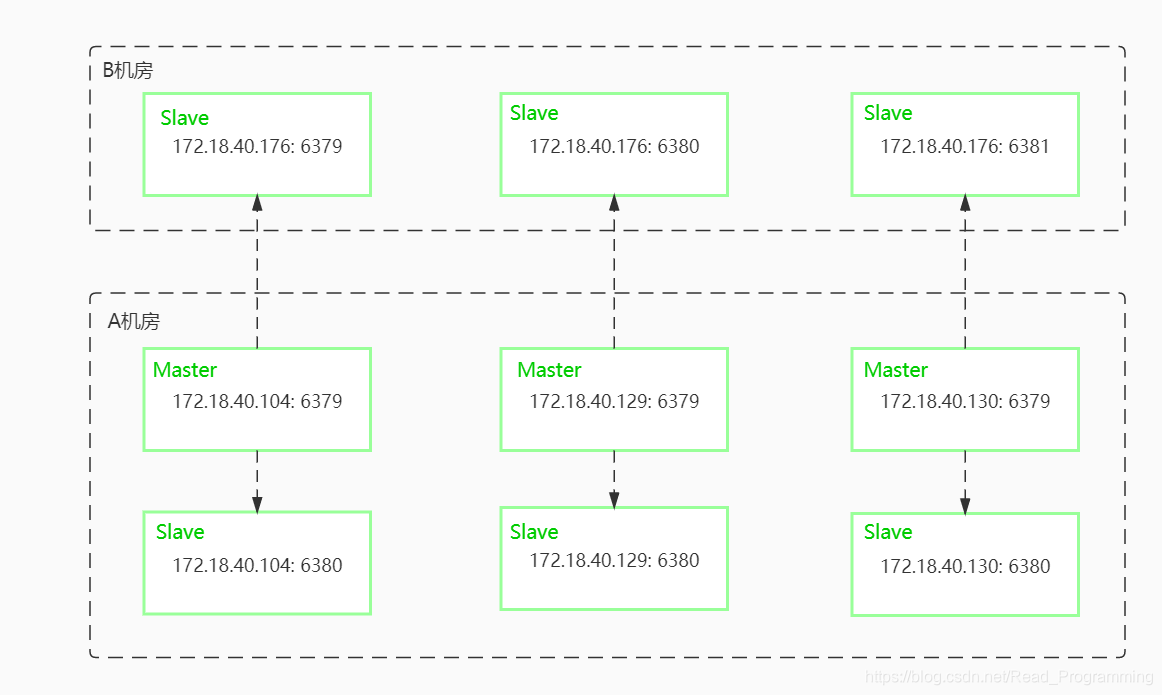
测试集群一
| Master | Slave |
|---|---|
| 172.18.40.129:6379 | 172.18.40.129:6380、172.18.40.176:6380 |
| 172.18.40.130:6379 | 172.18.40.130:6380、172.18.40.176:6381 |
| 172.18.40.104:6379 | 172.18.40.104:6380、172.18.40.176:6379 |
集群架构图
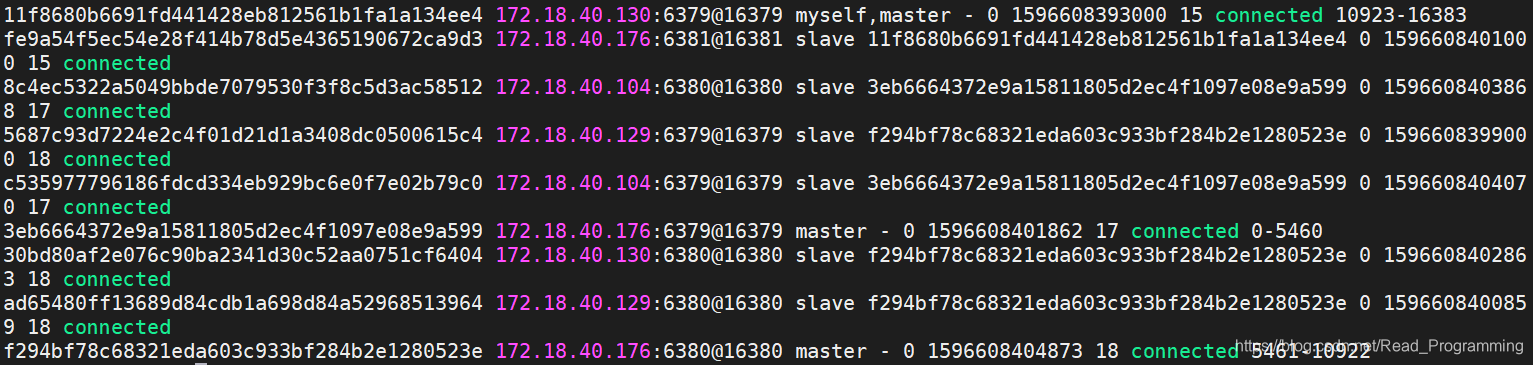
集群状态
测试集群二
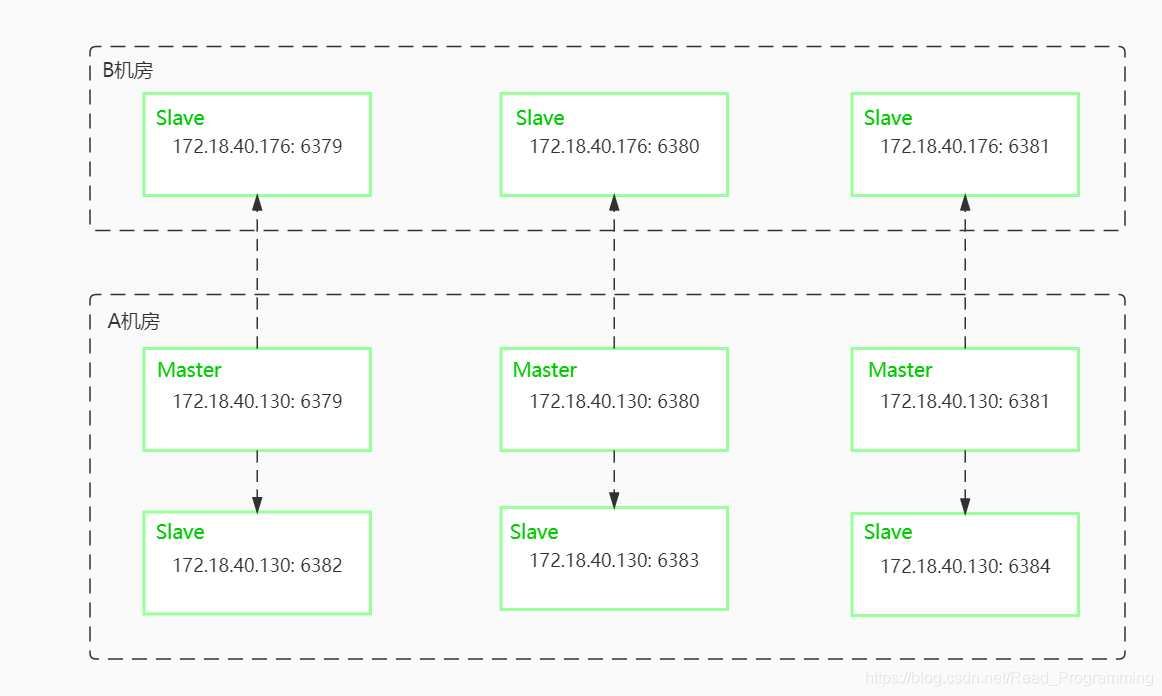
| 部分测试不方便用测试集群一实现,当测试集群一测试完毕后卸载了测试集群一,重新用两台服务器搭建了测试集群二,集群搭建思路没有改变。 |
| Master | Slave |
|---|---|
| 172.18.40.130:6379 | 172.18.40.130:6382、172.18.40.176:6379 |
| 172.18.40.130:6380 | 172.18.40.130:6383、172.18.40.176:6380 |
| 172.18.40.130:6381 | 172.18.40.130:6384、172.18.40.176:6381 |
集群架构图
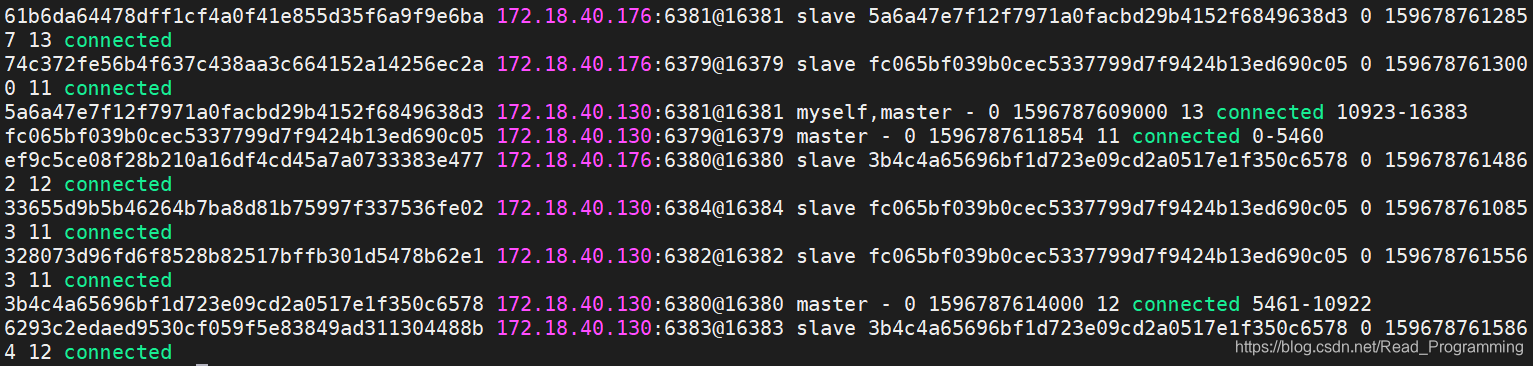
集群状态
二、redis cluster相关知识
1、Slave的选举与提升
当slaves节点进行选举时,会在其他masters的帮助下进行投票,选举出一个slave并提升为master。当master处于FAIL状态时,将会触发slave的选举。slaves都希望将自己提升为master, 此master的所有slaves都可以开启选举,不过最终只有一个slave获胜。具体的选举与提升流程如下:| ① 满足如下情况slave即可进行选举:a.当此slave的master处于FAIL状态;b.此master持有非零个slots;c、此slave的replication链接与master断开时间没有超过设定值,为了确保此被提升的slave的数据是新鲜的,这个时间用户可以配置。 |
| ②slave自增它的currentEpoch值,然后向其他masters请求投票(需求支持,votes)。slave通过向其他masters传播“FAILOVER_AUTH_REQUEST”数据包,然后最长等待2倍的NODE_TIMEOUT时间,来接收反馈。(在集群node创建时,master和slave都会将各自的currentEpoch设置为0,每次从其他node接收到数据包时,如果发现发送者的epoch值比自己的大,那么当前node将自己的currentEpoch设置为发送者的epoch,最终所有的nodes都会认同集群中最大的epoch值;当集群的状态变更,或者node为了执行某个行为需求agreement时,都将需要epoch(传递或者比较)。) |
| ③一旦一个master向此slave投票,将会响应“FAILOVER_AUTH_ACK”,此后在2 * NODE_TIMOUT时间内ÿ |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1091
1091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









