







正则表达式,使得字符串的操作变得更加方便。由于正则表达式是用于处理字符串,因此正则的类被放置在System.Text.RegularExpressions中。
使用示例:
1、使用情景:当我们复制一个文件时,文件名会自动在末尾增加一个下标,以避免覆盖原文件。如:info.txt -> info(1).txt
private static void FileNameModify()
{
string filePath = @".\NewFile.txt";
string pattern = @"\(\d+\)$";
while (File.Exists(filePath))
{
Regex rgx = new Regex(pattern);
string fileName = Path.GetFileNameWithoutExtension(filePath);
if (rgx.IsMatch(fileName))
{
Match indexMatch = rgx.Match(fileName);
string indexStr = indexMatch.Value;
Regex num = new Regex(@"\d+");
Match index = num.Match(indexStr);
int fileIndex = int.Parse(index.Value);
filePath = fileName.Substring(0, fileName.LastIndexOf('(')) + "(" + (++fileIndex) + ")" +
Path.GetExtension(filePath);
}
else
{
filePath = fileName + "(1)" + Path.GetExtension(filePath);
}
}
using (File.Open(filePath, FileMode.Create))
{
;
}
}
下面我们来开始学习正则表达式。
首先在System.Text.RegularExpressions命名空间中,有这几个主要的类:
1、Regex
2、Match、 MatchCollection
3、Group、GroupCollection
4、Capture 、CaptureCollection
首先,我们来整理一下,这几个类之间的关系。那么它们之间的关系是什么样子的呢?
在帮组文档中,我们可以看到:
System.Object
System.Text.RegularExpressions.Regex
System.Object
System.Text.RegularExpressions.Capture
System.Text.RegualrExpressions.Group
System.Text.RegularExpressions.Match
从这里我们就能看出后这几个类之间的关系:Match 是 Group的子类,Group是Capture的子类。知道这个东西有什么用呢?这个有助于我们理解下面的这些东西(个人理解,有错误请指出!)
*当我们使用一个正则表达式去对一段文本进行匹配时,我们可以使用Match去得到最终的匹配结果。但是,有时,我需要用到匹配结果中的一部分子集,这部分子集就会用Group这个东西来保存,而在Group中保存的东西就是Capture。说白了,其实在匹配过程中Capture才是最小单元。
(这里只是简单的正则使用,先理解了用法,然后去考虑正则的构建)
我们来举个例子:
第一步:我只想要得到一个符合条件的字符串。
private static void Test()
{
string myStr = "peeek";
string pattern = "^pe+k";
Regex regex = new Regex(pattern);
if (regex.IsMatch(myStr))
{
Match match = regex.Match(myStr);
Console.WriteLine("Match : " + match.Value);
}
}结果如下:
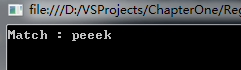
第二步:但是,我突然还想要得到其中e的情况,怎么办?为正则添加组(Group)。修改成下面的样子。
private static void Test()
{
string myStr = "peeek";
string pattern = "^p(e)+k";
Regex regex = new Regex(pattern);
if (regex.IsMatch(myStr))
{
Match match = regex.Match(myStr);
Console.WriteLine("Match : " + match.Value);
Console.WriteLine(" Match groups count: " + match.Groups.Count);
}
}
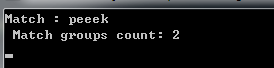
好了,我们就能发现,现在出席那了两个组。其中一个组是:peeek 另一个组是:e:它们分别是小括号括起来的部分匹配的字符串和整个正则匹配的字符串。
而我们使用小括号匹配的这部分信息就是我们需要的e的信息。
但是,我们又该怎么样去获得这部分的信息呢?我们知道在group中包含了多个capture信息(即captures:CaptureCollection),所以我们可以通过使用group的capture属性来获得我们需要的东西。(在group的Value属性中存储了最后一个capture信息)
第三步:使用Group中的captures属性获得详细信息
private static void Test()
{
string myStr = "peeek";
string pattern = "^p(e)+k";
Regex regex = new Regex(pattern);
if (regex.IsMatch(myStr))
{
Match match = regex.Match(myStr);
Console.WriteLine("Match : " + match.Value);
Console.WriteLine(" Match groups count: " + match.Groups.Count);
for (int i = 0; i < match.Groups.Count; i++)
{
Console.WriteLine(" Groups{0}: {1}", i, match.Groups[i].Value);
CaptureCollection cc = match.Groups[i].Captures;
Console.WriteLine(" this group has {0} captures", cc.Count);
for (int j = 0; j < cc.Count; j++)
{
Console.WriteLine(" capture {0}: {1}", j, cc[i]);
}
}
}
}结果如下:
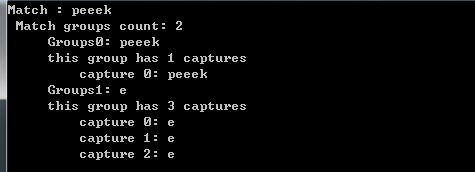
*当我们使用一个正则表达式去对一段文本进行匹配时,我们可以使用Match去得到最终的匹配结果。但是,有时,我需要用到匹配结果中的一部分子集,这部分子集就会用Group这个东西来保存,而在Group中保存的东西就是Capture。说白了,其实在匹配过程中Capture才是最小单元。















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









