






前情提要
本博客将一些比较散的知识归纳,用于平时巩固记忆,也希望能够帮到大家

下面是参考的网址,若有更详细的信息可以点击下方查询,本篇博客将较为重要的几个点进行归纳
string类文档介绍
🔺在最开始我们要明白一些单词的意思
| 原单词 | 中译 |
|---|---|
| Iterators | 迭代器 |
| Capacity | 容器 |
| Element access | 元素访问 |
| Modifiers | 修饰 符 |

Iterators
- begin & end
begin->任何容器返回第一个数据位置的iterator
end->任何容器返回最后数据的下一个位置的iterator


⭐代码实现
//用迭代器进行遍历
string s1 = "abcdef";
string::iterator it1 = s1.begin();
while(it1 != s1.end())
{
cout << it* << " ";
++it1;
}
迭代器是什么呢?不同的编译器迭代器实现的形式也会不同
★附加内容:还有两种遍历方式★
- 下标+[]
string s1 = "abcdef";
for(size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
- 范围for:auto
//自动将s1的值赋值给e
//自动往后++
//自动判断结束
for(auto e: s1)
{
cout << e << " ";
}
从底层角度来说,范围for就是迭代器↑
- sort
🔺规定排序的范围是左闭右开
⭐代码实现
string s1 = "hello world";4
//s1按照字典序排序
sort(s1.begin(),s1.end());
//只想要前五个进行排序
sort(s1.begin(),s1.begin()+5);
Capacity
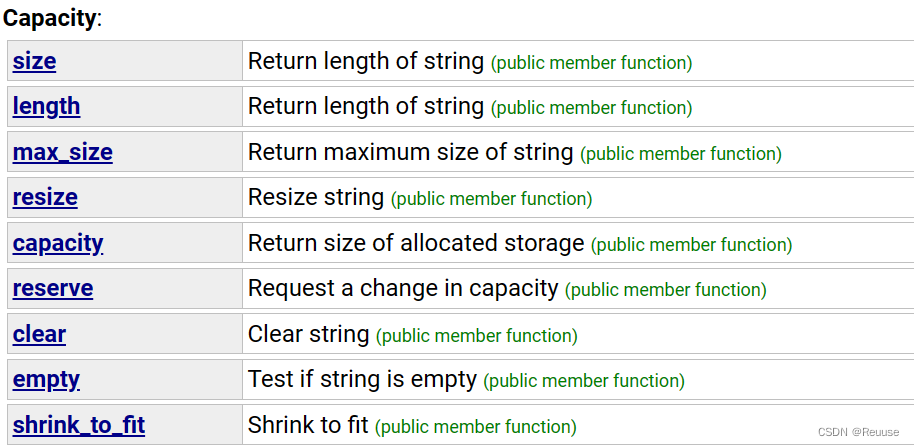
- size & length
- size()和length()对于std::string是等效的,都返回字符串的长度。
- size()更通用,用于多种STL容器,返回容器中元素的数量。
- sizeof返回对象或类型在内存中的字节大小。
- capacity
size()返回的是容器中当前实际存储的元素数量,而capacity() 返回的是容器当前的 内存分配大小。
⭐代码实现
string s1 = "hello";
cout << s1.size() << endl;
cout << s1.capacity() << endl;
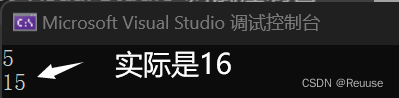
因为 capacity 比实际空间少一个,因为要给 \0 预留一个位置
- reserve 扩容
string s1;
s1.reserve(100);
注意:reserve保留 reverse逆置
Modifiers
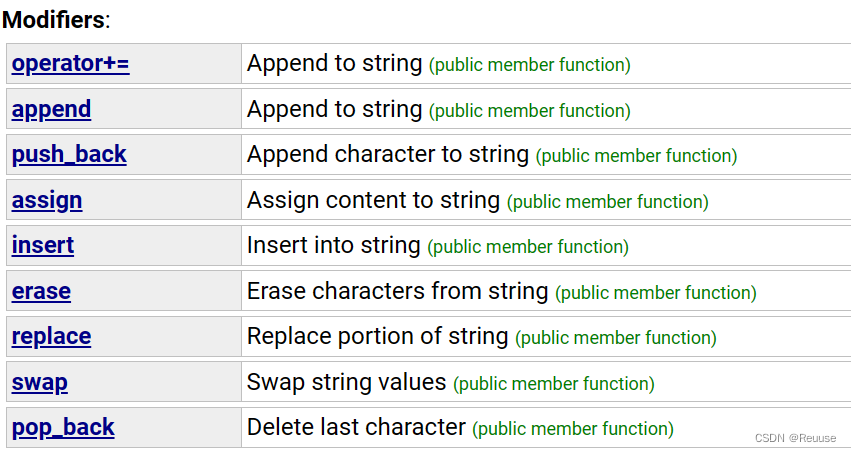
- push_back
底层空间扩容,在后面直接添加所需字符
⭐代码实现
string s1 = "hello world";
s1.push_back('x');
结果👇

弊端:只能插入一个字符,所以这里我们需要用到append
- append
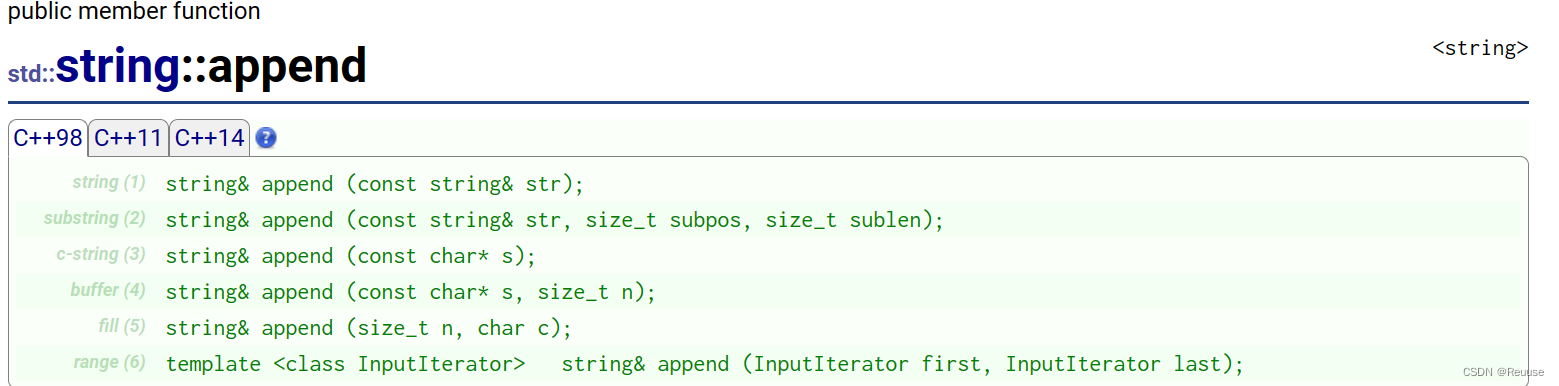
⭐代码实现
string s1 = "hello world";
s1.append("yyyyyy");
在实际引用当中我们不怎么用puch_back或者append,不难发现下面的代码会更加的方便。
例子:
string s1 = "hello world";
s1 += 'x';
s1 += "yyyyy";
🔺这里我们用到了operator+=
- operator+=
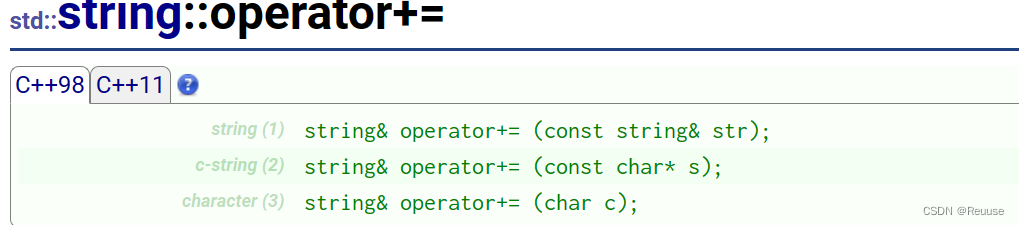
⭐代码补充
//以下方法都是可行的
string s2 = "abcd";
s1 += 'x';
s1 += "yyyyy"
s1 += s2;
结论:


- insert & erase

★ insert 头插 ★
string s1("good ");
string s2("hello world");
s2.insert(0,"xxxx"); //在 0 的位置头插
s2.insert(0, 1, 'y');//在 0 的位置头插 一个 y
s2.insert(s2.begin(), s1.begin(), s1.end());
//用迭代器实现插入一段数据
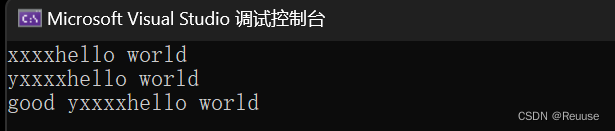
我们不建议使用是因为时间复杂度是O(N),效率不高
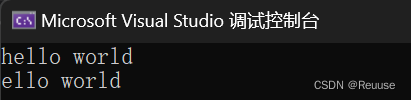
★ erase 头删 ★
string s1 = "hello world";
s1.erase(0, 1); //从 0 的下标删除 1 个
s1.erase(0, 50); //删除元素超过s1,不会报错
s1.erase(50, 100); //下标位置越界访问,报错
- replace
把一部分替换掉,提供下标和迭代器两种方法
⭐代码实现
string s1 = "hello world";
//从下标 5 开始的 1 个字符替换成”20%“
s1.replace(5, 1, "%20");
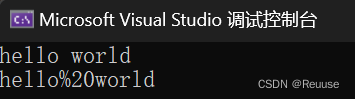
会挪动数据,导致效率很低
String operations
- c_str
取读文件,接口更兼容c
⭐代码实现
当然,如果你是vs编译器的话需要加上
#define _CRT_SECURE_NO_WARNINGS 1
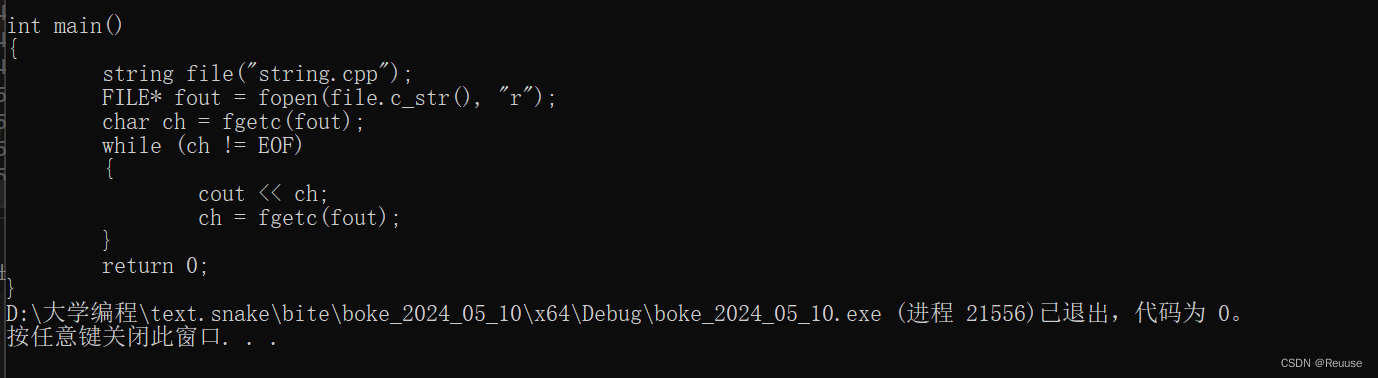
string file("string.cpp"); //你命名什么就打开什么文件
FILE* fout = fopen(file.c_str(), "r");
char ch = fgetc(fout);
while (ch != EOF)
{
cout << ch;
ch = fgetc(fout);
}
以上代码便会读取你现在所编译的所有代码
-
find
找到字符串

-
substr
取出一个字串生成新对象返回
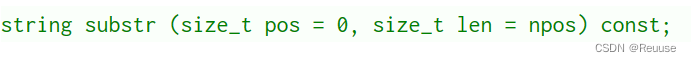
注意:第一个值是从哪里开始,第二个值是取多长

★怎么取出一个文件的后缀名★
void func()
{
string file("string.cpp");
size_t pos = file.rfind('.'); //倒着找点
string suffix = file.substr(pos, file.size() - pos);
cout << suffix << endl;
}
int main()
{
//如果我们要取出文件的后缀要怎么办
func();
return 0;
}
答案
★怎么分割网址★
string url("https://blog.csdn.net/Reeuse?spm=1010.2135.3001.5343");
size_t pos = url.find(':');
//现在我们取第一段"https"
string url1 = url.substr(0, pos);
cout << url1 << endl;
//从':'开始往后 3 个字符跳过'//'后,找下一个'/'
//此时 pos1 点位于 "blog.csdn.net" 后的 '/'
size_t pos1= url.find('/', pos + 3);
//pos1 - (pos + 3)两个位置相减便可以得出要取的字符有多长
string url2 = url.substr(pos + 3, pos1 - (pos + 3));
//取出第二段"blog.csdn.net"
cout << url2 << endl;
string url3 = url.substr(pos1 + 1);
//这里如果不写长度会默认整型的最大值
cout << url3 << endl;
⭐运行结果


秘密学习资料
★衍生知识★
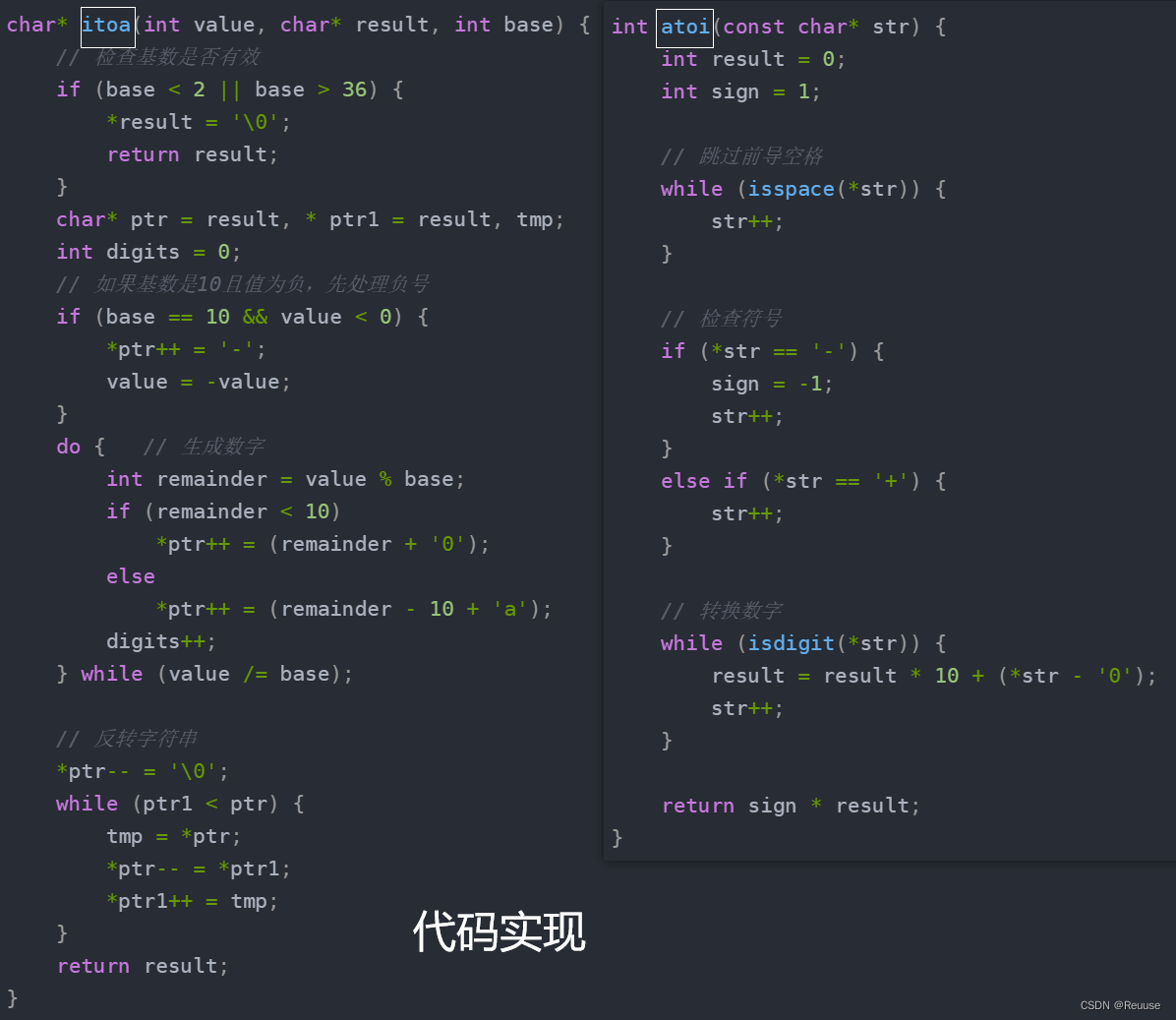
在c语言中字符串与整形互转是:atoi itoa
⭐头文件
#include <ctype.h> // 用于 isdigit 函数
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
⭐代码实现
然而在C++里面已经不需要这么麻烦了
- to_string
把整形转换成字符串
⭐代码实现
//类型转换
int x = 0, y = 0;
cin >> x >> y;
string str = to_string(x + y);
//那么相对应的,字符串转整形也很简单
int z = stoi(str);
完
如果大家喜欢的话就给一个小小的赞吧!
你的一个鼓励是对我创作最大的支持!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









