






1、系统函数
------------------------ -----【系统函数】-------- ------------------------ select current_database(); --获取当前的库名 select current_user(); --获取当前登录的用户 select current_groups(); --获取当前组名列表 select coalesce(null,null,3,4,5); --返回第一个非空值 3 可乐s 联合;合并 select version(); --查看hive版本
2、字符串函数
-------------------------
-----【字符串函数】--------
--------------------------
--1、对称加密
--key 16,24(键只能是16位或者是24位)
select base64(aes_encrypt('account=yuan123&password=abc123456','kb17kb17kb17kb17'));
select aes_decrypt(unbase64('8CF0coWdWEsDG29fNUV+gE3O0U27NxAPXXAfrfnVzHj/kB08H6O386NMCxCe6u+3'),'kb17kb17kb17kb17');
--2、非对称加密+salt
select md5('abc');
--select concat('abc','de'); --拼接字符串 结果为abcde
select md5(concat('kb17','12345','kgc'));
select sha('abc');
select sha2('abc',224); --参数2(固定数字224,256,384,512,使用其他数字则为空)
--3、简单加密
select base64(cast('I 爱 you' as binary));
select unbase64('SSDniLEgeW91');
--4、ASCII码转换和字符转换
select ascii('A');
select chr('65');
--5、字符集转换
select encode('I爱you','UTF-8');
select decode(encode('I爱you','UTF-8'),'UTF-8');
--6、字符长度
select character_length('I 爱 you'); --汉字算一个字符,空格也算一个字符 --7
select char_length('I 爱 you'); --7
select length('I 爱 you'); --7
select cast('I 爱 you' as binary); --'4920E788B120796F75'
select length(cast('I 爱 you' as binary)); --字节长度 --9 汉字的字节长度是3
--7、拼接字符串
select concat('hello',' ','world'); --以空格拼接字符串
select concat_ws(',',"aa","bb","cc"); --以指定连接符(逗号)拼接字符串
select concat_ws(',',array("aa","bb","cc")); --以指定连接符(逗号)拼接字符串数组
--8、分词和词频统计
select sentences("are you OK? I'm so happy. Will you come?"); --词频统计(限定单词数量)以逗号把每个句子分割成每个数组
select ngrams(sentences("are you OK? I'm so happy. Are you come? Are you will,I'm so right? Are we together? Are they going to join us?"),2,3); --词频统计(限定单词的数量和部分内容)
select context_ngrams(sentences("are you OK?I'm so happy.Are you come? Are you will,I'm so right? are we together? are they going join us?"),array('are',null),2);
--9、提取
--按参数2分割参数1字符串,提取连续的n(n>0从左侧提却,n<0从右侧提取)个元素
select substring_index("aa,bb,cc",",",-2);
select elt(3,"aa","bb","cc"); --根据参数1位置提取参数2指定位置元素
select index(array(1,2,3),0); --根据参数2下标提取参数1数组元素,下标从0开始
--10、按逗号分割参数2字符串,提取参数1字符串在分割后的位置(>=1)
select find_in_set("bb","aa,bb,cc"); --返回参数1在参数2以逗号分割集中的位置
select locate("aa","bbaacc",1) ; --从参数3(包含)指定的位置开始查找并返回参数1首字母的位置 从1的位置开始找aa的位置结果返回3
select instr("aabbcc","bb"); --从参数1中找到参数2的位置 --在aabbcc中找bb ,结果返回是3
select field("aa","aa","bb","cc"); --根据参数1元素提取其在参数2中的位置 --找aa的位置,结果返回1
--11、相似性
select levenshtein("abc","bcd"); --返回两个参数字符串之间内容的相似性,本次结果是2
select soundex('abc'); --返回参数字符串解析后的四位符号(字符串发音相似性)
--12、字符串替换
select replace('aa123aa456','aa','-'); --固定内容替换 把aa替换成-
select translate('abc123ab456a889b','abc','XYZ'); --参数2和3按字符定位匹配替换 --a用X替换,b用Y替换,c用Z替换
select regexp_replace('123ab456defg789','[a-z]','_'); --正则替换
--13、条件函数
select 'abxemn' like 'ab_e%'; --模糊匹配
select 'abc123' rlike '^[a-z]{3}[0-9]{3}$'; --正则匹配
--14、大小写转换
select upper('abc'); --转大写
select lower('ABC'); --转小写
select initcap('abc'); --首字母大写
--15、填充函数
select lpad('123',6,'0'); --向参数1字符串左侧填充参数2-length(参数1)个参数3符号 000123
select rpad('123',6,'0'); --向参数1字符串右侧填充参数2-length(参数1)个参数3符号 123000
--16、简单函数
select repeat('abc',3); --返回将参数1重复参数2遍后的字符串
select reverse('abc'); --字符串转置 cba
--查看某列数据是否存在于文件中(文件按行识别)
select name,in_file(name,'root/hive/in_line_test.log') as yes_or_no from default.users;
select java_method('java.lang.String','valueof',123); --调用java的类方法
select uuid(); --生成32位随机序列
select split('abc,def;ghi',',|;'); --正则分裂为字符串数组
select stack(2,1,3,4,5,6); --分为参数1组炸裂(参数2的元素数量必须被参数1整除)
select substr('abcdef',2,3); --截取字符串(参数2为从1开始的位置,参数2位截取字符长度)
--格式化字符串
select printf('%s,%s,%d,%.2f','henry','M',18,2345.28456);
--17、去除空格
select length(ltrim(' abc ')); --去除左边的空格部分,返回右边的字符长度8
select length(rtrim(' abc ')); --去除左边的空格部分,返回左边的字符长度6
select length(trim(' abc ')); --去除左右两边的空格部分,返回右边的字符长度3
--18、隐藏内容
select mask('abc'); --全部隐藏为xxx
select mask_first_n('abc',2); --从左开始隐藏2个字符 xxc
select mask_last_n('abc',2); --从右开始隐藏2个字符 axx
select mask_hash('abc'); --转为固定位数,(乱码)
--19、解析json格式字符串(一次解析一个属性,但支持嵌套)
select get_json_object('{"name":"henry","friends":[1,2,3],"address":{"province":"jiangsu","city":"nanjin"}}',"$.name"); --结果是henry
select get_json_object('{"name":"henry","friends":[1,2,3],"address":{"province":"jiangsu","city":"nanjin"}}',"$.friends[0]"); --结果是1
select get_json_object('{"name":"henry","friends":[1,2,3],"address":{"province":"jiangsu","city":"nanjin"}}',"$.address.city"); --结果是nanjin\
--解析json格式字符串(一次解析多个属性,但不支持嵌套)
select json_tuple('{"name":"henry","friends":[1,2,3],"address":{"province":"jiangsu","city":"nanjin"}}',"name","address"); --henry {"province":"jiangsu","city":"nanjin"}
--20、解析url格式字符串
--【HOST】,【PATH】【QUERY】【REF】,PROTOCOL,AUTHORITY,FILE, and USERINFO
select parse_url('https://www.cnblogs.com/kangxinxin/p/11585935.html','PATH');
select parse_url('https://mp.weixin.qq.com/s?__biz=MzAwMTUwNDM3Mw==&mid=2654155324&idx=1','QUERY','__biz');
select parse_url_tuple('https://mp.weixin.qq.com/s?__biz=MzAwMTUwNDM3Mw==&mid=2654155324&idx=1','HOST','PROTOCOL','PATH');
--正则分组提取
select regexp_extract('__biz=MzAwMTUwNDM3Mw==&mid=2654155324&idx=1','__biz=(.*?)==&mid=(.*?)&idx=(.*)',3);
3、数学函数
------------------------
-----【数学函数】--------
------------------------
--1、简单基础函数
select e();
select pi();
select abs(-3);
--2、进制转换
select bin(123); --10进制转换为2进制形式
select conv('abc',16,2); --不同进制之间相互转化
select hex('123'); --按符号ASCII码转换16进制 313233
select unhex('313233'); --hex逆向操作 123
--3、舍入函数
select round(3.145); --舍入法,默认取整
select round(3.145,2); --舍入法,设定精度
select ceil(3.00001); --向上取整
select `floor`(3.999999); --向下取整
select bround(3.35,1); --精度后一位<=4舍,>=6入,==5精度位 偶数 舍舍 ,奇数入
--4、幂运算
select cbrt(8); --立方根
select sqrt(4); --平方根
select pow(4,1/3); --幂运算
select exp(2); --E的n次幂
--5、对数函数
select ln(pow(e(),2)); --E为底
select log2(8); --2为底
select log10(100); --10为底
select log(2,100); --以参数1为底
--6、角度弧度互转
select degrees(pi()/2); --弧度转角度 90°
select radians(180); --角度转弧度 3.141592653589793
--7、阶乘
select factorial(4); -- 4*3*2*1 = 24 阶乘
--8、极限值
select greatest(2,5,1,7,3); --获取参数中最大值
select least(2,5,1,7,3); --获取参数中最小值
--数组字段最大值
select id,max(friends) as max_friend from friends,lateral view explode(friends) LV as friend group by id;
--9、生成直方图数据
select histogram_numeric(order_money,5) from db_01.hive_history_order;
--[
-- {"x":303.6794394852022,"y":97125.0},
-- {"x":888.6105143875009,"y":97689.0},
-- {"x":1476.334178131634,"y":99724.0},
-- {"x":2065.8121871309795,"y":102463.0},
-- {"x":2688.909913003765,"y":105062.0}
-- ]
select histogram_numeric(rating,10) from db_01.ods_ratings;
--[{"x":0.49999999999999994,"y":393068.0},
-- {"x":1.0,"y":776815.0},
-- {"x":1.5,"y":399490.0},
-- {"x":2.0,"y":1640868.0},
-- {"x":2.5,"y":1262797.0},
-- {"x":2.9999999999999996,"y":4896928.0},
-- {"x":3.5,"y":3177318.0},
-- {"x":3.9999999999999996,"y":6639798.0},
-- {"x":4.5,"y":2200539.0},
-- {"x":5.0,"y":3612474.0}
-- ]
--10、取值
select mod(5,3); --余2
select pmod(5,3); --余2
--1、符号函数
select sign(-6); --获取数值的符号 整数:1,负数:-1
select positive(6); --返回数值本身 6
select negative(6); --返回相反数 -6
--12、位运算
select shiftleft(5,1); --5的二进制:101 10(1010)
select shiftright(5,1); -- 2(0010)
select shiftrightunsigned(5,1); --2
--13、返回参数列表的hash值
select hash(10,12); --322
4、日期函数
------------------------
-----【日期函数】--------
------------------------
--1、获取
select `current_date`(); --获取系统当前日期
select `current_timestamp`(); --获取系统当前时间 2022-05-02 14:41:23.521000000
select unix_timestamp(); --获取系统时间戳(单位:秒) 1651473707
--2、转换
--默认完整格式 yyyy-MM-dd HH:mm:ss 年、月、日、时、分、秒
select unix_timestamp('2022-04-28 00:00:00'); --1651104000
--指定格式,格式不匹配返回null
select unix_timestamp('2022-04-28','yyy-MM-dd HH'); --NULL
--获取时间戳对应的指定格式日期
select from_unixtime(1651104000); --2022-04-28 00:00:00
--将日期格式化为指定格式
select from_unixtime(1651104000,'yyyy-MM-dd'); --2022-04-28
--将时间格式转化为日期格式
select to_date('2022-04-28 02:15'); --2022-04-28
--3、提取
--select year|quarter|month|date|hour|minute|second
select quarter(`current_date`()); --获取参数日期(今天2022-5-2)为当前的第几个季度 2
select day(`current_date`()); --等同于dayofmonth (今天2022-5-2) 2
--4、计算
select add_months(`current_date`(),-3); --将参数1日期上加上参数2个月份后的日期返回 (今天2022-5-2)->2022-02-02
select date_add(`current_date`(),5); --将参数1日期加上参数2个天数后的日期返回 (今天2022-5-2)->2022-05-07
select date_sub(`current_date`(),2); --将参数1日期减去参数2个天数后的日期返回 (今天2022-5-2)->2022-04-30
select months_between('2022-10-19',`current_date`()); --计算2个日期之间的月差数 (今天2022-5-2)->5.5483871
select weekofyear(`current_date`()) ; --返回参数日期的周为该年的第多少周
--5、最后一天
--年最后一天
select concat_ws('-',cast(`current_date`() as string),'12-31'); --2022-05-02-12-31
--3 6 9 12
--季度最后一天
select concat_ws('-',
cast(year(`current_date`())as string),
cast(quarter(`current_date`())*3 as string),
cast(`if`(quarter(`current_date`())%3==1,31,30) as string)); --(今天2022-5-2) ->2022-6-30
--最后一天
--计算年最后一天
select concat_ws('_',cast(year(`current_date`())as string) ,'12-31');
-- 3 6 9 12
--计算季度最后一天
select concat_ws('-',cast(year(`current_date`()) as string),
cast(quarter(`current_date`())*3 as string),
cast(`if`(quarter(`current_date`())%3==1,31,30) as string));
--计算该月的最后一天
select last_day('2022-10-19'); --2022-10-31
select next_day(`current_date`(),'SU'); --获取参数一对应日期的下一个参数2格式星期几的日期 2022-05-08
select `dayofweek`(`current_date`()); --返回参数对应日期的星期几(sunday-saturday 1~7) 2
--计算周最后一天
select date_add(`current_date`(),7-`dayofweek`(`current_date`()));
select if(`dayofweek`(`current_date`())==7,`current_date`(),next_day(`current_date`(),'SA'));
--6、第一天(今天是2022-05-02,星期一)
select floor_year(`current_timestamp`()); --2022-01-01 00:00:00.000000000
select floor_quarter(`current_timestamp`()); --2022-04-01 00:00:00.000000000
select floor_month(`current_timestamp`()); --2022-05-01 00:00:00.000000000
select floor_week(`current_timestamp`()); --2022-05-02 00:00:00.000000000
select floor_day(`current_timestamp`()); --2022-05-02 00:00:00.000000000
select floor_hour(`current_timestamp`()); --2022-05-02 15:00:00.000000000
select floor_minute(`current_timestamp`()); --2022-05-02 15:55:00.000000000
select floor_second(`current_timestamp`()); --2022-05-02 15:55:55.000000000
5、窗口函数:
over():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的改变而 变化。
current row: 当前行
n preceding:往前 n 行数据
n following:往后 n 行数据
unbounded:起点
unbounded preceding 表示从前面的起点
unbounded following 表示到后面的终点
lag(col,n,default_value): 往前第 n 行数据
lead(col,n,default_value): 往后第 n 行数据
ntile(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行,ntile 返回此行所属的组的编号。注意:n 必须为 int 类型。
------------------------ -----【窗口函数】-------- ------------------------ -- row_number() 行号(可以去重) -- rank() 排名(若存在并列会跳号) 1 1 3 4 5 6 -- dense_rank() 排名(并列不跳号) 1 1 2 3 -- ntiles(n) 切成n片 -- lead(n) 后第N行 -- log(n) 前第n行 -- percentile(0.25,0.5,0.75) 百分数为(限整数) -- percentile_approx(f1,0.25,0.5,0.75) 百分数为(可以面向小数) -- cume_dist(f1) 提取小于当前列值的记录数 -- first_value(f1) 提取窗口内某字段第一条数据 -- last_value(f1) 提取窗口内某字段最后一条数据 -- percent_rank() 分组内当前行的RANK值-1/分组内总行数-1 select * from hive_temp_order limit 20; select percentile_approx(order_money,`array`(0.2,0.4,0.6,0.8)) from hive_temp_order;
------------------------ -----【窗口函数】-------- ------------------------ --1、功能:扩展列 --1、1 窗口类型 --物理窗口:以行为单位,以当前行为基准,向上或向下控制窗口粒度, rows between N(n preceding) and M(m following) --逻辑窗口:默认窗口,以指定值为基准单位,向前或向后控制窗口粒度 range between N(n preceding) and M(m following) --窗口的控制 unbounded preceding --向上无边界,到上边界 n preceding current row unbounded following --向下无边界,到下边界 n following --默认粒度 --全表(类似于笛卡尔积) over() --分组(当前行xxx列值对应的分组) <=> unbounded preceding and unbounded following over(partition by xxx) --range between unbounded preceding and current row (<=value(f2)) over(partition by f1 order by f2) --控制粒度 over(... rows|range between (n|unbounded) preceding |current row and m|unbounded following) --列的特征:f1=f2=f3 || f1<>f2<>f3 func(f1) over(partition by f2 order by f3) --优化 --窗口粒度相同的多个任务会被合并到同一个job中 --select f1,count|sum|avg(distinct f2) from T group by f1 X select f1,count|sum|avg|(f2) as... from select f1,f2 from T group by f1,f2 )T group by f1 --2、语法 select necessary_original_fields, agg_func | window_func over([partition by | distribute by | clustered by original_fields[ order by | sort by original_fields]]) --练习 create external table hive_window_test( id int, name string, score decimal(2,1) ) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile location '/hive/window_test'; load data local inpath '/hive/window_test/window_test' overwrite into table db_01.hive_window_test; select * from db_01.hive_window_test; set mapreduce.job.reduces=4; select id,name,score, --sum(score) over() as s, --sum(score) over(partition by id ) as s_p, sum(score) over (partition by id order by score) as s_p_c, sum(score) over (partition by id order by score rows between unbounded preceding and current row ) as s_p_o_u_s, sum(score) over (partition by id order by score rows between 2 preceding and 1 preceding) as s_p_o_2p_1p, sum(score) over (partition by id order by score rows between 1 preceding and 1 preceding) as s_p_o_1p_1r, sum(score) over (partition by id order by score range between 1 preceding and 1 preceding) as s_p_o_1p_1r from hive_window_test; select id ,name,score, row_number() over (partition by id order by score rows between unbounded preceding and unbounded following) as rn_p_o_u_r, rank() over (partition by id order by score rows between unbounded preceding and unbounded following) as rnk_p_o_u_r, dense_rank() over (partition by id order by score rows between unbounded preceding and unbounded following) as drnk_p_o_u_r from hive_window_test order by id,score desc ; select id,name,score, ntile(3) over(partition by id) as nt_p_o_u_r from hive_window_test;
6、行列转换函数
------------------------
-----【行列转换函数】--------
------------------------
--1、行转列
select explode(`array`(1,2,3));
select explode(split("aa,bb,cc",','));
select posexplode(split("aa,bb,cc",','));
--select A.f1,B.f2 from A,lateral view explode(split(delimited_str)|array) B as f2
--select A.f1,B.pos,B.v from A,lateral view posexplode(array) B as pos,v
--select A.f1,B.k,B.v from A,lateral view explode(map) B as k,v
--select A.f1,B.f2,B.f3 from A lateral view inline(struct) B as f2,f3;
select S.stu_name,S.stu_age,S.stu_gender,
LVH.hobby,
LVS.subject,LVS.score,
LVA.city,LVA.district,LVA.province
from db_01.student_info S
lateral view explode(stu_hobby) LVH as hobby
lateral view explode(stu_scores) LVS as subject,score
lateral view inline(array(stu_address)) LVA as province,city,district;
-- 2、列转行(多行转一列)
--聚合函数 (聚合和explode是互逆的)
-- sum avg count max min
--collect_list collect_set concat_ws
select concat_ws('_',"aa","bb","cc"); --aa_bb_cc
select concat_ws('_',`array`("aa","bb","cc")); --aa_bb_cc
-- corr相关系数 stddev_pop标准差 var_pop方差 covar_pop协方差
--列转行(多行转多列)
--行转列 split
7、逻辑控制函数
------------------------ -----【逻辑控制函数】---- ------------------------ select `if`(false,1,2); --双分支(三目运算) 返回2 --switch,..case select case quarter(`current_date`()) when 3 then 31 when 6 then 30 else 30 end ; --30 --if,...else if.... select case when 5>6 then 'hello' else 'world' end ; --world select isnull(null); --验证参数是否为空 select isnotnull(null); --验证参数是否为空 select `if`(1 is null,1,2); --对参数1是否为空做不同处理 结果2 select nullif(1,2); --两个参数值相同返回null,否则返回参数1 select nvl(null,2); --参数1为null返回参数2,否则返回参数1
8、集合函数
------------------------
-----【集合函数】--------
------------------------
--array<T> | map<k,v> | struct<f1:T1,...,fn:Tn> struct_filed.f1
--1、创建
select `array`(1,2,3)[2]; --构建一个数组,根据下标取值 3
select `map`(1,'henrry',2,'pole')[2]; --构建一个map,根据键取值 pole
select str_to_map("1:henrt,2:pola",',',':');--将文本转化为map {"1":"henrt","2":"pola"}
select struct(1,'henry',18,'male'); --构建自动命名机构体 {"col1":1,"col2":"henry","col3":18,"col4":"male"}
select named_struct("id",1,"name","henry","age",18,"gender","male"); -- 构建指定命名结构体 {"id":1,"name":"henry","age":18,"gender":"male"}
--2、验证
select array_contains(`array`(1,2,3),5); --返回数组中是否包含元素
--3、提取
select map_keys(`map`(1,'henrry',2,'pole')); --提取map所有键集合 [1,2]
select map_values(`map`(1,'henrry',2,'pole')); --提取map所有值集合 ["henrry","pole"]
select arr[0];
select map[key];
select struct.field;
--4、容量
select id,size(friends) from friends; --获取集合元素数量
--5、排序
select sort_array(`array`(3,1,4,2,5));
select sort_array_by(
`array`(
named_struct("id",1,"name","henry1","age",18),
named_struct("id",2,"name","henr1","age",16),
named_struct("id",3,"name","hen1","age",26),
named_struct("id",4,"name","he1","age",15),
named_struct("id",5,"name","h1","age",19)
),
"age","desc" ['asc|desc']
);
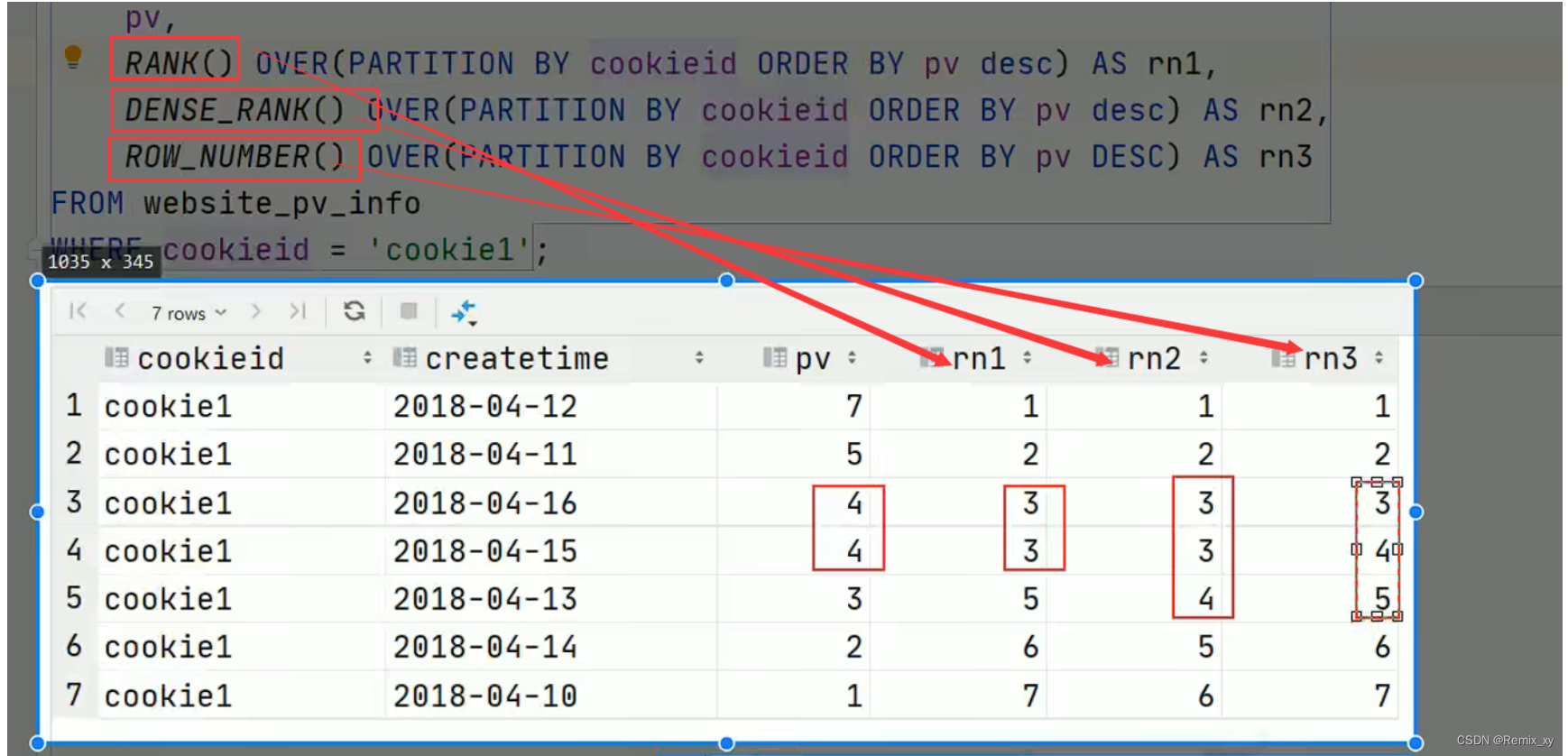
9、Rank
函数说明
rank() 排序相同时会重复,总数不会变
dense_rank() 排序相同时会重复,总数会减少
row_number() 会根据顺序计算















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









