







💞💞 前言
hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹
💥个人主页:大耳朵土土垚的博客
💥 所属专栏:C++入门至进阶
这里将会不定期更新有关C++的内容,希望大家多多点赞关注收藏💖💖

💥本篇博客将使用string类求解五个题目,包括题目链接,解题思路以及实现代码,题目中有关函数的理解和使用,也会挑出一些来介绍🥳🥳
☑️找出字符串中第一个只出现一次的字符
✨✨题目链接点击跳转
解题思路:
这里可以参考我们之前学习过的计数排序:
①先定义一个int数组,大小为26*sizeof(int),用来一一对应26个字母(小写),记录每个字母出现的次数;
②然后遍历题目中的字符串s,计算出每个字母的个数存放在之前定义的数组中;
③最后再通过遍历原字符串s找出第一次只出现一次的字符。
代码如下:
#include <iostream>
using namespace std;
#include<string>
int main()
{
string s; //原字符串
cin>>s;
int count[26] = {0} ; //开辟一个数组计数
for(auto ch : s) //范围for遍历
{
count[ch-'a']++; //计数
}
for(auto ch : s) //再次遍历找到第一个出现一次的字符
{
if(count[ch-'a'] == 1)
{
cout<<ch; //找到了打印该字符
return 0;
}
}
cout<<-1; //没找到输出-1
return 0;
}
这里遍历string类可以参考【C++】学习string类:字符操作的艺术这篇文章讲述的三种方法;
结果如下:
☑️字符串里面最后一个单词的长度
✨✨题目链接点击跳转
解题思路:
①使用getline函数(后文有解析)获取一行字符串;
②使用rfind函数(使用方法在后文)从字符串末尾往前找到第一个空格,返回该空格的位置;
③使用size函数得到整个字符串长度,减去之前空格的位置再-1,得出最后一个单词的长度。
#include <iostream>
using namespace std;
#include<string>
int main()
{
string s;
getline(cin,s); //获取一行字符串
int pos = s.rfind(' ');//从后往前遍历找到空格的位置
int length = s.size() - pos-1; //计算最后一个单词长度
cout<<length; //打印长度
}
结果如下:
🥳🥳getline使用方法:
- getline是C++中用于从输入流中读取一行文本的函数。它通常与std::cin结合使用。
示例如下:
#include <iostream>
#include <string>
int main() {
std::string line;
std::cout << "请输入一行文本:";
std::getline(std::cin, line);
std::cout << "你输入的内容是:" << line << std::endl;
return 0;
}
在上面的代码中,
std::getline(std::cin, line)将从标准输入流(std::cin)中读取一行文本,并将其存储到名为line的字符串变量中。然后,我们可以使用std::cout打印出用户输入的内容。
- getline函数还可以接受可选的第三个参数delim,用于指定行分隔符。默认情况下,行分隔符为换行符(\n)。可以将其修改为其他字符,如:
std::getline(std::cin, line, ';');
这将使用分号作为行分隔符
🥳🥳rfind函数使用方法:
- rfind是C++中的字符串成员函数,用于从字符串的末尾开始查找指定的子字符串,返回最后一次出现的位置。如果未找到子字符串,则返回std::string::npos。
示例如下:
#include <iostream>
#include <string>
int main() {
std::string str = "Hello world, hello C++";
std::size_t found = str.rfind("hello");
if (found != std::string::npos) {
std::cout << "子字符串在位置 " << found << " 处找到了" << std::endl;
} else {
std::cout << "未找到子字符串" << std::endl;
}
return 0;
}
结果如下:
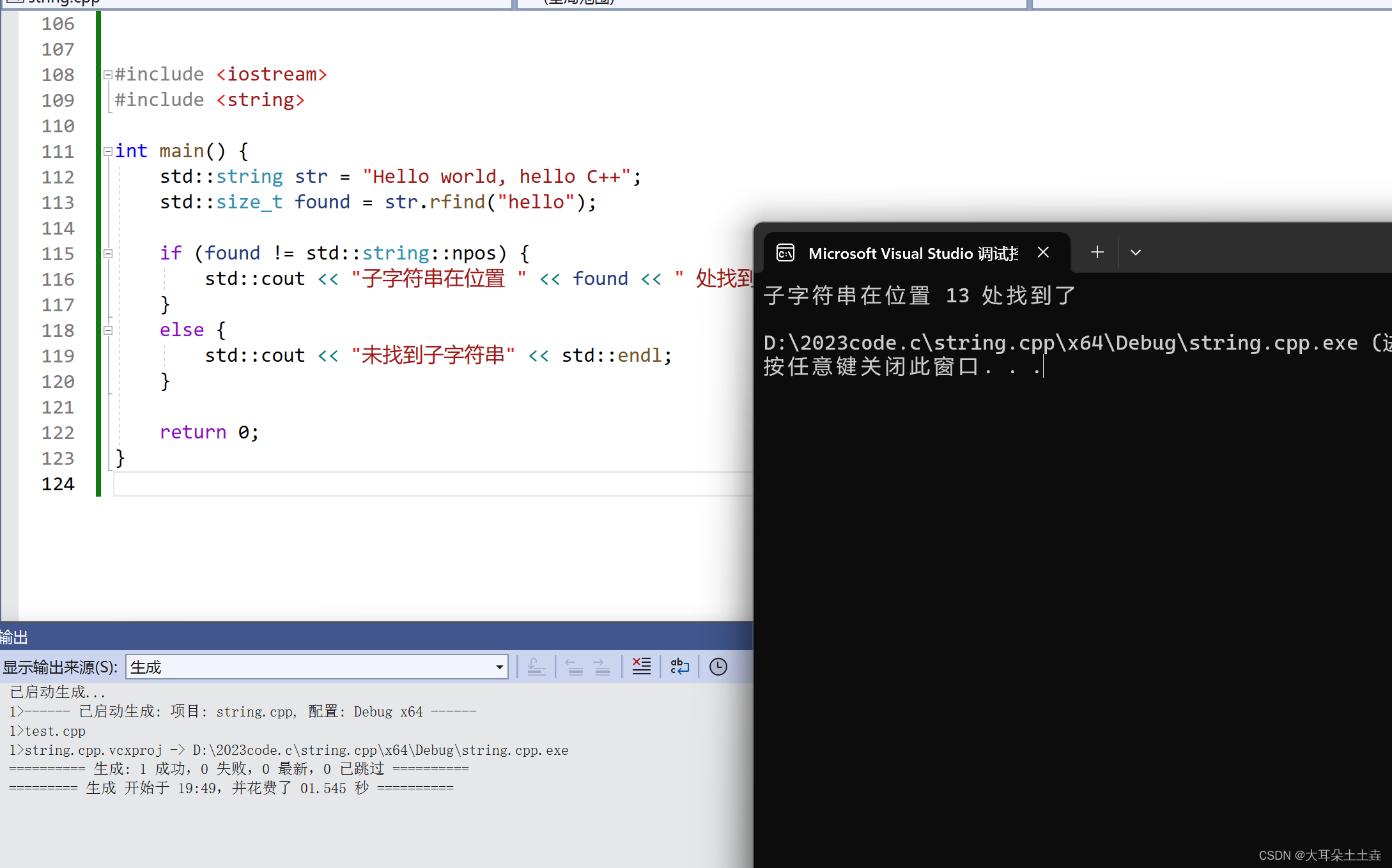
在上面的代码中,rfind函数从字符串的末尾开始搜索子字符串hello。如果找到了,则返回子字符串的起始位置。如果未找到,则返回std::string::npos。
- rfind函数还可以接受第二个参数pos,用于指定搜索的起始位置。可以通过调整起始位置来实现在字符串的特定部分进行查找。
示例如下:
std::size_t found = str.rfind("hello", 10);
这将从字符串的前10个字符开始向后搜索子字符串hello。
- 需要注意的是,rfind函数返回的位置是从字符串的起始位置(下标为0)开始计算的。
☑️翻转字符串
✨✨题目链接点击跳转
解题思路:
使用左右指针法:
①定义左右下标,当left < right时,交换它们对应的内容;
②直到left >= right 反转完成。
代码如下:
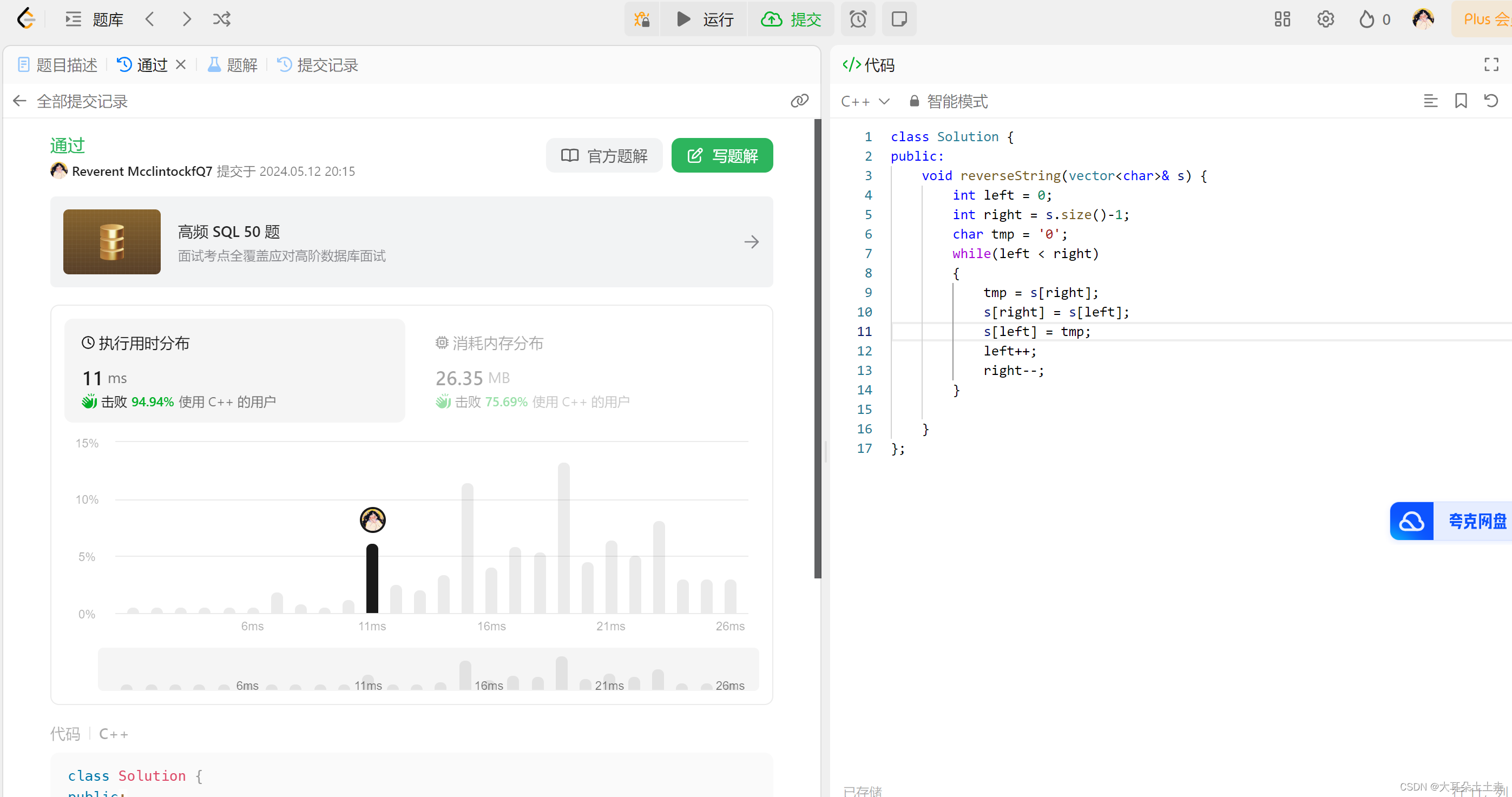
class Solution {
public:
void reverseString(vector<char>& s) {
//定义左右下标
int left = 0;
int right = s.size()-1;
char tmp = '0';
while(left < right) //左右交换
{
tmp = s[right];
s[right] = s[left];
s[left] = tmp;
left++;
right--;
}
}
};
结果如下:
☑️字符串相加
✨✨题目链接点击跳转
解题思路:
采用从后往前遍历两个数组,依次相加的方法,注意要进位:
①定义两个整型分别初始化为两个字符串最后一个字符下标;
②根据下标依次相加,定义整型flag记录进位,如果相加的和大于10,flag就标为1;
④将相加后的和存放在string类中(注意这里直接尾插即可,后面我们再翻转字符串);
代码如下:
class Solution {
public:
string addStrings(string num1, string num2) {
string num; //用来存放相加后的字符
//定义两个整型分别初始化为两个字符串最后一个字符下标;
int end1 = num1.size() -1;
int end2 = num2.size() -1;
int n = 0;
int flag = 0;//记录进位
while(end1>=0 || end2 >=0)
{
int n1 = end1 >= 0 ? num1[end1]-'0' :0; //这里如果end1小于0,那么就将n1赋值为0;end1>=0,说明字符串num1中还有值没加,就将n1赋值为num1[end1] - '0'
int n2 = end2 >= 0 ? num2[end2]-'0' :0; //同上
n = n1+n2; //两数相加
if(flag == 1) //如果有进位,则n++;
{
n++;
}
num+=(n%10+'0'); //将和n转成字符存放到num中
if(n >= 10)
{
flag = 1;//表示要进一位
}
else
{
flag = 0;
}
end1--;
end2--;
}
//最后如果还存在进位,就需要再+1
if(flag == 1)
{
num+='1';
}
//逆置
reverse(num.begin(),num.end());
return num;
}
};
这里有几个关键点:
①当end1<0时,end2>=0;也就是出现一个string中的字符加完了,另一个还剩,这时我们就可以借助三目运算符int n1 = end1 >= 0 ? num1[end1]-'0' :0;将n1赋值为0,继续和n2相加即可,直到end2<0;
②当全部加完后,还要检查一下进位flag是否为1,如果为1,那么num还需要+1
例如:num1 = “11” , num2 = “999” 时,就需要再+1;
③最后不要忘了反转字符串,如果使用头插就不需要反转字符串,但是头插时间复杂度为O(n^2),效率太低。
结果如下:
☑️字符串转整形数字
✨✨题目链接点击跳转

解题思路:
这里要注意看懂题目:
①前导如果有字符那么除了‘±’就是空格,一旦有空格后面一定是连续的空格,所以我们要使用while循环跳过前面的空格直到出现‘±’或者数字;
②还需要通过跳过前导空格后第一个字符是否为-,来判断正负,我们可以使用bool类型sign来判断;
③如果跳过前导空格后第一个字符为‘+/-’,就跳过第一个(下标i++)从第二个字符开始求和;如果是数字则直接从跳过空格后的第一个字符开始求和;
④我们还需要通过一些方法验证计算结果是否溢出int范围的数据,超过了就直接返回最值,但是这里要根据之前判断的符号位来决定返回的是INT_MAX还是INT_MIN;
⑤一旦出现了数字,如果之后又出现了字符则直接返回之前求的值即可,后面的如果还有数字就不用管了;
代码如下:
class Solution {
public:
int myAtoi(string str)
{
bool sign = true; //默认为正数
// 跳过开头可能存在的空格
int i = 0;
while(i < str.size() && str[i] == ' ')
{
i++;
}
//接着判断首个字符是否为正负号
if(str[i] == '-')
{
sign = false; // 该字符串为负数,移至下一个字符接着判断
i++;
}
else if(str[i] == '+') // 字符串为正数,sign已经默认为true,直接移动到下一位即可
i++;
//下面开始对非正负符号位进行判断
if(str[i] < '0' || str[i] > '9') // 正常数字第一位必须为0~9之间的数字,否则就是非法数字
return 0;
int res = 0; //这里res用的int型,需要更加仔细考虑边界情况,但如果用long的话可以省去一些麻烦
int num = 0; //求和
int border = INT_MAX / 10; // 用来验证计算结果是否溢出int范围的数据
while(i < str.size())
{
// 遇到非数字字符,则返回已经计算的res结果
if(str[i] < '0' || str[i] > '9')
break;
// 注意这句话要放在字符转换前,因为需要验证的位数比实际值的位数要少一位, 这里比较巧妙的地方在于
// 1. 用低于int型数据长度一位的数据border判断了超过int型数据长度的值
// 2. 将超过最大值和低于最小值的情况都包括了
if(res > border || res == border && str[i] > '7')
return sign == true ? INT_MAX : INT_MIN;
//开始对数字字符进行转换
num = str[i] - '0';
res = res * 10 + num;
i++;
}
//最后结果根据符号添加正负号
return sign == true ? res : -res;
}
};
结果如下:
🥳🥳这里还提供一种思路:
我们可以先将字符串str中的有效数字及开始的符号位存放在另外一个字符串num中,然后直接将字符串中的字符转换为整型即可;
代码如下:
int myAtoi(string str) {
string num;
// 如果空字符串,直接返回0
if (str.size() == 0)
{
return 0;
}
int flag = 0; // 记录正负
int count = 0; //利用count来判断是否数字中间有别的符号,有的话就直接break;
for (int i = 0; i < str.size(); i++)//遍历字符串
{
while (str[i] == ' ')//跳过前导空格
{
i++;
}
if (count > 1)
{
break;
}
if (str[i] == '-' || str[i] == '+')//记录符号位
{
count++;
num += str[i];
}
else if(str[i] >= '0' && str[i] <= '9')
{
count = 1;
num += str[i];
}
else
{
count++;
}
}
}
将num里面的字符转换为整型求和这里没写,大家感兴趣可以自己试试
结语
以上就是今天的所有内容啦,通过题目的练习相信大家对于string类的理解和使用又提高了一个层次 ~ 完结撒花~🥳🎉🎉
















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











