









本博文地图绘制部分来源于开源中国openthings博主的博客
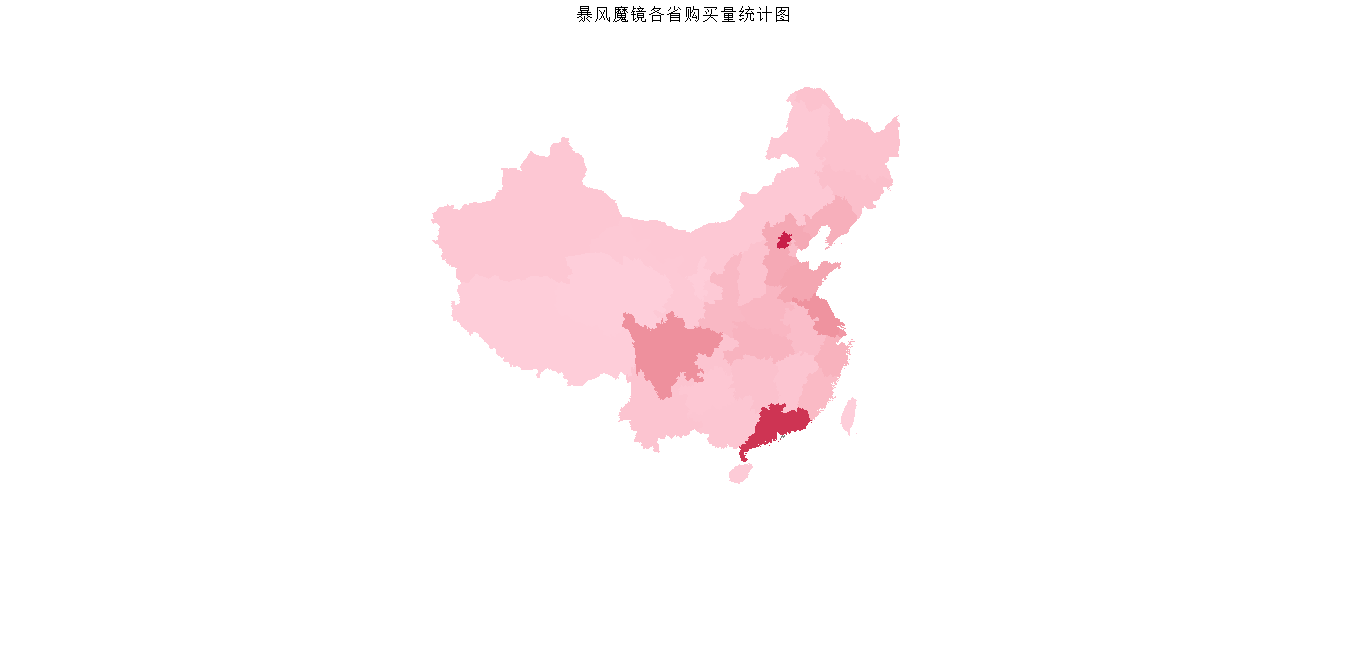
最终效果图:
第一部分为暴风魔镜评论数据的抓取
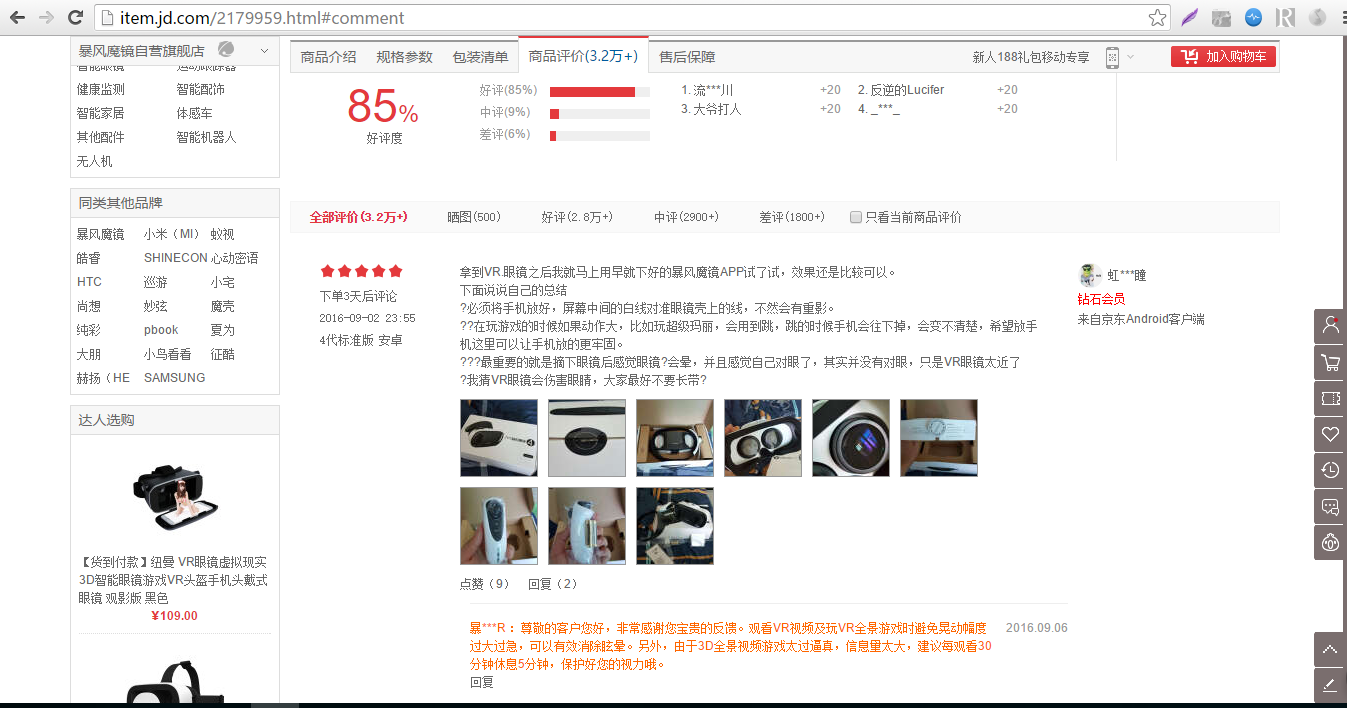
打开京东暴风魔镜的页面,可以看到是下面这个样子的:
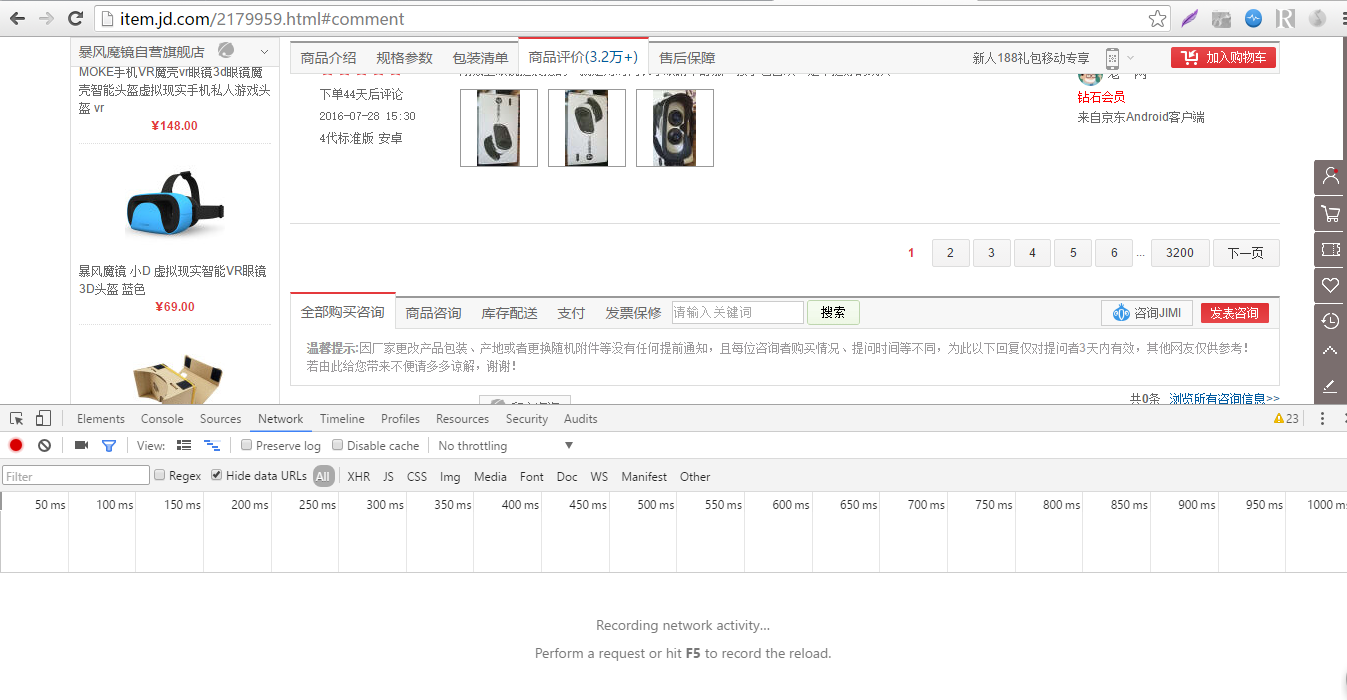
我们要对评论进行抓取,一般电商的评论数据都不是直接放在源代码里面的,都是通过json动态加载的,这时候就要使用到chrome的检查功能了,在网页上右键,选择检查,再点击里面的network选项,就会有如下的场景:
点击下一页,便会看见下面跳出很多东西:
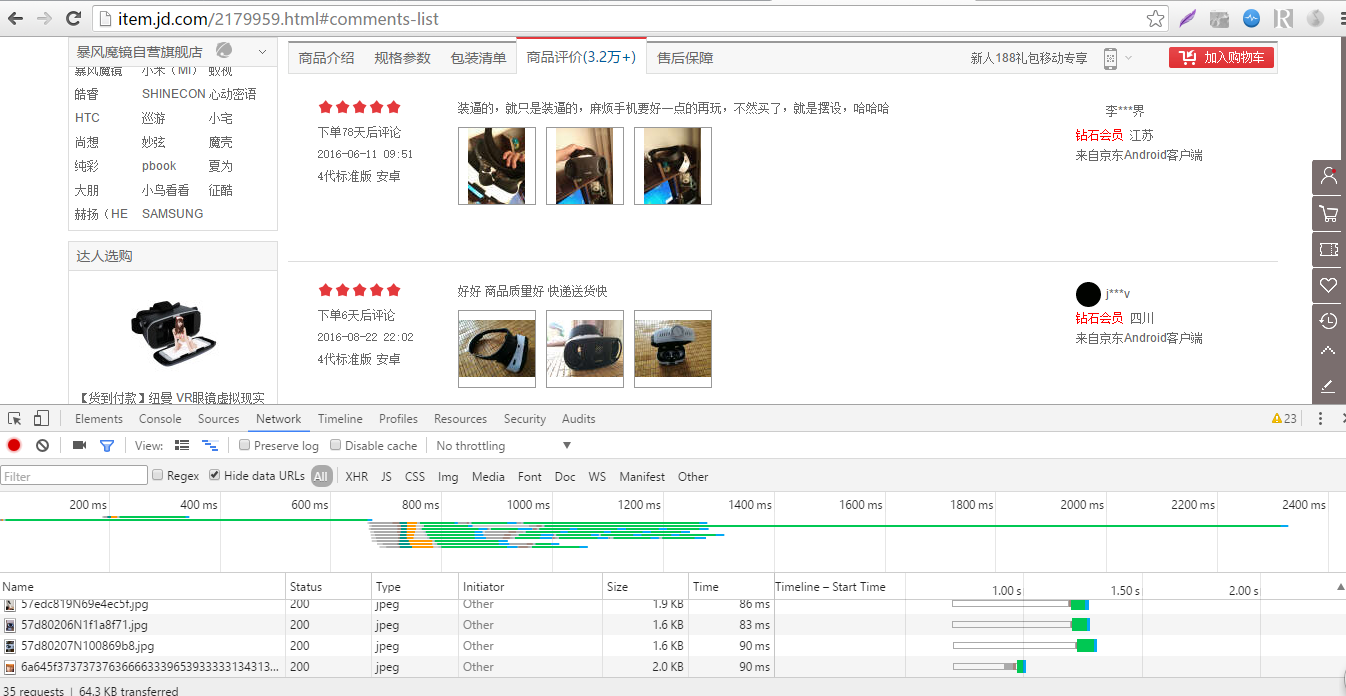
这些东西就是点击之后浏览器接收并加载的数据,从中我们可以找到评论数据,就是下面这个了:
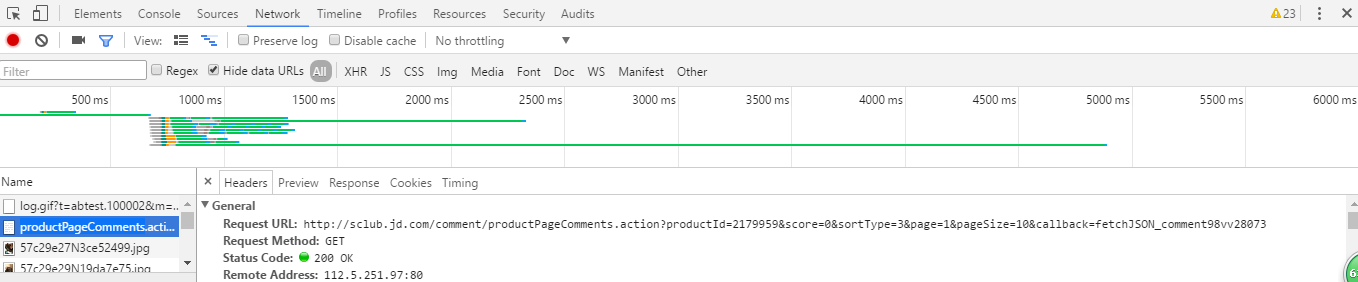
双击左边的文件名就可以打开链接了:
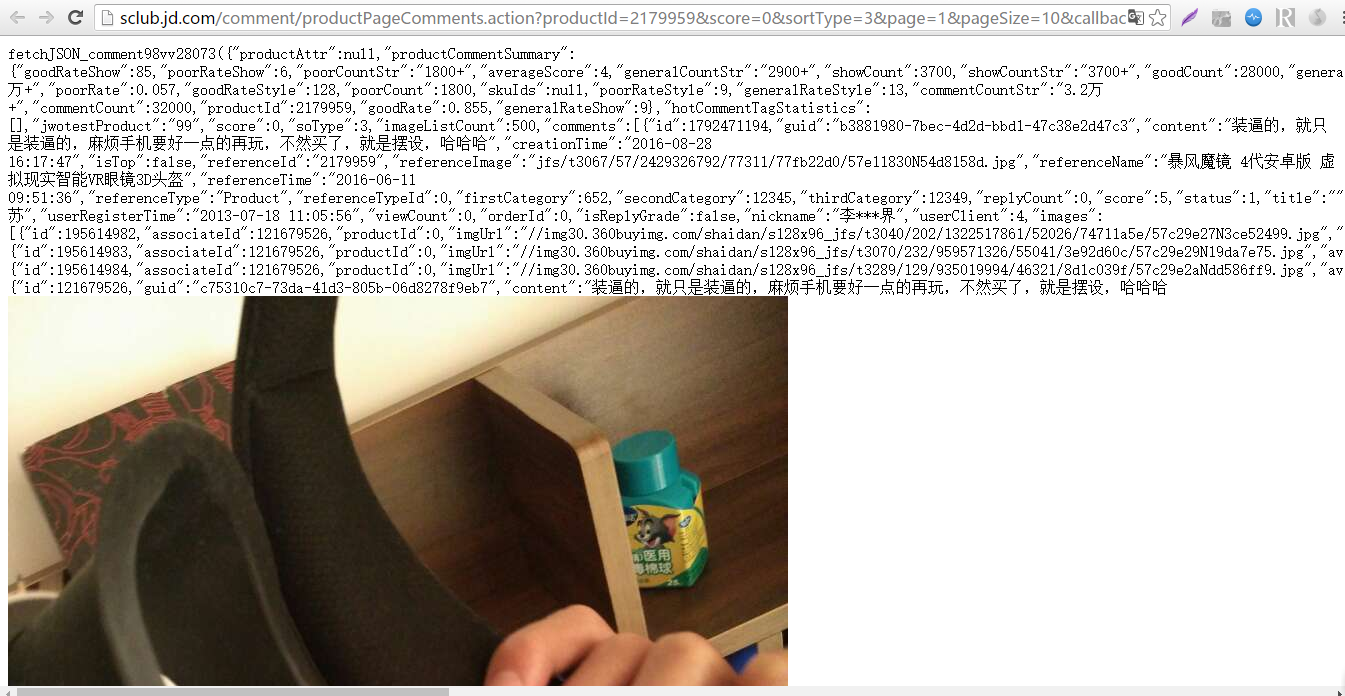
和之前页面比对这确实是评论数据,观察这个网址可以发现网址里面有一个page参数,这个参数应该就是关于获取评论第几页的,试着改变一下这个参数发现确实是这样。
这时候就要开始上R语言了,这种工作我喜欢交给RCurl包去完成(rvest或其他包也可以),我们先把第一页的数据下载下来转化为数据框,再把这个过程包装成一个函数,批量下载。
载入RCurl包之后,使用如下语句得到json数据:
url <- "http://sclub.jd.com/comment/productPageComments.action?productId=2179959&score=0&sortType=3&page=1&pageSize=10&callback=fetchJSON_comment98vv28073"
json_doc <- getURL(url,.encoding = 'gbk')然后用R语言里面的RJSONIO包转化json数据,这个过程是用fromJSON()函数实现的,但这里要注意,之前得到的数据并不是标准的json格式,因为前面有”fetchJSON_comment98vv28073”且被圆括号包围,需要预处理一下,可以用字符串操作处理,这里我选择了stringr包。
library(stringr)
library(RJSONIO)
json_doc <- str_extract(json_doc,'\\{.+\\}')
json_list <- fromJSON(json_doc)其中str_extract()函数抽取被大括号包围的数据,包含大括号本身,R语言本身是贪婪匹配,所以这个过程会抽取完整的json,关于json格式和正则表达式可以自行谷歌。
这个过程之后我们就可以得到一个层层嵌套的列表,我们从中提取评论部分把他们转化为数据框并合并:
library(plyr)
comments <- json_list$comments
comments_list <- llply(comments,function(vec)data.frame(t(vec)))
rbind.fill(comments_list)这里首先载入强大的plyr包,comments为列表中的评论部分,这时comments是一个由10个向量组成的列表,每部分是一条评论的向量,首先用llply()函数把每一部分转化为一个数据框,这时comments_list依然是一个列表,不同的是列表的每一部分变成了数据框,这时就可以用rbind.fill()函数把它们合并起来了,合并为一个包含10条评论的数据框,每个数据框占据一行。
我们可以把这个过程封装成一个函数然后执行批量操作,最终函数如下:
get_comments <- function(url){
#得到内容
json_doc <- getURL(url,.encoding = 'gbk')
#抽取合法的json数据
json_doc <- str_extract(json_doc,'\\{.+\\}')
#把json转化为列表
json_list <- fromJSON(json_doc)
#列表中得到评论部分
comments <- json_list$comments
#把每一条评论转化为一个独立的数据框
comments_list <-llply(comments,function(vec)data.frame(t(vec)))
#合并所有的评论数据框并返回
rbind.fill(comments_list)
}然后进行批量操作:
url <- paste0("http://sclub.jd.com/comment/productPageComments.action?productId=2179959&score=0&sortType=3&page=",0:1000,"&pageSize=10&callback=fetchJSON_comment98vv28014")
comments_data <- llply(url,get_comments,.progress = 'win')
comments_data <- rbind.fill(comments_data)在这里我们抓取评论的前1001页,用llply()函数把get_comments()函数作用到每一个url,这个过程有点漫长,大约有十分钟,所以我们在函数中加入了.progress = 'win'让它显示进度条。
最终得到的数据如图:
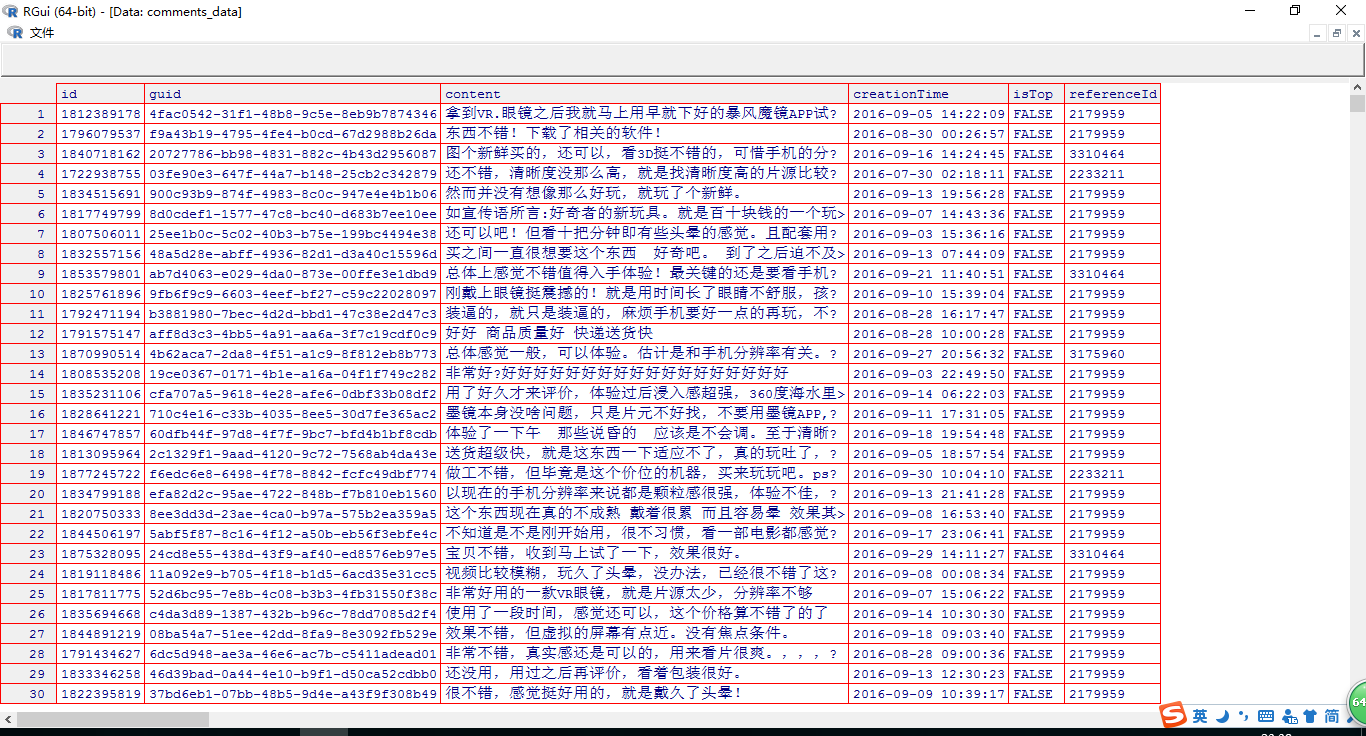
有10010条,一条都没少,之前我抓的时候总是抓不全,现在不知道为什么可以了。
现在就可以进入正题了,我们需要对每条评论的省份进行计数,没有的忽略,然后再利用博文开头提到的那篇博客里面的思路得到坐标,省份和频率的数据框,最后使用ggplot2作图。
代码如下:
china <- readShapePoly('bou2_4p.shp')
china_data1 <- fortify(china)
china_data2 <- china@data
china_data2$id <- 0:924
china_data <- join(china_data1,china_data2,by = 'id')
china_data3 <- china_data[,c(1,2,7,14)]
china_data3$NAME <- substr(china_data3$NAME,1,2)
china_data3$NAME <- ifelse(china_data3$NAME == '内蒙','内蒙古',china_data3$NAME)
china_data3$NAME <- ifelse(china_data3$NAME == '黑龙','黑龙江',china_data3$NAME)
bf_data <- table(unlist(comments_data$userProvince))
bf_data <- as.data.frame(bf_data)
names(bf_data) <- c('NAME','freq')
data_re <- join(china_data3,bf_data,type = 'left',by = 'NAME')
data_re <- data_re[!is.na(data_re$NAME),]
ggplot(data_re,aes(x = long,y = lat,group = group,fill = freq)) + geom_polygon() +
coord_map("polyconic") + scale_fill_gradient(low = '#feceda',high = '#c81f49') +
theme(legend.position = "none",
axis.text.x = element_blank(),
axis.text.y = element_blank(),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank(),
panel.grid = element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
plot.background = element_blank(),
panel.background = element_blank()) +
ggtitle("暴风魔镜各省购买量统计图")
写了两个小时了,太累了不想再写了,就这样吧。。。。。。。















 7452
7452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









