







MapReduce3_核心框架原理
文章目录
0. 概要框架
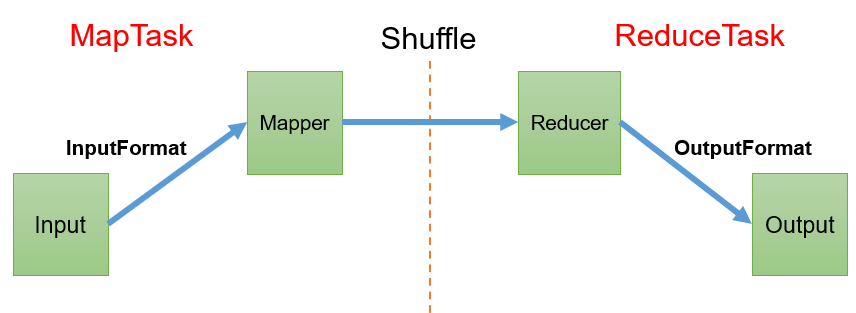
InputFormat从物理块读取数据→切片(逻辑)→切片决定了开启多少个MapTask→Shuffle→分区(逻辑)→分区决定了开启多少个ReduceTask
1. InputFormat数据输入
1.1 切片和MapTask并行度决定机制
- 数据块:HDFS物理存储单位
- 数据切片:MR程序逻辑输入数据的单位,一个切片对应一个MapTask
- 一个job的Map阶段并行度由客户端在提交job时的切片数决定
- 每一个Split切片分配一个MapTask并行实例处理
- 默认切片大小=BlockSize
- 切片时不考虑数据集整体,针对每一个文件单独切片
1.2 Job提交流程源码详解
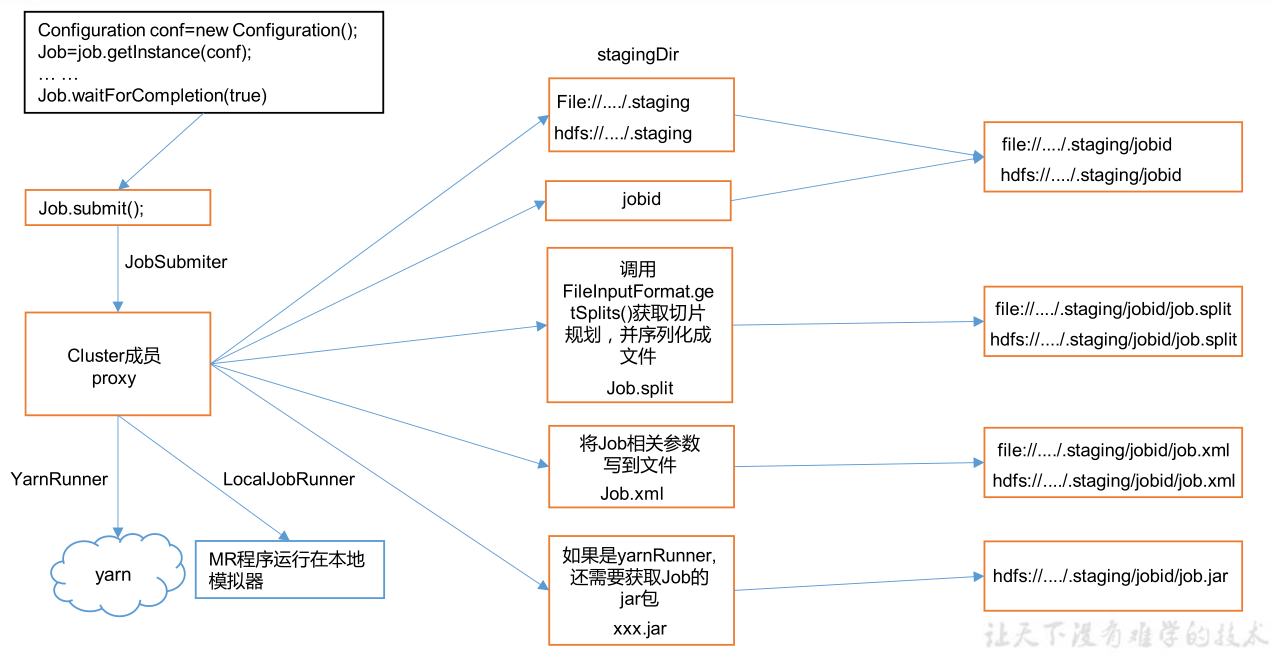
- job.waitForCompletion(true)
- submit()
- →ensureState确定状态,状态不对抛异常
- →setUserNewAPI处理新旧版本兼容性问题
- →connext()
- new Cluster→initialize
- →initProviderList()

- 客户端两种类型Yarn和本地类型
- ⭐submitter.submitJobInternal()
- →checkSpecs()检查路径是否给定以及是否存在
- →getStagingDir(cluster,conf)拿到当前用户名,生成tmp文件夹


- →getLocalHost(),getHostAddress(),…拿系统的一些信息
- →getNewJobID(),setJobID()生成一个JobID并设置
- →处理缓存的一些信息略过…
- →copyAndConfiureFiles(job,submitJobDir)集群模式需要提交jar包,本地模式不需要提交jar包
- →getJobConfPath()获取配置路径
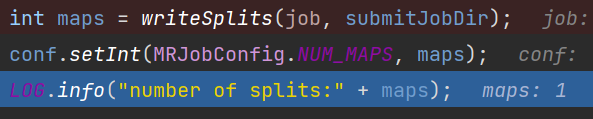
- ⭐→writeSplits()-#1.3详解,此处走完tem路径生成切片信息
- →conf.setInt(MRJobConfig.NUM_MAPS,maps)根据切片个数设置MapTask的个数,(此处文件挺小,就只生成了一个切片)
- →…
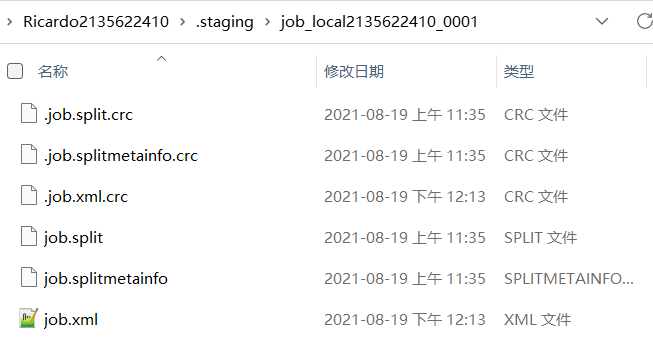
- →writeConf(conf,submitJobFile)→conf.writeXml(out)此两步执行完毕会生成job.xml,如果是集群运行还会生成.jar
- ⭐三个重要文件:job.split,job.xml,job.jar
- →…
- →state = JobState.RUNNING;状态从DEFINE置为RUNNING

- monitorAndPrintJob()进入监控运行阶段,清空tem下的文件信息
- …
- submit()
1.3 切片源码详解
//JobSubmitter
int maps = writeSplits(job, submitJobDir);
-
writeSplits()
-
writeNewSplits()用新API进行切分
-
input.getSplits()
-
minSize:从1和配置文件中选择一个最大值,配置文件(mapred-site.xml)默认是0
-
maxSize:从
Long.MAX_VALUE和配置文件中选最大值,默认配置(mapred-site.xml)文件中没有定义,所以取Long.MAX_VALUE -
isSplitable(job,path)判断文件是否能切割,比如1T压缩文件不支持切片,那么就切一个1T的切片
-
getBlockSize()获取块大小,本地块大小默认32M,集群模式下128M
-
computeSplitSize(blockSize,minSize,maxSize)
-

-
protected long computeSplitSize(long blockSize, long minSize,long maxSize) { return Math.max(minSize,Math.min(maxSize,blockSize)); } -
这里就是切片大小等于块大小
-
⭐判断切分后块是否大于块的1.1倍,如果是32.1M,32.1/32 < 1.1 ,所以切分成一块
-
private static final double SPLIT_SLOP = 1.1; // 10% slop
-
-
-
JobSplitWriter.createSplitFiles(jobSubmitDir,conf,jobSubmitDir.getFileSystem(conf), array)上面的getSplits()逻辑划分,这里的create才是生成真正的切片文件,声称在tem文件夹中
-
-
结论:
- 默认情况下,切片大小=块大小
- 可以通过调整minSize和maxSize调整切片的默认值(修改mapred-site.xml)
- 划分SPLIT_SLOP=1.1,每次切片判断切完剩下的部分是否大于块的1.1倍,不大于就化成一块
- InputSplit只记录切片的元数据信息,比如起始位置,长度以及所在的节点列表
- 提交切片规划文件到YARN上,YARN上的MrAppMaster根据切片规划文件计算开启MapTask的个数
1.4 FileInputFormat
继承树:
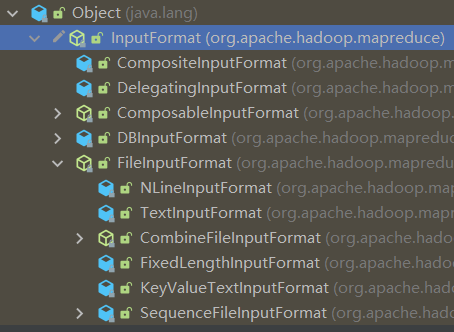
因为文件类型各种各样,所以每种文件的读取方式也各有不同,根据不同的文件类型,产生出不同类型的读取方式
都继承自InputFormat类
FileInputFormat下也有不同的读取方式,默认读取方式是TextInputFormat,也就是一行一行的读。
常见的接口实现类包括:TextInputFormat,KeyValueTextInputFormat,NLineInputFormat,CombineTextInputFormat和自定义InputFormat等。
- 切片机制
- 按照内容长度进行切片
- 切片大小默认block大小
- 不考虑数据集整体,每个一个文件单独切片
- 切片大小计算公式
Math.max(minSize, Math.min(maxSize, blockSize));
# mapred-site.xml中默认配置是1
mapreduce.input.fileinputformat.split.minsize=1
# maxSize没有在mapred-site.xml中配置,源码中取Long类型的最大值
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue
- 切片大小设置
- maxsize:参数调的比blockSize小,会让切片变小,而且就是这个参数的值
- minsize:参数调的比blockSize大,就可以扩大切片
1.5 TextInputFormat
TextInputFormat是默认的FileInputFormat实现类,按照行读取每条记录。
键是存储该行在整个文件中的其实字节偏移量,LongWritable类型。
值是这行的内容,不包括换行符和回车符,Text类型
txt
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
切割后
(0,Rich learning form)
(20,Intelligent learning engine)
(49,Learning more convenient)
(74,From the real demand for more close to the enterprise)
缺点:
- 按文件进行切片,不管文件多小都是单独的切片,都会单独开一个MapTask,占资源,效率低
1.6 CombineTextInputFormat
-
场景
由于TextInputFormat的劣势,引入CombineTextInputFormat方式
可以处理小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,如此就可以只生成一个MapTask
-
虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。 -
切片机制
包括虚拟存储过程和切片两部分
1.6.1 实例说明:
设置setMaxInputSplitSize值为4M
1.6.1.1 虚拟存储阶段
存在4个小文件
a.txt:2M,小于4M,划分为一个块
b.txt:7M,大于4M,小于8M,均分2各块,都是3.5M
c.txt:0.3M,小于4M,划分为一个块
d.txt:8.2M,大于8M,先划分一个4M,剩下4.2M大于4M小于8M,均分成两个2.1M
总共七个虚拟存储块
2M,3.5M,3.5M,0.3M,4M,2.1M,2.1M
1.6.1.2 切片过程
- 循环遍历七个虚拟存储块
- 一块一块合并,判断大小和是否大于maxSize(4M),如果大于则生成一个切片,否则继续与虚拟存储文件进行合并,直到合并后的文件大于设置的最大值
对于本个案例最终形成3个切片:(2+3.5)M,(3.5+0.3+4)M,(2.1+2.1)M
注意:虚拟存储的切片最大值最好根据实际的小文件大小情况具体设置
- 剩余数据大小超过设置的最大值并且不大于最大值的2倍,会将文件等分成两个虚拟存储块,防止出现太小的切片
- 合并顺序按照字典顺序
1.6.2 分割虚拟存储源码部分
for (int i = 0; i < locations.length; i++) {
fileSize += locations[i].getLength();
// each split can be a maximum of maxSize
long left = locations[i].getLength();
long myOffset = locations[i].getOffset();
long myLength = 0;
do {
//如果没有设置maxSize,那就按照文件本身长度分割
if (maxSize == 0) {
myLength = left;
} else {
//如果虚拟块比maxSize大并且比2倍maxSize那么久等分两份
if (left > maxSize && left < 2 * maxSize) {
// if remainder is between max and 1*max - then
// instead of creating splits of size max, left-max we
// create splits of size left/2 and left/2. This is
// a heuristic to avoid creating really really small
// splits.
myLength = left / 2;
} else {
//不大于maxSize的单独分一片
myLength = Math.min(maxSize, left);
}
}
//封装成块
CombineFileInputFormat.OneBlockInfo oneblock = new CombineFileInputFormat.OneBlockInfo(stat.getPath(),
myOffset, myLength, locations[i].getHosts(),
locations[i].getTopologyPaths());
//减掉分好的块
left -= myLength;
//调整偏移量
myOffset += myLength;
//添加到块列表里
blocksList.add(oneblock);
} while (left > 0);
}
1.6.3 合并虚拟存储块,生成切片部分源码
while (oneBlockIter.hasNext()) {
CombineFileInputFormat.OneBlockInfo oneblock = oneBlockIter.next();
// Remove all blocks which may already have been assigned to other
// splits.
if(!blockToNodes.containsKey(oneblock)) {
oneBlockIter.remove();
continue;
}
//把分好的虚拟存储块合并,计算长度
validBlocks.add(oneblock);
blockToNodes.remove(oneblock);
curSplitSize += oneblock.length;
// if the accumulated split size exceeds the maximum, then
// create this split.
//如果设置了maxSize并且当前合并的文件比maxSize大,那就生成一个切片
//不够就继续加一块
//所以最终块的大小(maxSize, 2 × maxSize)
if (maxSize != 0 && curSplitSize >= maxSize) {
// create an input split and add it to the splits array
addCreatedSplit(splits, Collections.singleton(node), validBlocks);
totalLength -= curSplitSize;
curSplitSize = 0;
splitsPerNode.add(node);
// Remove entries from blocksInNode so that we don't walk these
// again.
blocksInCurrentNode.removeAll(validBlocks);
validBlocks.clear();
// Done creating a single split for this node. Move on to the next
// node so that splits are distributed across nodes.
break;
}
}
if (validBlocks.size() != 0) {
// This implies that the last few blocks (or all in case maxSize=0)
// were not part of a split. The node is complete.
// if there were any blocks left over and their combined size is
// larger than minSplitNode, then combine them into one split.
// Otherwise add them back to the unprocessed pool. It is likely
// that they will be combined with other blocks from the
// same rack later on.
// This condition also kicks in when max split size is not set. All
// blocks on a node will be grouped together into a single split.
if (minSizeNode != 0 && curSplitSize >= minSizeNode
&& splitsPerNode.count(node) == 0) {
// haven't created any split on this machine. so its ok to add a
// smaller one for parallelism. Otherwise group it in the rack for
// balanced size create an input split and add it to the splits
// array
addCreatedSplit(splits, Collections.singleton(node), validBlocks);
totalLength -= curSplitSize;
splitsPerNode.add(node);
// Remove entries from blocksInNode so that we don't walk this again.
blocksInCurrentNode.removeAll(validBlocks);
// The node is done. This was the last set of blocks for this node.
} else {
// Put the unplaced blocks back into the pool for later rack-allocation.
for (CombineFileInputFormat.OneBlockInfo oneblock : validBlocks) {
blockToNodes.put(oneblock, oneblock.hosts);
}
}
validBlocks.clear();
curSplitSize = 0;
completedNodes.add(node);
} else { // No in-flight blocks.
if (blocksInCurrentNode.size() == 0) {
// Node is done. All blocks were fit into node-local splits.
completedNodes.add(node);
} // else Run through the node again.
}
1.6.4 CombineTextInputFormat案例
四个文件
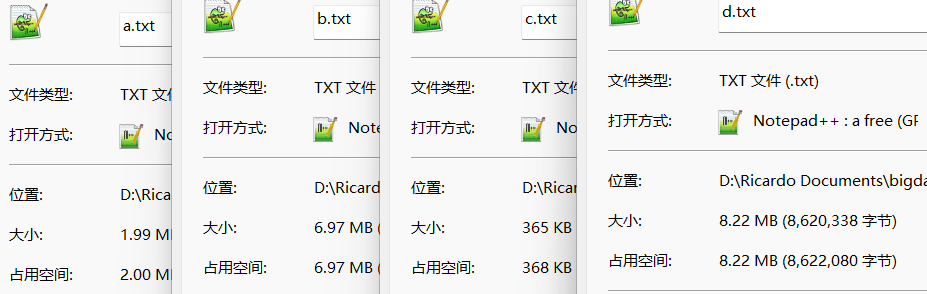
-
不做任何处理运行(TextInputFormat运行)
number of splits:4 -
设置用CombineTextInputFormat运行
//设置CombineTextInputFormat job.setInputFormatClass(CombineTextInputFormat.class); //设置虚拟存储切片最大值为4M CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);运行结果
number of splits:3
2. MapReduce工作流程
(一)
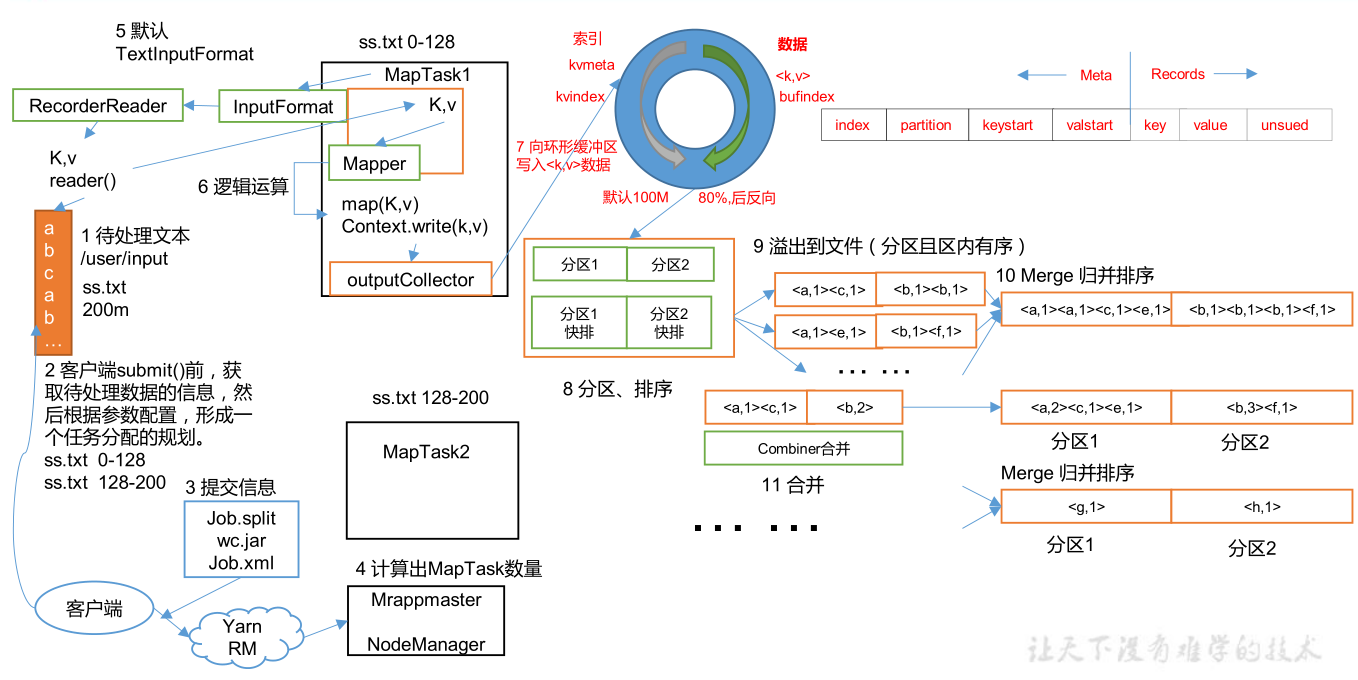
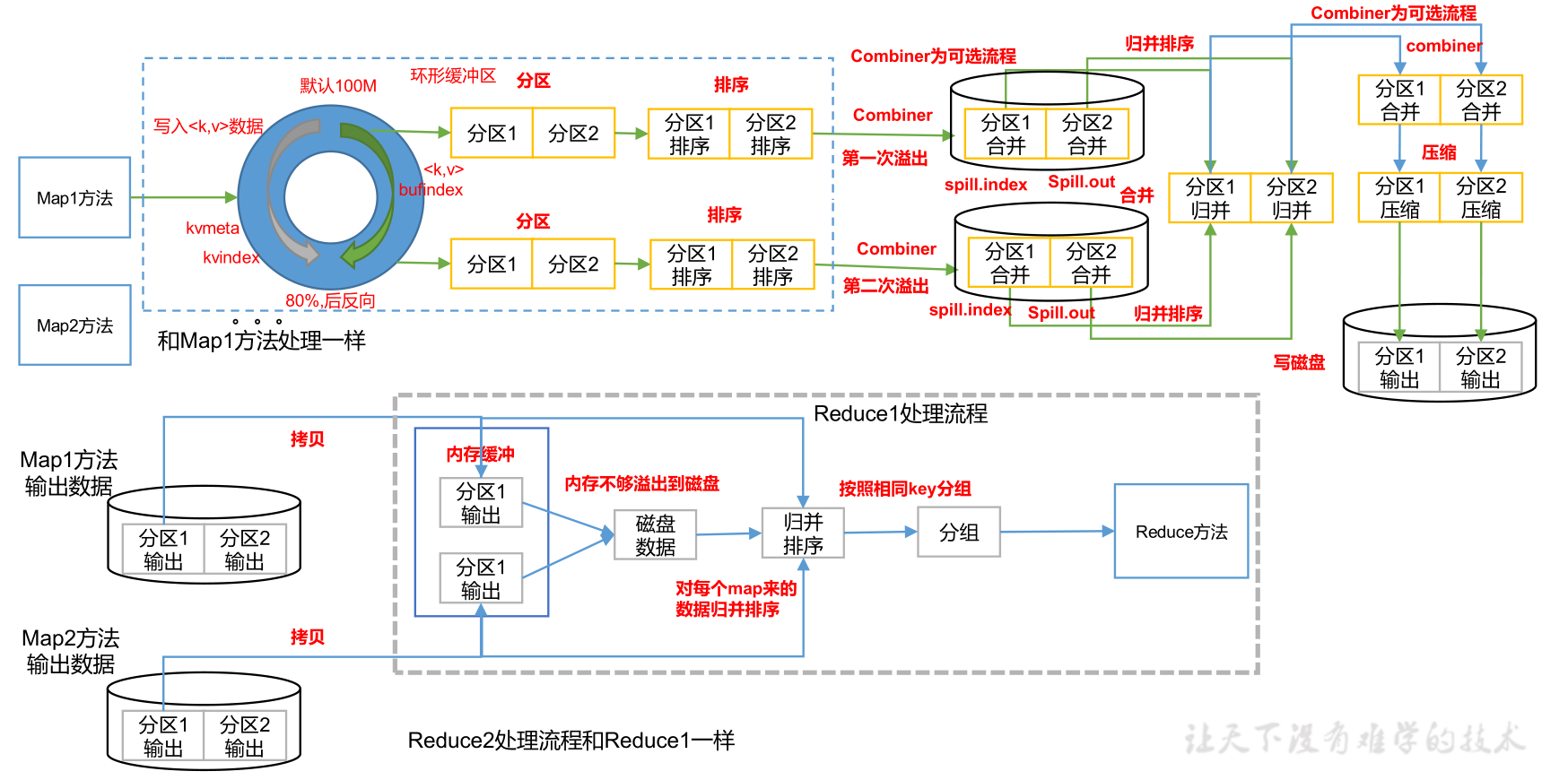
这里详细说明Shuffle过程
- InputFormat中的RecorderReader对文件进行读取,然后进入编写的Mapper方法中,执行完毕后outputCollector将数据写入缓冲区
- 缓冲区大小默认100M,一半是元数据(索引,分区,键值的起止位置),另一半存放数据
- 从缓冲区两头进行写入,写入到80%,进行反向写入,同时将80%的数据写入磁盘生成一个溢写文件,如果反向写入的20%也写满了,就等待80%的数据溢写完成
- 溢写过程会调用Partititor进行分区,分区决定了进入哪个reduce,分区个数可以设置
- 溢写前会对索引进行快速排序,相当于对数据进行快排,对索引效率更高,只改变键值的始止位置
- 生成的溢写文件可能包括多个分区
- 最终对溢写文件中的分区内数据key进行归并排序,每个分区内数据有序
- 归并后分区1(<a,1><a,1><c,1><e,1>),分区2(<b,1><b,1><b,1><><f,1>)
- 条件允许会进行Combiner合并,优化传递效率
- 合并后分区1(<a,2><c,1><c,1>),分区2(<b,3><f,1>)
(二)
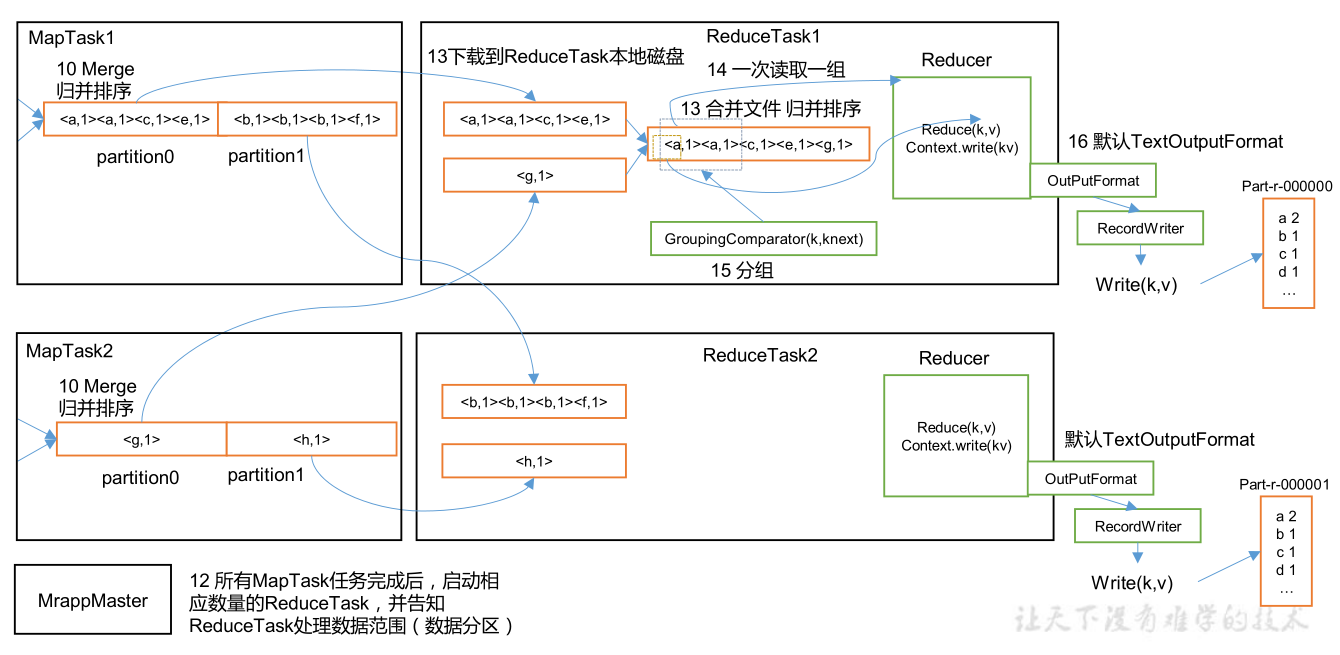
- 等待每个MapTask结束,MrAppMaster启动相应数量ReduceTask同时告知ReduceTask处理数据的范围(即哪个分区),但是否等待全部MapTask结束再开始ReduceTask也不绝对,可以进行设置,例如有100个MapTask,10个已经完成了,就可以先对这10个进行ReduceTask,都结束后在进行归并
- ReduceTask开启后主动到对应的分区拉取(拷贝)数据,例如MrAppMaster要求ReduceTask1只能处理分区1的数据,然后ReduceTask1主动去找分区1的数据(分区1的数据可能存在于多个溢写文件中),将所有分区1的数据拉取完后进行归并排序,最终生成一个大文件
- 对于已经有序的数据,归并的效率最高
- Shuffle过程结束,进入用户写好的reduce()方法
要点:
- Shuffle中缓冲区大小影响MapReduce程序的执行效率,原则上,缓冲区越大,溢写IO次数越少,那执行速度就越快
- 缓冲区大小可以通过
mapreduce.task.io.sort.mb调整,默认100M
3. Shuffle机制
3.1 整体流程
3.2 Partition分区
3.2.1 概述
MapTask→Partition→ReduceTask
Partiton分区数决定了开启的ReduceTask个数,也决定了最终生成文件的个数
Partition可以将最终输出的结果进行归类划分,划分到各个不同的文件之中
3.2.2 默认分区策略
如果不指定自定义分区条件,则采用如下的分区条件
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
3.2.4 自定义Partition
-
自定义Partiton继承Partitioner,重写getPartition()方法
这里指定需要指定泛型,KV是map的KV类型
public class CustomPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 控制分区代码逻辑
… …
return partition;
}
}
- 设置自定义Partitioner
job.setPartitionerClass(CustomPartitioner.class);
- 自定义分区之后,根据自己的分区个数设置相应的ReduceTask
job.setNumReduceTask(5);
3.2.5 源码说明

这里的collect就是环形缓冲器,下面的getPartition会根据设置的分区数进入对应的分区策略,如果不设置或者设置的是1,进入默认的分区机制,如果设置且大于1,则进入自定义的分区策略
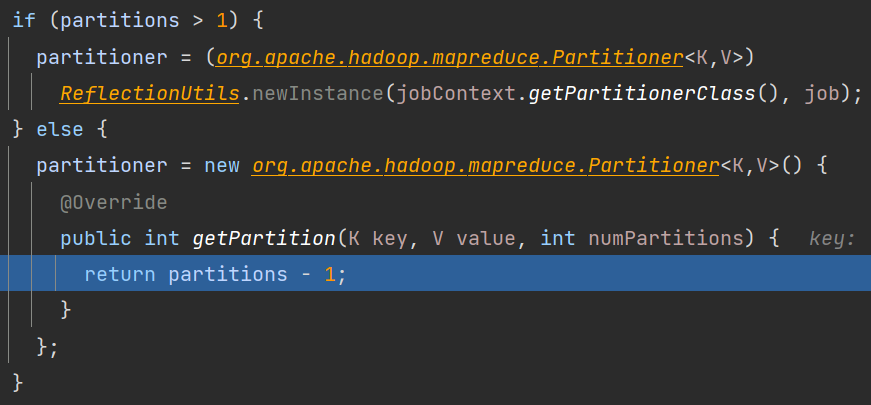
默认partitions是1,所以partitions-1就是0,就是默认一个分区的分区号0
3.2.5 Partition分区案例
目的:将手机号按照136,137,138,139开头放置到4个独立的文件之中,其他的放在一个文件中
步骤:
- FlowPartition:自定义的分区策略
package edu.tyut.mapreduce.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author Ricardo Jia
* @description
* @since 2021-08-20
*/
public class FlowPartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//获取手机号前三位
String pre3bitPhone = text.toString().substring(0, 3);
//定义一个分区号
int partition;
switch (pre3bitPhone) {
case "136": partition = 0; break;
case "137": partition = 1; break;
case "138": partition = 2; break;
case "139": partition = 3; break;
default: partition = 4;
}
//返回分区号
return partition;
}
}
- 设置自定义分区,设置分区个数
//设置job的分区为自定义的分区方式
job.setPartitionerClass(FlowPartitioner.class);
//设置分区个数
job.setNumReduceTasks(5);
如此一来,getPartition就会进入自定义的分区策略中
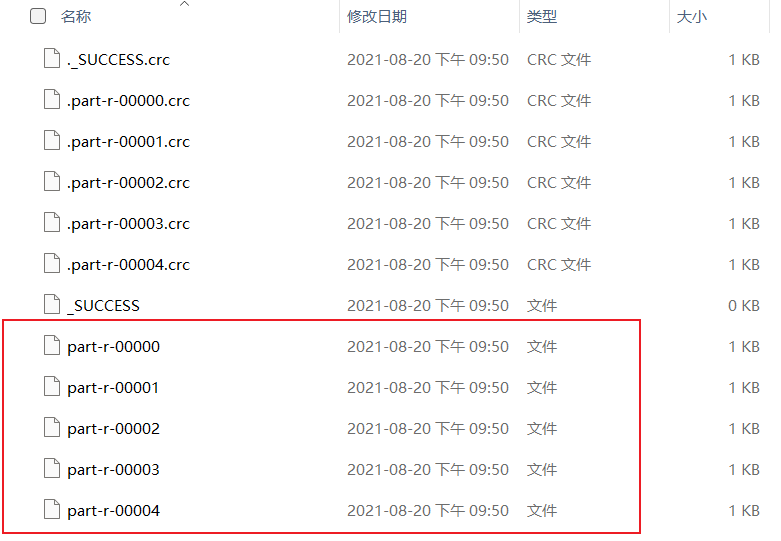
执行结果:
文件内容:
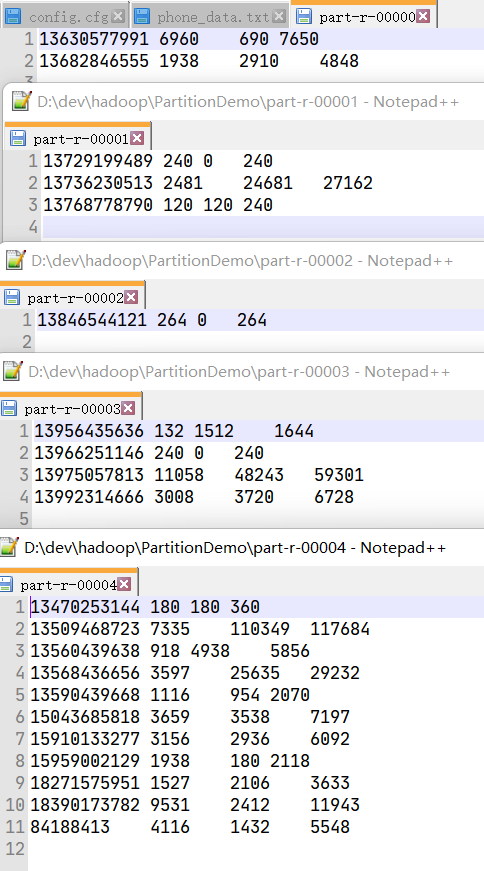
达到了预期效果
3.2.6 总结
- 如果ReduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
- 如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
- 如果ReduceTask的数量=1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个
ReduceTask,最终也就只会产生一个结果文件 part-r-00000; - 分区号必须从零开始,逐一累加。
- 案例分析
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1);会正常运行,只不过会产生一个输出文件
(2)job.setNumReduceTasks(2);会报错
(3)job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件
3.4 排序
3.4.1 排序概述
MapTask和ReduceTask均会对数据按照key进行排序,这是Hadoop的默认行为。
任何引用程序中的数据均会被排序,不论逻辑上是否需要
默认排序按照字典顺序,实现方法是快速排序
MapTask→结果放入环形缓冲区→达到阈值,进行一次快速排序→溢写到磁盘→所有数据处理完毕进行归并排序
ReduceTask拉取拷贝数据
if 内存有位置
放在内存
if 达到阈值
进行一次归并排序溢写到磁盘上
else
放在磁盘
if 达到阈值
进行一次归并排序生成一个更大文件
if 数据拷贝完毕
ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序
3.4.2 排序分类
- 部分排序
- MR根据输入的键对数据集进行排序,保证每个文件内部有序
- 全排序
- 只设置了一个ReduceTask,最终只生成一个文件,内部有序。效率很低
- 辅助排序GroupingComparator分组(了解)
- 对key进行分组,当接受的key是bean对象,想让一个字段相同或者几个字段相同的key进入同一个reduce(),可以采用。
- 二次排序
- compareTo两个判断条件就是二次排序,比如先按身高排,身高相同按照年龄排
3.4.3 自定义排序WritableComparable原理分析
bean对象作为key进行传输,bean实现WritableComparable接口重写compareTo()方法
3.4.4 WritableComparable全排序案例
将已经处理完成的Flow案例中的结果作为输入
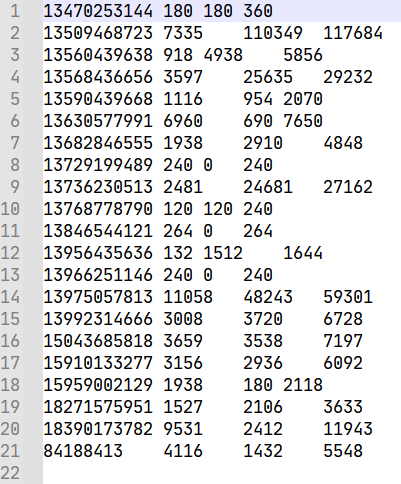
预期输出结果按照总流量降序排列
Bean:实现WritableComparable接口,泛型是需要排序的bean
public class FlowBean implements WritableComparable<FlowBean> {
@Override
public int compareTo(FlowBean o) {
//按照总流量进行逆序排序
return (int) (o.getSumFlow() - this.getSumFlow());
}
//其余一样
}
Mapper:
分析:因为要将总流量进行排序,所以需要将FlowBean作为key输入,手机号作为value输出
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private final FlowBean outK = new FlowBean();
private final Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据,转成字符串
String line = value.toString();
//切割数据
String regex = "\t";
String[] split = line.split(regex);
//封装outK和outV
outK.setUpFlow(Long.parseLong(split[1]));
outK.setDownFlow(Long.parseLong(split[2]));
outK.setSumFlow();
outV.set(split[0]);
context.write(outK,outV);
}
}
Reducer:
public class FlowReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Reducer<FlowBean, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {
//遍历values集合,循环写出,避免总流量相同的情况
for (Text value : values) {
//调换KV位置,反向写出,就是把手机号放在前头
context.write(value, key);
}
}
}
Driver:
调整一下map的输出KV类型
public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//关联Driver类
job.setJarByClass(FlowDriver.class);
//关联Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//设置Map端输出KV类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
//设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//设置程序最终输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\dev\\hadoop\\part-r-00000"));
FileOutputFormat.setOutputPath(job, new Path("D:\\dev\\hadoop\\WritableComparableOutput"));
//提交job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
运行结果
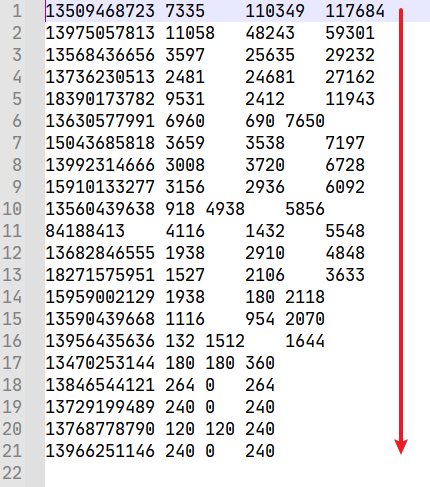
扩展:进行二次排序
目的:将总流量降序排列,输入流量升序排序
改写compareTo方法
public int compareTo(FlowBean o) {
//按照总流量进行逆序排序
//return (int) (o.getSumFlow() - this.getSumFlow());
if (this.sumFlow > o.sumFlow) {
return -1;
} else if (this.sumFlow < o.sumFlow){
return 1;
} else {
// 按上行流量的正序排序
if (this.upFlow > o.upFlow) {
return 1;
} else if (this.upFlow < o.upFlow) {
return -1;
} else {
return 0;
}
}
}
运行结果:
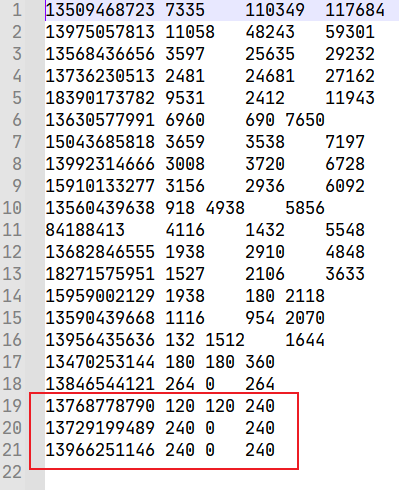
3.4.5 WritableComparable区内排序案例
只是加一个自定义分区策略,没有难度,注意一下KV的顺序
3.7 Combiner
3.7.1 概述
Combiner是MR程序中Mapper和Reducer之外的一种组件
Combiner的父类就是Reducer
Combiner和Reducer的区别在于运行位置不同
-
Combiner是在Shuffle中的一步,在最终生成分区文件前对结果先进行一个合并,如果没有Reduce阶段也就不会有Shuffle阶段,也就不会有Combiner
-
Combiner实在每一个MapTask所在的节点运行
-
Reducer是接收全局Mapper的输出结果
Combiner存在的意义是对每一个MapTask的输出进行局部汇总,以减少网络传输量
Combiner应用的前提是不能影响最终的业务逻辑
Combiner的输出KV要和Reducer输入KV对应
3.7.2 Combiner案例
自定义Combiner继承Reducer类,重写reduce方法
如下案例采用WordCound,Combiner和Reducer实现过程一样,直接使用Recuder的实现过程作为Combiner
//设置Combiner
job.setCombinerClass(WordCountReducer.class);
元数据:

对比图:
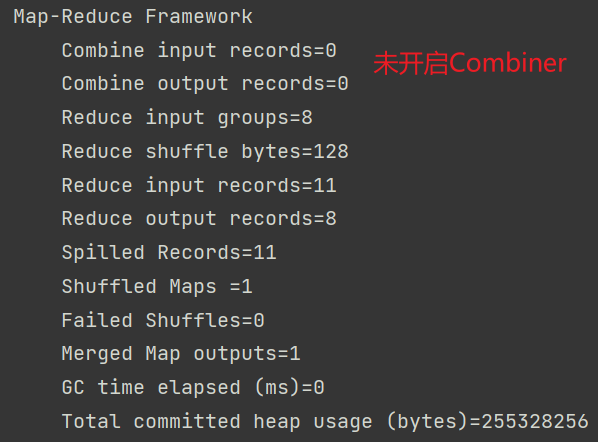
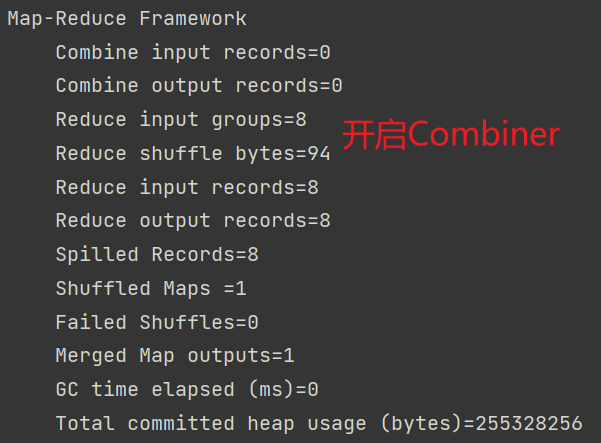
将Reduce输入从11减到了8
Combiner帮助Reduce完成了<a,1><a,1>→<a,2>的这个过程
4. OutPutFormat数据输出
4.1 概述
- 继承树
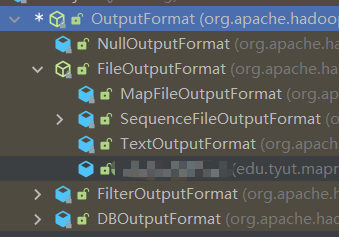
- 默认OutputFormat
- FileOutputForamt
- 默认TextOutputFormat
- FileOutputForamt
- 自定义OutputFormat
- 自定义输出到Mysql/HBase/ES等存储框架中
- 步骤:
- 继承FileOutputFormat
- 改写RecordWriter,重写write方法
4.2 案例
目的:将文件中含有http://www.ricardo.com的行输出到ricardo.log文件中,其他行输出到other.log
LogMapper
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//不做操作,直接写
context.write(value, NullWritable.get());
}
}
LogReducer
public class LogReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//防止都是相同key的值
for (NullWritable value : values) {
context.write(key, NullWritable.get());
}
}
}
LogOutputFormat
继承FileOutputFormat,写泛型
public class LogOutFormat extends FileOutputFormat<Text, NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
return new LogRecordWriter(job);
}
}
LogRecordWriter
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
...
public class LogRecordWriter extends RecordWriter<Text, NullWritable> {
private FSDataOutputStream ricardo;
private FSDataOutputStream other;
public LogRecordWriter(TaskAttemptContext job) {
try {
//获取文件系统对象
FileSystem fs = FileSystem.get(job.getConfiguration());
//创建两个输出流对应不同的目录
ricardo = fs.create(new Path("D:\\dev\\hadoop\\outputFormat\\ricardo.log"));
other = fs.create(new Path("D:/dev/hadoop/outputFormat/other.log"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
String log = key.toString();
if (log.contains("ricardo")) {
ricardo.writeBytes(log + "\n");
} else {
other.writeBytes(log + "\n");
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
IOUtils.closeStream(ricardo);
IOUtils.closeStream(other);
}
}
LogDriver
public class LogDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置输出outputFormat
job.setOutputFormatClass(LogOutFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\dev\\hadoop\\log.txt"));
//设置_SUCCESS文件输出位置
FileOutputFormat.setOutputPath(job, new Path("D:/dev/hadoop/LogOutPut"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
输出结果
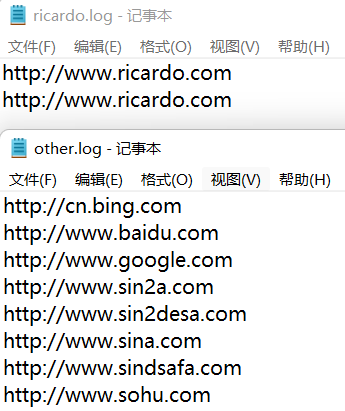
文件位置
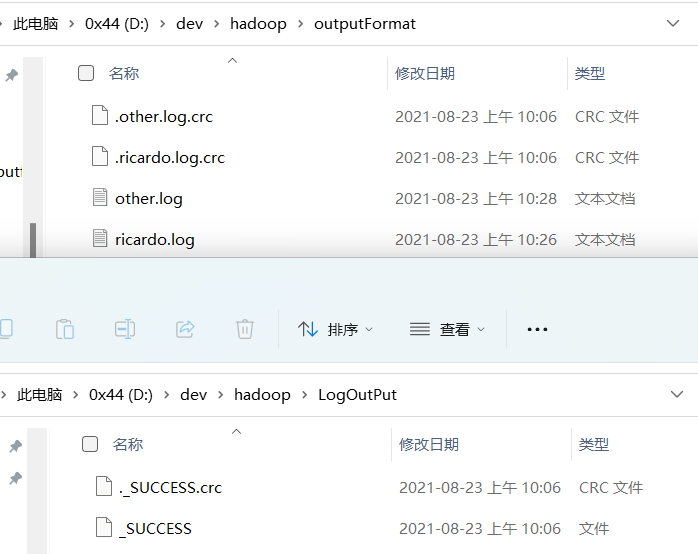
4.3 ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定
-
设置并行度个数
ReduceTask数量可以直接手动设置
//默认是1,手动设置为4 job.setNumReduceTasks(4); -
如何设置
是需要测试的,根据机器性能,逐步添加ReduceTask个数,统计总时间,会得到一个正态分布,选择性能最佳的就好
-
要点
- ReduceTask=0,说明没有Reduce阶段
- 默认=1,只生成一个输出文件
- 注意数据分布不均匀,会产生数据倾斜
- 若要对所有数据进行排序之类的操作,只能设置成1
- 设置分区数=1,但是ReduceTask=1,不执行分区操作
5. MR内核源码解析
5.1 MapTask源码流程解析
context.write(k, NullWritable.get()); //自定义的 map 方法的写出,进入
output.write(key, value);
//MapTask727 行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082 行 map 端所有的 kv 全部写出后会走下面的 close 方法
close() //MapTask732 行
collector.flush() // 溢出刷写方法,MapTask735 行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505 行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625 行,进入
mergeParts(); //合并文件,MapTask1527 行,进入
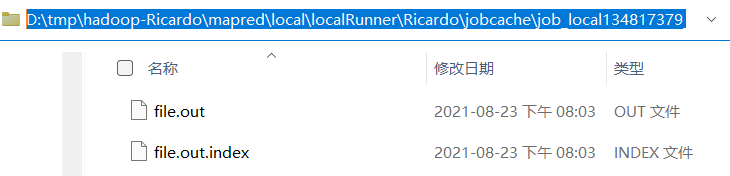
file.out就是最终的溢写文件,file.out.index就是ReduceTask进行拉取数据时参考的索引文件
collector.close(); //MapTask739 行,收集器关闭,即将进入 ReduceTask
5.2 ReduceTask 源码流程解析
if (isMapOrReduce()) //reduceTask324 行,提前打断点
initialize() // reduceTask333 行,进入
init(shuffleContext); // reduceTask375 行,走到这需要先给下面的打断点
totalMaps = job.getNumMapTasks(); // ShuffleSchedulerImpl 第 120 行,提前打断点
merger = createMergeManager(context); //合并方法,Shuffle 第 80 行
// MergeManagerImpl 第 232 235 行,提前打断点
this.inMemoryMerger = createInMemoryMerger(); //内存合并
this.onDiskMerger = new OnDiskMerger(this); //磁盘合并
rIter = shuffleConsumerPlugin.run();
eventFetcher.start(); //开始抓取数据,Shuffle 第 107 行,提前打断点
eventFetcher.shutDown(); //抓取结束,Shuffle 第 141 行,提前打断点
copyPhase.complete(); //copy 阶段完成,Shuffle 第 151 行
taskStatus.setPhase(TaskStatus.Phase.SORT); //开始排序阶段,Shuffle 第 152 行
sortPhase.complete(); //排序阶段完成,即将进入 reduce 阶段 reduceTask382 行
reduce(); //reduce 阶段调用的就是我们自定义的 reduce 方法,会被调用多次
cleanup(context); //reduce 完成之前,会最后调用一次 Reducer 里面的 cleanup 方法
6. Join应用
6.1 ReduceJoin
案例分析:
目的:将order表和pd表根据商品pid合并到订单数据表中
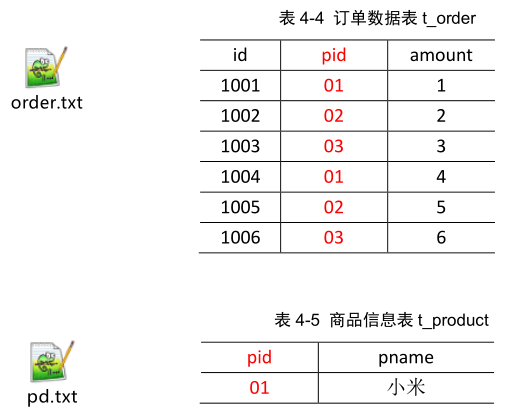
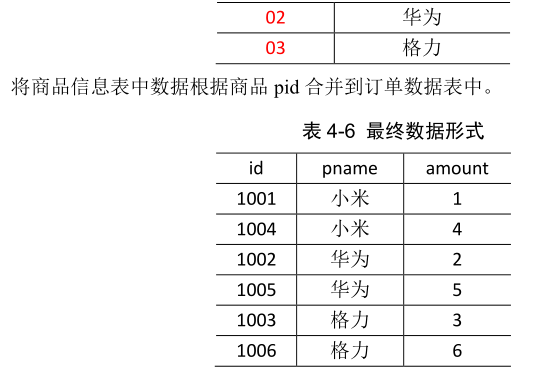
思路分析:
map阶段,拿到两个表中的所有数据,将pid相同的封装进一个Bean对象,将共有的pid作为key,封装的TableBean作为值,key相同的进入同一个ReduceTask
reduce阶段,拿到了pid相同的数据,将pd表中pname和order的数据进行封装,生成最终数据
TableBean
public class TableBean implements Writable {
private String id;//订单id
private String pid;//产品id
private int amount;//数量
private String pname;//产品名称
private String flag;//标记位
public TableBean() {
}
public TableBean(String id, String pid, int amount, String pname, String flag) {
this.id = id;
this.pid = pid;
this.amount = amount;
this.pname = pname;
this.flag = flag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(id);
out.writeUTF(pid);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readUTF();
this.pid = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
@Override
public String toString() {
return id + "\t" + pname + "\t" + amount;
}
}
TableMapper
public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean> {
private String fileName;
private final Text outK = new Text();
private final TableBean outV = new TableBean();
@Override
protected void setup(Mapper<LongWritable, Text, Text, TableBean>.Context context) throws IOException, InterruptedException {
//获取对应文件的名称
InputSplit split = context.getInputSplit();
FileSplit fileSplit = (FileSplit) split;
fileName = fileSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, TableBean>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String regex = "\t";
String[] split = line.split(regex);
if (fileName.contains("order")) {
outK.set(split[1]);
outV.setId(split[0]);
outV.setPid(split[1]);
outV.setAmount(Integer.parseInt(split[2]));
outV.setPname("");
outV.setFlag("order");
} else {
outK.set(split[0]);
outV.setId("");
outV.setPid(split[0]);
outV.setAmount(0);
outV.setPname(split[1]);
outV.setFlag("pd");
}
context.write(outK, outV);
}
}
TableReducer
注意:Hadoop底层对迭代器进行了修改,每次拿到的value地址是相同的,所以会导致添加进orderBeans中的bean只有一个,所以每次迭代需要新创建一个bean对象进行存放
public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<TableBean> values, Reducer<Text, TableBean, TableBean, NullWritable>.Context context) throws IOException, InterruptedException {
//将订单表存放在数组
//商品信息就一条,所以将商品表封装在一个对象中即可
ArrayList<TableBean> orderBeans = new ArrayList<>();
TableBean pdBean = new TableBean();
//判断数据来自哪个表
for (TableBean value : values) {
if ("order".equals(value.getFlag())) {
//由于hadoop中的迭代器规则,创建临时TableBean接受value
TableBean temBean = new TableBean();
try {
BeanUtils.copyProperties(temBean, value);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
//添加到集合
orderBeans.add(temBean);
} else {
try {
BeanUtils.copyProperties(pdBean, value);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
}
}
//遍历列表集合,设置pname
for (TableBean orderBean : orderBeans) {
orderBean.setPname(pdBean.getPname());
//写出
context.write(orderBean, NullWritable.get());
}
}
}
TableDriver
public class TableDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TableBean.class);
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:\\dev\\hadoop\\ReduceJoinInput"));
FileOutputFormat.setOutputPath(job, new Path("D:/dev/hadoop/ReduceJoinOutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
运行结果
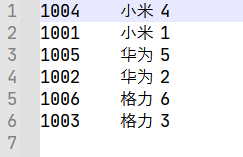
6.2 MapJoin
问题提出:上方的ReduceJoin将join放在reduce阶段,会导致大量的文件集中的reduce,产生数据倾斜
MapJoin适用场景:一张表很小,另一张表很大,可以将小表暂时存放在内存,对大表进行Map时取出内存数据
具体方法:采用DistributedCache
在setup阶段,将文件读取到缓存集合
在Driver驱动类中加载缓存
//缓存普通文件到Task运行节点
job.addCacheFile(new URI("file:///e:/cache/pd.txt"))
//集群运行,设置HDFS路径
job.addCacheFile(new URI("hdfs://rhnode2:8020/cache/pd.txt"))
源码实现
Driver
public class TableMapDriver {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(TableMapDriver.class);
job.setMapperClass(TableMapMapper.class);
job.setMapOutputKeyClass(TableMapMapper.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(TableMapMapper.class);
job.setOutputValueClass(NullWritable.class);
//设置缓存
job.addCacheFile(new URI("file:///D:/dev/hadoop/MapJoinInput/pd.txt"));
//设置不用reduce阶段
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job, new Path("D:\\dev\\hadoop\\MapJoinInput\\order.txt"));
FileOutputFormat.setOutputPath(job, new Path("D:\\dev\\hadoop\\MapJoinOutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
Mapper
package edu.tyut.mapreduce.mapJoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
/**
* @author Ricardo Jia
* @description
* @since 2021-08-24
*/
public class TableMapMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private final Map<String, String> pdMap = new HashMap<>();
private final Text text = new Text();
/**
* 任务开始前将pd.txt存入缓存
*
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//通过缓存文件得到小表数据pd.txt
URI[] cacheFiles = context.getCacheFiles();
Path path = new Path(cacheFiles[0]);
//获取文件系统对象,并开流
FSDataInputStream fis = FileSystem.get(context.getConfiguration()).open(path);
//通过包装流转换为reader,方便按行读取
BufferedReader reader = new BufferedReader(new InputStreamReader(fis, StandardCharsets.UTF_8));
//逐行读取,按行处理
String line;
while (StringUtils.isNotEmpty(line = reader.readLine())) {
//切割一行
String regex = "\t";
String[] split = line.split(regex);
pdMap.put(split[0], split[1]);
}
//关流
IOUtils.closeStream(reader);
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String regex = "\t";
String[] fields = value.toString().split(regex);
//通过大表order.txt表获取pid,取出pdMap中的数据
String pname = pdMap.get(fields[1]);
//重新组装数据
text.set(fields[0] + regex + pname + regex + fields[2]);
//写出
context.write(text, NullWritable.get());
}
}















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









