







文章目录
一、实验目的
1、掌握SLR(1)分析法进行语法分析的原理
2、掌握语法分析器的设计与调试
二、实验原理与要求
1、原理
LR分析法是一种自底向上的语法分析。SLR(1)分析表内包含几种操作:①移进;②归约;③接受。通过构造项目集规范族的状态转换表(即LR分析表)实现不同状态的跳转或归约,最后归约为文法的开始符号,从而接受。
2、要求
(1)定义语言子集的文法。
(2)构造识别文法活前缀的项目集规范族。
(3)构造SLR(1)分析表。
(4)根据SLR(1)分析表对输入串进行LR分析。
(5)测试要满足对文法的每个候选项的覆盖。
三、实验设备
配置有C/C++开发环境的计算机设备。
四、实验内容
采用SLR(1)分析法对表达式文法进行语法分析。表达式文法如下所示:
- G[E]:E→E+T | T T→(E) | i
五、实验步骤
1. 将文法G[E]拓广为G’[E’]
E’ →E
E →E+T
E →T
T →(E)
T →i
- 文法G’可存放在一个文件G1.txt中

2. 构造文法G’的LR(0)项目集规范族

3. 计算所有非终结符的FOLLOW集
char Follow[2][10]={
{
'E','+',')','#','\0'},{
'T','+',')','#','\0'}}; // 存放文法G1的所有非终结符的FOLLOW集
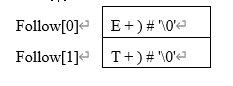
4. 构造SLR(1)分析表

5. 对输入串(i+i)#进行SLR(1)分析

6. 词法分析(在实验一基础上,增加一个单词’#’)


7. 编码
// -*- coding: utf-8 -*-
// @ Date : 2020/5/20 13:14
// @ Author : RichardLau_Cx
// @ file : Richard.cpp
// @ IDE : Dex-C++
// @ Source : 编译原理实验
#include"cstdio"
#include"cstring"
#include"process.h"
#include "实验一 词法分析程序.cpp" //“实验1词法分析”中除main函数外的其它代码段,并增加一个单词'#'
using namespace std;
typedef struct //表示一个项目
{
char str[81];
int R; //项目对应的产生式的编号
}Aitem;
typedef struct //表示项目集
{
Aitem item[100]; // item[ ]存放一个项目集中若干个项目
int number; //该项目集中项目的个数
}Item;
typedef struct //表示项目集规范族
{
Item I[100]; //I[0],I[1],I[2]…表示各个项目集I0,I1,I2,…
int number; //项目集的个数
}C;
typedef struct
{
char leftName; // 左部名称
int leftCode; // 左部代码
int rightLen; // 右部长度,决定出栈元素个数
}Production; // 产生式的表示
typedef struct
{
//说明:终结符和非终结符存放在char ch[100]中,若ch[j]='A',则符号A的编码是其下标j,符号的名称是'A'。
char name; // 存放文法符号的名称(便于外部输出)
int code; // 存放文法符号的编号(便于内部处理)
int state; // 存放状态
int value; // 该非终结符的值(只在语义分析阶段使用)
}Token; // 栈中元素类型的定义
typedef struct
{
Token body[100]; // 堆栈体
int top; // 栈顶指针
}TokenStack; // 分析栈的类型定义
int ip = 0; // 终结符(即单词)的下标
int lookAhead;
int Save[100][100]; //分析表
Item wenfa; //文法,将整个文法存放到一个项目集中
Production Prod[5]; // 存放表达式文法G1.txt中的5个表达式
C c; //项目集规范族
int MAXSIZE = 10; // 栈的大小
TokenStack S;
char ch[100]; //存放ACTION子表第一行中的终结符和'#'以及GOTO子表第一行中的非终结符;
//且ch[j]中下标j与Save[i][j]中的列下标j对应,也就是说,若ch[j]存放的是'a',则Save[i][j]的第j列为'a'列;
//且Save[i][j]中的行下标i对应分析表第一列中的状态。
char Follow[2][10]={
{
'E','+',')','#','\0'},{
'T','+',')','#','\0'}}; //存放文法G1的所有非终结符的FOLLOW集
//文法G1:E→E+T | T T→(E) | i
void Load_Wenfa();
void Build_Production();
void InitStack(TokenStack *s);
void push(TokenStack *s, char leftName, int leftCode, int curOp, int m);
void outputStacks(TokenStack *s);
void Analysis(TokenStack *s, int lookAhead);
int getState(TokenStack *s);
int getOperate(int curState, int code);
void Load_Wenfa()
{
//从文件G1.txt中获得表达式文法,存入全局变量wenfa中
FILE *fp;
int i, j;
char temp[81];
if((fp=fopen("G1.txt","r"))==NULL)
{
printf("cannot open G1.txt\n"); getchar( ); exit(0);
}
printf("文法文件G'已经成功打开!\n");
fgets(ch,81,fp); //从文件中获得ACTION子表第一行中的终结符和'#'以及GOTO子表第一行中的非终结符存入ch中,串尾的'\n'也存入了ch中。
for(i=0;(ch[i])!='\n';i++);
ch[i]='\0'; //删除串尾的'\n'
i=0;
while((fgets(temp, 81, fp)) != NULL)
{
strcpy(wenfa.item[i].str, temp);
for(j=0; (wenfa.item[i].str[j]) != '\n'; j++);
// wenfa.item[i].str[j] = '\0'; //删除串尾的'\n'
// printf("\n1 %c 1\n", wenfa.item[i].str[j]);
wenfa.item[i].R = 100+i; //存放产生式的编号,编号统一加100,如第1个产生式的编号为101
//
i++;
// printf("here!");
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1146
1146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









