









文章目录
1. 前言
在第(三)篇中,我们最后配置好了Zookeeper集群,下面我们将启动集群,注意这里BUG比较多,我也是摸着石头过河,好歹问题都已经解决。
2. 第一大坑之防火墙
这里先科普一下CentOS6.9下防火墙的命令:
| 功能 | 命令 |
|---|---|
| 打开防火墙 | service iptables start |
| 关闭防火墙 | service iptables stop |
| 查看防火墙状态 | service iptables status |
由于CentOS是默认开启防火墙的,所以启动集群后可能会导致Zookeeper启动失败等一系列BUG,最直接的是在格式化NameNode的时候就会失败。
所以,在每台机器上请先关闭防火墙:(每次开启都要使用)
service iptables stop

3. 第二大坑之格式化Zookeeper
在按照正常顺序启动zookeeper时,我发现DFSZKFailoverController进程总是启动不起来,经过各种百度、谷歌、StackOverflow都没有找到结果,然后一点点查看日志信息发现:
org.apache.hadoop.ha.ZKFailoverController: Unable to start failover controller. Parent znode does not exist.
Run with -formatZK flag to initialize ZooKeeper.
然后,得知:FC(failOver)需要把NN的状态写给ZK,所以格式化命令就是为了创建一个父目录,后续FC会把NN的状态写到这下面给ZK看。(只需第一次搭建时,使用)
格式化命令:
hdfs zkfc -formatZK
4. 集群启动之吹起号角
4.1 启动Zookeeper
由于小编很懒没有配置Zookeeper环境变量,所以各位观众老爷需要进入到Zookeeper的bin目录下去启动zkServer.sh文件。话不多说,直接截图:
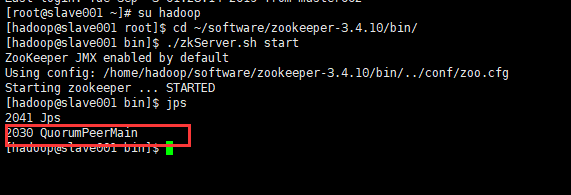
三台slave都要启动哦!!!
4.2 启动journalnode进程
在这里稍微普及一下journalnode进程的作用(在后面有机会讲高可用时会详细讲解)。由于我们实现的是高可用,有一个Active节点和一个Standby节点,而这两个节点正是通过使用JournalNode集群来进行数据同步的。

启动命令为:
hadoop-daemon.sh start journalnode

4.3 在master001中格式化NameNode
那么问题来了,为什么第一次启动集群时需要格式化NameNode节点呢?
因为NameNode主要被用来管理整个分布式文件系统的命名空间的元数据信息,同时为了保证数据的可靠性,还加入了操作日志,所以,NameNode会持久化这些数据(保存到本地的文件系统中)。
而格式化之后,会生成一个~/software/hadoop-2.6.5/tmp目录,目录结构下有/tmp/dfs/name/current目录,在current文件中,主要包含以下文件信息:
| 文件 | 作用 |
|---|---|
| fsimage | 存储命名空间(实际上就是目录和文件)的元数据信息 |
| edits | 用来存储对命名空间操作的日志信息,实现namenode节点的恢复 |
| fstime | 用来存储check point 的时间 |
| VERSION | 存放namenode的版本信息 |
格式化命令:
hdfs namenode -format
4.4 传送tmp文件到其他所有节点
cd ~/software/hadoop-2.6.5/
scp -r tmp master002:~/software/hadoop-2.6.5/
scp -r tmp slave001:~/software/hadoop-2.6.5/
scp -r tmp slave002:~/software/hadoop-2.6.5/
scp -r tmp slave003:~/software/hadoop-2.6.5/
4.5 启动hdfs
启动hdfs只需要在master001节点中启动即可,执行命令:
start-dfs.sh
执行该命令会分别在master001和master002中启动NN进程,在slave的三台机器上启动DN进程。

4.6 启动MapReduce
启动MapReduce只需要在master001中执行:
start-yarn.sh
会在master001中启动ResourceManager进程,在三台slave中启动Nodemanager进程:

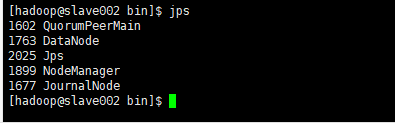
4.7 验证集群是否启动成功
激动的心,颤抖的手,宅皮艾斯一下有木有~~
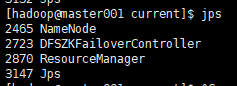
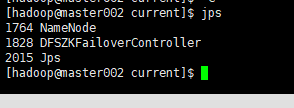
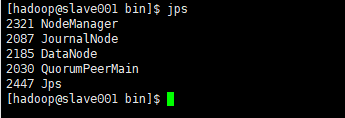

5. 正常启动顺序
刚刚第四步是我们第一次启动时的顺序,下面我给大家总结一下正常启动顺序:
5.1 启动Zookeeper
三台slave机器分别进入到Zookeeper的bin目录下,执行:
./zkServer.sh start
5.2 启动hdfs
在master001上执行:
start-dfs.sh
5.3 启动mapreduce
在master001上执行:
start-yarn.sh
6. 小结
截止到目前为止,我们已经搭建好了hadoop+zookeeper的真分布式高可用集群,可以在物理机通过:http://192.168.5.140:50070 进行访问:

在搭建Spark之前,我考虑到大部分初学者可能对HDFS、MapReduce操作不太熟悉,所以准备在接下来的一段时间里先陪大家练习一下HDFS的相关操作和熟悉MapReduce的工作原理以及编程模式。
希望有兴趣的初学者可以持续关注。。
溜了,溜了,恰饭去。。。














 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









