







博客内容源于《统计机器学习》一书的阅读笔记。Python的源码实现源于《机器学习实战》部分内容。
1. 感知机模型
感知机是二分类的线性分类模型,该模型的输入为实例的特征向量,输出为实例的类别,一般取+1和-1两个值。感知机将实例划分为两类,属于判别模型。
1.1 模型定义
【感知机定义】
假设输入空间(特征空间)是
X⊆Rn
,输出空间是
Y={−1,+1}
。
- 输入 x⊂X 表示实例的特征向量对应于输入空间(特征空间)的点。
- 输出 y⊂Y 表示实例的类别。
从输入空间到输出空间有如下的变换关系:
上述的变换关系就称为感知机。其中, w 和
1.2 模型的几何解释
线性方程:
对应于特征空间 Rn 中的一个超平面 S ,其中
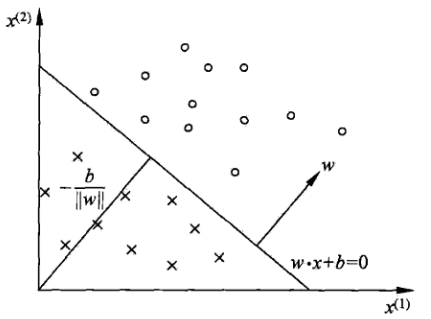
2. 感知机学习策略
假设训练数据集都是线性可分的,感知机学习的目标就是求得一个能够将训练数据集正实例点和负实例点完全正确分开的超平面。为了找到这个超平面,需要确定一个学习策略。定义一个损失函数,转化为求损失函数的极小值。
1. 很容易想到的是:将损失函数定义为误分点的个数,但是这里会有一个问题,因为这样的函数不是连续函数,所以对于参数
w,b
来说都是不可导的函数,这样不容易对问题进行优化。
2. 损失函数定义为误分类点到超平面
S
的总距离,这个损失函数是感知机所采用的。可知,
对于误分类的数据
(xi,yi)
来说,
所以可以所有将误分类点点超平面的总距离定义为:
上式中,若不考虑 1∥w∥ , 那么就得到了感知机学习的损失函数。
上式中 M 表示误分点的集合,这个损失函数就是感知机学习的经验风险函数。
3. 感知机学习算法
有了上面的损失函数,问题就转化成了一个优化问题,也就是求解损失函数的最小值。
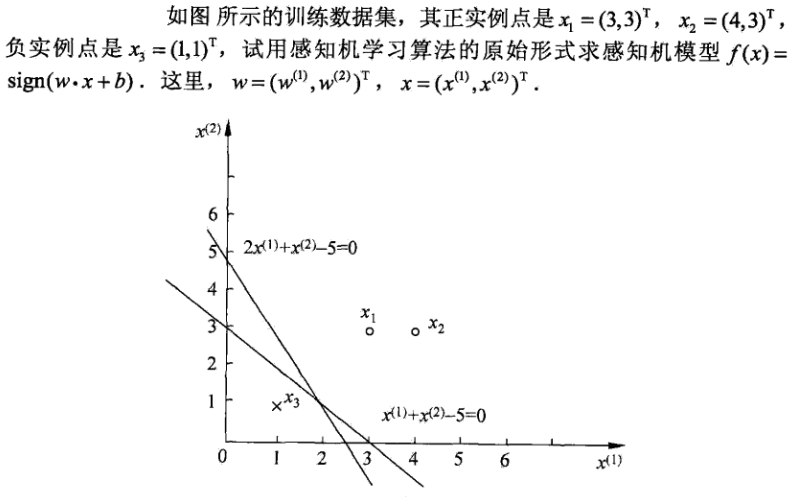
3.1 感知机学习算法原始形式
【问题】
给定一个训练数据集
其中, xi∈X=Rn,yi∈Y=−1,+1,i=1,2,⋅⋅⋅,N ,求参数 w,b ,使得损失函数的值为最小:
其中, M 表示误分点的集合。损失函数
采用梯度下降法就可以求解上述的问题,具体的求解步骤如下:
1. 任意选取一个超平面
w0,b0
2. 在训练数据集中选取数据
(xi,yi)
3. 如果
yi(w⋅xi+b)≤0
4.继续第2步,直到训练集中没有误分点(线性可分情况)。
3.2 Python实现感知机
import numpy as np
import matplotlib.pyplot as plt
class showPicture:
def __init__(self,data,tag,w,b):
self.b = b
self.w = w
plt.figure(1)
plt.title('Pic', size=14)
plt.xlabel('x', size=14)
plt.ylabel('y', size=14)
xData = np.linspace(0, 5, 100)
yData = self.expression(xData)
plt.plot(xData, yData, color='r', label='y1 data')
for i in range(len(data)):
if tag[i] == 1:
plt.scatter(data[i][0],data[i][1],s=50)
else:
plt.scatter(data[i][0],data[i][1],marker='x',s=50)
plt.savefig('pic.png',dpi=75)
def expression(self,x):
y = (-self.b - self.w[0]*x)/self.w[1]
return y
def show(self):
plt.show()
class perceptron:
def __init__(self,x,y,eta=1):
self.x = x
self.y = y
self.w = np.zeros((x.shape[1],1))
self.b = 0
self.eta = eta
def sign(self,w,b,x):
y = np.dot(x,w)+b
return int(y)
def train(self):
flag = True
length = len(self.x)
while flag:
count = 0
for i in range(length):
#print self.x[i,:]
tmpY = self.sign(self.w,self.b,self.x[i,:])
if tmpY*self.y[i]<=0:
tmp = self.y[i] * self.eta * self.x[i,:]
tmp = tmp.reshape(self.w.shape)
self.w = self.w + tmp
self.b = self.b + self.eta * self.y[i]
count += 1
#print "ttt\n"
if count == 0:
flag = False
return self.w,self.b
#
xArray = np.array([3,3,4,3,1,1])
xArray = xArray.reshape((3,2))
yArray = np.array([1,1,-1])
#
myPerceptron = perceptron(xArray,yArray,1)
w0,b0 = myPerceptron.train()
#
picture = showPicture(xArray,yArray,w=w0,b=b0)
picture.show()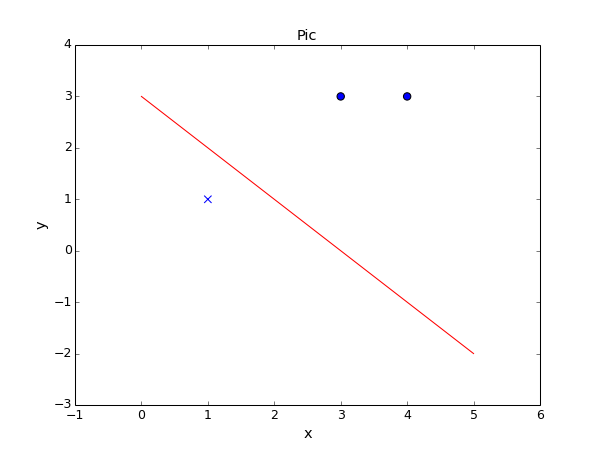
修改初始参数 w0,b0 会得到不同的结果,也就是说明感知机模型得到的结果依赖初始点。这样得到的模型泛化能力也就不同。后面可以看到利用最大间隔实现的分类器(SVM)总是可以得到最大的分割超平面,这点也是SVM分类器和感知机模型的典型的一个优点。
















 4264
4264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











