







 本文详细介绍了感知机模型,包括其数学定义、图形表示和线性可分的概念。损失函数通过误分类点到超平面的总距离来定义,并展示了原始形式和对偶形式的求解过程。最后,通过一个Python实现的感知机算法实例,展示了原始形式的训练过程。
本文详细介绍了感知机模型,包括其数学定义、图形表示和线性可分的概念。损失函数通过误分类点到超平面的总距离来定义,并展示了原始形式和对偶形式的求解过程。最后,通过一个Python实现的感知机算法实例,展示了原始形式的训练过程。
本文目录
感知机(Perception)
一、基本介绍
感知机是二元分类线性模型,输入为特征向量,输出为实例的类别,取值为+1和-1
对于线性可分的输入实例,感知机可以通过梯度下降法学习一个分离超平面,将实例分开
1. 数学定义
假设输入空间(特征空间)是
X
⊆
R
n
X \subseteq \mathbb{R}^{n}
X⊆Rn ,输出空间是
y
=
{
+
1
,
−
1
}
y=\{+1, -1\}
y={+1,−1}。输入
x
∈
X
x \in X
x∈X表示实例的特征向量,对应于输入空间(特征空间)的点;输出
y
∈
Y
y \in Y
y∈Y表示实例的类别。由输入空间到输出空间的如下函数:
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
f(x) = sign(w \cdot x + b)
f(x)=sign(w⋅x+b)
称为感知机,其中
w
w
w和
b
b
b为感知机模型参数,
w
∈
R
n
w \in \mathbb{R}^{n}
w∈Rn叫做权值(weight)或权值向量(weight vector),
b
∈
R
b \in \mathbb{R}
b∈R为偏置(bias),
w
⋅
x
w \cdot x
w⋅x为内积,
s
i
g
n
sign
sign为符号函数,
s
i
g
n
=
{
+
1
x
⩾
0
−
1
x
<
0
sign = \left\{\begin{matrix} +1 & x \geqslant 0 \\ -1 & x < 0 \end{matrix}\right.
sign={+1−1x⩾0x<0
2. 图形表示
如图所示,圆和叉分别是特征空间中的点,从图中可以看出他们是线性可分的,线性方程 w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0为一个超平面,w是超平面的法向量,b是超平面的截距,超平面将空间中的点分为正负两类
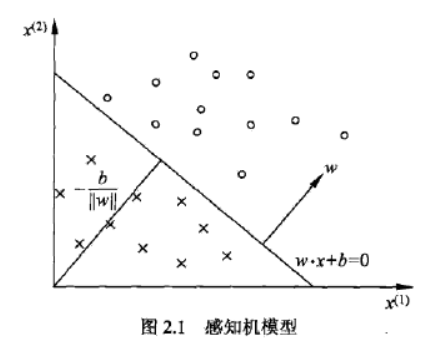
注意:为什么图中的 w w w是超平面的法向量呢?
首先我们知道两个向量内积,如果两个向量垂直,那么内积就是0,也就是说 a ⃗ ⋅ b ⃗ = 0 \vec{a} \cdot \vec{b}=0 a⋅b=0,可以得到 a ⃗ ⊥ b ⃗ \vec{a} \perp \vec{b} a⊥b,图中的 w w w也是如此
每一个点都是一个二维的数据,任取一个点 x i x_{i} xi,包括 [ x i ( 1 ) , x i ( 2 ) ] T [x_{i}^{(1)}, x_{i}^{(2)}]^{T} [xi(1),xi(2)]T,在计算过程中我们将 w 和 x w和x w和x的内积展开,也就是说我们得到 w ( 1 ) x i ( 1 ) + w ( 2 ) x i ( 2 ) + b = 0 w^{(1)}x_{i}^{(1)}+w^{(2)}x_{i}^{(2)}+b=0 w(1)xi(1)+w(2)xi(2)+b=0,我们忽略掉 b b b,也就是说 w ( 1 ) x i ( 1 ) + w ( 2 ) x i ( 2 ) = 0 w^{(1)}x_{i}^{(1)}+w^{(2)}x_{i}^{(2)}=0 w(1)xi(1)+w(2)xi(2)=0,所以得到 w ⃗ ⊥ x ⃗ \vec{w} \perp \vec{x} w⊥x。那么 b b b是什么呢? b b b表示超平面沿着 w ⃗ \vec{w} w移动的距离。
3. 线性可分
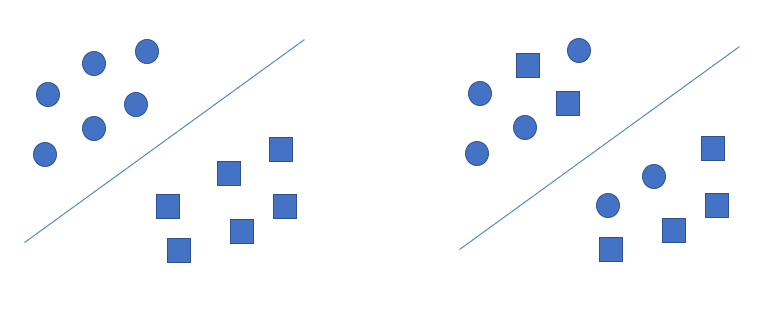
定义:给定一个数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{N}, y_{N})\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_{i} \in X=\mathbb{R}^{n} xi∈X=Rn, y i ∈ Y = { + 1 , − 1 } y_{i} \in Y=\{+1, -1\} yi∈Y={+1,−1}, i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N,如果存在某个超平面 S : w ⋅ x + b = 0 S:w \cdot x+b=0 S:w⋅x+b=0能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有的 y i = + 1 y_{i}=+1 yi=+1的实例 i i i,有 w ⋅ x + b > 0 w \cdot x+b>0 w⋅x+b>0,对所有 y i = − 1 y_{i}=-1 yi=−1的实例 i i i,有 w ⋅ x + b < 0 w \cdot x+b<0 w⋅x+b<0,则称数据集 T T T为线性可分数据集(linearly separable data set); 否则,数据集 T T T线性不可分。
如下图所示,左边的数据集可以找到一个超平面将其分开,所以是线性可分的;右边数据集找不到一个超平面将其分开,所以是线性不可分的
二、损失函数
一共有两种定义损失函数的方法
- 误分类点的总数:损失函数不是 w , b w,b w,b的连续可导函数,不易优化
- 误分类点到超平面的总距离:采用此方法
损失函数
空间
R
n
\mathbb{R}^{n}
Rn上的某点到超平面
S
S
S的距离
d
=
∣
w
⋅
x
+
b
∣
∣
∣
w
∣
∣
d = \frac{|w \cdot x+b|}{||w||}
d=∣∣w∣∣∣w⋅x+b∣
对于正确分类点
w
⋅
x
+
b
>
0
w \cdot x+b>0
w⋅x+b>0时,
y
i
=
1
y_{i}=1
yi=1;
w
⋅
x
+
b
<
0
w \cdot x+b<0
w⋅x+b<0时,
y
i
=
−
1
y_{i}=-1
yi=−1,即
y
i
(
w
⋅
x
i
+
b
)
>
0
y_{i}(w \cdot x_{i}+b)>0
yi(w⋅xi+b)>0
对于误分类点
y
i
(
w
⋅
x
i
+
b
)
<
0
y_{i}(w \cdot x_{i}+b)<0
yi(w⋅xi+b)<0,即
−
y
i
(
w
⋅
x
i
+
b
)
>
0
-y_{i}(w \cdot x_{i}+b)>0
−yi(w⋅xi+b)>0,设误分类点的集合为
M
M
M,则所有误分类点到超平面的总距离为
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
∣
∣
w
∣
∣
L(w,b)=-\frac{\sum_{x_{i} \in M}y_{i}(w \cdot x_{i}+b)}{||w||}
L(w,b)=−∣∣w∣∣∑xi∈Myi(w⋅xi+b),为了计算简便,这里将分母去掉,也就是说感知机的最终的损失函数为
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b)=-\sum_{x_{i}\in M}y_{i}(w \cdot x_{i}+b)
L(w,b)=−xi∈M∑yi(w⋅xi+b)
损失函数是非负的,当没有误分类点时,损失函数为0
三、感知机的求解
1. 原始形式
(1) 求解过程
首先给出具体的求解过程
给定一个数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_{1}, y_{1}), (x_{2}, y_{2}),...,(x_{N}, y_{N})\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_{i} \in X=\mathbb{R}^{n} xi∈X=Rn, y i ∈ Y = { + 1 , − 1 } y_{i} \in Y=\{+1, -1\} yi∈Y={+1,−1}, i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N,学习率 η ( 0 < η ≤ 1 ) \eta(0<\eta \leq 1) η(0<η≤1)
感知机模型: f ( x ) = s i g n ( w ⋅ x + b ) f(x) = sign(w \cdot x+b) f(x)=sign(w⋅x+b)
损失函数: L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w,b)=-\sum_{x_{i}\in M}y_{i}(w \cdot x_{i}+b) L(w,b)=−∑xi∈Myi(w⋅xi+b)
- 选取初值 w 0 , b 0 w_{0}, b_{0} w0,b0
- 在训练集中选取数据 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)
- 判断是否为误分点,即如果
y
i
(
w
⋅
x
i
+
b
)
≤
0
y_{i}(w \cdot x_{i}+b) \leq0
yi(w⋅xi+b)≤0,更新
- w n e w = w o l d + η y i x i w_{new} = w_{old}+\eta y_{i}x_{i} wnew=wold+ηyixi
- b n e w = b o l d + η y i b_{new} = b_{old}+\eta y_{i} bnew=bold+ηyi
- 转到第二步,直到没有误分类点为止
直观解释:如下图所示,当有一个实例点被误分类时,即位于超平面的错误一侧时,则调整 w , b w, b w,b的值,使超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直到超平面越过该误分类点使其被正确分类,如下图所示
- black arrow represents w w w
- black line is decision boundary w T x = 0 w^{T}x=0 wTx=0
- red points are positive, blue are negative
- learning rate η = 1 \eta=1 η=1
- if a linear classifier exists for the given dataset, then perceptron can converge
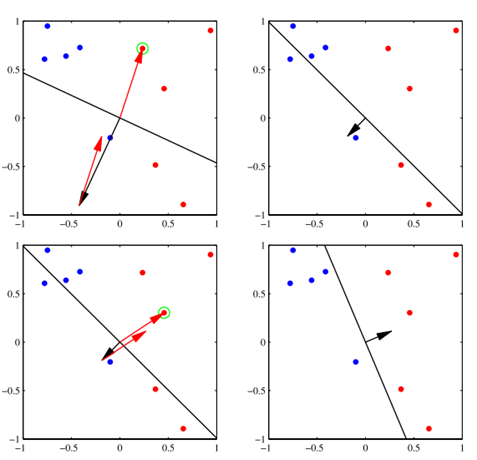
注意
- 在上述更新
w
,
b
w, b
w,b的时候需要计算梯度,即对于
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b)=-\sum_{x_{i}\in M}y_{i}(w \cdot x_{i}+b)
L(w,b)=−∑xi∈Myi(w⋅xi+b),分别对
w
,
b
w, b
w,b进行求导就可以得到更新的参数形式
▽ w L ( w , b ) = − ∑ x i ∈ M y i x i ▽ b L ( w , b ) = − ∑ x i ∈ M y i \bigtriangledown_{w} L(w, b) = -\sum_{x_{i}\in M}y_{i}x_{i} \\ \bigtriangledown_{b} L(w, b) = -\sum_{x_{i}\in M}y_{i} ▽wL(w,b)=−xi∈M∑yixi▽bL(w,b)=−xi∈M∑yi - 在更新时采用随机梯度下降法。通过上述求解步骤我们发现在极小化过程中不是对所有误分类点进行求和然后梯度下降,而是一次选取一个误分类点执行梯度下降,所以是
SGD
(2) 具体实例
这里引用统计学习课本上的一个实例
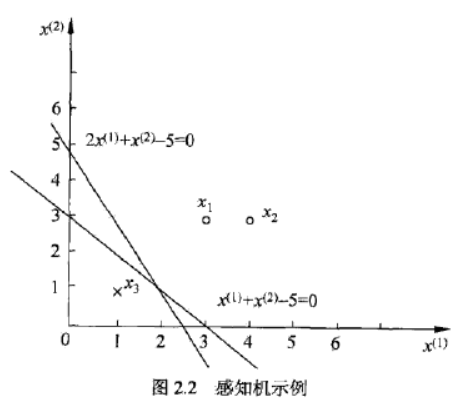
如图:正实例点为 x 1 = ( 3 , 3 ) T , x 2 = ( 4 , 3 ) T x_{1}=(3, 3)^{T},x_{2}=(4, 3)^{T} x1=(3,3)T,x2=(4,3)T,负实例点是 x 3 = ( 1 , 1 ) T x_{3}=(1, 1)^{T} x3=(1,1)T,试用原始形式求感知机模型 f ( x ) = s i g n ( w ⋅ x + b ) f(x) = sign(w \cdot x+b) f(x)=sign(w⋅x+b),其中 w = ( w 1 , w 2 ) T w = (w^{1}, w^{2})^{T} w=(w1,w2)T, x = ( x 1 , x 2 ) T x = (x^{1}, x^{2})^{T} x=(x1,x2)T
求解
arg min
w
,
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
\underset {w, b}{\operatorname {arg\,min}} L(w,b)=-\sum_{x_{i}\in M}y_{i}(w \cdot x_{i}+b)
w,bargminL(w,b)=−xi∈M∑yi(w⋅xi+b)
- 初始化 w 0 = 0 , b 0 = 0 w_{0}=0, b_{0}=0 w0=0,b0=0
- 取 x 1 = ( 3 , 3 ) T x_{1} = (3, 3)^{T} x1=(3,3)T, y i ( w ⋅ x i + b ) = 1 ( 0 × 3 + 0 × 3 ) = 0 y_{i}(w \cdot x_{i}+b)=1(0\times3+0\times3)=0 yi(w⋅xi+b)=1(0×3+0×3)=0,误分类
- 更新
w
,
b
w, b
w,b
w 1 = w 0 + η y 1 x 1 = ( 0 , 0 ) T + 1 × ( 3 , 3 ) T = ( 3 , 3 ) T b 1 = b 0 + η y 1 = 0 + 1 × 1 = 1 w_{1} = w_{0}+\eta y_{1}x_{1} = (0, 0)^{T}+1\times (3, 3)^{T} = (3, 3)^{T} \\ b_{1} = b_{0}+\eta y_{1} = 0+1\times 1 =1 w1=w0+ηy1x1=(0,0)T+1×(3,3)T=(3,3)Tb1=b0+ηy1=0+1×1=1 - 取 x 1 = ( 3 , 3 ) T x_{1} = (3, 3)^{T} x1=(3,3)T, y 1 ( w 1 ⋅ x 1 + b 1 ) = 1 ( 3 × 3 + 3 × 3 ) > 0 y_{1}(w_{1} \cdot x_{1}+b_{1})=1(3\times3+3\times3)>0 y1(w1⋅x1+b1)=1(3×3+3×3)>0,正确分类
- 取 x 2 = ( 4 , 3 ) T x_{2} = (4, 3)^{T} x2=(4,3)T, y 2 ( w 1 ⋅ x 2 + b 1 ) = 1 ( 3 × 4 + 3 × 3 ) > 0 y_{2}(w_{1} \cdot x_{2}+b_{1})=1(3\times4+3\times3)>0 y2(w1⋅x2+b1)=1(3×4+3×3)>0,正确分类
- 取 x 3 = ( 1 , 1 ) T x_{3} = (1, 1)^{T} x3=(1,1)T, y 3 ( w 1 ⋅ x 3 + b 1 ) = − 1 ( 3 × 1 + 3 × 1 ) < 0 y_{3}(w_{1} \cdot x_{3}+b_{1})=-1(3\times1+3\times1)<0 y3(w1⋅x3+b1)=−1(3×1+3×1)<0,误分类
- 更新
w
,
b
w, b
w,b
w 2 = w 1 + η y 3 x 3 = ( 3 , 3 ) T + ( − 1 ) × ( 1 , 1 ) T = ( 2 , 2 ) T b 2 = b 1 + η y 3 = 1 + 1 × − 1 = 0 w_{2} = w_{1}+\eta y_{3}x_{3} = (3, 3)^{T}+(-1)\times (1,1)^{T} = (2, 2)^{T} \\ b_{2} = b_{1}+\eta y_{3} = 1+1\times -1 =0 w2=w1+ηy3x3=(3,3)T+(−1)×(1,1)T=(2,2)Tb2=b1+ηy3=1+1×−1=0 - 如此迭代直到没有误分类点为止
也就是说具体的迭代过程是:首先找 x 1 x_{1} x1是不是误分类点,是的话更新 w , b w, b w,b直到他变为正确分类点为止,然后看一看 x 2 x_{2} x2是不是误分类点,不是的话看看 x 3 x_{3} x3,如果 x 3 x_{3} x3是误分类点,那么在更新 w , b w, b w,b直到 x 3 x_{3} x3不是误分类点,此时到了关键的一步:不要停止,在从 x 1 x_{1} x1到 x 3 x_{3} x3重新计算一遍看看是否有误分类点,假设在更新 x 3 x_{3} x3的时候超平面 S S S进行了移动,那么有可能之前本来已经处于正确分类的点又变回了误分类,哪有人会问,这样后面会影响前面的话他会收敛吗,答案是肯定的,因为已经有人证明当数据是线性可分的时候,必然会进行收敛
注意:在迭代过程中误分类点是随机选取的,也就是说随着选取顺序的不同,最终的超平面也不同,这很容易理解,因为从图上我们可以直观的看出,能够将两种类型的点区分开的超平面不止一个
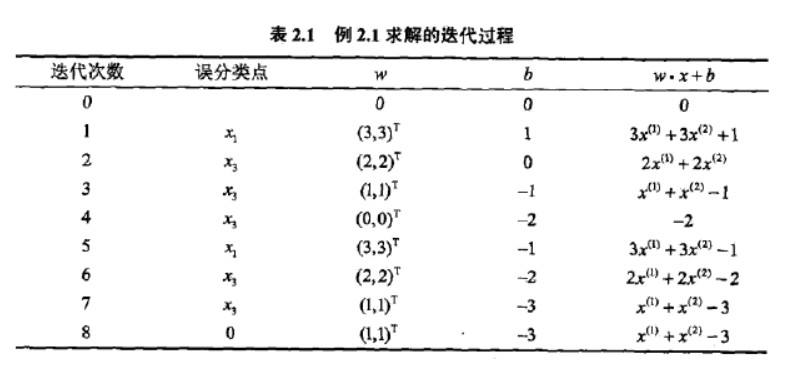
下面给出迭代过程
2. 对偶形式
首先我们看一下上述损失函数对
w
,
b
w, b
w,b的梯度
▽
w
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
x
i
▽
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
\bigtriangledown_{w} L(w, b) = -\sum_{x_{i}\in M}y_{i}x_{i} \\ \bigtriangledown_{b} L(w, b) = -\sum_{x_{i}\in M}y_{i}
▽wL(w,b)=−xi∈M∑yixi▽bL(w,b)=−xi∈M∑yi
上述数值就是每次我们进行更新时的梯度大小,可以观察到每次更新的结果与
x
i
y
i
x_{i}y_{i}
xiyi有关,当一个点误分类时我们就将当前的
w
,
b
w,b
w,b进行一次修改,当最终找到超平面时,
w
,
b
w,b
w,b就会利用
x
i
,
y
i
x_{i}, y_{i}
xi,yi修改
n
i
n_{i}
ni次
为了更直观的理解,先给出感知机的对偶形式最终的结果
w
=
∑
i
=
1
N
α
i
y
i
x
i
=
∑
i
=
1
N
n
i
η
y
i
x
i
b
=
∑
i
=
1
N
α
i
y
i
=
∑
i
=
1
N
n
i
η
y
i
w = \sum_{i=1}^{N}\alpha_{i} y_{i}x_{i} = \sum_{i=1}^{N}n_{i}\eta y_{i}x_{i} \\ b = \sum_{i=1}^{N}\alpha_{i} y_{i} = \sum_{i=1}^{N}n_{i}\eta y_{i}
w=i=1∑Nαiyixi=i=1∑Nniηyixib=i=1∑Nαiyi=i=1∑Nniηyi
即如果设置
w
0
=
0
,
b
0
=
0
w_{0}=0, b_{0}=0
w0=0,b0=0,那么在进行迭代之后会得到
Δ
w
=
w
0
+
∑
i
=
1
N
n
i
η
y
i
x
i
=
w
0
+
n
1
η
y
1
x
1
+
n
2
η
y
2
x
2
+
.
.
.
+
n
N
η
y
N
x
N
Δ
b
=
b
0
+
∑
i
=
1
N
n
i
η
y
i
=
b
0
+
n
1
η
y
1
+
n
2
η
y
2
+
.
.
.
+
n
N
η
y
N
\Delta w =w_{0} + \sum_{i=1}^{N}n_{i}\eta y_{i}x_{i} = w_{0} + n_{1}\eta y_{1}x_{1} + n_{2}\eta y_{2}x_{2} +...+n_{N}\eta y_{N}x_{N} \\ \Delta b =b_{0} + \sum_{i=1}^{N}n_{i}\eta y_{i} =b_{0} + n_{1}\eta y_{1} + n_{2}\eta y_{2} +...+n_{N}\eta y_{N}
Δw=w0+i=1∑Nniηyixi=w0+n1ηy1x1+n2ηy2x2+...+nNηyNxNΔb=b0+i=1∑Nniηyi=b0+n1ηy1+n2ηy2+...+nNηyN
其中 n i n_{i} ni表示样本点 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)在更新时被用了 n i n_{i} ni次, n i n_{i} ni越大代表这个样本点被经常使用,说明该样本点在超平面附近,当超平面进行微小的变化该样本点就会被误分类,我们知道了 w , b w, b w,b以后,令 α i = n i η \alpha_{i} = n_{i}\eta αi=niη,直接给出感知机模型的形式
感知机模型: f ( x ) = s i g n ( w ⋅ x + b ) = s i g n ( ∑ i = 1 N α i y i x i ⋅ x + ∑ i = 1 N α i y i ) f(x) = sign(w \cdot x+b) = sign(\sum_{i=1}^{N}\alpha_{i} y_{i}x_{i} \cdot x+\sum_{i=1}^{N}\alpha_{i} y_{i}) f(x)=sign(w⋅x+b)=sign(∑i=1Nαiyixi⋅x+∑i=1Nαiyi)
感知机的对偶形式在更新时并不是更新 w , b w, b w,b,而是更新 n i n_{i} ni
算法流程
- 令所有 n i = 0 n_{i}=0 ni=0,即 α i = 0 \alpha_{i}=0 αi=0
- 在训练集中选取数据 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)
- 判断是否为误分点,即如果
y
i
(
∑
i
=
1
N
α
i
y
i
x
i
⋅
x
+
∑
i
=
1
N
α
i
y
i
)
≤
0
y_{i}(\sum_{i=1}^{N}\alpha_{i} y_{i}x_{i} \cdot x+\sum_{i=1}^{N}\alpha_{i} y_{i}) \leq0
yi(∑i=1Nαiyixi⋅x+∑i=1Nαiyi)≤0,则
n
i
=
n
i
+
1
n_{i}=n_{i}+1
ni=ni+1,因为
α
i
=
n
i
η
\alpha_{i} = n_{i}\eta
αi=niη,所以
α
i
=
α
i
+
η
\alpha_{i} = \alpha_{i}+\eta
αi=αi+η,更新
- w = w + η y i x i w = w + \eta y_{i}x_{i} w=w+ηyixi
- b = b + η y i b = b + \eta y_{i} b=b+ηyi
- 转到第二步,直到没有误分类点为止
所以相比于原始形式,对偶形式并没有本质的区别,而是可以将样本点的特征向量以内积的形式存在于感知机的对偶形式算法中,如果事先计算好所有的内积,即Gram矩阵,就可以大大加快计算速度
四、程序实例
下面用python展示一个感知机原始形式的计算实例
# 利用Python实现感知机算法的原始形式
import numpy as np
import matplotlib.pyplot as plt
def createData():
samples = np.array([[1, 2], [2, 3], [3, 3], [2, 1], [3, 2]])
labels = [1, 1, 1, -1, -1]
return samples, labels
class Perception:
def __init__(self, x, y, lr=1):
self.x = x
self.y = y
self.l_rate = lr
self.w = np.random.rand(x.shape[1], 1)
self.b = 0
self.numSimples = x.shape[0]
self.numFeatures = x.shape[1]
def sign(self, w, b, x):
y = np.dot(x, w) + b # x .w + b
if y >= 0:
y = 1
else:
y = -1
return y
def update(self, label_i, data_i):
tmp = label_i * self.l_rate * data_i # w = w + n yx
tmp = tmp.reshape(self.w.shape)
self.w = tmp + self.w
self.b = self.b + label_i * self.l_rate # b = b + n y
def train(self):
isFind = False
step = 1
while not isFind:
count = 0
for row in range(self.numSimples):
simY = self.sign(self.w, self.b, self.x[row, :])
if simY * self.y[row] <= 0: # 如果是一个误分类实例点
print("------------------------step{}----------------------".format(step) )
print('误分类点为:', self.x[row, :], '此时的w和b为:', self.w[0], self.w[1], self.b)
count += 1
step += 1
self.update(self.y[row], self.x[row])
if count == 0:
print("训练完成:")
print('最终训练得到的w和b为:', self.w[0], self.w[1], self.b)
isFind = True
return self.w, self.b
def plot_figure(samples, w, b):
plt.figure(1)
plt.title("Perception Algorithm", size=14)
plt.xlabel("x1", size=14)
plt.ylabel("x2", size=14)
x1 = np.linspace(0, 5, 100)
x2 = expression(x1, w, b)
plt.plot(x1, x2, color='r', label='data')
plt.scatter(samples[0][0], samples[0][1], s=50)
plt.scatter(samples[1][0], samples[1][1], s=50)
plt.scatter(samples[2][0], samples[2][1], s=50)
plt.scatter(samples[3][0], samples[3][1], s=50, marker='x')
plt.scatter(samples[4][0], samples[4][1], s=50, marker='x')
plt.savefig('perception.png', dpi=75)
plt.show()
def expression(x1, w, b):
x2 = (-b - w[0] * x1) / w[1]
# 注意在此,把x0,x1当做两个坐标轴,把x1当做自变量,x2为因变量
return x2
if __name__ == '__main__':
np.random.seed(2)
samples, labels = createData()
myperceptron = Perception(x=samples, y=labels, lr=1)
weights, bias = myperceptron.train()
Picture = plot_figure(samples, weights, bias)
'''输出
------------------------step1----------------------
误分类点为: [2 1] 此时的w和b为: [0.4359949] [0.02592623] 0
------------------------step2----------------------
误分类点为: [1 2] 此时的w和b为: [-1.5640051] [-0.97407377] -1
------------------------step3----------------------
误分类点为: [3 2] 此时的w和b为: [-0.5640051] [1.02592623] 0
------------------------step4----------------------
误分类点为: [1 2] 此时的w和b为: [-3.5640051] [-0.97407377] -1
------------------------step5----------------------
误分类点为: [2 3] 此时的w和b为: [-2.5640051] [1.02592623] 0
------------------------step6----------------------
误分类点为: [2 1] 此时的w和b为: [-0.5640051] [4.02592623] 1
训练完成:
最终训练得到的w和b为: [-2.5640051] [3.02592623] 0
'''


















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









