







归一化的主要公式
1.将数据归一到[0,1]:
x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x^{\prime} =\frac{x - min(x)}{max(x)-min(x)} x′=max(x)−min(x)x−min(x)
其中 m a x ( x ) max(x) max(x)和 m i n ( x ) min(x) min(x)分别是数据的最大值和最小值。
2.将数据归一化到[-1,1]:
x ′ = x − m e a n ( x ) m a x ( x ) − m i n ( x ) x^{\prime}=\frac{x-mean(x)}{max(x)-min(x)} x′=max(x)−min(x)x−mean(x)
其中 m e a n ( x ) mean(x) mean(x)是数据的均值。
3.将数据归一化到均值为0,标准差为1的标准正态分布上:
x ′ = x − μ σ x^{\prime}= \frac{x-\mu}{\sigma} x′=σx−μ
其中 μ \mu μ和 σ \sigma σ分别是数据的均值和标准差。
4.将数据归一化到[a,b]:
计算系数:
k
=
b
−
a
m
a
x
(
x
)
−
m
i
n
(
x
)
k=\frac{b-a}{max(x)-min(x)}
k=max(x)−min(x)b−a
数据归一化:
x ′ = a + k × ( x − m i n ( x ) ) x^{\prime}=a+k\times(x-min(x)) x′=a+k×(x−min(x))
或者
x ′ = b + k × ( x − m a x ( x ) ) x^{\prime}=b+k\times(x-max(x)) x′=b+k×(x−max(x))
归一化的作用
- 消除数据之间的量纲的影响,是数据的分布一致。(尤其是神经网络一直在算概率)
- 使数据集的更新速度变得更为一致,容易更快地通过梯度下降找到最优解(加速收敛速度)。如下图所示。
- 消除异常样本的影响,异常样本会增加网络学习难度,可能导致训练不收敛。
- 保证输出特征中数值小的特征也可以被充分学习。
- 避免梯度消失,比如使用Sigmoid激活函数时,数值小于0和大于1时会导致梯度几乎为0。
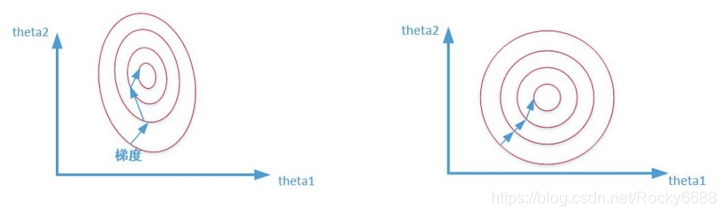
归一化应用场景
需要用到梯度下降法求解的模型通常需要归一化,如线性回归,罗辑回归,支持向量机和神经网络等模型。
但是对于决策树则并不适用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。
不进行归一化的后果
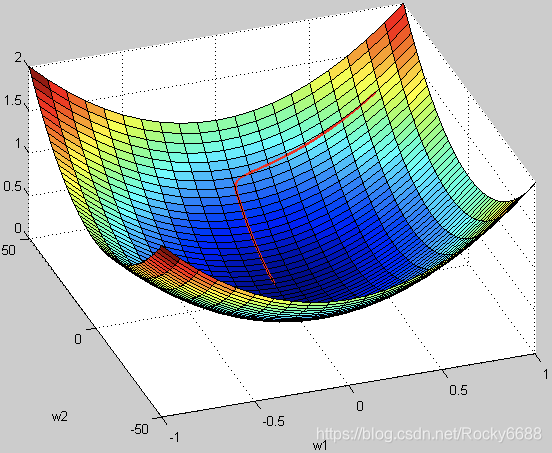
假设 w 1 w1 w1 的范围在 [ − 10 , 10 ] [-10, 10] [−10,10],而 w 2 w2 w2 的范围在 [ − 100 , 100 ] [-100, 100] [−100,100],梯度每次都前进 1 单位,那么在 w 1 w1 w1 方向上每次相当于前进了 1 / 20 1/20 1/20,而在 w 2 w2 w2 上只相当于 1 / 200 1/200 1/200!某种意义上来说,在 w 2 w2 w2 上前进的步长更小一些,而 w 1 w1 w1 在搜索过程中会比 w 2 w2 w2 “走”得更快。
这样会导致,在搜索过程中更偏向于 w 1 w1 w1 的方向。走出了“L”形状,或者成为“之”字形。















 2119
2119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











