







获取分组后排名
主要使用groupby 和 rank方法
import pandas as pd
data = {'year':['2018','2018','2018','2019','2019'],
'数学':[23, 99, 90, 30, 10]}
df = pd.DataFrame(data)
df
df['rank'] = df.groupby('year')['数学'].rank(ascending=False)
df

获取组内的topN
主要使用sort_values 、 groupby 和 head
import pandas as pd
data = {'year':['2018','2018','2018','2019','2019'],
'数学':[23, 99, 90, 30, 10]}
df = pd.DataFrame(data)
df
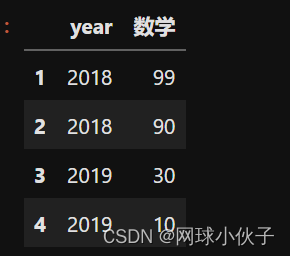
df = df.sort_values(by="数学", ascending=False).groupby(["year"]).head(2)
df















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









