







论文地址:TextAug: Test time Text Augmentation for Multimodal Person Re-identification
代码地址:未公布(2025.01.22)
bib引用:
@INPROCEEDINGS{
10495691,
author={
Fawakherji, Mulham and Vazquez, Eduard and Giampa, Pasquale and Bhattarai, Binod},
booktitle={
2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW)},
title={
TextAug: Test Time Text Augmentation for Multimodal Person Re-Identification},
year={
2024},
volume={
},
number={
},
pages={
320-329},
keywords={
Deep learning;Training;Computer vision;Computational modeling;Soft sensors;Conferences;Data augmentation},
doi={
10.1109/WACVW60836.2024.00040}}
InShort
提出一种在推理时对多模态行人重识别进行文本增强的方法TextAug,通过融合CV的Cutout和CutMix提升模型性能与泛化能力。
- 研究背景
- 多模态行人重识别:结合图像和文本等多模态数据的行人重识别研究受关注,但多模态深度学习需大量训练数据。
- 数据增强技术:图像领域常用裁剪、翻转等增强技术提升模型泛化能力,自然语言处理(NLP)中数据增强困难,如同义词替换需外部数据源,预训练语言模型或翻译系统需大量计算资源且受语言限制。
- 相关工作
- 行人重识别方法:传统方法聚焦于开发判别特征或进行度量学习,深度学习中CNNs被广泛应用,但存在过拟合问题,轻量化模型及网络架构搜索等方法被提出。
- 文本查询与多模态融合:基于文本查询的行人重识别受关注,但面临训练数据获取难、建模复杂等问题。将图像和文本嵌入联合空间的方法在多个任务中取得成功。
- 研究方法
- TextAug文本增强:融合Cutout和CutMix技术,在推理时对查询输入的文本部分进行增强。CutMix通过随机选择句子A的子序列,用其打乱版本的对应子序列替换,按二进制掩码拼接生成新文本;CutOut随机选择并删除输入文本A的部分子序列,用特殊标记替代,按掩码拼接剩余子序列。最终以一定概率随机选择CutMix或CutOut的结果作为增强结果。
- 生成嵌入向量:基于视觉语言预训练(VLP)模型,如CLIP。图像经图像编码器生成嵌入向量,再经线性投影得到图像嵌入;增强后的文本经文本编码器生成嵌入向量并聚合,得到文本最终嵌入。将文本和图像嵌入连接,用于计算不同行人实例间的相似度。
- 实验结果
- 实验设置:使用RSTPReid和PETA两个数据集,采用累积匹配特征(CMC)曲线评估性能,对比基于同义词的PPDB、词嵌入技术等现有文本增强策略,以及不同输入表示方式。
- 性能提升:所有模型在使用文本增强后,top - k准确率均有提高,ViT - L14模型提升最为显著。所提策略在多个指标上优于其他增强策略,结合文本和图像的输入表示方式在行人重识别中表现更准确。增加文本描述的单词数量可提高准确率。
- 定性分析:可视化结果表明,引入增强文本和混合嵌入能提高检索准确率,在特征空间中,结合增强文本和图像的嵌入使相同身份的嵌入更接近。
- 研究结论:TextAug是一种有效的多模态行人重识别方法,在推理时进行文本增强可提升基于图像的行人重识别模型性能,增强深度学习模型在NLP中的泛化能力和行人重识别模型的鲁棒性。
摘要
多模态人员重新识别在研究界越来越受欢迎,因为它与对应的 unimodal frameworks 相比是有效的。然而,多模态深度学习的瓶颈是需要大量的多模态训练示例。数据增强技术(如裁剪、翻转、旋转等)通常用于图像域,以提高深度学习模型的泛化。使用图像以外的其他形式(例如文本)进行增强是一项挑战,并且需要大量的计算资源和外部数据源。在这项研究中,我们调查了两种计算机视觉数据增强技术 “cutout” 和 “cutmix” 在多模态人物重新识别中用于文本增强的有效性。我们的方法将这两种增强策略合并为一种称为 “CutMixOut” 的策略,该策略涉及从句子中随机删除单词或子短语 (Cutout) 并混合两个或多个句子的部分以创建不同的示例 (CutMix),并为每个操作分配一定的概率。这种增强是在推理时实现的,无需任何事先训练。我们的结果表明,所提出的技术在提高多个多模态人物再识别基准的性能方面简单而有效。
Introduction
近年来,将图像和文本的表示嵌入到一个联合空间中以完成各种任务引起了极大的研究兴趣。这种方法已成功应用于图像注释和搜索 [2, 17]、零样本识别 [31, 35]、鲁棒图像分类 [10]、图像描述生成 [16]、视觉问答 [27] 等任务。总之,在联合空间中嵌入图像和文本表示的能力为各种任务提供了许多潜在的好处。
除了利用多模态输入外,数据增强在过去十年中还广泛用于计算机视觉 (CV)。图像上的几何增强,如裁剪、反射和平移 [19] 已成为 CV 中的标准技术,并迅速成为提高计算机视觉模型泛化的常见方法 [13, 33]。特别是,这些技术已被用于增加训练数据集的大小和减少过度拟合。然而,在自然语言处理 (NLP) 中增强数据一直是一项具有挑战性的任务。像同义词替换 [47] [41] 这样的简单方法需要外部数据源(如同义词库),并为同义词集选择算法带来额外的工程成本。需要其他方法,如预先训练的语言模型 [18] 或翻译系统 [9, 41] 来改写训练文本,这限制了可以从数据增强中受益的语言集,并使资源匮乏的语言与英语相比更具挑战性。此外,这些方法需要大量的计算资源。为了应对这些挑战,NLP 研究人员提出了计算机视觉方法的应用,如 Mixup [11, 12, 15],它通过对输入数据和标签进行加权线性组合来组合成对的示例。这种方法会生成新的合成样本,这些样本是输入样本的线性插值,从而增加了训练数据的多样性,提高了模型的泛化能力。Mixup 是一种软增强技术,它可以平滑地混合输入示例以生成新示例,并且生成的示例通常保留两个输入示例的特征。
Cutout [6] 和 CutMix [44] 是计算机视觉中常用的数据增强技术,用于增强深度学习模型的鲁棒性和泛化性。与 Mixup 不同,我们提出的增强 CutMix 和 Cutout 是硬增强技术,它们通过删除或替换输入样本的一部分来操纵输入数据,并为输入样本引入更高程度的变化,通常会导致输入数据发生更显着的变化。这可以提高模型对 NLP 中输入数据中的噪声和失真的弹性。这些技术可以有效地增加训练数据集的大小并防止过拟合。在我们的研究中,我们考虑为每个人只有一个句子描述,这使得实现需要成对示例的 Mixup 算法变得困难。因此,我们专注于利用 CutMix 和 Cutout 技术,因为它们可以应用于单个示例,并且仍然会在数据中引入变化。

图 1.显示用作人员重新识别模型输入的不同文本增强策略的比较。第一行从左到右显示原始文本和使用来自 PPDB 数据集的同义词替换扩充的文本。第二行从左到右显示了使用 Cutout 扩充的文本和使用 Word2Vec 生成的文本嵌入。
我们采用了这些方法来增强文本描述,并将其用于多模态人物重新识别的上下文中。图 1 将我们的方法与一些重要的现有文本增强方法进行了比较。与同义词 PPDB [28] 和单词嵌入 [39] 不同,我们的方法很简单,不需要同义词库或 WordNet 等外部数据库。同义词 PPDB 用它们的同义词替换了一些原始单词,它产生了一个语法正确的句子,但在描述原始场景时缺乏连贯性和准确性。短语 “eyes walked with two paws on either other” 似乎是同义词替换过程中错误的结果,在场景的上下文中没有意义。同样,Word Embeddings 通过替换具有相似含义的单词来生成文本的变体,从而生成与原始文本相似但措辞略有不同的句子。然而,这种技术似乎错过了现场的一些重要细节,比如他穿着黑色外套和黑色裤子。另一方面,Cutout 和 Cutmix 制作了原始文本的变体,这些变体在描述场景时是连贯和精确的。Cutout 遮罩了图像的随机部分,而 Cutmix 通过将一个图像的随机部分剪切并粘贴到另一个图像上来混合两个不同的图像。这两种技术都保留了场景的主要元素,例如作为男人的衣服,同时在措辞中引入细微的变化。我们的方法涉及将文本增强技术应用于查询输入,其中包括文本和图像。图 2 总结了我们的pipeline。使用文本增强方法对文本进行处理以生成多个表示形式。然后将这些表示形式馈送到文本编码器,该编码器会生成相应的文本嵌入。同样,图像通过图像编码器传递,该编码器生成图像嵌入。生成的文本嵌入将聚合在一起,生成的聚合与图像嵌入连接在一起,以形成查询输入的最终表示形式。在我们的管道中,我们利用了一个预先训练的 CLIP 模型 [30],该模型在大量不同的文本和图像数据上进行了训练,可以生成高质量的文本和图像嵌入,以捕获输入数据中的语义和视觉信息。
总而言之,其中一个关键贡献是一种简单而有效的文本增强技术,称为 CutMixOut,其灵感来自 cutout [7] 和 cutmix [43]。我们在推理过程中使用它来进行多模态人员重新识别。据我们所知,这是在多模态人物重新识别中采用文本增强的第一项工作。从广泛的实验中,我们发现它对个人重新识别非常有效。我们的结果表明,所提出的方法可以在不进一步训练的情况下显着增强模型的泛化。
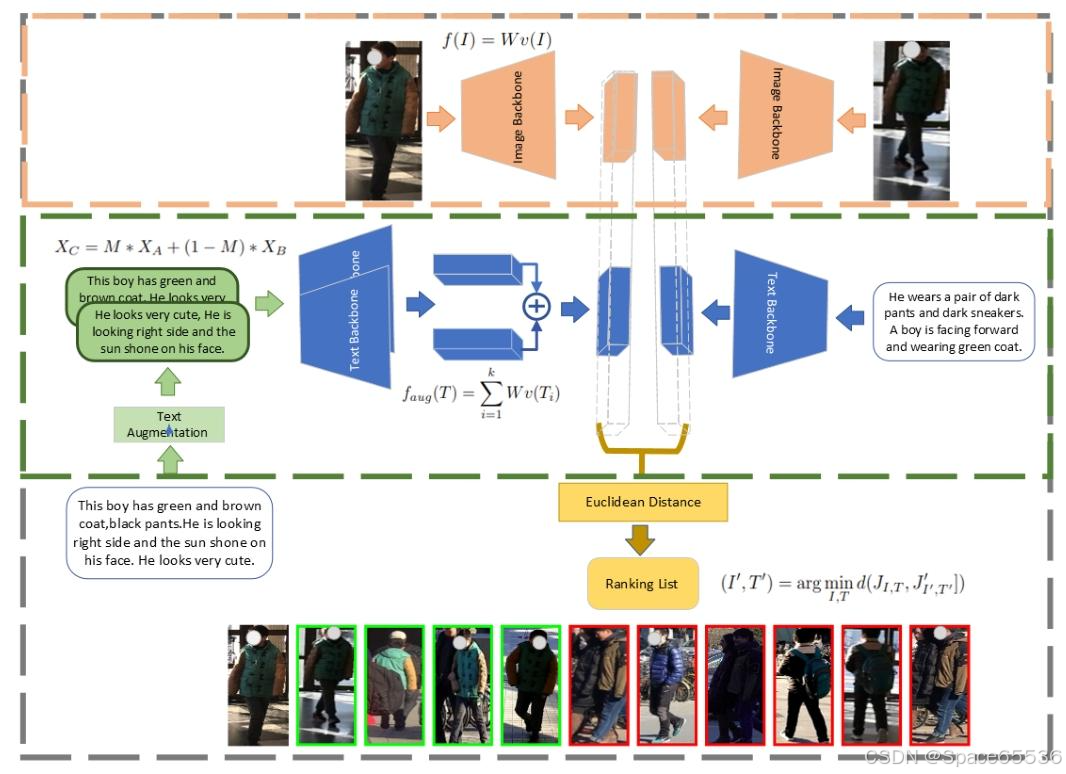
图 2.该图说明了我们的人员重新识别架构,它利用文本和图像输入。在推理过程中,文本输入被增强以生成多种表示形式,并馈送到 Clip 预训练的文本主干模型中。将生成的嵌入向量相加以创建单个文本嵌入向量。图像输入也被馈送到 Clip 预训练的图像主干模型中。文本和图像嵌入将连接起来以生成单个嵌入向量,该向量用于通过测量查询向量和库向量之间的距离来重新识别。
3. 方法
【问题定义】
给定一组 N 个图库图像 I 1 , I 2 , . . . , I N I_{1}, I_{2}, ..., I_{N} I1,I2,...,IN 和一个查询图像 Q ,人员重新识别的目标是在图库集中查找与query image 查询图像。
生成嵌入的过程包括将每个图像映射到捕获图像基本特征的 d 维向量。
过去,手工制作的特征 [24]、距离度量学习 [26] 和深度学习架构 [23] 被用来学习特征 f ( I i ) = ϕ ( I i ) f(I_{i})=\phi(I_{i}) f(Ii)=ϕ(Ii)
其中 I i I_{i} Ii 是图像集中的第 i 个图像,φ 是图像模型, f ( I i ) f(I_{i}) f(Ii) 是图像 I i I_{i} Ii 的嵌入向量
计算嵌入向量后,可以使用距离函数(如欧几里得距离或余弦距离)来测量查询嵌入和每个图像嵌入之间的距离。查询图像与集合中每张图像之间的相似度分数可以计算为: S ( I i , Q ) = d ( f ( I i ) , f ( Q ) ) S(I_{i}, Q)=d(f(I_{i}), f(Q)) S(Ii,Q)=d(f(Ii),f(Q)),其中 Q 是查询图像, f ( Q ) f(Q) f(Q) 是查询图像的嵌入向量,d 是距离函数。与以前大多数只处理图像的作品不同,我们正在处理用于人物重新识别的多模态数据。
多模态ReID 涉及跨不同数据源(例如图像、视频和文本)识别个人。虽然视觉特征传统上是人员重新识别的主要关注点,但文本也可以在这项任务中发挥重要作用。文本可以提供有关一个人身份的有价值的信息,其中可以包括与一个人的外表相关的广泛信息,包括他们衣服的颜色和款式这些信息可以用来补充视觉特征,尤其是在视觉信息不完整或模棱两可的情况下。多模态人员重新识别涉及学习来自多个来源的数据的联合表示,并将查询与画廊进行比较,类似
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









