







1. 什么是正则表达式
正则表达式是处理字串的方法,他是以行为单位来进行字串的处理行为, 正则表达式通过一些特殊符号的辅助,可以让使用者轻易的达到 “搜寻 / 删除 / 取代” 某特定字串的处理程序!
正则表达式一般以文本行进行处理,在进行下面实例之前,建议先为grep命令设置--color参数,这样每次过滤出来的字符串都会带色彩了:
$ alias grep='grep --color=auto'
2. 基础正则表达式
2.1 基础正则表达式字符汇整
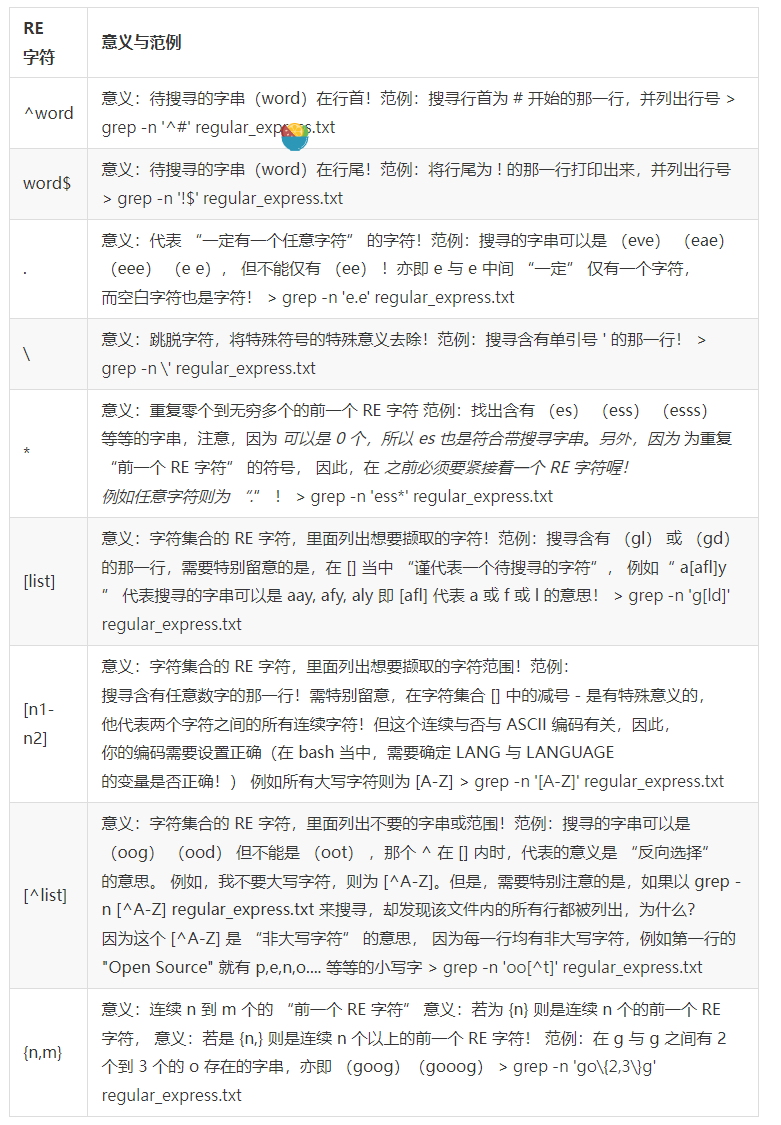
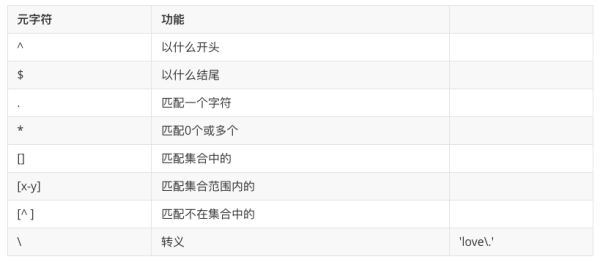
【重要/常用】基础的正则表达式特殊字符汇整如下:
详细版本:
简单版本:
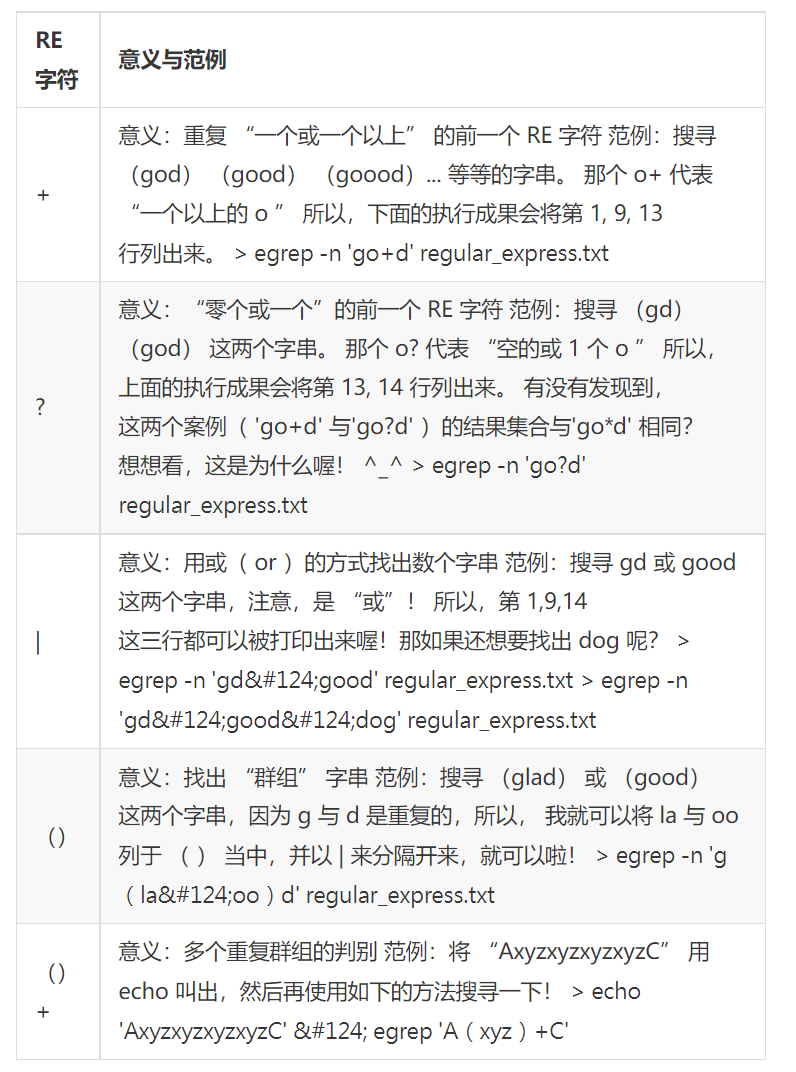
以下是延伸型正则表达式用到的RE字符,可以使用 grep -E搭配以下字符使用:
详细版本:
简单版本:

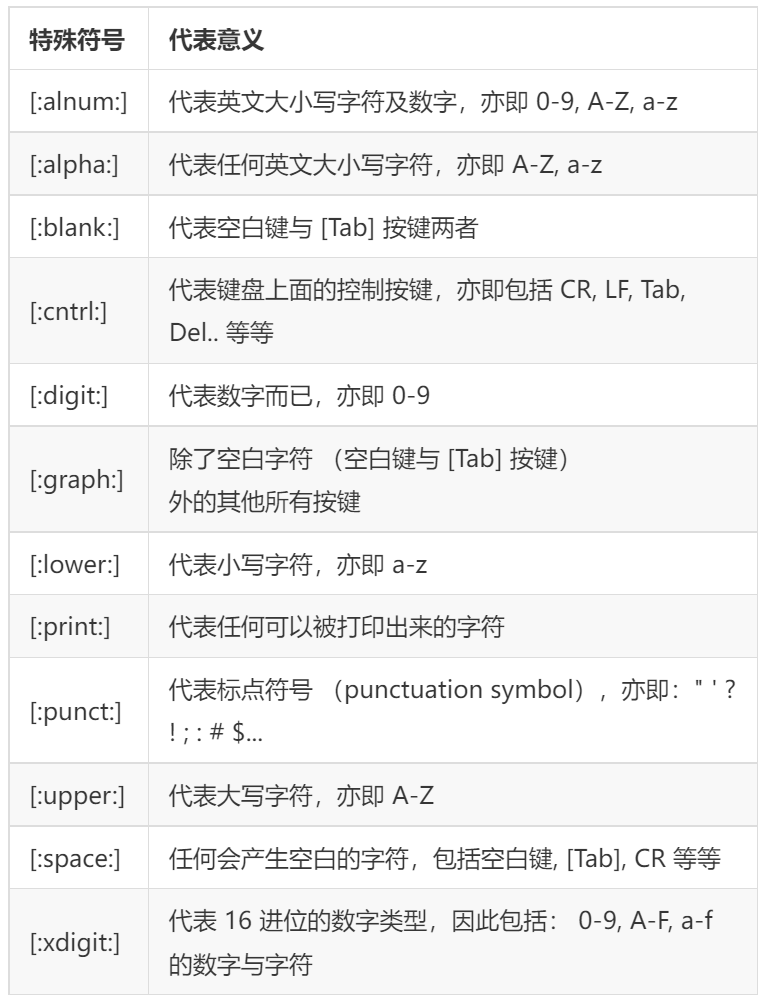
【了解/不是很常用】一些特殊符号的含义:
2.2 正则表达式练习
首先创建一个文本作为练习,文本中输入以下内容:
[dmtsai@study ~]$ vi regular_express.txt
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.
However, this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M
I can't finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car.
This window is clear.
the symbol '*' is represented as start.
Oh! My god!
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.
google is the best tools for search keyword.
goooooogle yes!
go! go! Let's go.
# I am VBird
- 例题一、搜寻特定字串
假设我们要从刚刚的文件当中取得 the 这个特定字串,最简单的方式就是这样:
[dmtsai@study ~]$ grep -n 'the' regular_express.txt
8:I can't finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
如果想要 “反向选择” ,也就是说当该行没有'the' 这个字串时才显示在屏幕上,则:
[dmtsai@study ~]$ grep -vn 'the' regular_express.txt
如果你想要取得不论大小写的the这个字串,则:
[dmtsai@study ~]$ grep -in 'the' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
12:the symbol '*' is represented as start.
14:The gd software is a library for drafting programs.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
- 例题二、利用中括号
[]来搜寻集合字符
如果想要搜寻test或taste这两个单字时,可以发现到,其实她们有共通的't?st' 存在,这个时候,我可以这样来搜寻:
[dmtsai@study ~]$ grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
其实[] 里面不论有几个字符,他都仅代表某 “一个” 字符,所以上面的例子说明了,我需要的字串是 “tast” 或“test”两个字串而已!
如果想要 搜寻oo 但不想要oo前面有 g 的话,可以利用在集合字符的反向选择 来达成:
[dmtsai@study ~]$ grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
假设我 oo 前面不想要有小写字符,可以这样写:
[dmtsai@study ~]$ grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
# 指令也可以是: [dmtsai@study ~]$ grep -n '[^[:lower:]]oo' regular_express.txt
# 那个 [:lower:] 代表的就是 a-z 的意思!请参考前两小节的说明表格
- 例题三、行首与行尾字符
^ $
如果想要让 the 只在行首列出:
[dmtsai@study ~]$ grep -n '^the' regular_express.txt
12:the symbol '*' is represented as start.
如果我想要开头是小写字符的那一行就列出:
[dmtsai@study ~]$ grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
# 指令也可以是: [dmtsai@study ~]$ grep -n '^[[:lower:]]' regular_express.txt
如果我不想要开头是英文字母:
[dmtsai@study ~]$ grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:# I am VBird
# 指令也可以是: grep -n '^[^[:alpha:]]' regular_express.txt
注意:那个
^符号,在字符集合符号(括号[])之内与之外是不同的! 在[]内代表 “反向选择”,在[]
之外则代表定位在行首的意义。
如果我想要找出来,行尾结束为小数点 . 的那一行:
[dmtsai@study ~]$ grep -n '\.$' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
11:This window is clear.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
20:go! go! Let's go.
如果我想要找出来,哪一行是 “空白行”, 也就是说,该行并没有输入任何数据:
[dmtsai@study ~]$ grep -n '^$' regular_express.txt
22:
-
例题四、任意一个字符
.与重复字符*
.和*这两个符号在正则表达式的意义如下: -
. (小数点):代表 “一定有一个任意字符” 的意思; -
*(星星号):代表 “重复前一个字符, 0 到无穷多次” 的意思,为组合形态
假设我需要找出 g??d 的字串,亦即共有四个字符, 起头是 g 而结束是 d ,我可以这样做:
[dmtsai@study ~]$ grep -n 'g..d' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! The soup taste good.
16:The world <Happy> is the same with "glad".
如果我想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog… 等等:
[dmtsai@study ~]$ grep -n 'goo*g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
如果我想要找出 g 开头与 g 结尾的字串,当中的字符可有可无,可以这样写:
[dmtsai@study ~]$ grep -n 'g.*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
- 例题五、限定连续 RE 字符范围
{}
如果想要限制一个范围区间内的重复字符数,举例来说,想要找出两个到五个 o 的连续字串,该如何做?这时候就得要使用到限定范围的字符 {} 了。但因为 { 与} 的符号在 shell 是有特殊意义的,因此, 我们必须要使用跳脱字符\来让他失去特殊意义才行。
假设我要找到两个 o 的字串,可以是:
[dmtsai@study ~]$ grep -n 'o\{2\}' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
假设我们要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样:
[dmtsai@study ~]$ grep -n 'go\{2,5\}g' regular_express.txt
18:google is the best tools for search keyword.














 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









