







Table of Contents
106.DPDK结合网卡虚拟化及Cloud Filter功能
93.说起网卡多队列,顾名思义,也就是传统网卡的DMA队列有多个,网卡有基于多个DMA队列的分配机制。图8-1是Intel®82580网卡的示意图,其很好地指出了多队列分配在网卡中的位置。
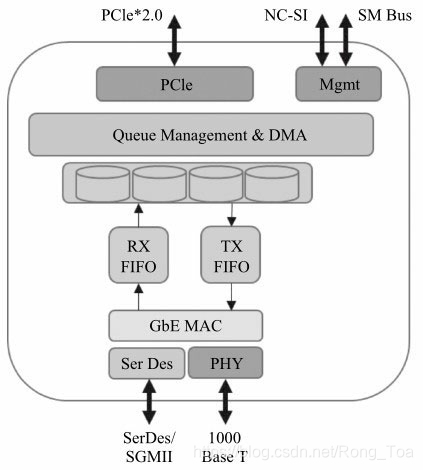
图8-182580网卡的简易框图
网卡多队列技术应该是与处理器的多核技术密不可分的。早期的多数计算机,处理器可能只有一个核,从网卡上收到的以太网报文都需要这个处理器处理。随着半导体技术发展,处理器上核的数量在不断增加,与此同时就带来问题:网卡上收到的报文由哪个核来处理呢?怎样支持高速网卡上的报文处理?
随着网络IO带宽的不断提升,当端口速率从10Mbit/s/100Mbit/s进入1Gbit/s/10Gbit/s,单个处理器核不足以满足高速网卡快速处理的需求,2007年在Intel的82575、82598网卡上引入多队列技术,可以将各个队列通过绑定到不同的核上来满足高速流量的需求。常见的多队列网卡有Intel的82580,82599和XL710等,随着网卡的升级换代,可支持的队列数目也在不断增加。除此以外,多队列技术也可以用来进行流的分类处理(见8.2节),以及解决网络IO的服务质量(QoS),针对不同优先级的数据流进行限速和调度。
网卡多队列技术是一个硬件手段,需要结合软件将它很好地利用起来从而达到设计的需求。利用该技术,可以做到分而治之,比如每个应用一个队列,应用就可以根据自己的需求来对数据包进行控制。比如视频数据强调实时性,而对数据的准确性要求不高,这样我们可以为其队列设置更高的发送优先级,或者说使用更高优先级的队列,为了达到较好的实时性,我们可以减小队列对应的带宽。而对那些要求准确性但是不要求实时的数据(比如电子邮件的数据包队列),我们可以使用较低的优先级和更大的带宽。当然这个前提也是在网卡支持基于队列的调度的基础上。但是如果是不支持多队列的网卡,所有的报文都进入同一个队列,那如何保证不同应用对数据包实时性和准确性的要求呢?那就需要软件支持复杂的调度算法来统一管理它们,这不但给处理器带来了很大的额外开销,同时也很难满足不同应用的需求。
94.Linux内核对多队列的支持
数据包需要在kernel内部完成数据包的网络层转发,Linux NAPI和Qdisc技术已是被广泛应用的技术。
(1)多队列对应的结构
众所周知,Linux的网卡由结构体net_device表示,一个该结构体可对应多个可以调度的数据包发送队列,数据包的实体在内核中以结构体sk_buff(skb)表示。
(2)接收端
网卡驱动程序为每个接收队列设定相应的中断号,通过中断的均衡处理,或者设置中断的亲和性(SMP IRQ Aff inity),从而实现队列绑定到不同的核。而对网卡而言,下面的流分类小节将介绍如何将流量导入到不同的队列中。
(3)发送端
Linux提供了较为灵活的队列选择机制。dev_pick_tx用于选取发送队列,它可以是driver定制的策略,也可以根据队列优先级选取,按照hash来做均衡。也就是利用XPS(Transmit Packet Steering,内核2.6.38后引入)机制,智能地选择多队列设备的队列来发送数据包。为了达到这个目标,从CPU到硬件队列的映射需要被记录。这个映射的目标是专门地分配队列到一个CPU列表,这些CPU列表中的某个CPU来完成队列中的数据传输。这有两点优势。第一点,设备队列上的锁竞争会被减少,因为只有很少的CPU对相同的队列进行竞争。(如果每个CPU只有自己的传输队列,锁的竞争就完全没有了。)第二点,传输时的缓存不命中(cache miss)的概率相应减少。下面的代码简单说明了在发送时队列的选取是考虑在其中的。
int dev_queue_xmit(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
txq = dev_pick_tx(dev, skb); //选出一个队列。
spin_lock_prefetch(&txq->lock);
dev_put(dev);
}
struct netdev_queue *netdev_pick_tx(struct net_device *dev,
struct sk_buff *skb)
{
int queue_index = 0;
if (dev->real_num_tx_queues ! = 1) {
const struct net_device_ops *ops = dev->netdev_ops;
if (ops->ndo_select_queue)
queue_index = ops->ndo_select_queue(dev, skb);
// 按照driver提供的策略来选择一个队列的索引
else
queue_index = __netdev_pick_tx(dev, skb);
queue_index = dev_cap_txqueue(dev, queue_index);
}
skb_set_queue_mapping(skb, queue_index);
return netdev_get_tx_queue(dev, queue_index);
}
(4)收发队列一般会被绑在同一个中断上。
如果从收队列1收上来的包从发队列1发出去,cache命中率高,效率也会高。
总的来说,多队列网卡已经是当前高速率网卡的主流。Linux也已经提供或扩展了一系列丰富接口和功能来支持和利用多队列网卡。图8-2描述了CPU与缓存的关系,CPU上的单个核都有私有的1级和2级缓存,3级缓存由多核共享,有效利用数据在缓存能提供性能,软件应减少数据在不同核的cache中搬移。
对于单队列的网卡设备,有时也会需要负载分摊到多个执行单元上执行,在没有多队列支持的情况下,就需要软件来均衡流量,我们来看一看Linux内核是如何处理的(见图8-3):
在接收侧,RPS(Receive Packet Steering)在接收端提供了这样的机制。RPS主要是把软中断的负载均衡到CPU的各个core上,网卡驱动对每个流生成一个hash标识,这个hash值可以通过四元组(源IP地址SIP,源四层端口SPORT,目的IP地址DIP,目的四层端口DPORT)来计算,然后由中断处理的地方根据这个hash标识分配到相应的core上去,这样就可以比较充分地发挥多核的能力了。通俗点来说,就是在软件层面模拟实现硬件的多队列网卡功能。
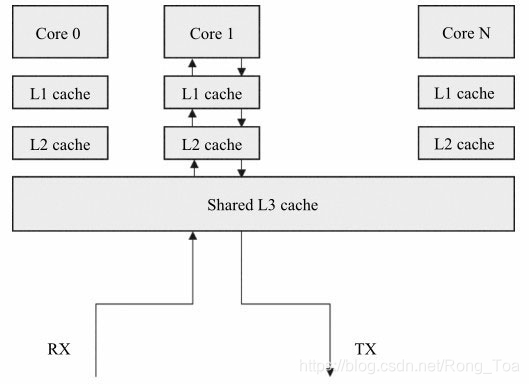
图8-2 CPU缓存
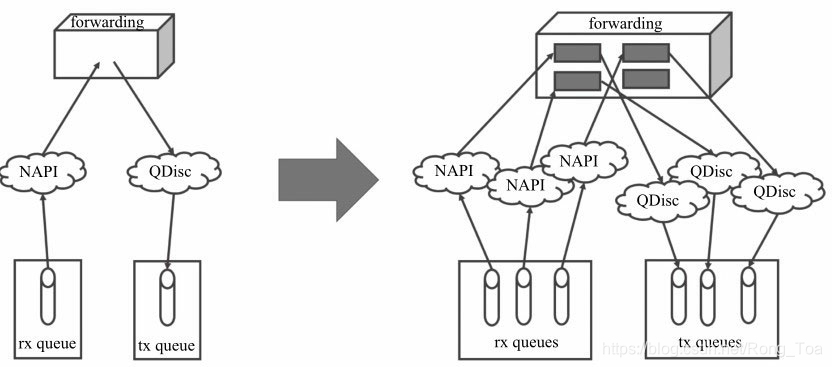
图8-3 Linux内核与多队列处理
在发送侧,无论来自哪个CPU的数据包只能往这唯一的队列上发送。
95.DPDK与多队列
在某个核上运行的程序从指定的队列上接收,往指定的队列上发送,可以达到很高的cache命中率,效率也就会高。
除了方便地做到对指定队列进行收发包操作外,DPDK的队列管理机制还可以避免多核处理器中的多个收发进程采用自旋锁产生的不必要等待。
96.以run to completion模型为例,可以从核、内存与网卡队列之间的关系来理解DPDK是如何利用网卡多队列技术带来性能的提升。
- ❑将网卡的某个接收队列分配给某个核,从该队列中收到的所有报文都应当在该指定的核上处理结束。
- ❑从核对应的本地存储中分配内存池,接收报文和对应的报文描述符都位于该内存池。
- ❑为每个核分配一个单独的发送队列,发送报文和对应的报文描述符都位于该核和发送队列对应的本地内存池中。
97.Pool Select是与虚拟化策略相关的(比如VMDQ);从Queue Select来看,在接收方向常用的有微软提出的RSS与英特尔提出的Flow Director技术,前者是根据哈希值希望均匀地将包分发到多个队列中。后者是基于查找的精确匹配,将包分发到指定的队列中。此外,网卡还可以根据优先级分配队列提供对QoS的支持。不论是哪一种,网卡都需要对包头进行解析。
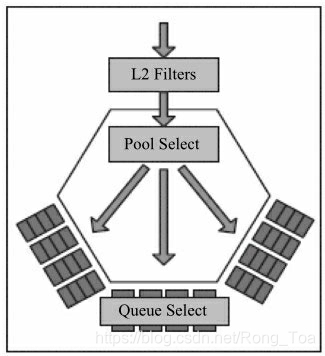
图8-4 多队列选择顺序
98.流分类
本章要讲述的流分类,指的是网卡依据数据包的特性将其分类的技术。分类的信息可以以不同的方式呈现给数据包的处理者,比如将分类信息记录于描述符中,将数据包丢弃或者将流导入某个或者某些队列中。
8.2.1 包的类型
高级的网卡设备可以分析出包的类型,包的类型会携带在接收描述符中,应用程序可以根据描述符快速地确定包是哪种类型的包,避免了大量的解析包的软件开销。以Intel® XL710为例,它可以分析出很多包的类型,比如传统的IP、TCP、UDP甚至VXLAN、NVGRE等tunnel报文,该信息可以体现在数据包的接收描述符中。对DPDK而言,Mbuf结构中含有相应的字段来表示网卡分析出的包的类型,从下面的代码可见Packet_type由二层、三层、四层及tunnel的信息来组成,应用程序可以很方便地定位到它需要处理的报文头部或是内容。
struct rte_mbuf {
……
union {
uint32_t packet_type; /**< L2/L3/L4 and tunnel information. */
struct {
uint32_t l2_type:4; /**< (Outer) L2 type. */
uint32_t l3_type:4; /**< (Outer) L3 type. */
uint32_t l4_type:4; /**< (Outer) L4 type. */
uint32_t tun_type:4; /**< Tunnel type. */
uint32_t inner_l2_type:4; /**< Inner L2 type. */
uint32_t inner_l3_type:4; /**< Inner L3 type. */
uint32_t inner_l4_type:4; /**< Inner L4 type. */
};
};
……
};
网卡设备同时可以根据包的类型确定其关键字,从而根据关键字确定其收包队列。上面章节提及的RSS及下面提到的Flow Director技术都是依据包的类型匹配相应的关键字,从而决定其DMA的收包队列。
需要注意的是,不是所有网卡都支持这项功能;还有,就是支持功能的复杂度也有差异。
99.RSS
《DPDK笔记 RSS(receive side scaling)网卡分流机制》
《网卡多队列:RPS、RFS、RSS、Flow Director(DPDK支持)》
负载均衡是多队列网卡最常见的应用,其含义就是将负载分摊到多个执行单元上执行。对应Packet IO而言,就是将数据包收发处理分摊到多个核上。
8.1节提到过网卡的多队列技术,Linux内核和DPDK如何使用多队列,以及内核使用软件的方式达到负载均衡。这里要介绍一种网卡上用于将流量分散到不同的队列中的技术:RSS (Receive-Side Scaling,接收方扩展),它是和硬件相关联的,必须要有网卡的硬件进行支持,RSS把数据包分配到不同的队列中,其中哈希值的计算公式在硬件中完成的,也可以定制修改。
然后Linux内核通过亲和性的调整把不同的中断映射到不同的Core上(见8.1.2节中)。DPDK由于天然地支持多队列的网卡,可以很简便地将接收与发送队列指定给某一个应用。DPDK的轮询模式的驱动也提供了配置RSS的接口。下面就以XL710网卡为例,看看其对RSS的支持及DPDK提供的接口。
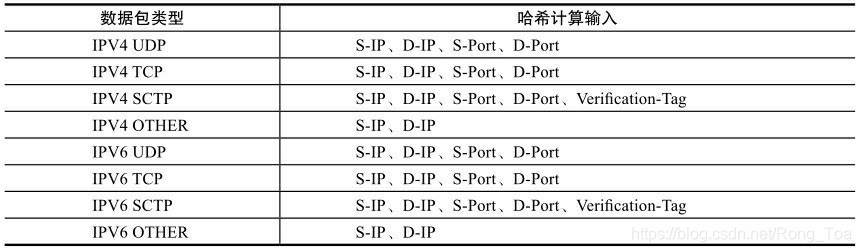
简单的说,RSS就是根据关键字通过哈希函数计算出哈希值,再由哈希值确定队列。关键字是如何确定的呢?网卡会根据不同的数据包类型选取出不同的关键字,见表8-1。比如IPV4 UDP包的关键字就由四元组组成(源IP地址、目的IP地址、源端口号、目的端口号), IPv4包的关键字则是源IP地址和目的IP地址。更为灵活的是,使用者甚至可以修改包类型对应的关键字以满足不同的需求。
表8-1 RSS关键字
由哈希值得到分配的队列索引,是由硬件中一个哈希值与队列对应的表来决定的。图8-5很好地描述了这个关系。
从这个过程我们可以看出,RSS是否能将数据包均匀地散列在多个队列中,取决于真实环境中的数据包构成和哈希函数的选取,哈希函数一般选取微软托普利兹算法(Microsoft Toeplitz Based Hash)。Intel®XL710支持多种哈希函数,可以选用对称哈希(Symmetric Hash),该算法可以保证Hash(src, dst)=Hash(dst, src)。在某些网络处理的设备中,使用对称哈希可以提高性能,比如一个电信转发设备,对一个连接的双向流有着相似的处理,自然就希望有着对称信息的数据包都能进入同一个核上处理,比较典型的有防火墙、服务质量保证等应用。如同一个流在不同的核上处理,涉及不同核之间的数据同步,这些会引入额外的开销。
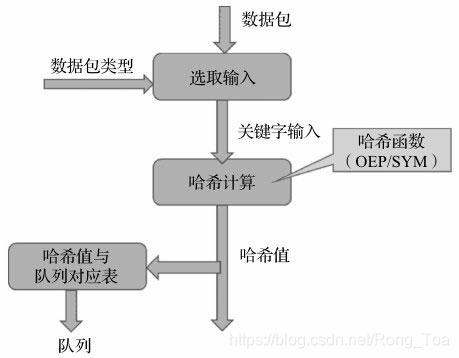
图8-5 流分类的哈希运算与队列选择
网卡可以支持多种哈希函数,具体看网卡功能与数据手册,看是否可以定制修改。
100.Flow Director
Flow Director技术是Intel公司提出的根据包的字段精确匹配,将其分配到某个特定队列的技术。
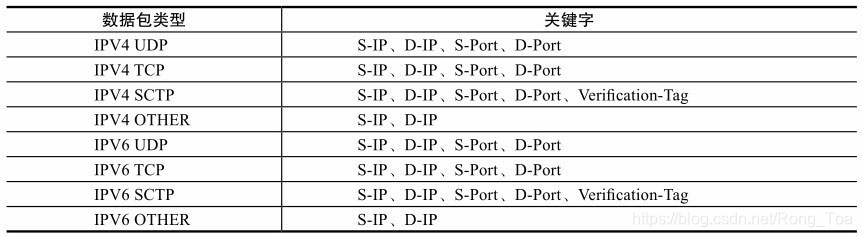
从图8-6可以了解到Flow Director是如何工作的:网卡上存储了一个Flow Director的表,表的大小受硬件资源限制,它记录了需要匹配字段的关键字及匹配后的动作;驱动负责操作这张表,包括初始化、增加表项、删除表项;网卡从线上收到数据包后根据关键字查Flow Director的这张表,匹配后按照表项中的动作处理,可以是分配队列、丢弃等。其中关键字的选取同8.2.1节中所述,也与包的类型相关,表8-2给出了Intel网卡中它们的对应关系。更为灵活的是,使用者也可以为不同包类型指定关键字以满足不同的需求,比如针对IPV4 UDP类型的包只匹配目的端口,忽略其他字段。
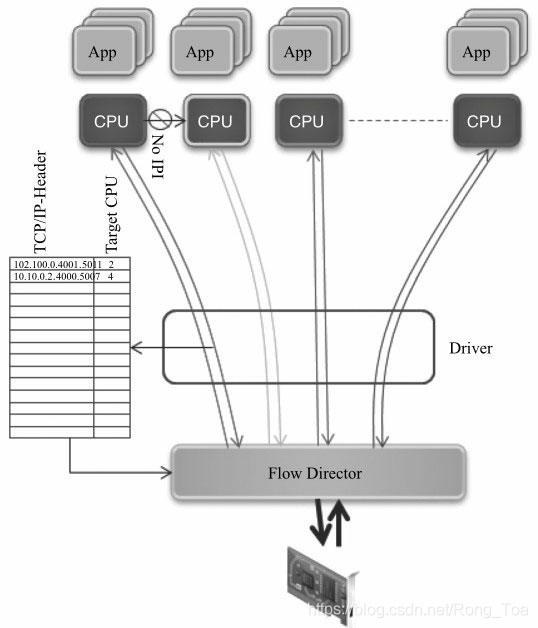
图8-6 Flow Director与队列选择
表8-2 Flow Director关键字
相比RSS的负载分担功能,它更加强调特定性。
比如,用户可以为某几个特定的TCP对话(S-IP + D-IP + S-Port + D-Port)预留某个队列,那么处理这些TCP对话的应用就可以只关心这个特定的队列,从而省去了CPU过滤数据包的开销,并且可以提高cache的命中率。
101.服务质量
多队列应用于服务质量(QoS)流量类别:把发送队列分配给不同的流量类别,可以让网卡在发送侧做调度;把收包队列分配给不同的流量类别,可以做到基于流的限速。根据流中优先级或业务类型字段,可以将流不同的业务类型有着不同的调度优先级及为其分配相应的带宽,一般网卡依照VLAN标签的UP(User Priority,用户优先级)字段。网卡依据UP字段,将流划分到某个业务类型(TC, Traff ic Class),网卡设备根据TC对业务做相应的处理,比如确定相对应的队列,根据优先级调度等。
以Intel®82599网卡为例,其使用DCB模型在网卡上实现QoS的功能。DCB (Data Center Bridge)是包含了差分服务的一组功能,在IEEE 802.1Qaz中有详细的定义,本节的描述主要集中在UP、TC及队列之间的关系。
1. 发包方向
下面的图8-7和图8-8分别给出了在DCB disable和DCB enable状态下的描述符、报文及发送队列之间的关系。
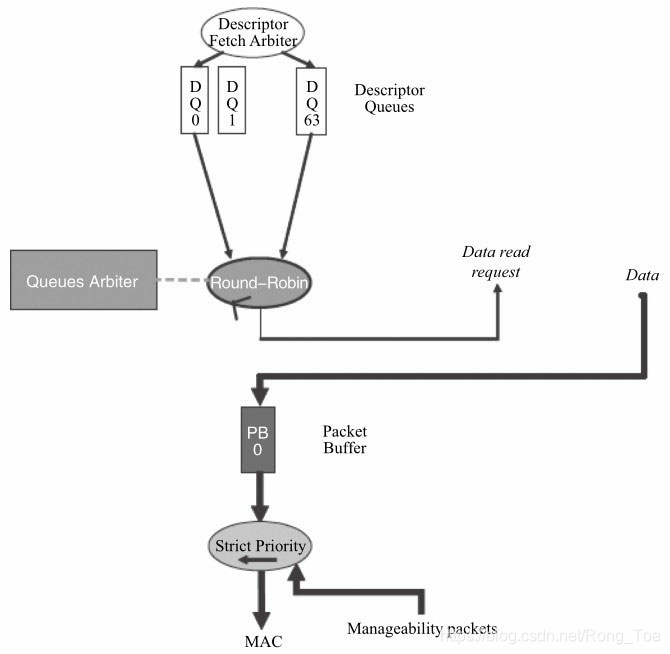
图8-7 未使能QoS的多队列调度
从图8-7可以看出,在没有使能QoS功能的情况下,对描述符而言,网卡是按照轮询的方式来调度;对数据包而言,网卡从buffer 0中获取数据包。
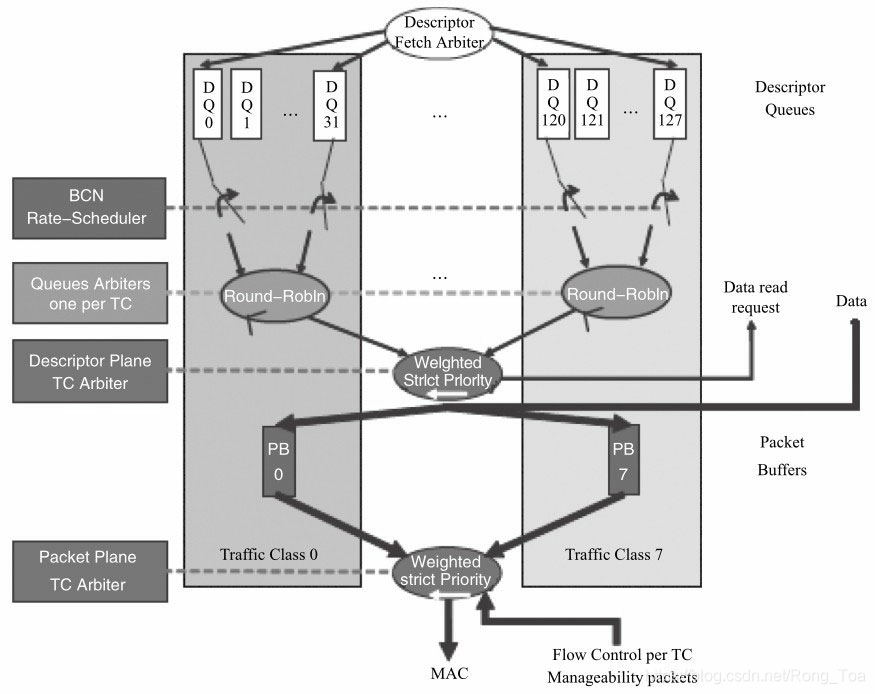
图8-8 使能QoS的多队列调度
从图8-8可以看出,在使能QoS功能的情况下,先根据UP来决策其属于哪个TC。TC内部的不同队列之间,网卡通过轮询(Round Robin)的方式获取其描述符。不同的TC之间则是依据加权严格优先级(Weighted Strict Priority)来调度,同时不同的TC有不同的数据包buffer。对描述符而言,网卡是依据加权严格优先级调度;对数据包而言,网卡从对应的buffer中获取数据包。加权严格优先级是常用的调度算法,其基于优先级来调度,优先级高的描述符或者数据包优先被获取,同时会考虑到权重,权重与为TC分配的带宽有关。当然,不同的网卡所采用的调度方法可能不尽相同,具体可参考各网卡的操作手册,这里就不再累述。
2. 收包方向
在使能QoS的场景下,与发包方向类似,先根据UP来决策其属于哪个TC。一个TC会对应一组队列,在这个TC内再由RSS或其他分类规则将其分配给不同的队列。TC之间的调度同样采用加权严格优先级的调度算法。当然,不同的网卡所采用的调度方法可能不尽相同。
102.虚拟化流分类方式
前面的章节介绍了RSS、Flow Director、QoS几种按照不同的规则分配或指定队列的方式。另外,较常用的还有在虚拟化场景下多多队列方式。第10章虚拟化章节会讲到网卡虚拟化的多种方式。不论哪种方式,都会有一组队列与虚拟化的实体(SRIOV VF/VMDQ POOL)相对应。类似前面的8.2.4节中的不同TC会对应一组队列,在虚拟化场景下,也有一组队列与虚拟设备相对应,如图8-9所示:

图8-9 虚拟化的多队列调度
103.流过滤
流的合法性验证的主要任务是决定哪些数据包是合法的、可被接收的。合法性检查主要包括对外部来的流和内部流的验证。
来自外部的数据包哪些是本地的、可以被接收的,哪些是不可以被接收的?可以被接收的数据包会被网卡送到主机或者网卡内置的管理控制器,其过滤主要集中在以太网的二层功能,包括VLAN及MAC过滤。在8.1.4节中包的接收过程中第二步按照地址过滤数据包(图8-4中的L2 Filters),从这个流程中可以看出它是位于指定队列之前的,过滤无效的非法的数据包。从图8-10中可以看出流的过滤可以分为以下几步:
- 1)MAC地址的过滤(L2 Filter)。
- 2)VLAN标签的过滤。
- 3)管理数据包的过滤。
不同的网卡可能在组织上有所差异,不过总的来说,就是决定数据包是进入主存、管理控制器或者丢弃的过程。
Intel网卡大多支持SRIOV和VMDQ这两类虚拟化的多队列分配方式。网卡内部会有内部交换逻辑处理,得知哪些是合法的报文,并同时可以做到虚拟化实体(SRIOV VF/VMDQ POOL)之间的数据包交换。如图8-11所示,图中Dst MAC/VLAN Filtering就用来检查PF及VF对应的MAC地址及VLAN是真正合法的。与之相对的Src MAC/VALN anti spoof ing的用途则是检查来自PF或者VF的数据包其源地址是否是其所属实体的地址,从而防止欺骗的发生。
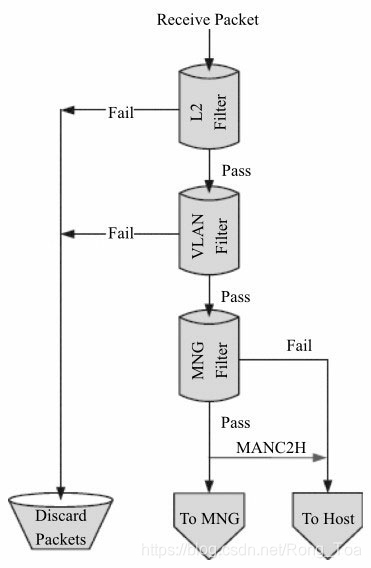
图8-10 报文过滤流程
除此以外,不同的网卡由于设计上的不一样,为了满足流分类的需求,也提供了很多流分类规则技术的应用,比如:
- 1)N tuple f ilter:根据N元组指定队列。
- 2)EtherType Filter:根据以太网报文的EtherType指定队列。
- 3)Cloud Filter:针对云应用中的VXLAN等隧道报文指定队列等。
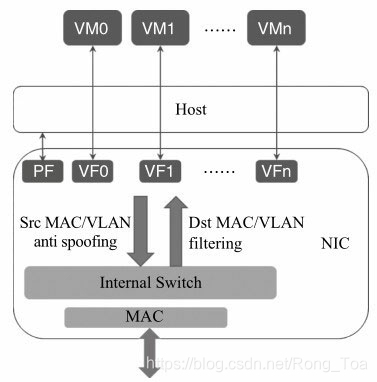
图8-11 SR-IOV的报文过滤
流分类技术的使用
104.流分类技术的使用
当下流行的多队列网卡往往支持丰富的流分类技术,我们可以很好地利用这些特定的分类机制,跟软件更好结合以满足多种多样的需求。
下面举两个DPDK与多队列网卡流分类功能结合的应用。
105.DPDK结合网卡Flow Director功能
一个设备需要一定的转发功能来处理数据平面的报文,同时需要处理一定量的控制报文。对于转发功能而言,要求较高的吞吐量,需要多个core来支持;对于控制报文的处理,其报文量并不大,但需要保证其可靠性,并且其处理逻辑也不同于转发逻辑。那么,我们就可以使用RSS来负载均衡其转发报文到多个核上,使用Flow Director将控制报文分配到指定的队列上,使用单独的核来处理。(见图8-12)。对这个实例而言,其好处显而易见:
- 1)这样可以帮助用户在设计时做到分而治之。
- 2)节省了软件过滤数据报文的开销。
- 3)避免了应用在不同核处理之间的切换。
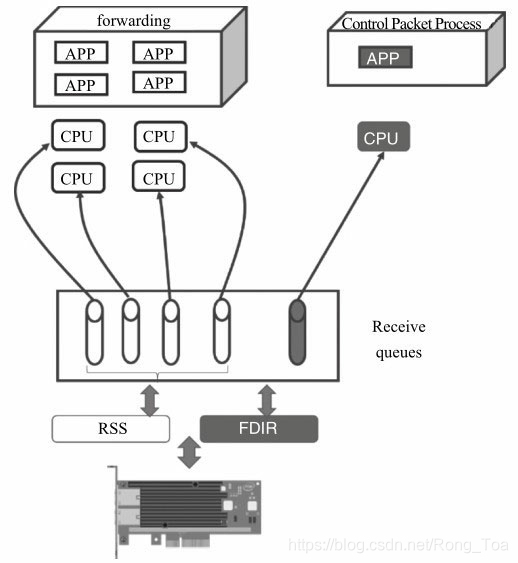
图8-12 DPDK结合Flow Director的应用
假设使用DPDK2.1,在一个Intel网卡82599的物理网口上一共使用4个接收队列,其中队列0-2用于普通的数据包转发,如图8-12中白色部分所示;队列3用于处理特定的UDP报文(Source IP=2.2.2.3, Destination IP=2.2.2.5, Source Port = Destination Port=1024),如图8-12中灰色部分所示。有三个核可以用于普通的数据包转发,一个核用于特定的UDP报文处理,那么如何利用DPDK API配置网卡呢?再回顾8.1.3中介绍的l3fwd的例子,为了避免使用锁的机制,每个核使用一个单独的发送队列,那么该例中,我们又该如何配置发送队列呢?读者可以按照以下几步操作:
(1)初始化网卡配置
RSS及Flow Director都是靠网卡上的资源来达到分类的目的,所以在初始化配置网卡时,我们需要传递相应的配置信息去使能网卡的RSS及Flow Director功能。
static struct rte_eth_conf port_conf = {
.rxmode = {
.mq_mode = ETH_MQ_RX_RSS,
},
.rx_adv_conf = {
.rss_conf = {
.rss_key = NULL,
.rss_hf = ETH_RSS_IP — ETH_RSS_UDP
ETH_RSS_TCP — ETH_RSS_SCTP,
},
}, //为设备使能RSS。
fdir_conf = {;
.mode = RTE_FDIR_MODE_PERFECT,
.pballoc = RTE_FDIR_PBALLOC_64K,
.status = RTE_FDIR_REPORT_STATUS,
.mask = {
.VLAN_tci_mask = 0x0,
.ipv4_mask = {
.src_ip = 0xFFFFFFFF,
.dst_ip = 0xFFFFFFFF,
},
.ipv6_mask = {
.src_ip = {0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF},
.dst_ip = {0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF, 0xFFFFFFFF},
},
.src_port_mask = 0xFFFF,
.dst_port_mask = 0xFFFF,
.mac_addr_byte_mask = 0xFF,
.tunnel_type_mask = 1,
.tunnel_id_mask = 0xFFFFFFFF,
},
.drop_queue = 127,
}, //为设备使能Flow Director。
};
rte_eth_dev_configure(port, rxRings, txRings, &port_conf);
// 配置设备,在该例中rxRings、txRings的大小应为4。
(2)配置收发队列
mbuf_pool = rte_pktmbuf_pool_create(); //为数据包收发预留主存空间
for (q = 0; q < rxRings; q ++) {
retval = rte_eth_rx_queue_setup(port, q, rxRingSize,
rte_eth_dev_socket_id(port),
NULL,
mbuf_pool);
if (retval < 0)
return retval;
}
for (q = 0; q < txRings; q ++) {
retval = rte_eth_tx_queue_setup(port, q, txRingSize,
rte_eth_dev_socket_id(port),
NULL);
if (retval < 0)
return retval;
}
// 配置收发队列,在该例中rxRings、txRings的大小应为4. (3)启动设备
rte_eth_dev_start(port);(4)增加Flow Director的分类规则
struct rte_eth_fdir_filter arg =
{
.soft_id = 1,
.input = {
.flow_type = RTE_ETH_FLOW_NONFRAG_IPV4_UDP,
.flow = {
.udp4_flow = {
.ip = {.src_ip = 0x03020202, .dst_ip = 0x05020202, }
.src_port = rte_cpu_to_be_16(1024),
.dst_port = rte_cpu_to_be_16(1024),
}
}
}
.action = {
.rx_queue = 3,
.behavior= RTE_ETH_FDIR_ACCEPT,
.report_status = RTE_ETH_FDIR_REPORT_ID,
}
}
rte_eth_dev_filter_ctrl(port, RTE_ETH_FILTER_FDIR, RTE_ETH_FILTER_ADD, &arg);
(5)重新配置RSS,修改哈希值与队列的对应表。
由于RSS的配置是根据接收队列的数目来均匀分配,我们只希望队列3接收特别的UDP数据流,所以尽管上一步中配置Flow Director规则已经指定UDP数据包导入到队列3中,但是由于RSS均衡的作用,非指定UDP的数据包会在0,1,2,3四个队列均匀分配,数据同样可能达到队列3,如果希望队列3上只收到指定的UDP数据流,那就需要修改RSS配置,修改哈希值与队列的对应表,从该表中将队列3移除。
// 配置哈希值与队列的对应表,82599网卡该表的大小为128。
struct rte_eth_rss_reta_entry64 reta_conf[2];
int i, j = 0;
for (idx = 0; idx < 2; idx++) {
reta_conf[idx].mask = ~0ULL;
for (i = 0; i < RTE_RETA_GROUP_SIZE; i++, j++) {
if (j == 3)
j = 0;
reta_conf[idx].reta[i] = j;
}
}
rte_eth_dev_rss_reta_query(port, reta_conf, 128); (6)接着,各应用线程就可以从各自分配的队列中接收和发送报文了。
106.DPDK结合网卡虚拟化及Cloud Filter功能
针对Intel®XL710网卡,PF使用i40e Linux Kernel驱动,VF使用DPDK i40e PMD驱动。使用Linux的Ethtool工具,可以完成配置操作cloud f ilter,将大量的数据包直接分配到VF的队列中,交由运行在VF上的虚机应用来直接处理。如图8-13所示,使用这样的方法可以将一个网卡上的队列分配给DPDK和i40e Linux Kernel同时处理,很好地结合二者的优势。
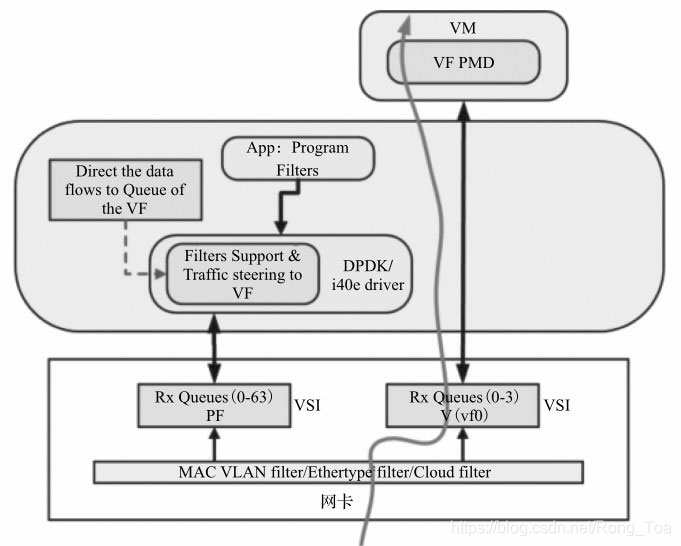
图8-13 DPDK结合虚拟化和cloud f ilter的应用
-
1)Kernel对协议报文的处理完整性。
-
2)DPDK的高性能吞吐,适合运用基于VF的网络吞吐密集型应用。
这样的使用方法还可以便于云服务提供商提供简单高效的分发数据包的方式。比如在网络数据与存储数据之间的切分。
假设使用DPDK2.1及i40e-1.3.46的Linux kernel驱动,在一个Intel®XL710网卡的物理网口上分配一个VF,该VF在虚拟机中由DPDK使用,那么如何配置网卡呢?读者可以在Linux系统上按照以下几步操作进行尝试:
- 1)在启动系统前,在BIOS中使能Intel®VT,并且在内核参数中加上Intel_iommu=on。
- 2)加载XL710对应的Linux内核驱动i40e.ko。
下载i40e-1.3.46驱动的源代码:
CFLAGS_EXTRA="-DI40E_ADD_CLOUD_FILTER_OFFLOAD"
make
rmmod i40e
insmod i40e.ko
3)生成VF。
echo 1 > /sys/bus/pci/devices/0000:02:00.0/sriov_numvfs
modprobe pci-stub
echo "8086154c" > /sys/bus/pci/drivers/pci-stub/new_id
echo 0000:02:02.0 > /sys/bus/pci/devices/0000:2:02.0/driver/unbind
echo 0000:02:02.0 > /sys/bus/pci/drivers/pci-stub/bind
4)启动虚拟机。
qemu-system-x86_64 -name vm0 -enable-kvm -cpu host -m 2048 -smp 4 -drive
file=dpdk-vm0.img -vnc :4-device pci-assign, host=02:02.0
5)在主机上通过ethtool将指定的流导入VF中。
ethtool -N ethx flow-type ip4 dst-ip 2.2.2.2 user-def 0xffffffff00000000 action 2 loc 1
6)在虚拟机中运行DPDK,可以看到目的地址为2.2.2.2的数据报文将在VF的队列2上接收到。
8.4 可重构匹配表
可重构匹配表(Reconf igurable Match Table, RMT)是软件自定义网络(Software Def ined Networking, SDN)中提出的用于配置转发平面的通用配置模型,图8-14给出了RMT模型中多级“Match+Action”的示意图。如果从“Match+Action”的角度来看,网卡的流分类也可以如斯抽象,不同的流分类技术,其区别在于匹配的内容,或者下一步的行为。表8-3中按照“Match+Action”的特性列出了上面讲述的多个分类技术。详见[Ref8-1]。
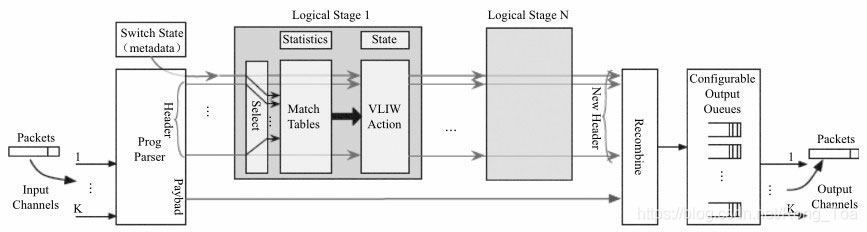
图8-14 RMT模型中多级“Match + Action”的示意图
表8-3 流分类技术对比

107.小结
当前行业高速网卡芯片提供商数量已经很少,网卡之间的功能差异不大,但细节可能不同,使用具体功能之前,需要参见网卡手册。作为相对成熟的技术,网卡功能大同小异,负载均衡与流分类是网络最基本的功能,利用好网卡硬件特性,可以提高系统性能。充分理解网卡特性,利用好网卡,需要一定的技术积累。
总体上,高速网卡智能化处理发展是个趋势。数据中心期望大量部署基于网络虚拟化的应用,需要对进出服务器系统的数据报文实施安全过滤、差异化服务的策略。在实现复杂网络功能又不占用过多运算资源,智能化网卡被期待来实现这些功能服务。
系列文章
《《深入浅出DPDK》读书笔记(三):NUMA - Non Uniform Memory Architecture 非统一内存架构》
《《深入浅出DPDK》读书笔记(四):并行计算-SIMD是Single-Instruction Multiple-Data(单指令多数据)》
《《深入浅出DPDK》读书笔记(六):报文转发(run to completion、pipeline、精确匹配算法、最长前缀匹配LPM)》
《《深入浅出DPDK》读书笔记(七):PCIe与包处理I/O》
《《深入浅出DPDK》读书笔记(八):网卡性能优化(异步中断模式、轮询模式、混和中断轮询模式)》
《《深入浅出DPDK》读书笔记(九):流分类与多队列》
相关阅读
《DPDK PMD( Poll Mode Driver)轮询模式驱动程序》

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









