







《NMI watchdog: BUG: soft lockup》
《kernel:NMI watchdog: BUG: soft lockup - CPU#6 stuck for 28s! CentOS7linux中内核被锁死》
《服务器安装系统——出错BUG: soft lockup...》
《内核如何检测SOFT LOCKUP与HARD LOCKUP?》
《Softlockup detector and hardlockup detector (aka nmi_watchdog)》
《NMI watchdog: BUG: soft lockup》
目录
IDC的一个交换机出了点问题,引发网络不通,同事反馈console上出现了 NMI watchdog: BUG: soft lockup - CPU#1 stuck for 31s 这样的输出,我查了点资料,这里做点笔记.
读核笔记 有对NMI watchdog和lockup的更多介绍.
什么是lockup
lockup 就是某段内核代码占着CPU不放, lockup 严重时导致整个系统失去相应, lockup 有两个特点:
- 只有内核代码才能引起lockup,因为用户代码是可被抢占的,不可能形成lockup(只有一个例外:
SCHED_FIFO优先级为99的实时进程也是不可抢占的,SCHED_FIFO优先级为99的实时进程即使在用户态也可能使[watchdog/x]内核线程抢不到CPU而形成soft lock,参见《Real-Time进程会导致系统Lockup吗?》) - 内核代码必须处于禁止抢占状态,因为linux是抢占式内核,只有某些特定代码区才禁止抢占,只有这些区域才能形成lockup
lockup分为soft lockup和hard lockup,如果lockup时没屏蔽中断soft,否则hard.
- Soft lockup是指CPU被内核代码占据,以至于无法执行其它进程。检测soft lockup的原理是给每个CPU分配一个定时执行的内核线程[watchdog/x],如果该线程在设定的期限内没有得到执行的话就意味着发生了soft lockup,[watchdog/x]是SCHED_FIFO实时进程,优先级为最高的99,拥有优先运行的特权。
- Hard lockup比soft lockup更加严重,CPU不仅无法执行其它进程,而且不再响应中断。检测hard lockup的原理利用了PMU的NMI perf event,因为NMI中断是不可屏蔽的,在CPU不再响应中断的情况下仍然可以得到执行,它再去检查时钟中断的计数器hrtimer_interrupts是否在保持递增,如果停滞就意味着时钟中断未得到响应,也就是发生了hard lockup。
什么是NMI?非可屏蔽中断
NMI,即非可屏蔽中断。即使在内核代码中设置了屏蔽所有中断的时候,NMI也是不可以被屏蔽的。
中断分为可屏蔽中断和非可屏蔽中断。其中,可屏蔽中断包含时钟中断,外设中断(比如键盘中断,I/O设备中断,等等),当我们处理中断处理程序的时候,在中断处理程序top half时候,在不允许嵌套的情况下,需要关闭中断。
但NMI就不一样了,即便在关闭中断的情况下,他也能被响应。触发NMI的条件一般都是ECC error之类的硬件Error。但NMI也给我们提供了一种机制,在系统中断被误关闭的情况下,依然能通过中断处理程序来执行一些紧急操作,比如kernel panic。
这里涉及到了3个东西:kernel线程,时钟中断,NMI中断(不可屏蔽中断)。
这3个东西具有不一样的优先级,依次是kernel线程 < 时钟中断 < NMI中断。其中,kernel 线程是可以被调度的,同时也是可以被中断随时打断的。
接下来,我们分别看什么是soft lockup,什么是hard lockup.
使用NMI Watchdog检测lockup
Linux kernel设计了一个检测lockup的机制,称为NMI Watchdog,是利用NMI中断实现的,用NMI是因为lockup有可能发生在中断被屏蔽的状态下,这时唯一能把CPU抢下来的方法就是通过NMI,因为NMI中断是不可屏蔽的。NMI Watchdog 中包含 soft lockup detector 和 hard lockup detector,2.6之后的内核的实现方法如下。
当发生hard lockup时,唯一能把cpu抢下来的唯一办法就是NMI,因为NMI是不可屏蔽中断. NMI Watchdog包含两部分:
- 高精度计时器,递增
hrtimer_interrupts,唤醒[watchodg/x]内核线程,更新一个时间戳. - NMI中断时,检查
hrtimer_interrupts是否递增,如果没有说明hard lockup,检查时间戳是否更新,如果没有说明soft lockup
NMI Watchdog 的触发机制包括两部分:
- 一个高精度计时器(hrtimer),对应的中断处理例程是kernel/watchdog.c: watchdog_timer_fn(),在该例程中:
- 要递增计数器hrtimer_interrupts,这个计数器供hard lockup detector用于判断CPU是否响应中断;
- 还要唤醒[watchdog/x]内核线程,该线程的任务是更新一个时间戳;
- soft lock detector检查时间戳,如果超过soft lockup threshold一直未更新,说明[watchdog/x]未得到运行机会,意味着CPU被霸占,也就是发生了soft lockup。
- 基于PMU的NMI perf event,当PMU的计数器溢出时会触发NMI中断,对应的中断处理例程是 kernel/watchdog.c: watchdog_overflow_callback(),hard lockup detector就在其中,它会检查上述hrtimer的中断次数(hrtimer_interrupts)是否在保持递增,如果停滞则表明hrtimer中断未得到响应,也就是发生了hard lockup。
hrtimer的周期是:softlockup_thresh/5。
注:
- 在2.6内核中:
softlockup_thresh的值等于内核参数kernel.watchdog_thresh,默认60秒; - 而到3.10内核中:
内核参数kernel.watchdog_thresh名称未变,但含义变成了hard lockup threshold,默认10秒;
soft lockup threshold则等于(2*kernel.watchdog_thresh),即默认20秒。
NMI perf event是基于PMU的,触发周期(hard lockup threshold)在2.6内核里是固定的60秒,不可手工调整;在3.10内核里可以手工调整,因为直接对应着内核参数kernel.watchdog_thresh,默认值10秒。
检测到 lockup 之后怎么办?可以自动panic,也可输出条信息就算完了,这是可以通过内核参数来定义的:
- kernel.softlockup_panic: 决定了检测到soft lockup时是否自动panic,缺省值是0;
- kernel.nmi_watchdog: 定义是否开启nmi watchdog、以及hard lockup是否导致panic,该内核参数的格式是”=[panic,][nopanic,][num]”.
(注:最新的kernel引入了新的内核参数kernel.hardlockup_panic,可以通过检查是否存在 /proc/sys/kernel/hardlockup_panic来判断你的内核是否支持。)
和lockup和watchdog有关的sysctl参数
kernel.nmi_watchdog = 1开启或关闭nmi watchdogkernel.softlockup_panic = 0softlockup 不触发panickernel.watchdog = 1同时开启或关闭soft lockup detector和nmi watchdogkernel.watchdog_thresh = 10hard lockup的阈值,soft lockup的阈值是2*watchdog_thresh
lockup 的解决
发生lockup通常是特定条件下触发了内核bug,表现为负载高(因为cpu hang住了).如果是偶然发生一次,可以忽略,如果频繁发生,则考虑两种方法:
- 看看是什么条件触发了内核bug,解决这个条件
- 向厂商/社区报告这个bug
在我碰到例子中,就是网络原因触发的,网络恢复后,问题自动消失了.
和lockup有关的信息
lockup时 dmsg 中相关的信息,留心几个关键点.
Modules linked in看看是不是新增内核模块引起的CPU: 1 PID: 5071 Comm: sshd Kdump: loaded Tainted类似这种,记录了内核态对应的进程,这里是pid为5071的sshd进程,但lockup和进程无关RIP: 0010:[<ffffffff91f904dc>] [<ffffffff91f904dc>] iowrite16+0x1c/0x40RIP记录lockup时执行的函数,这里是iowrite16Call Trace记录lockup的堆栈
寻找多个lockup之间的共同点,判断是什么引发了内核bug. 在我碰到例子中,RIP都是 iowrite16 ,堆栈都和网络有关.
SoftLockup
Soft lockup是指CPU被内核代码占据,以至于无法执行其它进程。检测soft lockup的原理是给每个CPU分配一个定时执行的内核线程[watchdog/x],如果该线程在设定的期限内没有得到执行的话就意味着发生了soft lockup,[watchdog/x]是SCHED_FIFO实时进程,优先级为最高的99,拥有优先运行的特权。
SoftLockup 示例代码
以下是一段Soft lockup的示例代码,通过一直占用某个CPU,而达到soft lockup的目的:
#include<linux/kernel.h>
#include<linux/module.h>
#include<linux/kthread.h>
struct task_struct *task0;
static spinlock_t spinlock;
int val;
int task(void *arg)
{
printk(KERN_INFO "%s:%d\n",__func__,__LINE__);
/* To generate panic uncomment following */
/* panic("softlockup: hung tasks"); */
while(!kthread_should_stop()) {
printk(KERN_INFO "%s:%d\n",__func__,__LINE__);
spin_lock(&spinlock);
/* busy loop in critical section */
while(1) {
printk(KERN_INFO "%s:%d\n",__func__,__LINE__);
}
spin_unlock(&spinlock);
}
return val;
}
static int softlockup_init(void)
{
printk(KERN_INFO "%s:%d\n",__func__,__LINE__);
val = 1;
spin_lock_init(&spinlock);
task0 = kthread_run(&task,(void *)val,"softlockup_thread");
set_cpus_allowed_ptr(task0, cpumask_of(0));
return 0;
}
static void softlockup_exit(void)
{
printk(KERN_INFO "%s:%d\n",__func__,__LINE__);
kthread_stop(task0);
}
module_init(softlockup_init);
module_exit(softlockup_exit);上述代码是从某个网站上找到的,它通过spinlock()实现关抢占,使得该CPU上的[watchdog/x]无法被调度。另外,通过set_cpus_allowed_ptr()将该线程绑定到特定的CPU上去。
Hardlockup
讲完了Softlockup,我们接着讲 Hardlockup。
Hard lockup比soft lockup更加严重,CPU不仅无法执行其它进程,而且不再响应中断。检测hard lockup的原理利用了PMU的NMI perf event,因为NMI中断是不可屏蔽的,在CPU不再响应中断的情况下仍然可以得到执行,它再去检查时钟中断的计数器hrtimer_interrupts是否在保持递增,如果停滞就意味着时钟中断未得到响应,也就是发生了hard lockup
Hardlockup 示例代码
下面代码示意了hardlockup如何产生的,其中重要一点就是关中断,这里,通过spin_lock_irqsave()
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/spinlock.h>
MODULE_LICENSE("GPL");
static int
hog_thread(void *data)
{
static DEFINE_SPINLOCK(lock);
unsigned long flags;
printk(KERN_INFO "Hogging a CPU now\n");
spin_lock_irqsave(&lock, flags);
while (1);
/* unreached */
return 0;
}
static int __init
hog_init(void)
{
kthread_run(&hog_thread, NULL, "hog");
return 0;
}
module_init(hog_init);在上述例子中,中断被关闭,普通中断无法被相应(包括时钟中断),线程无法被调度,因此,在这种情况下,不仅仅[watchdog/x]线程也无法工作,hrtimer也无法被相应。
lockup发生时的一段dmsg输出
[Mon Dec 30 18:39:04 2019] NMI watchdog: BUG: soft lockup - CPU#1 stuck for 31s! [sshd:5071]
[Mon Dec 30 18:39:04 2019] Modules linked in: ipmi_devintf ipmi_msghandler sunrpc dm_mirror dm_region_hash dm_log dm_mod ppdev iosf_mbi xfs crc32_
pclmul ghash_clmulni_intel libcrc32c aesni_intel lrw gf128mul joydev glue_helper ablk_helper cryptd pcspkr sg virtio_balloon parport_pc parport i2
c_piix4 ip_tables ext4 mbcache jbd2 sr_mod cdrom virtio_blk virtio_net ata_generic pata_acpi crct10dif_pclmul crct10dif_common crc32c_intel serio_
raw cirrus drm_kms_helper syscopyarea sysfillrect floppy sysimgblt fb_sys_fops ttm drm ata_piix libata virtio_pci virtio_ring virtio drm_panel_ori
entation_quirks
[Mon Dec 30 18:39:04 2019] CPU: 1 PID: 5071 Comm: sshd Kdump: loaded Tainted: G L ------------ 3.10.0-957.el7.x86_64 #1
[Mon Dec 30 18:39:04 2019] Hardware name: Red Hat KVM, BIOS 0.5.1 01/01/2011
[Mon Dec 30 18:39:04 2019] task: ffff8be9ffa94100 ti: ffff8be9ad548000 task.ti: ffff8be9ad548000
[Mon Dec 30 18:39:04 2019] RIP: 0010:[<ffffffff91f904dc>] [<ffffffff91f904dc>] iowrite16+0x1c/0x40
[Mon Dec 30 18:39:04 2019] RSP: 0018:ffff8be9ad54b950 EFLAGS: 00000202
[Mon Dec 30 18:39:04 2019] RAX: 0000000000000001 RBX: ffff8be9f6ab6000 RCX: ffff8be9f36026c0
[Mon Dec 30 18:39:04 2019] RDX: 000000000000c0b0 RSI: 000000000001c0b0 RDI: 0000000000000001
[Mon Dec 30 18:39:04 2019] RBP: ffff8be9ad54b958 R08: 0000000000000020 R09: 00000000000000c2
[Mon Dec 30 18:39:04 2019] R10: 0000000000000001 R11: 000000000000000c R12: ffff8be9f6ab6000
[Mon Dec 30 18:39:04 2019] R13: ffff8be9bfc01700 R14: ffff8be996a4d500 R15: 00000000f3ef44c9
[Mon Dec 30 18:39:04 2019] FS: 0000000000000000(0000) GS:ffff8be9ffd00000(0000) knlGS:0000000000000000
[Mon Dec 30 18:39:04 2019] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[Mon Dec 30 18:39:04 2019] CR2: 000055586c776c60 CR3: 0000000145e10000 CR4: 00000000003606e0
[Mon Dec 30 18:39:04 2019] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[Mon Dec 30 18:39:04 2019] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[Mon Dec 30 18:39:04 2019] Call Trace:
[Mon Dec 30 18:39:04 2019] [<ffffffffc02a8b76>] ? vp_notify+0x16/0x20 [virtio_pci]
[Mon Dec 30 18:39:04 2019] [<ffffffffc029c720>] virtqueue_kick+0x30/0x50 [virtio_ring]
[Mon Dec 30 18:39:04 2019] [<ffffffffc03f1584>] start_xmit+0x264/0x500 [virtio_net]
[Mon Dec 30 18:39:04 2019] [<ffffffff92238c66>] dev_hard_start_xmit+0x246/0x3b0
[Mon Dec 30 18:39:04 2019] [<ffffffff92265cea>] sch_direct_xmit+0x11a/0x250
[Mon Dec 30 18:39:04 2019] [<ffffffff9223bbe1>] __dev_queue_xmit+0x491/0x650
[Mon Dec 30 18:39:04 2019] [<ffffffff9223bdb0>] dev_queue_xmit+0x10/0x20
[Mon Dec 30 18:39:04 2019] [<ffffffff92288736>] ip_finish_output+0x556/0x7b0
[Mon Dec 30 18:39:04 2019] [<ffffffff92288c93>] ip_output+0x73/0xe0
[Mon Dec 30 18:39:04 2019] [<ffffffff92286817>] ip_local_out_sk+0x37/0x40
[Mon Dec 30 18:39:04 2019] [<ffffffff92286bb4>] ip_queue_xmit+0x144/0x3c0
[Mon Dec 30 18:39:04 2019] [<ffffffff922a0f64>] tcp_transmit_skb+0x4e4/0x9e0
[Mon Dec 30 18:39:04 2019] [<ffffffff922a15d2>] tcp_write_xmit+0x172/0xd00
[Mon Dec 30 18:39:04 2019] [<ffffffff922a23de>] __tcp_push_pending_frames+0x2e/0xc0
[Mon Dec 30 18:39:04 2019] [<ffffffff922a3ed2>] tcp_send_fin+0x62/0x190
[Mon Dec 30 18:39:04 2019] [<ffffffff92295110>] tcp_close+0x3a0/0x400
[Mon Dec 30 18:39:04 2019] [<ffffffff922be86d>] inet_release+0x7d/0x90
[Mon Dec 30 18:39:04 2019] [<ffffffff92218765>] sock_release+0x25/0x90
[Mon Dec 30 18:39:04 2019] [<ffffffff922187e2>] sock_close+0x12/0x20
[Mon Dec 30 18:39:04 2019] [<ffffffff91e433dc>] __fput+0xec/0x260
[Mon Dec 30 18:39:04 2019] [<ffffffff91e4363e>] ____fput+0xe/0x10
[Mon Dec 30 18:39:04 2019] [<ffffffff91cbe79b>] task_work_run+0xbb/0xe0
[Mon Dec 30 18:39:04 2019] [<ffffffff91c9dc61>] do_exit+0x2d1/0xa40
[Mon Dec 30 18:39:04 2019] [<ffffffff91c9e44f>] do_group_exit+0x3f/0xa0
[Mon Dec 30 18:39:04 2019] [<ffffffff91c9e4c4>] SyS_exit_group+0x14/0x20
[Mon Dec 30 18:39:04 2019] [<ffffffff92374ddb>] system_call_fastpath+0x22/0x27
[Mon Dec 30 18:39:04 2019] Code: ff ff 5d c3 0f 1f 00 40 88 3e c3 0f 1f 40 00 48 81 fe ff ff 03 00 48 89 f2 77 2c 48 81 fe 00 00 01 00 76 0b 0f b7 d6 89 f8 66 ef <c3> 0f 1f 00 55 48 c7 c6 51 40 6a 92 48 89 d7 48 89 e5 e8 5d fe
[Mon Dec 30 18:39:41 2019] INFO: rcu_sched detected stalls on CPUs/tasks: {} (detected by 1, t=70290 jiffies, g=151052658, c=151052657, q=3140)
[Mon Dec 30 18:39:41 2019] All QSes seen, last rcu_sched kthread activity 70290 (14862025930-14861955640), jiffies_till_next_fqs=3
[Mon Dec 30 18:39:41 2019] sshd R running task 0 5071 3124 0x0000000a
[Mon Dec 30 18:39:41 2019] Call Trace:
[Mon Dec 30 18:39:41 2019] <IRQ> [<ffffffff91cd5d88>] sched_show_task+0xa8/0x110
[Mon Dec 30 18:39:41 2019] [<ffffffff91d55fde>] rcu_check_callbacks+0x72e/0x730
[Mon Dec 30 18:39:41 2019] [<ffffffff91d0ad60>] ? tick_sched_do_timer+0x50/0x50
[Mon Dec 30 18:39:41 2019] [<ffffffff91cab136>] update_process_times+0x46/0x80
[Mon Dec 30 18:39:41 2019] [<ffffffff91d0aad0>] tick_sched_handle+0x30/0x70
[Mon Dec 30 18:39:41 2019] [<ffffffff91d0ad99>] tick_sched_timer+0x39/0x80
[Mon Dec 30 18:39:41 2019] [<ffffffff91cc5f93>] __hrtimer_run_queues+0xf3/0x270
[Mon Dec 30 18:39:41 2019] [<ffffffff91cc651f>] hrtimer_interrupt+0xaf/0x1d0
[Mon Dec 30 18:39:41 2019] [<ffffffff91c5a2cb>] local_apic_timer_interrupt+0x3b/0x60
[Mon Dec 30 18:39:41 2019] [<ffffffff923796c3>] smp_apic_timer_interrupt+0x43/0x60
[Mon Dec 30 18:39:41 2019] [<ffffffff92375df2>] apic_timer_interrupt+0x162/0x170
[Mon Dec 30 18:39:41 2019] [<ffffffff91f904dc>] ? iowrite16+0x1c/0x40
[Mon Dec 30 18:39:41 2019] [<ffffffffc02a8b76>] ? vp_notify+0x16/0x20 [virtio_pci]
[Mon Dec 30 18:39:41 2019] [<ffffffffc029c720>] virtqueue_kick+0x30/0x50 [virtio_ring]
[Mon Dec 30 18:39:41 2019] [<ffffffffc03f1584>] start_xmit+0x264/0x500 [virtio_net]
[Mon Dec 30 18:39:41 2019] [<ffffffff92238c66>] dev_hard_start_xmit+0x246/0x3b0
[Mon Dec 30 18:39:41 2019] [<ffffffff92265cea>] sch_direct_xmit+0x11a/0x250
[Mon Dec 30 18:39:41 2019] [<ffffffff92265eae>] __qdisc_run+0x8e/0x360
[Mon Dec 30 18:39:41 2019] [<ffffffff92237386>] net_tx_action+0x1d6/0x240
[Mon Dec 30 18:39:41 2019] [<ffffffff91ca0f05>] __do_softirq+0xf5/0x280
[Mon Dec 30 18:39:41 2019] [<ffffffff9237832c>] call_softirq+0x1c/0x30
[Mon Dec 30 18:39:41 2019] <EOI> [<ffffffff91c2e675>] do_softirq+0x65/0xa0
[Mon Dec 30 18:39:41 2019] [<ffffffff91ca035b>] __local_bh_enable_ip+0x9b/0xb0
[Mon Dec 30 18:39:41 2019] [<ffffffff91ca0387>] local_bh_enable+0x17/0x20
[Mon Dec 30 18:39:41 2019] [<ffffffff92288464>] ip_finish_output+0x284/0x7b0
[Mon Dec 30 18:39:41 2019] [<ffffffff92288c93>] ip_output+0x73/0xe0
[Mon Dec 30 18:39:41 2019] [<ffffffff92286817>] ip_local_out_sk+0x37/0x40
[Mon Dec 30 18:39:41 2019] [<ffffffff92286bb4>] ip_queue_xmit+0x144/0x3c0
[Mon Dec 30 18:39:41 2019] [<ffffffff922a0f64>] tcp_transmit_skb+0x4e4/0x9e0
[Mon Dec 30 18:39:41 2019] [<ffffffff922a15d2>] tcp_write_xmit+0x172/0xd00
[Mon Dec 30 18:39:41 2019] [<ffffffff922a23de>] __tcp_push_pending_frames+0x2e/0xc0
[Mon Dec 30 18:39:41 2019] [<ffffffff922a3ed2>] tcp_send_fin+0x62/0x190
[Mon Dec 30 18:39:41 2019] [<ffffffff92295110>] tcp_close+0x3a0/0x400
[Mon Dec 30 18:39:41 2019] [<ffffffff922be86d>] inet_release+0x7d/0x90
[Mon Dec 30 18:39:41 2019] [<ffffffff92218765>] sock_release+0x25/0x90
[Mon Dec 30 18:39:41 2019] [<ffffffff922187e2>] sock_close+0x12/0x20
[Mon Dec 30 18:39:41 2019] [<ffffffff91e433dc>] __fput+0xec/0x260
[Mon Dec 30 18:39:41 2019] [<ffffffff91e4363e>] ____fput+0xe/0x10
[Mon Dec 30 18:39:41 2019] [<ffffffff91cbe79b>] task_work_run+0xbb/0xe0
[Mon Dec 30 18:39:41 2019] [<ffffffff91c9dc61>] do_exit+0x2d1/0xa40
[Mon Dec 30 18:39:41 2019] [<ffffffff91c9e44f>] do_group_exit+0x3f/0xa0
[Mon Dec 30 18:39:41 2019] [<ffffffff91c9e4c4>] SyS_exit_group+0x14/0x20
[Mon Dec 30 18:39:41 2019] [<ffffffff92374ddb>] system_call_fastpath+0x22/0x27
CentOS7中内核被锁死原因
https://www.cnblogs.com/fusheng11711/p/10767190.html
网上找资料分析了一下原因,直接原因是:如果CPU太忙导致喂狗(watchdog)不及时,此时系统会打印CPU死锁信息:
kernel:BUG: soft lockup - CPU#0 stuck for 38s! [kworker/0:1:25758]
kernel:BUG: soft lockup - CPU#7 stuck for 36s! [java:16182]
......内核参数kernel.watchdog_thresh(/proc/sys/kernel/watchdog_thresh)系统默认值为10。如果超过2*10秒会打印信息,注意:调整值时参数不能大于60。
虽然调整该值可以延长喂狗等待时间,但是不能彻底解决问题,只能导致信息延迟打印。因此问题的解决,还是需要找到根本原因。
可以打开panic,将/proc/sys/kernel/panic的默认值0改为1,便于定位。
网上查找资料,发现引发CPU死锁的原因有很多种:
- * 服务器电源供电不足,导致CPU电压不稳导致CPU死锁:https://ubuntuforums.org/showthread.php?t=2205211
I bought a small (500W) new power supply made by what I feel is a reputable company and made the swap.
GREAT NEWS: After replacing the power supply, the crashes completely stopped!
I wanted to wait a while just to be sure, but it is now a few weeks since the new powersupply went in, and I haven't had a single crash since.
The power supply is not something that I would normally worry about, but in this case it totally fixed my problem.
Thanks to those who read my post, and especially to those who responded.- * vcpus超过物理cpu cores:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- * 虚机所在的宿主机的CPU太忙或磁盘IO太高
- * 虚机的的CPU太忙或磁盘IO太高:https://www.centos.org/forums/viewtopic.php?t=60087
- * BIOS KVM开启以后的相关bug,关闭KVM可解决,但关闭以后物理机不支持虚拟化:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- * VM网卡驱动存在bug,处理高水位流量时存在bug导致CPU死锁
- * BIOS开启了超频,导致超频时电压不稳,容易出现CPU死锁:https://ubuntuforums.org/showthread.php?t=2205211
- * Linux kernel存在bug:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- * KVM存在bug:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds
- * clocksource tsc unstable on CentOS and cloud Linux with Hyper-V Virtualisation:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds 通过设置clocksource=jiffies可解决
- * BIOS Intel C-State开启导致,关闭可解决:https://unix.stackexchange.com/questions/70377/bug-soft-lockup-cpu-stuck-for-x-seconds;https://support.citrix.com/article/CTX127395;http://blog.sina.com.cn/s/blog_906d892d0102vn26.html
- * BIOS spread spectrum(频展)开启导致: 当主板上的时钟震荡发生器工作时,脉冲的尖峰会产生emi(电磁干扰)。spread spectrum(频展)设定功能可以降低脉冲发生器所产生的电磁干扰,脉冲波的尖峰会衰减为较为平滑的曲线。 如果我们没有遇到电磁干扰问题,建议将此项设定为disabled,这栏可以优化系统的性能表现和稳定性; 否则应该将此项设定为enabled。 如果对cpu进行超频,必须将此项禁用。因为即使是微小的脉冲值漂移也会导致超频运行的cpu锁死。 再次强调:CPU超频时,SPREAD SPECTRUM必须关闭,否则容易出现锁死cpu的情况。
#追加到配置文件中
echo 30 > /proc/sys/kernel/watchdog_thresh #查看
# tail -1 /proc/sys/kernel/watchdog_thresh
30#临时生效
sysctl -w kernel.watchdog_thresh=30#内核软死锁(soft lockup)bug原因分析 Soft lockup名称解释:所谓,soft lockup就是说,这个bug没有让系统彻底死机,但是若干个进程(或者kernel thread)被锁死在了某个状态(一般在内核区域),很多情况下这个是由于内核锁的使用的问题。
vi /etc/sysctl.conf
kernel.watchdog_thresh=30
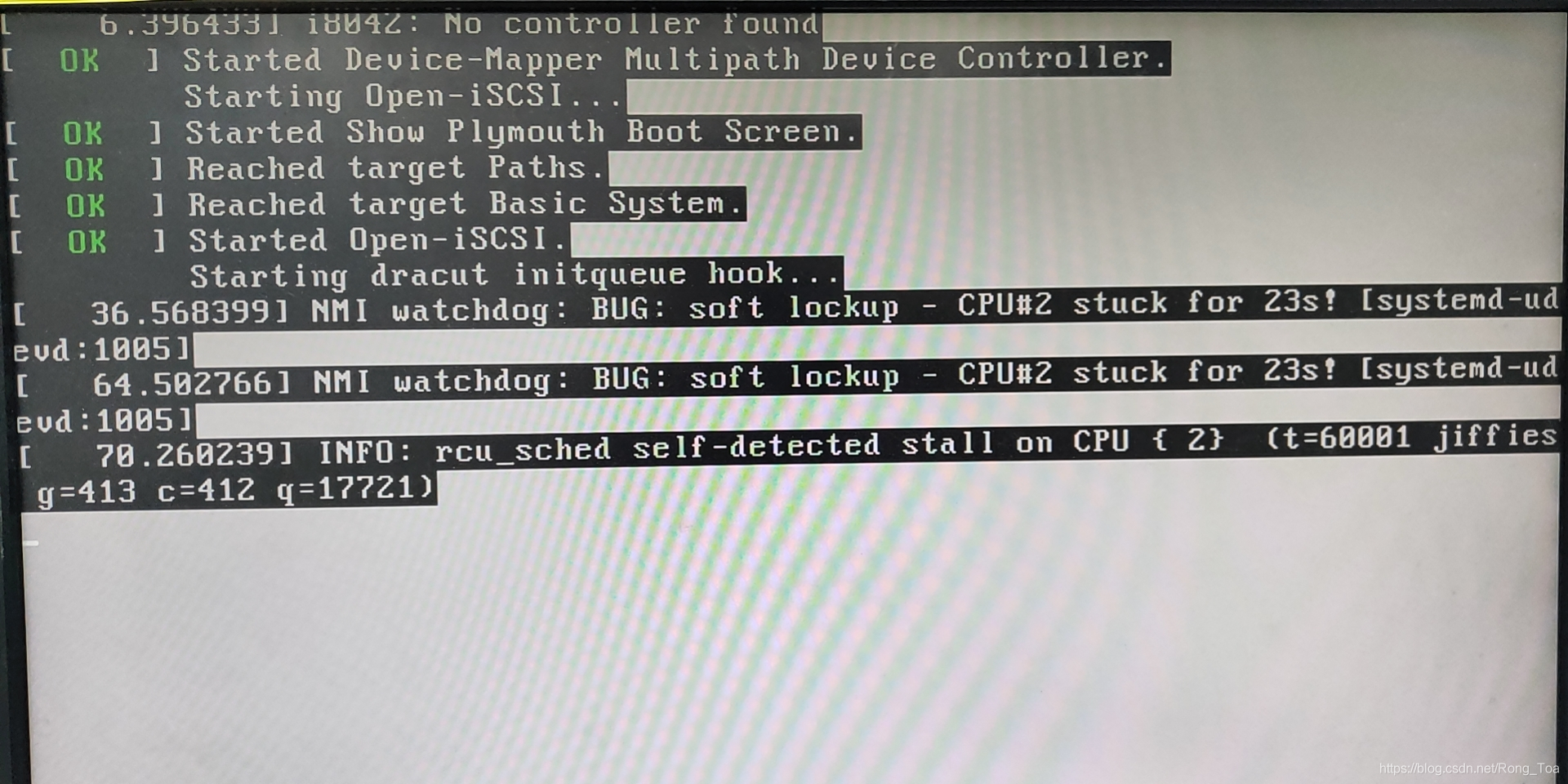
安装系统时Lockup
https://blog.csdn.net/hyj_king/article/details/105227622
有时候在服务器安装系统时,总是安装不成功系统;
(1)在此界面按Tab健,在quiet前加入modprobe.blacklist=ast
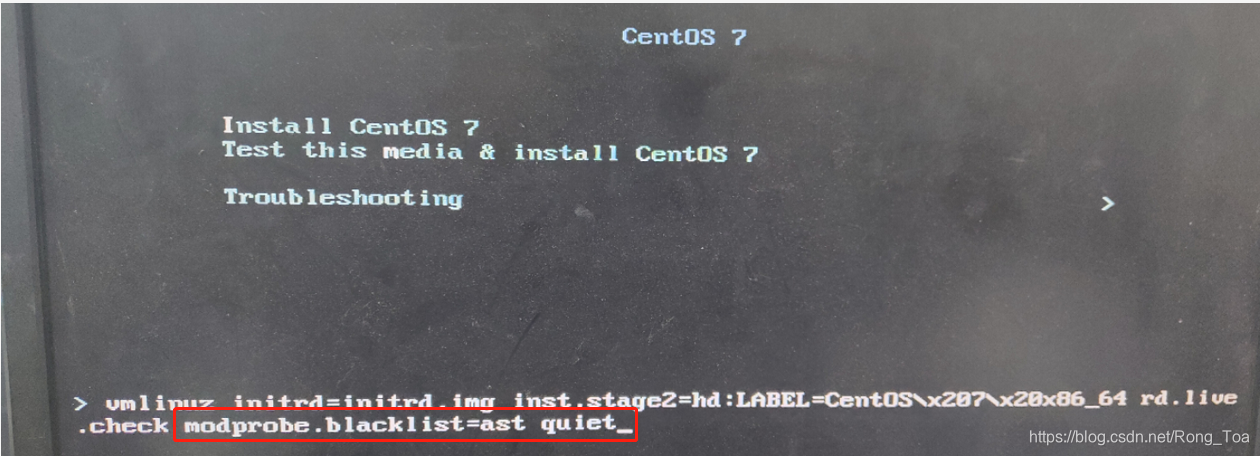
(2)有的系统按e进入编辑,并在在quiet前加入modprobe.blacklist=ast

















 6811
6811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









