









概叙
实战:搞懂SQL执行流程、SQL执行计划解读和SQL优化_sql解析和sql执行计划-CSDN博客
在排查mysql执行慢的过程中,前面文章中都有解释explain执行计划,这里单独拿出来解读一下。
慢查询的确会导致很多问题,我们要如何优化慢查询呢?
主要解决办法有:
-
监控sql执行情况,发邮件、短信报警,便于快速识别慢查询sql
-
打开数据库慢查询日志功能
-
简化业务逻辑
-
代码重构、优化
-
异步处理
-
sql优化
-
索引优化
如何查看某条sql的索引执行情况呢?
没错,在sql前面加上explain关键字,就能够看到它的执行计划,通过执行计划,我们可以清楚的看到表和索引执行的情况,索引有没有执行、索引执行顺序和索引的类型等。
索引优化的步骤是:
-
使用
explain查看sql执行计划 -
判断哪些索引使用不当
-
优化sql,sql可能需要多次优化才能达到索引使用的最优值。
explain的语法:
{EXPLAIN | DESCRIBE | DESC}
tbl_name [col_name | wild]
{EXPLAIN | DESCRIBE | DESC}
[explain_type]
{explainable_stmt | FORCONNECTION connection_id}
explain_type: {
EXTENDED
| PARTITIONS
| FORMAT = format_name
}
format_name: {
TRADITIONAL
| JSON
}
explainable_stmt: {
SELECTstatement
| DELETEstatement
| INSERTstatement
| REPLACEstatement
| UPDATEstatement
}explain分析慢sql重点关注对象
一般思路:
1.先用慢查询日志定位具体需要优化的sql
2.使用explain执行计划查看索引使用情况
3.重点关注:
key(查看有没有使用索引)
key_len(查看索引使用是否充分,通过key_len计算,判断是否有使用对应的索引)
type(查看索引类型)
Extra(重点关注:查看附加信息:排序、临时表、where条件为false等)
一般情况下根据这4列就能找到索引问题。
4.根据上1步找出的索引问题优化sql
5.再回到第2步
索引优化查询一般操作流程
对于出现在where条件中表的列或者group by中的列,可以尝试建立索引优化查询;
如果一个表有多个列出现在where中,可以考虑在这几列上建立联合索引;
如果select只取表中较少的列可以考虑建立覆盖索引。
//先更新表的统计数据,更新前后可能导致执行计划不同
analyze table tbname (切记,在业务低峰时操作;最好不要直接在生产环境操作)
//查看sql执行计划
explain select ...;
//重点观察:type为ALL类型的查询可能是缺少索引;
//rows较高的列可能是缺少索引或者索引唯一性不好,可以考虑建立联合索引;
//查看表上已经存在的索引,避免重复建立索引
show indexes from tb;
//cardinality列代表了索引的唯一性,越大越好
//在表tb的列colx建立索引前应该先分析索引的唯一性
select colx,count(*) from tb group by colx;
//建立索引
create index idname on tbnabme(col1,col2...);
//重新查看执行计划,检查执行计划是否使用了新建立的索引
explain select ....;
//直接执行sql,查看是否真的有性能提升
//有时候建立索引反而导致性能下降,mysql的执行计划都无法正确判断是否应该走索引
//所以实践是检验真理的唯一标准
select ...建立索引并不一定就能起到优化查询的效果。
全表扫描读取的数据量大,是顺序IO;通过普通索引查询读取的数据少,但回表(type为ref)是随机IO。
当普通索引筛选出的数据量少到一定阈值之后,才会优于全表扫描。
这个阈值是很难确定的(数据库的执行计划是如何判断成本的呢?)。
联合索引可以更准确的找到数据,但是联合索引占用的存储空间比单列索引大,所以也不一定能提高查找效率。
建立索引的时候需要重点考虑索引唯一性,索引大小,回表产生的随机IO。
建立索引或导致数据更新操作变慢,因为这些操作需要维护索引,同时索引导致数据库占用更多的存储空间。
explain列概叙
//查看slow-log.log获取慢sql
explain sql;
//如explain select * from test;

explain列详细解释
id列
该列的值是select查询中的序号,比如:1、2、3、4等,它决定了表的执行顺序。
某条sql的执行计划中一般会出现三种情况:
-
id相同
-
id不同
-
id相同和不同都有
那么这三种情况表的执行顺序是怎么样的呢?
1.id相同
执行sql如下:
explain select * from test1 t1 inner join test1 t2 on t1.id=t2.id
结果:

我们看到执行结果中的两条数据id都是1,是相同的。
这种情况表的执行顺序是怎么样的呢?
答案:从上到下执行,先执行表t1,再执行表t2。
执行的表要怎么看呢?
答案:看table字段,这个字段后面会详细解释。
2.id不同
执行sql如下:
explain select * from test1 t1 where t1.id = (select id from test1 t2 where t2.id=2);
结果:

我们看到执行结果中两条数据的id不同,第一条数据是1,第二条数据是2。
这种情况表的执行顺序是怎么样的呢?
答案:序号大的先执行,这里会从下到上执行,先执行表t2,再执行表t1。
3.id相同和不同都有
执行sql如下:
explain
select t1.* from test1 t1
inner join (select max(id) mid from test1 group by id) t2
on t1.id=t2.mid
结果:

我们看到执行结果中三条数据,前面两条数据的的id相同,第三条数据的id跟前面的不同。
这种情况表的执行顺序又是怎么样的呢?
答案:先执行序号大的,先从下而上执行。遇到序号相同时,再从上而下执行。所以这个列子中表的顺序顺序是:test1、t1、
也许你会在这里心生疑问:<derived2> 是什么鬼?
它表示派生表,别急后面会讲的。
还有一个问题:id列的值允许为空吗?
答案在后面揭晓。
select_type列
该列表示select的类型。具体包含了如下11种类型:
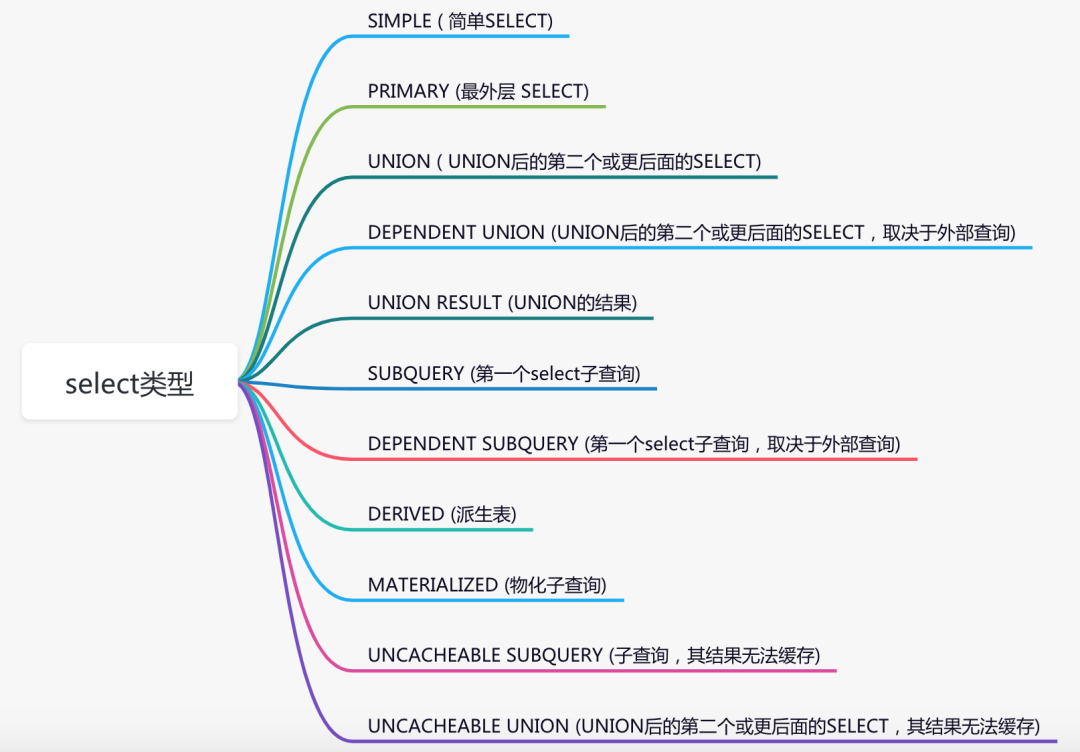
但是常用的其实就是下面几个:
| 类型 | 含义 |
|---|---|
| SIMPLE | 简单SELECT查询,不包含子查询和UNION |
| PRIMARY | 复杂查询中的最外层查询,表示主要的查询 |
| SUBQUERY | SELECT或WHERE列表中包含了子查询 |
| DERIVED | FROM列表中包含的子查询,即衍生 |
| UNION | UNION关键字之后的查询 |
| UNION RESULT | 从UNION后的表获取结果集 |
下面看看这些SELECT类型具体是怎么出现的:
-
SIMPLE
执行sql如下:
explain select * from test1;结果:

它只在简单SELECT查询中出现,不包含子查询和UNION,这种类型比较直观就不多说了。
-
PRIMARY 和 SUBQUERY
执行sql如下:
explain select * from test1 t1 where t1.id = (select id from test1 t2 where t2.id=2);结果:

我们看到这条嵌套查询的sql中,最外层的t1表是PRIMARY类型,而最里面的子查询t2表是SUBQUERY类型。
-
DERIVED
执行sql如下:
explain select t1.* from test1 t1 inner join (select max(id) mid from test1 group by id) t2 on t1.id=t2.mid结果:

最后一条记录就是衍生表,它一般是FROM列表中包含的子查询,这里是sql中的分组子查询。
-
UNION 和 UNION RESULT
执行sql如下:
explain select * from test1 union select* from test2结果:

test2表是UNION关键字之后的查询,所以被标记为UNION,test1是最主要的表,被标记为PRIMARY。而<union1,2>表示id=1和id=2的表union,其结果被标记为UNION RESULT。
UNION 和 UNION RESULT一般会成对出现。
此外,回答上面的问题:id列的值允许为空吗?
如果仔细看上面那张图,会发现id列是可以允许为空的,并且是在SELECT类型为: UNION RESULT的时候。
table列
该列的值表示输出行所引用的表的名称,比如前面的:test1、test2等。
但也可以是以下值之一:
-
<unionM,N>:具有和id值的行的M并集N。 -
<derivedN>:用于与该行的派生表结果id的值N。派生表可能来自(例如)FROM子句中的子查询 。 -
<subqueryN>:子查询的结果,其id值为N
partitions列
该列的值表示查询将从中匹配记录的分区
type列
该列的值表示连接类型,是查看索引执行情况的一个重要指标。包含如下类型:
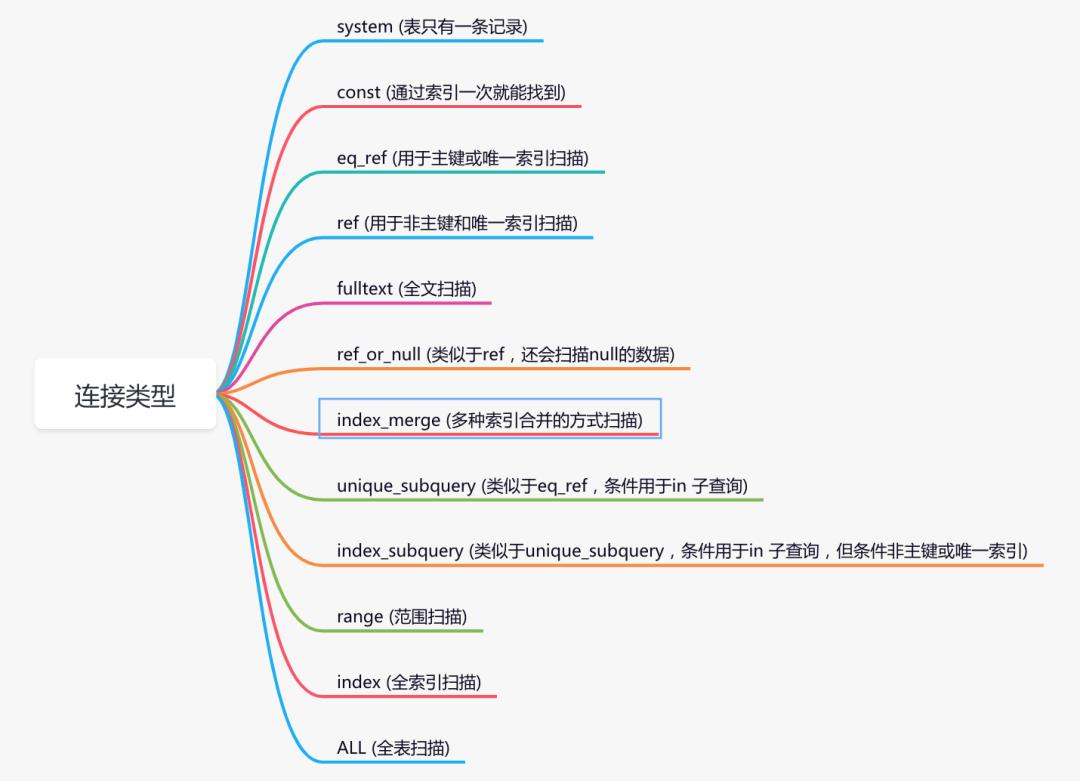
执行结果从最好到最坏的的顺序是从上到下。
我们需要重点掌握的是下面几种类型:
system > const > eq_ref > ref > range > index > ALL
在演示之前,先说明一下test2表中只有一条数据:
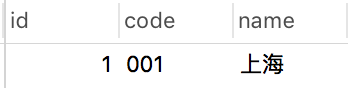
并且code字段上面建了一个普通索引:

下面逐一看看常见的几个连接类型是怎么出现的:
-
system
这种类型要求数据库表中只有一条数据,是const类型的一个特例,一般情况下是不会出现的。
-
const
通过一次索引就能找到数据,一般用于主键或唯一索引作为条件的查询sql中,执行sql如下:
explain select * from test2 where id=1;结果:

-
eq_ref
常用于主键或唯一索引扫描。执行sql如下:
explain select * from test2 t1 inner join test2 t2 on t1.id=t2.id;结果:

此时,有人可能感到不解,const和eq_ref都是对主键或唯一索引的扫描,有什么区别?
答:const只索引一次,而eq_ref主键和主键匹配,由于表中有多条数据,一般情况下要索引多次,才能全部匹配上。
-
ref
常用于非主键和唯一索引扫描。执行sql如下:
explain select * from test2 where code = '001';结果:

-
range
常用于范围查询,比如:between ... and 或 In 等操作,执行sql如下:
explain select * from test2 where id between 1 and 2;结果:

-
index
全索引扫描。执行sql如下:
explain select code from test2;结果:

-
ALL
全表扫描。执行sql如下:
explain select * from test2;结果:

possible_keys列
该列表示可能的索引选择。
请注意,此列完全独立于表的顺序,这就意味着possible_keys在实践中,某些键可能无法与生成的表顺序一起使用。

如果此列是NULL,则没有相关的索引。在这种情况下,您可以通过检查该WHERE 子句以检查它是否引用了某些适合索引的列,从而提高查询性能。
key列
该列表示实际用到的索引。
可能会出现possible_keys列为NULL,但是key不为NULL的情况。
演示之前,先看看test1表结构:

test1表中数据:
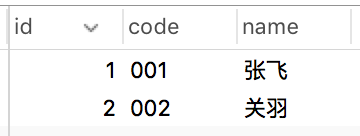
使用的索引:

code和name字段使用了联合索引。
执行sql如下:
explain select code from test1;
结果:

这条sql预计没有使用索引,但是实际上使用了全索引扫描方式的索引。
key_len列
该列表示使用索引的长度。上面的key列可以看出有没有使用索引,key_len列则可以更进一步看出索引使用是否充分。不出意外的话,它是最重要的列。

有个关键的问题浮出水面:key_len是如何计算的?
决定key_len值的三个因素:
1.字符集
2.长度
3.是否为空
常用的字符编码占用字节数量如下:
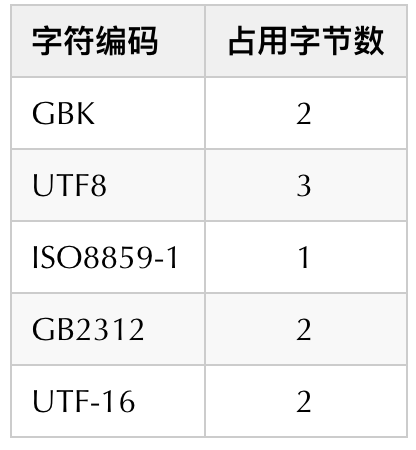
目前我的数据库字符编码格式用的:UTF8占3个字节。
mysql常用字段占用字节数:
| 字段类型 | 占用字节数 |
|---|---|
| char(n) | n |
| varchar(n) | n + 2 |
| tinyint | 1 |
| smallint | 2 |
| int | 4 |
| bigint | 8 |
| date | 3 |
| timestamp | 4 |
| datetime | 8 |
此外,如果字段类型允许为空则加1个字节。
上图中的 184是怎么算的?
184 = 30 * 3 + 2 + 30 * 3 + 2
再把test1表的code字段类型改成char,并且改成允许为空:

执行sql如下:
explain select code from test1;
结果:

怎么算的?
183 = 30 * 3 + 1 + 30 * 3 + 2
还有一个问题:为什么这列表示索引使用是否充分呢,还有使用不充分的情况?
执行sql如下:
explain select code from test1 where code='001';
结果:

上图中使用了联合索引:idx_code_name,如果索引全匹配key_len应该是183,但实际上却是92,这就说明没有使用所有的索引,索引使用不充分。
ref列
该列表示索引命中的列或者常量。
执行sql如下:
explain select * from test1 t1 inner join test1 t2 on t1.id=t2.id where t1.code='001';
结果:

我们看到表t1命中的索引是const(常量),而t2命中的索引是列sue库的t1表的id字段。
rows列
该列表示MySQL认为执行查询必须检查的行数。

对于InnoDB表,此数字是估计值,可能并不总是准确的。
filtered列
该列表示按表条件过滤的表行的估计百分比。最大值为100,这表示未过滤行。值从100减小表示过滤量增加。

rows显示了检查的估计行数,rows× filtered显示了与下表连接的行数。例如,如果 rows为1000且 filtered为50.00(50%),则与下表连接的行数为1000×50%= 500。
Extra列
该字段包含有关MySQL如何解析查询的其他信息,这列还是挺重要的,但是里面包含的值太多,就不一一介绍了,只列举几个常见的。
-
Impossible WHERE
表示WHERE后面的条件一直都是false,
执行sql如下:
explain select code from test1 where 'a' = 'b';结果:

-
Using filesort
表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。
执行sql如下:
explain select code from test1 order by name desc;结果:

这里建立的是code和name的联合索引,顺序是code在前,name在后,这里直接按name降序,跟之前联合索引的顺序不一样。
-
Extra为Using filesort说明,得到所需结果集,需要对所有记录进行文件排序。
这类SQL语句性能极差,需要进行优化。
典型的,在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
-
-
Using index
表示是否用了覆盖索引,说白了它表示是否所有获取的列都走了索引。

上面那个例子中其实就用到了:Using index,因为只返回一列code,它字段走了索引。
-
"Using index":这表示查询只使用了索引来获取数据,而没有进行额外的全表扫描。这是一个高效的查询方式,但并不意味着查询已经完全优化。额外的优化可能包括确保查询的排序操作也利用了索引,或者考虑是否可以通过调整查询结构来避免不必要的索引使用。
-
Extra为Using index说明,SQL所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。
画外音:The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row.
这类SQL语句往往性能较好。
-
Extra为Using index condition说明,确实命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
画外音:聚集索引,普通索引的底层实现差异,之前撰文过。
这类SQL语句性能也较高,但不如Using index。
-
-
Using temporary
表示是否使用了临时表,一般多见于order by 和 group by语句。
执行sql如下:
explain select name from test1 group by name;结果:

Extra是Using temporary说明,需要建立临时表(temporary table)来暂存中间结果。
这类SQL语句性能较低,往往也需要进行优化。
典型的,group by和order by同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集。
-
Using where
表示使用了where条件过滤。这表示MySQL服务层将部分条件下推到存储引擎层,但仍然需要在MySQL服务层应用其他条件来过滤数据。这通常意味着查询可能不是最优的,因为全表扫描可能正在使用,或者因为某些条件不能有效地使用索引。优化手段可能包括重新评估查询条件,确保它们能够充分利用索引,或者考虑添加或修改索引以更好地支持查询需求。
-
全表扫描:当Extra列显示为"Using where",并且查询执行了全表扫描(type字段为"ALL"),这通常意味着查询可以优化。优化方法可能包括在where条件中使用的字段上添加索引,或者重新考虑查询逻辑以减少需要扫描的数据量。
-
Extra为Using where说明,SQL使用了where条件过滤数据。
需要注意的是:
(1)返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,对于这类SQL往往需要进行优化;
(2)使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断;
画外音:join type在《上》中有详细叙述,本文不再展开。
本例虽然Extra字段说明使用了where条件过滤,但type属性是ALL,表示需要扫描全部数据,仍有优化空间。
常见的优化方法为,在where过滤属性上添加索引。
画外音:本例中,sex字段区分度不高,添加索引对性能提升有限。
-
-
Using join buffer
表示是否使用连接缓冲。来自较早联接的表被部分读取到联接缓冲区中,然后从缓冲区中使用它们的行来与当前表执行联接。
实验语句:
explain select * from user where id in(select id from user where sex='no');
结果说明:
Extra为Using join buffer (Block Nested Loop)说明,需要进行嵌套循环计算。
画外音:内层和外层的type均为ALL,rows均为4,需要循环进行4*4次计算。
这类SQL语句性能往往也较低,需要进行优化。
典型的,两个关联表join,关联字段均未建立索引,就会出现这种情况。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
Extra:执行情况的描述和说明(重点分析)
Using index:仅使用索引树中的信息从表中检索列信息,而不需要进行附加搜索来读取实际行(使用 二 级 覆 盖 索 引 即 可 获 取 数 据 , 比 较 好 \color{red}{用二级覆盖索引即可获取数据,比较好}用二级覆盖索引即可获取数据,比较好)。
当查询仅使用作为单个索引的一部分的列时,可以使用此策略。
Using index condition:会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
Using where( 需 要 添 加 合 适 的 索 引 ) \color{red}{(需要添加合适的索引)}(需要添加合适的索引):不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤,需要添加合适的索引
Using index for group-by:数据访问和 Using index 一样,所需数据只须要读取索引,当Query
中使用GROUP BY或DISTINCT 子句时,如果分组字段也在索引中,Extra中的信息就会是 Using index for group-by。注:和Using index一样,只需读取覆盖索引
Using temporary( 需 要 添 加 合 适 的 索 引 ) \color{red}{(需要添加合适的索引)}(需要添加合适的索引):表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ;order by,需要添加合适的索引
Using filesort( 需 要 添 加 合 适 的 索 引 ) \color{red}{(需要添加合适的索引)}(需要添加合适的索引):当Query中包含 order by操作,而且无法利用索引完成的排序操作称为“文件排序”,需要添加合适的索引
Using join buffer( 需 要 添 加 合 适 的 索 引 ) \color{red}{(需要添加合适的索引)}(需要添加合适的索引):该值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果),无需过多关注。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行,比 较 好 的 结 果 之 一 \color{red}{比较好的结果之一}比较好的结果之一
No tables used:Query语句中使用from dual 或不含任何from子句 unique row not
found:对于诸如SELECT … FROM tbl_name的查询,没有行满足表上的UNIQUE索引或PRIMARY KEY的条件。
















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











