










概叙
科普文:微服务之Spring Cloud 熔断保护组件Hystrix原理-CSDN博客
科普文:微服务之Spring Cloud 熔断保护组件Hystrix基本操作-CSDN博客
其实前面文章都有提,这里再做一个小结;
1. Spring Cloud引入Hystrix和基本操作
和其他组件一样,springcloud要引入Hystrix基本也是这么三步
1.pom依赖
<!--引入hystrix 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<!--引入hystrix-dashboard 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>2.启动类上的Hystrix开启注解:
@EnableHystrix // 启用Hystrix
@EnableCircuitBreaker // 加入Hystrix监控 依赖actuator3.需要做熔断处理的接口或者方法添加注解:@HystrixCommand
隔离策略:线程池隔离

隔离策略:信号量隔离

2.Hystrix的运作流程
在前面的例子中,我们使用Hystrix时仅仅是创建命令并予以执行。这一步骤看是简单,实际上,Hystrix有一套较为复杂的执行逻辑,下面简单说明一下运作流程。

第一步:在命令执行开始时会做一些准备工作,例如为命令创建相应的线程池等。
第二步:判断是否打开了缓存,打开了缓存就直接查找缓存并返回结果。
第三步:判断断路器是否打开,如果打开就表明该链路不可用,直接执行回退方法。
第四步:判断线程池、信号量(计数器)等条件,例如线程池超负荷,则执行回退方法,否则就去执行命令的内容。
第五步:执行命令,计算是否要对断路器进行处理,执行完成后,如果满足一定条件,这需要开启断路器。如果执行成功,则返回结果,反之则执行回退。
整个流程的关键最主要的地方在于断路器是否打开。我们的客户端在使用Hystrix时表面上只是创建了一个命令来执行,实际上Hystrix已经为客户端添加了几层保护。
2.实际问题
假设有如下应用程序
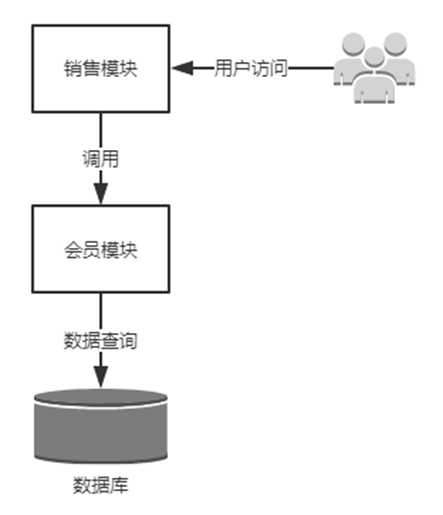
用户范围销售模块,服务通过Web接口或者其他方式访问会员模块,会员模块访问数据库。如果数据库因为某些原因变得不可用,会员模块就会得到“数据库无法访问”的信息,并且会将此信息告知销售模块。在实际问题中,用户会不断地向销售模块发请求,而销售模块这继续请求会员模块,会员模块会不断地请求连接有问题的数据库直到超时,但是还是会有大量的用户请求(包括重试的)会发过来,导致整个应用不堪重负。可能情况会比这个更糟糕,用户的请求不停的发送给销售模块,而由于数据库的原因,会员模块迟迟没有响应,有可能导致整个机房的网络阻塞,受害的不仅仅是这个应用程序,机房中的所有服务都有可能因为网络的原因而瘫痪。
3. 传统的解决方式
对于前面遇到的实际问题,可以选择在连接数据库的同时加上超时的配置,让会员模块快速响应。但这仅仅是解决了其中的一种情况,在实际情况中,会员模块有可能出现问题,例如部分线程阻塞、进程假死等,在这些情况下,对外的服务销售模块面对大量的用户与有故障的会员模块,仍然无法独善其身,前面所说的问题依旧会出现。
在当今的互联网时代,面对大量的用户请求,传统或者单一的解决方式在复杂的急群中显得力不从心,我们需要跟优雅更完善的方案来解决这些问题。
Hystrix除了能支持过载保护,还能提供:请求合并和请求cache两个功能。
4.集群容错框架Hystrix
在分布式环境中,总会有一些被依赖的服务会失效,例如像网络短暂无法访问、服务器宕机等情况。Hystrix是Netflix下的一个java库,Spring Cloud将Hystrix整合到Netflix项目中,Hystrix通过添加延迟阈值以及容错的逻辑,来帮助我们控制分布式系统间组件的交互。Hystrix通过隔离服务间的访问点、停止他们之间的级联故障、提供可回退操作来实现容错。
例如我们之前讲到的问题,如果数据库层面出现问题,销售模块在访问会员模块时必然会出现超时的情况,此时可以将会员模块隔离开来,销售模块短时间内不再调用会员模块,并且会快速响应用户的请求,从而保证销售模块自身乃至整个集群的稳定性,这是Hystrix可以解决的问题。加入了容错机制,当会员模块或者数据库不可用时,销售模块将对其进行“熔断”,在一定时间内,销售模块不会再调用会员模块,以维持自身的稳定,结构图就变成下面的图了

Hystrix主要实现以下的功能:
> 当所依赖的网络服务发生延迟或者失败时,对访问的客户端程序进行保护,就像上面的例子对销售模块进行保护一样;
> 在分布式系统中停止级联故障;
> 网络服务恢复正常后,可以快速恢复客户端的访问能力;
> 调用失败时执行服务回退;
> 可支持实时监控、报警和其他操作。
Hystrix 源码解读
先放一张源码图

在微服务架构中,根据业务来拆分成一个个的服务,服务与服务之间可以相互调用(RPC),在 Spring Cloud 可以用 RestTemplate+Ribbon 和 Feign 来调用。为了保证其高可用,单个服务通常会集群部署。由于网络原因或者自身的原因,服务并不能保证 100% 可用,如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet 容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的 “雪崩” 效应。

为了解决这个问题,业界提出了断路器模型。
在生活中,如果电路的负载过高,保险箱会自动跳闸,以保护家里的各种电器,这就是熔断器的一个活生生例子。在 Hystrix 中也存在这样一个熔断器,当所依赖的服务不稳定时,能够自动熔断,并提供有损服务,保护服务的稳定性。在运行过程中,Hystrix 会根据接口的执行状态(成功、失败、超时和拒绝),收集并统计这些数据,根据这些信息来实时决策是否进行熔断。
一、Hystrix 简介
Netflix has created a library called Hystrix that implements the circuit breaker pattern. In a microservice architecture it is common to have multiple layers of service calls.
. —- 摘自官网
Netflix 开源了 Hystrix 组件,实现了断路器模式,SpringCloud 对这一组件进行了整合。 在微服务架构中,一个请求需要调用多个服务是非常常见的,如下图:

较底层的服务如果出现故障,会导致连锁故障。当对特定的服务的调用的不可用达到一个阀值(Hystric 是 5 秒 20 次) 断路器将会被打开。

断路打开后,可用避免连锁故障,fallback 方法可以直接返回一个固定值。
Hystrix 是什么?
在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的。
Hystrix 可以让我们在分布式系统中对服务间的调用进行控制,加入一些调用延迟或者依赖故障的容错机制。
Hystrix 通过将依赖服务进行资源隔离,进而阻止某个依赖服务出现故障时在整个系统所有的依赖服务调用中进行蔓延;同时 Hystrix 还提供故障时的 fallback 降级机制。
总而言之,Hystrix 通过这些方法帮助我们提升分布式系统的可用性和稳定性。
Hystrix 的历史
Hystrix 是高可用性保障的一个框架。Netflix(可以认为是国外的优酷或者爱奇艺之类的视频网站)的 API 团队从 2011 年开始做一些提升系统可用性和稳定性的工作,Hystrix 就是从那时候开始发展出来的。
在 2012 年的时候,Hystrix 就变得比较成熟和稳定了,Netflix 中,除了 API 团队以外,很多其他的团队都开始使用 Hystrix。
时至今日,Netflix 中每天都有数十亿次的服务间调用,通过 Hystrix 框架在进行,而 Hystrix 也帮助 Netflix 网站提升了整体的可用性和稳定性。
2018 年 11 月,Hystrix 在其 Github 主页宣布,不再开放新功能,推荐开发者使用其他仍然活跃的开源项目。维护模式的转变绝不意味着 Hystrix 不再有价值。相反,Hystrix 激发了很多伟大的想法和项目,我们高可用的这一块知识还是会针对 Hystrix 进行讲解。
Hystrix 的设计原则
・对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护。
・在复杂的分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延。比如某一个服务故障了,导致其它服务也跟着故障。
・提供 fail-fast(快速失败)和快速恢复的支持。
・提供 fallback 优雅降级的支持。
・支持近实时的监控、报警以及运维操作。
・阻止任何一个依赖服务耗尽所有的资源,比如 tomcat 中的所有线程资源。
・避免请求排队和积压,采用限流和 fail fast 来控制故障。
・提供 fallback 降级机制来应对故障。
・使用资源隔离技术,比如 bulkhead(舱壁隔离技术)、circuit breaker(断路技术)来限制任何一个依赖服务的故障的影响。
・通过近实时的统计 / 监控 / 报警功能,来提高故障发现的速度。
・通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度。
・保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况。
那么Hystrix是如何解决依赖隔离呢?
从官网上看到这样一段:
Hystrix使用命令模式HystrixCommand(Command)包装依赖调用逻辑,每个命令在单独线程中/信号授权下执行。
可配置依赖调用超时时间,超时时间一般设为比99.5%平均时间略高即可.当调用超时时,直接返回或执行fallback逻辑。
为每个依赖提供一个小的线程池(或信号),如果线程池已满调用将被立即拒绝,默认不采用排队,加速失败判定时间。
依赖调用结果分:成功,失败(抛出异常),超时,线程拒绝,短路。 请求失败(异常,拒绝,超时,短路)时执行fallback(降级)逻辑。
提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认错误率阈值为50%,超过将自动运行。
另外在学习之前大家需要注意的是,Hystrix现在已经停止更新,意味着你在生产环境如果想使用的话就要考虑现有功能是否能够满足需求。另外开源界现在也有别的更优秀的服务治理组件:Resilience4j 和 Sentinel,如果你有需要可以去看一下它们现在的使用情况。当然这里并不影响我们继续学习Hystrix,毕竟作为分布式依赖隔离的鼻祖,它的设计思想还是需要吃透的。
Hystrix如何实现依赖隔离
命令模式
将所有请求外部系统(或者叫依赖服务)的逻辑封装到 HystrixCommand 或者 HystrixObservableCommand 对象中。
Run()方法为实现业务逻辑,这些逻辑将会在独立的线程中被执行当请求依赖服务时出现拒绝服务、超时或者短路(多个依赖服务顺序请求,前面的依赖服务请求失败,则后面的请求不会发出)时,执行该依赖服务的失败回退逻辑(Fallback)。
隔离策略
Hystrix 为每个依赖项维护一个小线程池(或信号量);如果它们达到设定值(触发隔离),则发往该依赖项的请求将立即被拒绝,执行失败回退逻辑(Fallback),而不是排队。
隔离策略分线程隔离和信号隔离。
线程隔离
第三方客户端(执行Hystrix的run()方法)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。
使用线程隔离的好处:
应用程序可以不受失控的第三方客户端的威胁,如果第三方客户端出现问题,可以通过降级来隔离依赖。
当失败的客户端服务恢复时,线程池将会被清除,应用程序也会恢复,而不至于使整个Tomcat容器出现故障。
如果一个客户端库的配置错误,线程池可以很快的感知这一错误(通过增加错误比例,延迟,超时,拒绝等),并可以在不影响应用程序的功能情况下来处理这些问题(可以通过动态配置来进行实时的改变)。
如果一个客户端服务的性能变差,可以通过改变线程池的指标(错误、延迟、超时、拒绝)来进行属性的调整,并且这些调整可以不影响其他的客户端请求。
简而言之,由线程供的隔离功能可以使客户端和应用程序优雅的处理各种变化,而不会造成中断。
线程池的缺点
线程最主要的缺点就是增加了CPU的计算开销,每个command都会在单独的线程上执行,这样的执行方式会涉及到命令的排队、调度和上下文切换。
Netflix在设计这个系统时,决定接受这个开销的代价,来换取它所提供的好处,并且认为这个开销是足够小的,不会有重大的成本或者是性能影响。
信号隔离
信号隔离是通过限制依赖服务的并发请求数,来控制隔离开关。信号隔离方式下,业务请求线程和执行依赖服务的线程是同一个线程(例如Tomcat容器线程)。
观察者模式
Hystrix通过观察者模式对服务进行状态监听
每个任务都包含有一个对应的Metrics,所有Metrics都由一个ConcurrentHashMap来进行维护,Key是CommandKey.name()
在任务的不同阶段会往Metrics中写入不同的信息,Metrics会对统计到的历史信息进行统计汇总,供熔断器以及Dashboard监控时使用
Metrics
Metrics内部又包含了许多内部用来管理各种状态的类,所有的状态都是由这些类管理的
各种状态的内部也是用ConcurrentHashMap来进行维护的
Metrics在统计各种状态时,时运用滑动窗口思想进行统计的,在一个滑动窗口时间中又划分了若干个Bucket(滑动窗口时间与Bucket成整数倍关系),滑动窗口的移动是以Bucket为单位进行滑动的。
熔断机制
熔断机制是一种保护性机制,当系统中某个服务失败率过高时,将开启熔断器,对该服务的后续调用,直接拒绝,进行Fallback操作。
熔断所依靠的数据即是Metrics中的HealthCount所统计的错误率。
如何判断是否应该开启熔断器?
必须同时满足两个条件:
请求数达到设定的阀值;
请求的失败数 / 总请求数 > 错误占比阀值%。
降级策略
当construct()或run()执行失败时,Hystrix调用fallback执行回退逻辑,回退逻辑包含了通用的响应信息,这些响应从内存缓存中或者其他固定逻辑中得到,而不应有任何的网络依赖。
如果一定要在失败回退逻辑中包含网络请求,必须将这些网络请求包装在另一个 HystrixCommand 或 HystrixObservableCommand 中,即多次降级。
失败降级也有频率限时,如果同一fallback短时间请求过大,则会抛出拒绝异常。
缓存机制
同一对象的不同HystrixCommand实例,只执行一次底层的run()方法,并将第一个响应结果缓存起来,其后的请求都会从缓存返回相同的数据。
由于请求缓存位于construct()或run()方法调用之前,所以,它减少了线程的执行,消除了线程、上下文等开销。
二、demo 演示
1:在 ribbon 使用断路器
改造 serice-ribbon 工程的代码,首先在 pox.xml 文件中加入 spring-cloud-starter-hystrix 的起步依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>在程序的启动类 SpringCloudServiceRibbonApplication 加 @EnableHystrix 注解开启 Hystrix:
@SpringBootApplication
@EnableDiscoveryClient
@EnableHystrix
@EnableHystrixDashboard
public class SpringCloudServiceRibbonApplication {
public static void main(String[] args) {
SpringApplication.run(SpringCloudServiceRibbonApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate(){
return new RestTemplate();
}
}改造 UserService 类,在 query 方法上加上 @HystrixCommand 注解。该注解对该方法创建了熔断器的功能,并指定了 fallbackMethod 熔断方法,熔断方法直接返回了一个对象,代码如下:
@Service
public class UserService {
@Autowired
RestTemplate restTemplate;
@HystrixCommand(commandKey="queryCommandKey",groupKey = "queryGroup",threadPoolKey="queryThreadPoolKey",fallbackMethod = "queryFallback",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "100"),//指定多久超时,单位毫秒。超时进fallback
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "3"),//判断熔断的最少请求数,默认是10;只有在一个统计窗口内处理的请求数量达到这个阈值,才会进行熔断与否的判断
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),//判断熔断的阈值,默认值50,表示在一个统计窗口内有50%的请求处理失败,会触发熔断
},
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "30"),
@HystrixProperty(name = "maxQueueSize", value = "100"),
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "15"),
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "10"),
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "100000")
})
public List<User> query(){
return restTemplate.getForObject("http://service-user/user/query",List.class);
}
public List<User> queryFallback(){
List<User> list = new ArrayList<>();
User user = new User();
user.setId("1211");
user.setName("queryFallback");
list.add(user);
return list;
}
}启动:service-ribbon 工程,当我们访问 http://127.0.0.1:9527/user/query, 浏览器显示:
[{
"id": "id0",
"name": "testname0"
},
{
"id": "id1",
"name": "testname1"
},
{
"id": "id2",
"name": "testname2"
}
]此时关闭 service-user 工程,当我们再访问 http://127.0.0.1:9527/user/query, 浏览器会显示:
[{
"id": "1211",
"name": "queryFallback"
}]这就说明当 service-user 工程不可用的时候,service-ribbon 调用 service-user 的 API 接口时,会执行快速失败,直接返回一组字符串,而不是等待响应超时,这很好的控制了容器的线程阻塞。
2:在 Feign 中使用断路器
Feign 是自带断路器的,在 D 版本的 Spring Cloud 中,它没有默认打开。需要在配置文件中配置打开它,在配置文件加以下代码:
feign:
hystrix:
enabled: true基于 service-feign 工程进行改造,只需要在 FeignClient 的 UserService 接口的注解中加上 fallback 的指定类就行了:
@FeignClient(value="service-user",fallback = UserServiceFallback.class)
public interface UserService {
@RequestMapping(value="/user/query",method = RequestMethod.GET)
public List<User> query();
}UserServiceFallback 需要实现 UserService 接口,并注入到 Ioc 容器中,代码如下:
@Component
public class UserServiceFallback implements UserService {
@Override
public List<User> query() {
List<User> list = new ArrayList<>();
User user = new User();
user.setId("1211");
user.setName("feignFallback");
list.add(user);
return list;
}
}启动 servcie-feign 工程,浏览器打开 http://127.0.0.1:9528/user/query 注意此时 service-user 工程没有启动,网页显示:
[{
"id": "1211",
"name": "feignFallback",
"date": null
}]这证明断路器起到作用了。
基于 service-ribbon 改造,Feign 的改造和这一样。
首选在 pom.xml 引入 spring-cloud-starter-hystrix-dashboard 的起步依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix-dashboard</artifactId>
</dependency>在主程序启动类中加入 @EnableHystrixDashboard 注解,开启 hystrixDashboard:
@SpringBootApplication
@EnableDiscoveryClient
@EnableHystrix
@EnableHystrixDashboard
public class ServiceRibbonApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceRibbonApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}3:Hystrix Dashboard (断路器:Hystrix 仪表盘)
打开浏览器:访问 http://localhost:9527/hystrix, 界面如下:

点击 monitor stream,进入下一个界面,访问:http://127.0.0.1:9527/user/query
此时会出现监控界面:

4:Hystrix Turbine 简介
看单个的 Hystrix Dashboard 的数据并没有什么多大的价值,要想看这个系统的 Hystrix Dashboard 数据就需要用到 Hystrix Turbine。Hystrix Turbine 将每个服务 Hystrix Dashboard 数据进行了整合。Hystrix Turbine 的使用非常简单,只需要引入相应的依赖和加上注解和配置就可以了。
三:Hystrix 流程图
下面的流程图展示了当使用 Hystrix 的依赖请求,Hystrix 是如何工作的。

下面将更详细的解析每一个步骤都发生哪些动作:
1. 构建一个 HystrixCommand 或者 HystrixObservableCommand 对象。
第一步就是构建一个 HystrixCommand 或者 HystrixObservableCommand 对象,该对象将代表你的一个依赖请求,向构造函数中传入请求依赖所需要的参数。
如果构建 HystrixCommand 中的依赖返回单个响应,例如:
HystrixCommand command = new HystrixCommand(arg1, arg2);
如果依赖需要返回一个 Observable 来发射响应,就需要通过构建 HystrixObservableCommand 对象来完 成,例如:
•HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2. 执行命令
・有 4 种方式可以执行一个 Hystrix 命令。
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
•Observable<K> ocValue = command.toObservable(); //cold observable
同步调用方法 execute () 实际上就是调用 queue ().get () 方法,queue () 方法的调用的是 toObservable ().toBlocking ().toFuture (). 也就是说,最终每一个 HystrixCommand 都是通过 Observable 来实现的,即使这些命令仅仅是返回一个简单的单个值。
3. 响应是否被缓存
・如果这个命令的请求缓存已经开启,并且本次请求的响应已经存在于缓存中,那么就会立即返回一个包含缓存响应的 Observable(下面将 Request Cache 部分将对请求的 cache 做讲解)。
4. 回路器是否打开
当命令执行时,Hystrix 会检查回路器是否被打开。
如果回路器被打开(或者 tripped),那么 Hystrix 就不会再执行命令,而是直接路由到第 8 步,获取 fallback 方法,并执行 fallback 逻辑。
・如果回路器关闭,那么将进入第 5 步,检查是否有足够的容量来执行任务。(其中容量包括线程池的容量,队列的容量等等)。
5. 线程池、队列、信号量是否已满
・如果与该命令相关的线程池或者队列已经满了,那么 Hystrix 就不会再执行命令,而是立即跳到第 8 步,执行 fallback 逻辑。
6.HystrixObservableCommand.construct () 或者 HystrixCommand.run ()
・在这里,Hystrix 通过你写的方法逻辑来调用对依赖的请求,通过下列之一的调用:
HystrixObservableCommand.construct () — 返回一个发射响应的 Observable 或者发送一个 onError () 的通知。
如果 run()或 construct()方法超出命令的超时值,则线程将抛出 TimeoutException(如果命令本身未在其自己的线程中运行,则将抛出单独的计时器线程)。
在这种情况下,Hystrix 将响应路由到 8. 获取回退,如果该方法不取消 / 中断,它将丢弃最终返回值 run()或 construct()方法。
请注意,没有办法强制潜在的线程停止工作 - 最好的 Hystrix 可以在 JVM 上执行的操作是将其抛出 InterruptedException。
如果由 Hystrix 包装的工作不遵守 InterruptedExceptions,则 Hystrix 线程池中的线程将继续其工作,尽管客户端已经收到 TimeoutException。
这种行为可以使 Hystrix 线程池饱和,尽管负载 “正确脱落”。
大多数 Java HTTP 客户端库不解释 InterruptedExceptions。
因此,请确保在 HTTP 客户端上正确配置连接和读 / 写超时。
如果该命令没有抛出任何异常并且它返回了响应,则 Hystrix 在执行一些日志记录和度量报告后返回此响应。
在 run()的情况下,Hystrix 返回一个 Observable,它发出单个响应,然后发出 onCompleted 通知;
在 construct()的情况下,Hystrix 返回由 construct()返回的相同 Observable。
7. 计算回路指标 [Circuit Health]
Hystrix 会报告成功、失败、拒绝和超时的指标给回路器,回路器包含了一系列的滑动窗口数据,并通过该数据进行统计。
・它使用这些统计数据来决定回路器是否应该熔断,如果需要熔断,将在一定的时间内不在请求依赖 [短路请求],当再一次检查请求的健康的话会重新关闭回路器。
8. 获取 FallBack
・当命令执行失败时,Hystrix 会尝试执行自定义的 Fallback 逻辑:
写一个 fallback 方法,提供一个不需要网络依赖的通用响应,从内存缓存或者其他的静态逻辑获取数据。如果再 fallback 内必须需要网络的调用,更好的做法是使用另一个 HystrixCommand 或者 HystrixObservableCommand。
如果你的命令是继承自 HystrixCommand,那么可以通过实现 HystrixCommand.getFallback () 方法返回一个单个的 fallback 值。
如果你的命令是继承自 HystrixObservableCommand,那么可以通过实现 HystrixObservableCommand.resumeWithFallback () 方法返回一个 Observable,并且该 Observable 能够发射出一个 fallback 值。
Hystrix 会把 fallback 方法返回的响应返回给调用者。
如果你没有为你的命令实现 fallback 方法,那么当命令抛出异常时,Hystrix 仍然会返回一个 Observable,但是该 Observable 并不会发射任何的数据,并且会立即终止并调用 onError () 通知。通过这个 onError 通知,可以将造成该命令抛出异常的原因返回给调用者。
失败或不存在回退的结果将根据您如何调用 Hystrix 命令而有所不同:
・execute ():抛出一个异常。
・queue ():成功返回一个 Future,但是如果调用 get () 方法,将会抛出一个异常。
・observe ():返回一个 Observable,当你订阅它时,它将立即终止,并调用 onError () 方法。
・toObservable ():返回一个 Observable,当你订阅它时,它将立即终止,并调用 onError () 方法。
9. 返回成功的响应
・如果 Hystrix 命令执行成功,它将以 Observable 形式返回响应给调用者。根据你在第 2 步的调用方式不同,在返回 Observablez 之前可能会做一些转换。

・execute ():通过调用 queue () 来得到一个 Future 对象,然后调用 get () 方法来获取 Future 中包含的值。
・queue ():将 Observable 转换成 BlockingObservable,在将 BlockingObservable 转换成一个 Future。
・observe ():订阅返回的 Observable,并且立即开始执行命令的逻辑,
・toObservable ():返回一个没有改变的 Observable,你必须订阅它,它才能够开始执行命令的逻辑。
四:断路器
下图显示了 HystrixCommand 或 HystrixObservableCommand 如何与 HystrixCircuitBreaker 及其逻辑和决策流程进行交互,包括计数器在断路器中的行为方式。

回路器打开和关闭有如下几种情况:
・假设回路中的请求满足了一定的阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold ())
・假设错误发生的百分比超过了设定的错误发生的阈值 HystrixCommandProperties.circuitBreakerErrorThresholdPercentage ()
・回路器状态由 CLOSE 变换成 OPEN
・如果回路器打开,所有的请求都会被回路器所熔断。
・一定时间之后 HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds (),下一个的请求会被通过(处于半打开状态),如果该请求执行失败,回路器会在睡眠窗口期间返回 OPEN,如果请求成功,回路器会被置为关闭状态,重新开启 1 步骤的逻辑。
Hystrix 的熔断器实现在 HystrixCircuitBreaker 类中,比较重要的几个参数如下:
1、circuitBreaker.enabled
熔断器是否启用,默认是 true
2、circuitBreaker.forceOpen
熔断器强制打开,始终保持打开状态,默认是 false
3、circuitBreaker.forceClosed
熔断器强制关闭,始终保持关闭状态,默认是 false
4、circuitBreaker.requestVolumeThreshold
滑动窗口内(10s)的请求数阈值,只有达到了这个阈值,才有可能熔断。默认是 20,如果这个时间段只有 19 个请求,就算全部失败了,也不会自动熔断。
5、circuitBreaker.errorThresholdPercentage
错误率阈值,默认 50%,比如(10s)内有 100 个请求,其中有 60 个发生异常,那么这段时间的错误率是 60,已经超过了错误率阈值,熔断器会自动打开。
6、circuitBreaker.sleepWindowInMilliseconds
熔断器打开之后,为了能够自动恢复,每隔默认 5000ms 放一个请求过去,试探所依赖的服务是否恢复。
・在最新代码中,已经弃用了 allowRequest (),取而代之的是 attemptExecution () 方法。

和 allowRequest () 方法相比,唯一改进的地方是通过 compareAndSet 修改状态值。通过 attemptExecution () 方法的返回值决定执行正常逻辑,还是降级逻辑。
1、如果 circuitBreaker.forceOpen=true,说明熔断器已经强制开启,所有请求都会被熔断。
2、如果 circuitBreaker.forceClosed =true,说明熔断器已经强制关闭,所有请求都会被放行。
3、circuitOpened 默认 - 1,用以保存最近一次发生熔断的时间戳。
4、如果 circuitOpened 不等于 - 1,说明已经发生熔断,通过 isAfterSleepWindow () 判断当前是否需要进行试探。

这里就是熔断器自动恢复的逻辑,如果当前时间已经超过上次熔断的时间戳 + 试探窗口 5000ms,则进入 if 分支,通过 compareAndSet 修改变量 status,竞争试探的能力。其中 status 代表当前熔断器的状态,包含 CLOSED, OPEN, HALF_OPEN,只有试探窗口之后的第一个请求可以执行正常逻辑,且修改当前状态为 HALF_OPEN,进入半熔断状态,其它请求执行 compareAndSet (Status.OPEN, Status.HALF_OPEN) 时都返回 false,执行降级逻辑。
5、如果试探请求发生异常,则执行 markNonSuccess ()

通过 compareAndSet 修改 status 为熔断开启状态,并更新当前熔断开启的时间戳。
6、如果试探请求返回成功,则执行 markSuccess ()
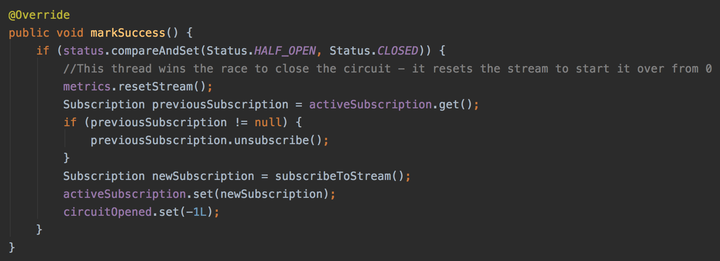
通过 compareAndSet 修改 status 为熔断关闭状态,并重置接口统计数据和 circuitOpened 标识为 - 1,后续请求开始执行正常逻辑。
说了这么多,如何实现自动熔断还没提到,在 Hystrix 内部有一个 Metric 模块,专门统计每个 Command 的执行状态,包括成功、失败、超时、线程池拒绝等,在熔断器的中 subscribeToStream () 方法中,通过订阅数据流变化,实现函数回调,当有新的请求时,数据流发生变化,触发回调函数 onNext

在 onNext 方法中,参数 hc 保存了当前接口在前 10s 之内的请求状态(请求总数、失败数和失败率), 其主要逻辑是判断请求总数是否达到阈值 requestVolumeThreshold,失败率是否达到阈值 errorThresholdPercentage,如果都满足,说明接口的已经足够的不稳定,需要进行熔断,则设置 status 为熔断开启状态,并更新 circuitOpened 为当前时间戳,记录上次熔断开启的时间。
五:隔离
Hystrix 采用舱壁模式来隔离相互之间的依赖关系,并限制对其中任何一个的并发访问。

线程和线程池
客户端(第三方包、网络调用等)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。
•[Hystrix uses separate, per-dependency thread pools as a way of constraining any given dependency so latency on the underlying executions will saturate the available threads only in that pool]

您可以在不使用线程池的情况下防止出现故障,但是这要求客户端必须能够做到快速失败(网络连接 / 读取超时和重试配置),并始终保持良好的执行状态。
Netflix,设计 Hystrix,并且选择使用线程和线程池来实现隔离机制,有以下几个原因:
・很多应用会调用多个不同的后端服务作为依赖。
・每个服务会提供自己的客户端库包。
・每个客户端的库包都会不断的处于变更状态。
•[Client library logic can change to add new network calls]
・每个客户端库包都可能包含重试、数据解析、缓存等等其他逻辑。
・对用户来说,客户端库往往是 “黑盒” 的,对于实现细节、网络访问模式。默认配置等都是不透明的。
•[In several real-world production outages the determination was “oh, something changed and properties should be adjusted” or “the client library changed its behavior.]
・即使客户端本身没有改变,服务本身也可能发生变化,这些因素都会影响到服务的性能,从而导致客户端配置失效。
・传递依赖可以引入其他客户端库,这些客户端库不是预期的,也许没有正确配置。
・大部分的网络访问是同步执行的。
・客户端代码中也可能出现失败和延迟,而不仅仅是在网络调用中。

使用线程池的好处
・通过线程在自己的线程池中隔离的好处是:
简而言之,由线程池提供的隔离功能可以使客户端库和子系统性能特性的不断变化和动态组合得到优雅的处理,而不会造成中断。
注意:虽然单独的线程提供了隔离,但您的底层客户端代码也应该有超时和 / 或响应线程中断,而不能让 Hystrix 的线程池处于无休止的等待状态。
线程池的缺点
线程池最主要的缺点就是增加了 CPU 的计算开销,每个命令都会在单独的线程池上执行,这样的执行方式会涉及到命令的排队、调度和上下文切换。
・Netflix 在设计这个系统时,决定接受这个开销的代价,来换取它所提供的好处,并且认为这个开销是足够小的,不会有重大的成本或者是性能影响。
线程成本
Hystrix 在子线程执行 construct () 方法和 run () 方法时会计算延迟,以及计算父线程从端到端的执行总时间。所以,你可以看到 Hystrix 开销成本包括(线程、度量,日志,断路器等)。
Netflix API 每天使用线程隔离的方式处理 10 亿多的 Hystrix Command 任务,每个 API 实例都有 40 多个线程池,每个线程池都有 5-20 个线程(大多数设置为 10)
・下图显示了一个 HystrixCommand 在单个 API 实例上每秒执行 60 个请求(每个服务器每秒执行大约 350 个线程执行总数):

在中间位置(或者下线位置)不需要单独的线程池。
在第 90 线上,单独线程的成本为 3ms。
在第 99 线上,单独的线程花费 9ms。但是请注意,线程成本的开销增加远小于单独线程(网络请求)从 2 跳到 28 而执行时间从 0 跳到 9 的增加。
对于大多数 Netflix 用例来说,这样的请求在 90%以上的开销被认为是可以接受的,这是为了实现韧性的好处。
对于非常低延迟请求(例如那些主要触发内存缓存的请求),开销可能太高,在这种情况下,可以使用另一种方法,如信号量,虽然它们不允许超时,提供绝大部分的有点,而不会产生开销。然而,一般来说,开销是比较小的,以至于 Netflix 通常更偏向于通过单独的线程来作为隔离实现。
线程隔离 - 信号量
上面提到了线程池隔离的缺点,当依赖延迟极低的服务时,线程池隔离技术引入的开销超过了它所带来的好处。这时候可以使用信号量隔离技术来代替,通过设置信号量来限制对任何给定依赖的并发调用量。下图说明了线程池隔离和信号量隔离的主要区别:

使用线程池时,发送请求的线程和执行依赖服务的线程不是同一个,而使用信号量时,发送请求的线程和执行依赖服务的线程是同一个,都是发起请求的线程。
您可以使用信号量(或计数器)来限制对任何给定依赖项的并发调用数,而不是使用线程池 / 队列大小。这允许 Hystrix 在不使用线程池的情况下卸载负载,但它不允许超时和离开。如果您信任客户端而您只想减载,则可以使用此方法。
HystrixCommand 和 HystrixObservableCommand 支持 2 个地方的信号量:回退:当 Hystrix 检索回退时,它总是在调用 Tomcat 线程上执行此操作。执行:如果将属性 execution.isolation.strategy 设置为 SEMAPHORE,则 Hystrix 将使用信号量而不是线程来限制调用该命令的并发父线程数。您可以通过定义可以执行多少并发线程的动态属性来配置信号量的这两种用法。您应该使用在调整线程池大小时使用的类似计算来调整它们的大小(以毫秒为单位返回的内存中调用可以在 5000rps 下执行,信号量仅为 1 或 2 ...... 但默认值为 10)。注意:如果依赖项与信号量隔离然后变为潜在的,则父线程将保持阻塞状态,直到基础网络调用超时。信号量拒绝将在限制被触发后开始,但填充信号量的线程无法离开。
由于 Hystrix 默认使用线程池做线程隔离,使用信号量隔离需要显示地将属性 execution.isolation.strategy 设置为 ExecutionIsolationStrategy.SEMAPHORE,同时配置信号量个数,默认为 10。客户端需向依赖服务发起请求时,首先要获取一个信号量才能真正发起调用,由于信号量的数量有限,当并发请求量超过信号量个数时,后续的请求都会直接拒绝,进入 fallback 流程。
信号量隔离主要是通过控制并发请求量,防止请求线程大面积阻塞,从而达到限流和防止雪崩的目的。
隔离总结
线程池和信号量都可以做线程隔离,但各有各的优缺点和支持的场景,对比如下:
| 线程切换 | 支持异步 | 支持超时 | 支持熔断 | 限流 | 开销 | |
|---|---|---|---|---|---|---|
| 信号量 | 否 | 否 | 否 | 是 | 是 | 小 |
| 线程池 | 是 | 是 | 是 | 是 | 是 | 大 |
线程池和信号量都支持熔断和限流。相比线程池,信号量不需要线程切换,因此避免了不必要的开销。但是信号量不支持异步,也不支持超时,也就是说当所请求的服务不可用时,信号量会控制超过限制的请求立即返回,但是已经持有信号量的线程只能等待服务响应或从超时中返回,即可能出现长时间等待。线程池模式下,当超过指定时间未响应的服务,Hystrix 会通过响应中断的方式通知线程立即结束并返回。
请求合并
您可以使用请求合并器(HystrixCollapser 是抽象父代)来提前发送 HystrixCommand,通过该合并器您可以将多个请求合并为一个后端依赖项调用。
下面的图展示了两种情况下的线程数和网络连接数,第一张图是不使用请求合并,第二张图是使用请求合并(假定所有连接在短时间窗口内是 “并发的”,在这种情况下是 10ms)。

为什么使用请求合并
・事情请求合并来减少执行并发 HystrixCommand 请求所需要的线程数和网络连接数。请求合并以自动方式执行的,不需要代码层面上进行批处理请求的编码。
全局上下文(所有的 tomcat 线程)
理想的合并方式是在全局应用程序级别来完成的,以便来自任何用户的任何 Tomcat 线程的请求都可以一起合并。
例如,如果将 HystrixCommand 配置为支持任何用户请求获取影片评级的依赖项的批处理,那么当同一个 JVM 中的任何用户线程发出这样的请求时,Hystrix 会将该请求与其他请求一起合并添加到同一个 JVM 中的网络调用。
・请注意,合并器会将一个 HystrixRequestContext 对象传递给合并的网络调用,为了使其成为一个有效选项,下游系统必须处理这种情况。
用户请求上下文(单个 tomcat 线程)
如果将 HystrixCommand 配置为仅处理单个用户的批处理请求,则 Hystrix 仅仅会合并单个 Tomcat 线程的请求。
・例如,如果一个用户想要加载 300 个影片的标签,Hystrix 能够把这 300 次网络调用合并成一次调用。
对象建模和代码的复杂性
有时候,当你创建一个对象模型对消费的对象而言是具有逻辑意义的,这与对象的生产者的有效资源利用率不匹配。
例如,给你 300 个视频对象,遍历他们,并且调用他们的 getSomeAttribute () 方法,但是如果简单的调用,可能会导致 300 次网络调用(可能很快会占满资源)。
有一些手动的方法可以解决这个问题,比如在用户调用 getSomeAttribute () 方法之前,要求用户声明他们想要获取哪些视频对象的属性,以便他们都可以被预取。
或者,您可以分割对象模型,以便用户必须从一个位置获取视频列表,然后从其他位置请求该视频列表的属性。
这些方法可以会使你的 API 和对象模型显得笨拙,并且这种方式也不符合心理模式与使用模式。由于多个开发人员在代码库上工作,可能会导致低级的错误和低效率开发的问题。因为对一个用例的优化可以通过执行另一个用例和通过代码的新路径来打破。
通过将合并逻辑移到 Hystrix 层,不管你如何创建对象模型,调用顺序是怎样的,或者不同的开发人员是否知道是否完成了优化或者是否完成。
・getSomeAttribute()方法可以放在最适合的地方,并以任何适合使用模式的方式被调用,并且合并器会自动将批量调用放置到时间窗口。
请求 Cache
HystrixCommand 和 HystrixObservableCommand 实现可以定义一个缓存键,然后用这个缓存键以并发感知的方式在请求上下文中取消调用(不需要调用依赖即可以得到结果,因为同样的请求结果已经按照缓存键缓存起来了)。
以下是一个涉及 HTTP 请求生命周期的示例流程,以及在该请求中执行工作的两个线程:

请求 cache 的好处有:
・不同的代码路径可以执行 Hystrix 命令,而不用担心重复的工作。
这在许多开发人员实现不同功能的大型代码库中尤其有用。
例如,多个请求路径都需要获取用户的 Account 对象,可以像这样请求:
Account account = new UserGetAccount(accountId).execute();
//or
Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix RequestCache 将只执行一次底层的 run()方法,执行 HystrixCommand 的两个线程都会收到相同的数据,尽管实例化了多个不同的实例。
・整个请求的数据检索是一致的。
每次执行该命令时,不再会返回一个不同的值(或回退),而是将第一个响应缓存起来,后续相同的请求将会返回缓存的响应。
・消除重复的线程执行。
由于请求缓存位于 construct()或 run()方法调用之前,Hystrix 可以在调用线程执行之前取消调用。
如果 Hystrix 没有实现请求缓存功能,那么每个命令都需要在构造或者运行方法中实现,这将在一个线程排队并执行之后进行。
六:源码入口
Spring Boot 中有一种非常解耦的扩展机制:Spring Factories. 这种机制实际上是仿照 java 中的 SPI 扩展机制实现的。
什么是 SPI 机制
SPI 的全名为 Service Provider Interface,简单总结下 Java SPI 机制的思想。我们系统里抽象的各个模块,往往有很多不同的实现方案,比如 日志模块的方案,xml 解析模块、jdbc 模块的方案等。面向的对象设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及了具体的实现类,就违反了可插拔的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI 就是提供这样的一种机制:为某个接口寻找服务的实现的机制,有点类似 IOC 的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制很重要。
Spring Boot 中的 SPI 机制
在 Spring 中也有一种类似与 Java SPI 的加载机制。它在 META-INF/spring.factories 文件中配置接口的实现类名称,然后在程序中读取这些配置文件并实例化。
这种自定义的 SPI 机制是 Spring Boot Starter 实现的基础。
Spring Factories 实现原理
spring-core 包里定义了 SpringFactoriesLoader 类,这个类实现了检索 META-INF/spring.factories 文件,并获取指定接口的配置的功能。在这个类中定义了两个对外的方法:
loadFactories 根据接口类获取其实现类的实例,这个方法返回的是对象列表。
loadFactoryNames 根据接口获取其接口类的名称,这个方法返回的是类名的列表。
上面的两个方法的关键都是从指定的 ClassLoader 中获取 spring.factories 文件,并解析得到类名列表
















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











