










InnoDB有两个非常重要的日志:undo log、redo log
(1)通过undo log可以看到数据较早版本,实现MVCC,或回滚事务等功能。
(2)通过redo log用来保证事务持久性。
重做日志的实现是往磁盘页顺序写物理逻辑日志,如果数据库异常宕机,启动后扫描重做日志并进行恢复可保证数据不丢失,但是我们忽略了一点就是数据一致性问题,如何保证单页数据的一致性其实就是我们本文关注的内容。
Mini-Transaction概叙
Mini-Transaction是用来实现InnoDB的物理逻辑日志的写入和页恢复的。
通过Mini-Transaction来保证并发事务操作和数据库异常时页的一致性。
Mini-Transaction主要用于innodb redo log和undo log写入,保证两种日志的ACID特性。(注意:是日志的ACID特性)
当在MySQL中对InnoDB表进行更改时,这些更改首先存储在InnoDB日志缓冲区的内存中,然后写入通常称为重做日志(redo logs)的InnoDB日志文件中。

redo日志缓冲区是内存存储区域,用于保存要写入磁盘上的日志文件的数据。日志缓冲区大小由innodb_log_buffer_size 变量定义,默认大小为16MB。
日志缓冲区的内容定期刷新到磁盘。较大的日志缓冲区可以运行大型事务,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘I/O。
innodb_flush_log_at_trx_commit :控制如何将日志缓冲区的内容写入并刷新到磁盘。
innodb_flush_log_at_timeout :控制日志刷新频率。
如果磁盘I/O导致性能问题,则需要观察事务,例如涉及许多BLOB条目的事务。只要InnoDB日志缓冲区已满,便会将其刷新到磁盘,因此增加缓冲区大小可以减少I/O。
日志文件的缺省数量为两个: ib_logfile0 和 ib_logfile1 。
日志具有固定大小,默认大小取决于MySQL版本。
从5.7版本开始,默认值是每个48MB,从MySQL 5.6.3开始,最大总大小为 512GB。
如果应用程序是写密集型应用程序,则可以使用48MB,并且鉴于日志以循环方式工作,当日志写满时,有必要对磁盘上的数据文件进行写操作。所以,如redo log大小设置较小,可能会导致频繁的磁盘写入甚至是等待,极大地降低了性能。可通过查看日志序列号状态变量log_lsn_current和log_lsn_last_checkpoint来观察刷新的频率。通过将两个值相减,并与重做日志空间的总大小进行比较,可了解刷新是否比期望的发生更频繁。
要调整 innodb_log_buffer_size 或 innodb_log_file_size 变量,必须在MySQL的my.cnf配置文件中显式定义。
attention:
调整 innodb_log_buffer_size 或 innodb_log_file_size 变量前,建议关闭实例,以确保MySQL正确无误地停止运行。如果在关闭过程中出现错误,则现有的日志文件可能尚未完全写入数据文件,数据可能会丢失。
这里重点讲述下innodb_flush_log_at_trx_commit,该参数控制如何将日志缓冲区的内容写入并刷新到磁盘。
先看下图:redo log落盘策略
事务的日志是先写入到redo log buffer 中是很快的,那如何保证redo log buffer中的信息高效的落到磁盘日志文件中呢?
redo log buffer不是直接将日志内容刷盘到redo log file中。redo log buffer内容先刷入到操作系统的文件系统缓存 (page cache)中去,这个过程很快,而且整个系统宕机概率相对MySQL会小很多。- 最后,日志内容会从操作系统的文件系统缓存中刷到磁盘的日志文件中,至于什么时候触发这个动作,MySQL的innoDB引擎提供了3种策略可选。
InnoDB引擎提供了 innodb_flush_log_at_trx_commit 参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 的3种策略。
- innodb_flush_log_at_trx_commit=1
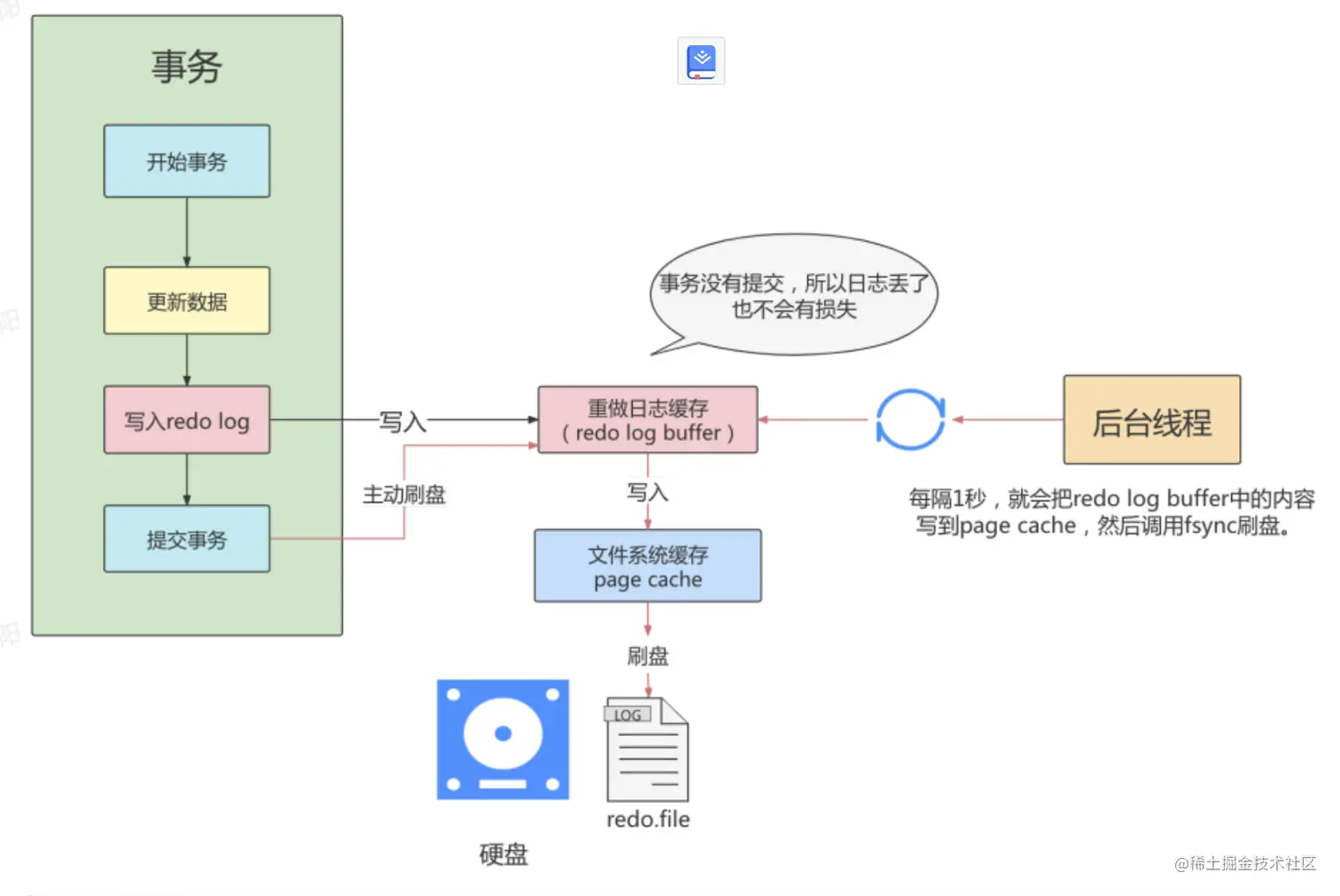
- 每次事务提交时都将进行同步, 执行主动刷盘操作,如上图的红线位置,所以只要事务提交成功,
redo log记录就一定在硬盘里,不会有田可数据丢失。 - 该种方式是MySQL
innoDB存储引擎默认的刷盘机制。 - 如果事务执行期间MySQL挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损
失。可以保证ACID的D,数据绝对不会丢失,但是效率最差的。
- innodb_flush_log_at_trx_commit=2
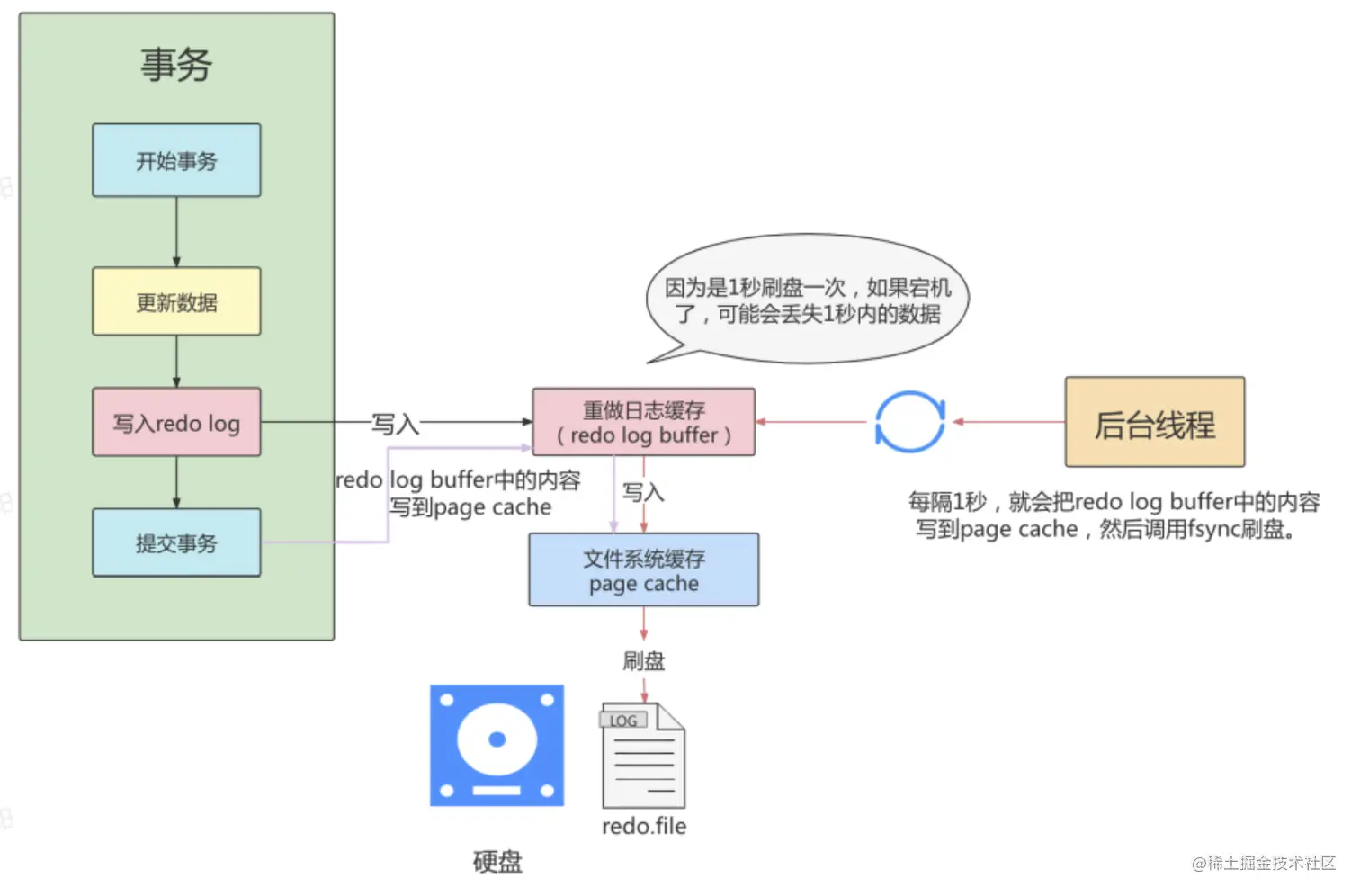
- 为2时,只要事务提交成功,
redo log buffer中的内容只写入文件系统缓存(pagecache) - 如果仅仅只是MySQL挂了不会有任何数据丢失,但是操作系统宕机可能会有1秒数据的丢失,这种情况下无法满足ACID中的D
- 数值2的效率是高于数值等于1的
- innodb_flush_log_at_trx_commit=0
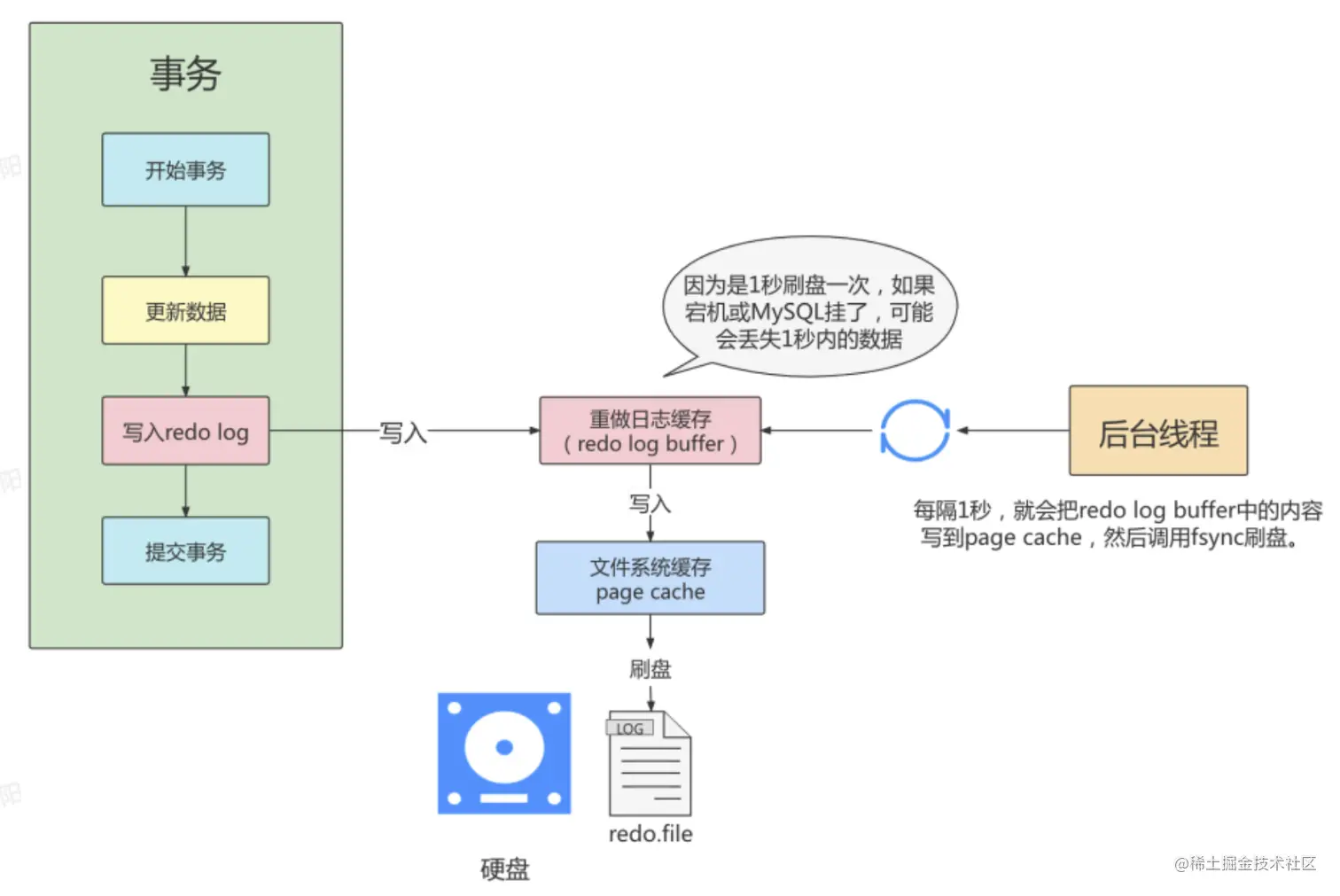
- 为0时,后台线程每隔1秒进行一次重做日志的刷盘操作,因此MySQL挂了最多丢失1秒钟内的事务。
- 这种方式效率是最高的,这种策略也有丢失数据的风险,也无法保证持久性。
- 其他被动触发刷盘的场景
除了上面3种策略进行刷盘以外,还有两种场景会让一个没有提交的事务的 redo log 写入到磁盘中。
redo log buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是write,而没有调用fsync,也就是只留在了文件系统的page cache。- 并行的事务提交的时候,顺带将这个事务的
redo log buffer持久化到磁盘。假设一个事务 A 执行到一半,已经写了一些redo log到buffer中,这时候有另外一个线程的事务 B 提交,如果innodb_flush_log_at_trx_commit设置的是 1,那么按照这个参数的逻辑,事务 B 要把redo log buffer里的日志全部持久化到磁盘。这时候,就会带上事务 A 在redo log buffer里的日志一起持久化到磁盘。
Mini-Transaction详解
mini-transaction其实是保证单个内存也写操作的一致性。在并发场景下,多线程写内存页,一方面能保证线程安全,另一方面在写安全的基础上保证redolog的顺序性。即使redo log恢复过程是并发操作的,但也能保证一致。
mini-transaction和我们理解的数据库事务不是一个东西。从一致性来讲,数据库事务是保证多条语句操作的一致性,往往涉及到多个页的修改。而mini-transaction是单页数据一致性,是避免内存页的并发更新影响。当然数据库事务一致性实现也是建立在mini-transaction的基础上的。
所有对页的操作都要在mini_transaction中执行。
在一个mini-transaction操作中,需要对对应的page加锁。锁中代码逻辑主要就是操作页,然后生成redo和undolog,完成之后释放锁。
mini_transaction(){
Lock page
Transform page
Generate undo and redo log
Unlock page
}为什么这样能保证一致性?
1.对页加锁,能保证这个内存页并发修改的安全性。
2.在锁中append log也能保证log的顺序性(从前面的文章可知,innodb是通过log保证持久,所有内存页写操作都要写log)
3.在innodb中,每当一个事务提交的时候,所有的mini_transaction产生的log必须持久化(当然可以通过参数配置,但是不丢失数据的场景是如此)。
4.Innodb每个数据页都有一个lsn,对于页修改需要更新lsn,在持久化页时,保证对应lsn的log都被持久化即可。
mini-transaction代码实现
代码参照mysql 8.0.23。
mini-transaction代码实现 mini-transaction是mysql内部的对底层page的一个原子操作,保证并发事务操作下以及数据库异常时page中数据的一致性。
mini transaction 的信息保存在结构体 mtr_t 中,结构体成员描述详见前文,其中m_memo和m_log最为重要。
m_memo管理mtr持有的锁信息。对于持有的page锁,还要保留page指针,这是为了在commit时,将修改的脏页加入flush list中。
m_log保存mtr修改操作对应的redo日志。在commit时,将redo日志一起拷贝到log_sys模块的公共日志buffer中。
而mtr的使用方式如下:
mtr_t mtr;
mtr_start(&mtr);
// 1. 加锁
// 对待访问的index加锁
mtr_s_lock(rw_lock_t, mtr);
mtr_x_lock(rw_lock_t, mtr);
// 对待读写的page加锁
mtr_memo_push(mtr, buf_block_t, MTR_MEMO_PAGE_S_FIX);
mtr_memo_push(mtr, buf_block_t, MTR_MEMO_PAGE_X_FIX);
// 2. 访问或修改page
btr_cur_search_to_nth_level
btr_cur_optimistic_insert
// 3. 为修改操作生成redo
mlog_open
mlog_write_initial_log_record_fast
mlog_close
// 4. 持久化redo,解锁
mtr_commit(&mtr);mini-transaction数据结构
struct mtr_struct{
ulint state; /* MTR_ACTIVE, MTR_COMMITTING, MTR_COMMITTED */
dyn_array_t memo; /* memo stack for locks etc. */
dyn_array_t log; /* mini-transaction log */
ibool modifications;
/* TRUE if the mtr made modifications to
buffer pool pages */
ulint n_log_recs;
/* count of how many page initial log records
have been written to the mtr log */
ulint log_mode; /* specifies which operations should be
logged; default value MTR_LOG_ALL */
dulint start_lsn;/* start lsn of the possible log entry for
this mtr */
dulint end_lsn;/* end lsn of the possible log entry for
this mtr */
ulint magic_n;
};
主要存储了状态,对页写入的相关信息以及日志信息。
memo存储了持有latch的信息,是一个stack。栈存储的为mtr_memo_slot_struct。其实就是实现锁的获取和释放。
typedef struct mtr_memo_slot_struct mtr_memo_slot_t;
struct mtr_memo_slot_struct{
ulint type; /* type of the stored object (MTR_MEMO_S_LOCK, ...) */
void* object; 主要是latch对象 参考rw_lock_t、buf_block_t
};
n_log_recs表示修改页的数量,因为一个操作可能会影响多个页,如果涉及多个页的修改,会按顺序对页进行加锁。
上文所说所有操作都要在mini-transaction中执行。其实就是下面的代码逻辑。
mtr_t mtr;
mtr_start(&mtr);
(代码逻辑)
mtr_commit(&mtr);mtr的成员
我们重点看下mtr_t中m_memo和m_log成员的实现。m_memo和m_log都是mtr_buf_t类型的对象,mtr_buf_t是由一个双向链表组成的动态buffer,每个元素是512B大小的buffer(512B刚好匹配一个log block大小)。随着mtr_buf_t存储的数据的增加,它会自动生成新的512B的buffer,并加入双向链表中。
m_memo使用动态buffer的方式是把锁类型、锁地址或page地址加入动态buffer。在mtr_s_lock或mtr_memo_push中会执行如下操作:
mtr_memo_slot_t *slot;
// 先在动态buffer中申请能容纳锁类型+地址的空间,再对该空间进行初始化
slot = m_impl.m_memo.push<mtr_memo_slot_t *>(sizeof(*slot));
// 锁类型
slot->type = type;
// 锁地址或page地址
slot->object = object;m_log使用动态buffer的方式是把日志类型、space id、page no、以及具体的操作信息加入动态buffer。mlog_open:预分配待写入的日志空间,若空间不够,则增加新的buffer到动态buffer中。 mlog_write_initial_log_record_fast:写入日志类型、space id、page no,且m_n_log_recs加1。
// 将日志类型写入从动态buffer中申请的空间log_ptr
mach_write_to_1(log_ptr, type);
log_ptr++;
// 将space id和page no以压缩格式写入log_ptr
log_ptr += mach_write_compressed(log_ptr, space_id);
log_ptr += mach_write_compressed(log_ptr, page_no);
// m_n_log_recs加1,用于标识是single log record还是multiple log records
mtr->added_rec();mlog_close:更新最终的日志大小m_size
mtr_start
UNIV_INLINE mtr_t* mtr_start(mtr_t* mtr)
{
dyn_array_create(&(mtr->memo));
dyn_array_create(&(mtr->log));
mtr->log_mode = MTR_LOG_ALL;
mtr->modifications = FALSE;
mtr->n_log_recs = 0;
#ifdef UNIV_DEBUG
mtr->state = MTR_ACTIVE;
mtr->magic_n = MTR_MAGIC_N;
#endif
return(mtr);
}
这个方法只是对mtr_struct数据结构的初始化。
代码逻辑拿到初始化好的mtr可进行相关操作。对页操作前先获取锁,然后push到mtr。
UNIV_INLINE void mtr_memo_push(
mtr_t* mtr, /* in: mtr */
void* object, /* in: object */
ulint type) /* in: object type: MTR_MEMO_S_LOCK, ... */
{
dyn_array_t* memo;
mtr_memo_slot_t* slot;
ut_ad(object);
ut_ad(type >= MTR_MEMO_PAGE_S_FIX);
ut_ad(type <= MTR_MEMO_X_LOCK);
ut_ad(mtr);
ut_ad(mtr->magic_n == MTR_MAGIC_N);
memo = &(mtr->memo);
slot = dyn_array_push(memo, sizeof(mtr_memo_slot_t));
slot->object = object;
slot->type = type;
}
mtr_commit
void mtr_commit(mtr_t* mtr)
{
ut_ad(mtr);
ut_ad(mtr->magic_n == MTR_MAGIC_N);
ut_ad(mtr->state == MTR_ACTIVE);
if (mtr->modifications) {
mtr_log_reserve_and_write(mtr);
}
mtr_memo_pop_all(mtr);
if (mtr->modifications) {
log_release();
}
dyn_array_free(&(mtr->memo));
dyn_array_free(&(mtr->log));
}
1.如果modifications为true则将transaction产生的日志写入到redolog buf中。在redo log恢复过程中也要启动事务,但是不需要再写redo log。
写入的时候需要持有log_sys->mutex
2.mtr_memo_pop_all方法调用mtr_memo_slot_release释放所有的latch。
3.释放log_sys->mutex
mtr事务操作流程
在开启一个mini transaction时,会初始化mtr对象中的m_log和m_memo成员,设置m_state为active。
mtr_t::start
|
|-> 初始化mtr.m_impl->m_log日志管理对象
|
|-> 初始化mtr.m_impl->m_memo锁管理对象
| m_log和m_memo都是mtr_buf_t,以block_t节点m_node域构建的双向链表
|
|-> m_log_mode=MTR_LOG_ALL(记录所有的数据变更) & m_state=MTR_STATE_ACTIVE
提交一个mini transaction的过程比较复杂,大致流程是先将m_log中的日志写入公共log buffer,再将m_memo中的加锁并且发生修改的脏page加入flush list,最后释放m_memo中的所有锁。
公共log buffer是按照log block格式存储的(包含12B的header和4B的trailer,详见前文中的日志块结构),每个log block大小为512B,并且持久化时以512B进行对齐。每个log block中能存储日志内容的空间为512-12-4=496B。
公共log buffer有个原子变量log.sn,其统计的是公共buffer中曾经存储过的日志内容的大小。通过sn可以很容易计算出对应的lsn,其统计的是公共buffer中曾经存储过的以log block格式的日志量的大小。 lsn = (sn / 496 * 512 + sn % 512 + 12)
公共log buffer是个循环buffer,其中有三个重要的位点log.write_lsn,log.sn对应的lsn,log.buf_limit_sn对应的lsn。其中log.write_lsn表示已写入磁盘的日志位点(不要求flush),log.sn对应的lsn表示已占位待拷贝的日志位点,log.buf_limit_sn对应的lsn表示可以占位的最大日志位点。满足log.write_lsn <= log.sn对应的lsn <= log.buf_limit_sn对应的lsn。
将m_log中的日志写入公共log buffer:
- 根据日志数m_n_log_recs是否为1,来判断是single log还是multiple log。对于single log,在日志的开头的日志类型字段中增加MLOG_SINGLE_REC_FLAG。而对于multiple log,在日志结尾增加1B的MLOG_MULTI_REC_END。
- 在公共log buffer中使用原子变量log.sn进行日志占位。
- 在往已占位的日志空间中拷贝日志前,有以下两种情况需要等待:
- 若当前的log.sn位点被SN_LOCKED锁定,则要等待log.sn_locked 超过占位前的log.sn。当公共log buffer需要在线变更大小的时候,会进行SN_LOCKED加锁。
- 若日志写入速度过快,来不及写磁盘,就会把log buffer占满,这时需要阻塞等待日志的写磁盘。
- 将m_log动态buffer拷贝到公共log buffer,是按照512B大小的buffer粒度进行拷贝的:
- 若日志长度超过log block剩余大小,则要做截断,并增加tail和新的header,以满足log block格式
- 若写到log buffer的结尾(默认大小为16M),要继续转向log buffer开头继续拷贝。由于log buffer大小是log block的倍数,所以这里不需要再次做截断。
- 每个buffer拷贝完成后触发一次log.recent_written的Link_buf更新(详见前文),log.recent_written记录完成拷贝的最大连续日志的lsn
- 当m_log日志都写完,要检查已写入的日志是否横跨log block,若横跨了,则要在结尾的log block的header的LOG_BLOCK_FIRST_REC_GROUP字段中标识新mtr的位点end_lsn。
将m_memo中的加锁并且发生修改的脏page加入flush list:
- 遍历m_memo动态buffer中的每个buffer中的每个锁对象mtr_memo_slot_t
- 若是page锁,且该page发生了修改,则将该page加入flush list
- 触发一次log.recent_closed的Link_buf更新,log.recent_closed记录添加到flush list的最大连续日志的lsn
以下是详细流程图:
mtr_t::commit
|
|-> mtr_t::Command
|
(m_n_log_recs>0 || m_modifications)
|
|-> (yes)
| v
| Command::execute 将mtr.m_impl->m_log写入公共log buffer,把脏页加入flush list
| |
| |-> prepare_write
| | |
| | |-> 若 mtr.m_impl->m_log_mode为 MTR_LOG_NO_REDO或MTR_LOG_NONE,则直接返回
| | |
| | |-> 若 mtr.m_impl->m_n_log_recs==1,则 m_log.front()->begin()|=MLOG_SINGLE_REC_FLAG,在日志头Type字段中标识,
| | 否则 m_log->push(MLOG_MULTI_REC_END),在日志结尾附加1B
| |
| |-> log_buffer_reserve 在公共log buffer中为日志预留空
| | |
| | |-> log_buffer_s_lock_enter_reserve
| | | |
| | | |-> 对 log.pfs_psi加 s-lock
| | | |
| | | |-> log.sn.fetch_add(mtr.m_impl->m_log.m_size) 在公共的log buffer中占位
| | | |
| | | |-> log_buffer_s_lock_wait 若log.sn被SN_LOCKED,则等待log.sn_locked 超过占位前的log.sn
| | |
| | |-> log_translate_sn_to_lsn 将日志内容的偏移量log.sn 转为log block格式的偏移量start_lsn,start_lsn可以唯一表示日志在log block和公共log buffer中的位置
| | |
| | |-> log_wait_for_space_after_reserving 若end_sn > log.buf_limit_sn,则等待
| |
| |-> mtr_write_log_t(mtr.m_impl->m_log.m_list) 将日志内容拷贝至预留的空间
| | |
| | (loop mtr_buf_t::block in m_list) 将mtr.m_impl->m_log中的日志按block粒度拷贝到公共log buffer
| | |
| | |-> log_buffer_write 以log block的 start_lsn%OS_FILE_LOG_BLOCK_SIZE位置的数据 拷贝到公共log buffer的 start_lsn%log.buf_size位置
| | | |
| | | |-> left = OS_FILE_LOG_BLOCK_SIZE - LOG_BLOCK_TRL_SIZE - offset 若日志长度超过log block剩余大小,则要做截断
| | | |
| | | |-> lsn_diff = left + LOG_BLOCK_TRL_SIZE + LOG_BLOCK_HDR_SIZE 若log block写满,要增加tail和新的header
| | | |
| | | |-> 若公共log buffer被写满,则下次从开头继续写。因为每个mtr的日志在解析时大小就不超过2M,肯定不会超过公共log buffer的大小16M
| | | |
| | | |-> log_block_set_first_rec_group 在新header中设置 LOG_BLOCK_FIRST_REC_GROUP为0
| | |
| | |-> log_buffer_set_first_record_group 若mtr日志都写完且 mtr开头和结尾不在同一个log block中,则在新header中设置 LOG_BLOCK_FIRST_REC_GROUP为 end_lsn
| | |
| | |-> log_buffer_write_completed 每个block拷贝完成后均触发一次Link_buf(并查集)的更新,log.recent_written记录完成拷贝的最大连续日志的lsn
| | |
| | |-> log.recent_written.add_link_advance_tail 在recent_written->m_links的slot中记录当前日志的end_lsn,m_tail表示已拷贝到log buffer连续日志的end_lsn
| | | |
| | | |-> 若m_tail为当前日志的start_lsn,则推进m_tail为当期日志的end_lsn
| | | |
| | | |-> 否则recent_written->m_links[start_lsn%capacity] = end_lsn,并推进m_tail
| | | v
| | | log.recent_written.advance_tail_until 等到log.recent_written.m_tail推进到最大lsn
| | | |
| | | |-> 若recent_written->m_links[m_tail%capacity] > m_tail,则使用cas更改recent_written->m_links[m_tail%capacity] = m_tail 来排他访问
| | | |
| | | |-> (loop next_position) 推进m_tail为此刻连续的最大lsn,即使没推进到当前日志,其它help线程会帮忙推进
| | |
| | |-> 若log.recent_written.m_tail > log.current_ready_waiting_lsn,则os_event_set(log.closer_event)
| |
| |-> add_dirty_blocks_to_flush_list(mtr.m_impl->m_memo) 将mtr锁管理中记录的脏页加入flush list
| | |
| | (reverse loop mtr_buf_t::block in m_memo)
| | v
| | (reverse loop mtr_memo_slot_t in block)
| | |
| | |-> add_to_flush 为了去掉flush_order_mutex,把mtr对应的脏页无序的添加到flush list,在做checkpoint时, 无法保证flush list 上面最头的page lsn是最小的
| | v
| | add_dirty_page_to_flush_list 把修改后的page加入flush list,当mtr_memo_slot_t.type为MTR_MEMO_PAGE_X_FIX或MTR_MEMO_PAGE_SX_FIX,
| | | 或为MTR_MEMO_BUF_FIX,且mtr_memo_slot_t.object->made_dirty_with_no_latch
| | v
| | buf_flush_note_modification(mtr_memo_slot_t.object)
| |
| |-> log_buffer_close 将mtr锁管理中记录的脏页处理完后触发一次Link_buf更新,log.recent_closed记录添加到flush list的最大连续日志的lsn
| | 以log.recent_closed.m_tail的lsn来做checkpoint肯定是安全的,
| v
| log_buffer_s_lock_exit_close
| |
| |-> 对 log.pfs_psi解锁 s-lock
| |
| |-> log.recent_closed.add_link_advance_tail
|
|-> Command::release_all
| |
| |-> Release_all(mtr.m_impl->m_memo) 释放mtr持有的锁
|
|-> Command::release_resources -> clean mtr.m_impl->m_log & m_memo















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











