










什么是代价估计器
代价估计器(Cost Estimates)是Cost-Based Optimizer(简称CBO)中关键的一个组件。简单来说,它的作用是评估对于一个表使用某种Access Path获取数据时,在磁盘IO,CPU上的cost。数据库支持的Access Path,IO,CPU代价计算其实与数据库的存储引擎特性关系紧密。也因此,虽然代价估计器是优化器的一个关键组件,但具体实现时却会与存储引擎有着更加紧密的联系。
下图描述了优化器的基本结构,可以看到代价估计器虽然服务于Optimizer,但其实确实相对独立的一个组件。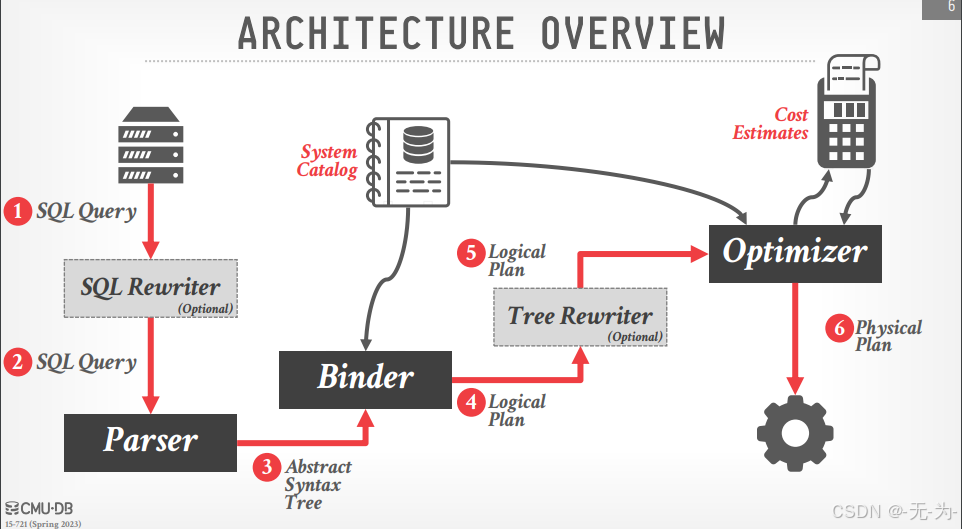
数据库优化器架构图
Access Path
接下来,我们来说一下什么是表的Access Path。
创建一个简单的表,其中id是主键,并且我们在col1建立有二级索引:
CREATE TABLE t1 (id INT PRIMARY KEY, col1 INT, col2 INT, KEY index_col1 (col1))ENGINE=InnoDB;对于一条最简单的单表查询语句:
SELECT * FROM t1 where t1.col1 < 5;它从逻辑上来说很简单,就是想要找到t1.col1小于5的所有记录。然而,如何从表中获取数据呢?至少可以有以下方案:
- 查主键索引,全表遍历一遍,然后过滤出t1.col1 <5的记录。
- 查col1上建立的二级索引,找到t1.col1 <5的记录对应的主键,然后根据得到的主键再去主键索引上查找完整记录。
可以发现,这两种方式都能达到逻辑上一致的效果,但它们访问了哪些数据,访问方式确实完全不同的。因此,我们称对每个表获取数据的实际执行方式为是这个表的Access Path。当确定了所有表的Access Path后,也就获得了这条查询的Physcal Plan。而可能存在多种Physcal Plan获得的记录在逻辑上是完全一样的,也因此说它们其实都对应同一种Logical Plan。
那么,这两种Access Path孰优孰劣呢?
我们来看两种情况:
表中只有一万条记录,且这些记录都满足t1.col1 <5。
- 使用第一种Access Path,需要在主键索引上全表扫描一遍即可。
- 使用第二种Access Path,需要在二级索引上全表扫描一遍,并且每个记录都需要从主键索引上回一遍表。
显然第一种更优。
表中有一万条记录,且只有其中一条记录满足t1.col1 <5。
- 使用第一种Access Path,需要在主键索引上全表扫描一遍即可。
- 使用第二种Access Path,需要在二级索引上扫描,但只会得到一条记录,对这条记录再从主键索引查找完整记录即可。
显然第二种更优。
从这个例子可以发现,实际哪种Access Path更优是与数据强相关的。并不是说我在WHERE子句中指明了一条与二级索引相关的谓词(Predicate)就必须选择二级索引。
从以上分析,我们可以有一些发现:
- Access Path是与存储引擎相关的。因为我们使用的是InnoDB引擎,而InnoDB是索引组织表,因此才会存在走二级索引需要回表。
- 同一个Logical Plan对应的不同Access Path,谁更优秀在不知道数据分布下,是无法直接判断的。这也证明代价估计器存在的必要性。
接下来我们将按照源码+案例的方式进行代价估计器浅析,源码基于MySQL 8.0.34版本。
源码解读
在MySQL中,有关代价估计的代码主要集中在两个函数中:bool JOIN::estimate_rowcount()和bool Optimize_table_order::choose_table_order()中。
bool JOIN::estimate_rowcount()会对每个表估计每种Access Path能够获得的行数以及对应的cost(从之前我们举的例子可以看出行数估计的重要性)。在这个函数中,只会考虑当这个表作为第一个读到的表时可行的Access Path。
bool Optimize_table_order::choose_table_order()是通过某种搜索算法计算不同JOIN ORDER下,每个表的最佳Access Path和对应的cost。在这个函数中,表可以通过JOIN condition来拓展出新的Access Path。
本文主要解读bool JOIN::estimate_rowcount()中有关单表代价估计的代码,而对于优化多表JOIN查询语句时的JOIN reorder算法不涉及,在之后的文章中回对这部分详细介绍。
bool JOIN::estimate_rowcount()
在该函数中,会对所有参与JOIN的表计算它们作为第一个表时可行的Access Path和对应的cost。
为了理解这个函数,可以先看一个简单例子:
select * from t1, t2 where t1.key1 = t2.key2 and t1.key1 < 15;这是两个表进行JOIN的SQL语句,JOIN condtion是t1.key1 = t2.key2。其中对于表t1还有t1.key1 < 15的过滤条件。
那么假设第一个读到的表是t1,则有两种可行的Access Path:
- 全表扫描
- 在t1.key1上扫描,获得小于15的记录
假设第一个读到的表是t2,则也有两种可行的Access Path:
- 全表扫描
- 在t2.key1上扫描,获得小于15的记录
这个函数的作用对每个表就是找到所有的可行的单表Access Path,因此这个函数的大致逻辑也就十分简单,
for each table:
for each Access Path:
if (Access Path can be applied):
calculate the rowcount and cost遍历每个表,遍历每种存储引擎支持的Access Path,判断是否可以应用这种Access Path,如果可以,则计算rowcount和cost。
到这里,我们就知道这个函数的关键其实是遍历所有可行的Access Path,因此,接下来的代码解读将按照Access Path进行分类解读。
system/const
这类Access Path的特点是查询结果只有一条记录。可能是表只有一行(对应system)或者在该表上有主键/唯一索引的点查(对应const),这类查询会被提前处理不参与JOIN reorder,cost为固定值1,rowcount也为1。
if (tab->type() == JT_SYSTEM || tab->type() == JT_CONST) {
// rows:1,cost:1
trace_table.add("rows", 1)
.add("cost", 1)
.add_alnum("table_type",
(tab->type() == JT_SYSTEM) ? "system" : "const")
.add("empty", tab->table()->has_null_row());
// Only one matching row and one block to read
// 设置找到记录数1
tab->set_records(tab->found_records = 1);
// 设置read_time为一次索引查询的的最差值
tab->worst_seeks = tab->table()->file->worst_seek_times(1.0);
tab->read_time = tab->worst_seeks;
continue;
}
小结:
行数:1
cost:1
Table Scan
这类Access Path其实就是全表扫描,由于InnoDB是索引组织表,因此其实也是扫描主键索引。
首先会从统计信息中获得这个表有多少条记录,这个统计信息是有存储引擎维护的,对于InnoDB而言,行数的统计信息是不准确的(因为MVCC和事务隔离,其实也无法获得准确的行数统计)。
ha_rows records = table->file->stats.records;
if (!records) records++; /* purecov: inspected */
double scan_time =
cost_model->row_evaluate_cost(static_cast<double>(records)) + 1;
// 全表扫描的cost
Cost_estimate cost_est = table->file->table_scan_cost();
// 固定的IO开销(修正量)
cost_est.add_io(1.1);
// 将evaluate的cost添加到CPU cost中
cost_est.add_cpu(scan_time);将每一条记录从InnoDB中读出来后需要进行evaluate,也会产生大量CPU cost,scan_time就描述了这项cost,计算公式也非常简单:m_row_evaluate_cost * records,行数 * 每条记录evaluate的cost,进行evaluate主要是消耗CPU资源,因此scan_time会记录到CPU cost中。
全表扫描会带来IO cost,计算公式是:
文件页数 * 读取每个page的cost
= 聚簇索引页数 * 读取每个page的cost
= 聚簇索引页数 * (内存中page的比例 * 读取内存中page的cost + on-disk的page的比例 * 读取on-disk的page的cost)在MySQL中,具体的计算代码如下:
stat_clustered_index_size * page_read_cost(1.0)
将IO cost加入到最终的cost中。
需要注意的是,为了让优化器不倾向于全表扫,MySQL给全表扫的cost添加了2.1的固定修正值
小结:
行数:stats.records
cost:scan的io cost + evaluate的cpu cost + io cost修正值(1.1) + scan cost修正值(1)
Covering Index
当某个二级索引包含的列包括了查询想要的所有列时,可以通过扫描二级索引来减少IO cost。这里所说的覆盖索引仅指全表扫描时检索二级索引代替检索主键索引。
if (!table->covering_keys.is_clear_all()) {
// 寻找最短的,能够包含查询想要的所有列的index
int key_for_use = find_shortest_key(table, &table->covering_keys);
// find_shortest_key() should return a valid key:
assert(key_for_use != MAX_KEY);
// 计算在这个index上scan的cost
Cost_estimate key_read_time = param.table->file->index_scan_cost(
key_for_use, 1, static_cast<double>(records));
// 和table scan一样,需要计算evaluate的cost
key_read_time.add_cpu(
cost_model->row_evaluate_cost(static_cast<double>(records)));
bool chosen = false;
// 如果小于table scan的cost,则将这种Access Path设为最佳
if (key_read_time < cost_est) {
cost_est = key_read_time;
chosen = true;
}
Opt_trace_object trace_cov(trace, "best_covering_index_scan",
Opt_trace_context::RANGE_OPTIMIZER);
trace_cov.add_utf8("index", table->key_info[key_for_use].name)
.add("cost", key_read_time)
.add("chosen", chosen);
if (!chosen) trace_cov.add_alnum("cause", "cost");
} 整个代码也很简单,就是先获得最短的索引,然后计算做index_scan的cost。计算index_scan的cost公式如下:
索引页数 * 读每个索引页的cost
= (记录数 + 每页多少记录 - 1 ) / 每页多少记录 * 读每个索引页的cost
= 记录数 + 每页多少记录 - 1 ) / 每页多少记录 + 内存中索引页的比例 * 读内存页的cost + on-disk索引页的比例 * 读on-disk页的cost)
每页多少记录
= 页大小 / (二级索引key的长度 + 主键长度)
= (记录数 / (页大小 / (二级索引key的长度 + 主键长度))* 读每个索引页的costMySQL中具体的公式可以看Cost_estimate handler::index_scan_cost,这个函数的大致逻辑就是上述公式所示。
小结:
行数 :stats.records
cost:index scan的io cost + evaluate的cpu cost
Group Range
这种Access Path主要针对有GROUP子句,并且SELECT中存在例如MIN或者MAX的聚合函数。简单举个例子:
select key_part1, key_part2, min(key_part3) from t1 where key_part2 = 1 group by key_part1;针对这条SQL,就可以使用Group Range的Access Path,生成GroupIndexSkipScanIterator的执行器。在执行时,会先根据key_part1和key_part2定位到一个区间,然后只读这个区间的key_part3的第一条记录和最后一条记录即可完成查询,所以这其实是一种针对GROUP BY和MIN/MAX聚合函数特殊优化的Skip Scan。
针对这种Access Path的cost计算比较复杂,在这里就不放公式了,只是简单描述一下。
首先,需要计算有多少个group,估计有多少group就需要一个统计信息records_per_key:每个key会有多少条记录(这个统计信息在InnoDB中非常重要,Cardinality其实也是从这个统计信息来的)。以上述SQL为例,通过看key_part1的records_per_key值,使用表的总行数 / 每个key_part1会有多少条记录就可以记录出有多少个group(其实也就是key_part1的 Cardinality)。然后,通过该值计算出要读多少页,这个计算公式就很麻烦了,因为还需要考虑key_part2的等值条件会不会造成读到的页有overlap,一个group的数据能占多少页,对key_part3的MIN/MAX是否都有等因素。知道了要读多少页之后,就可以按照table scan一样计算IO cost。
除此之外,还需要考虑在B+树上检索的CPU cost,这项cost会与树的高度有关。最后,还有对获取的每条记录进行 evaluate cost。
可以发现,这种Scan的方式有可能会减少IO cost,但却会因为在B+树上做检索加大CPU cost。因此是否选择这种Access Path的关键就是减少的IO cost和加大的CPU cost哪个更大。
// 对Group Range记录Optimizer Trace
if (group_path) {
DBUG_EXECUTE_IF("force_lis_for_group_by", group_path->cost = 0.0;);
param.table->quick_condition_rows =
min<double>(group_path->num_output_rows(), table->file->stats.records);
Opt_trace_object grp_summary(trace, "best_group_range_summary",
Opt_trace_context::RANGE_OPTIMIZER);
if (unlikely(trace->is_started()))
trace_basic_info(thd, group_path, ¶m, &grp_summary);
if (group_path->cost < best_cost) {
grp_summary.add("chosen", true);
best_path = group_path;
best_cost = best_path->cost;
} else
grp_summary.add("chosen", false).add_alnum("cause", "cost");
}
小结:
行数:用于GROUP BY语句的key的Cardinality
cost:skip scan的io cost + evaluate的cpu cost + 遍历B+树的cost
Skip Scan
这种Access Path也是能够跳过一些记录。也举个例子:
select key_part1, key_part2, key_part3 from t1 where key_part3 > 10;针对这条SQL,虽然是在key_part3上有过滤条件,但其实不用对这个索引做完整的scan。可以对每一组key_part1,key_part2定位到一个区间开始处,然后再从该区间的key_part3 > 10的记录处开始scan。可以发现,这种scan方式可以跳过所有对key_part3 <= 10记录的scan。
这种Access Path的cost计算其实和Group Range是十分相似的。简单也说,也是比较Skip Scan带来的IO cost减少能不能弥补在做B+树检索时的CPU cost。
以上面这个SQL为例,能够获取的行数可以通过key_part1, key_part2的records_per_key来估计,而key_part3 <= 10所占总数据的比例是通过condition filter给出一个估计值,如果有在key_part1这列上建有直方图,能给出一个较精确的值,否则就是一个固定值。
// 对Skip Scan记录Optimizer Trace
if (skip_scan_path) {
param.table->quick_condition_rows = min<double>(
skip_scan_path->num_output_rows(), table->file->stats.records);
Opt_trace_object summary(trace, "best_skip_scan_summary",
Opt_trace_context::RANGE_OPTIMIZER);
if (unlikely(trace->is_started()))
trace_basic_info(thd, skip_scan_path, ¶m, &summary);
if (skip_scan_path->cost < best_cost || force_skip_scan) {
summary.add("chosen", true);
best_path = skip_scan_path;
best_cost = best_path->cost;
} else
summary.add("chosen", false).add_alnum("cause", "cost");
}
小结:
行数:range数 * 每个range有多少记录
cost:skip scan的io cost + evaluate的cpu cost + 遍历B+树的cost
Index Range Scan
Index Range Scan其实是最常见的Access Path。这种Access Path其实就是使用单一索引去获取满足该索引过滤条件的记录。但这里有两个需要明确一下:单一索引,是指这种方式至多检索一个二级索引(有可能会回表读主键索引);满足该索引过滤条件,指获得的记录其实是查询希望获得的记录的超集,因此,后续还需对记录进行过滤得到真正满足所有过滤条件的记录。
在介绍这种Access Path之前,需要首先介绍一种数据结构:SEL_TREE。
SEL_TREE的作用其实很直观,对于WHERE子句中的复杂过滤条件,其实可以理解为在某个索引上的一个个子区间,在检索时,只需要获得索引上处于这些子区间的记录即可。因此,我们需要将复杂的过滤条件结构化为一个个子区间,这样才能够便于后续的行数和代价估计。在这里,我们通过一个例子来看SEL_TREE这个数据结构,以下面SQL为例:
select * from t1 where (kp1 < 1 and kp2 = 5 and (kp3 = 10 or kp3 = 12)) or (kp1 = 2 and (kp3 = 11 or kp3 = 14)) or (kp1 = 3 and (kp3 = 11 or kp3 = 14));最终会生成下述SEL_TREE:

SEL_TREE结构
我们用以下特点去描述SEL_TREE:
- SEL_TREE中keys数组指向了针对不同key的SEL_ROOT。
- SEL_ROOT指向一个key的一个key_part的不同区间构成红黑树,不同区间是OR关系。
- 红黑树按照区间进行排序。
- 每个结点的next_key_part指向下一个key_part的红黑树,不同key_part之间是AND关系。
这个图其实就是对AND/OR关系进行了结构化的图,通过这个图,我们就获得查询感兴趣的记录在index上的区间表示。
在MySQL中,用analyzing_range_alternatives来指代Index Range Scan。get_key_scans_params()函数的作用就是利用之前获得SEL_TREE获得最佳的Index Range Scan的Access Path。
Opt_trace_object trace_range_alt(trace, "analyzing_range_alternatives",
Opt_trace_context::RANGE_OPTIMIZER);
AccessPath *range_path = get_key_scans_params(
thd, ¶m, tree, false, true, interesting_order,
skip_records_in_range, best_cost, needed_reg);
get_key_scans_params()函数的逻辑也非常清晰,用伪代码表示如下:
for each key in SEL_TREE:
calculate rowcount and cost:
if (cost < best_cost):
update Access Path实际的MySQL代码如下:
AccessPath *get_key_scans_params(THD *thd, RANGE_OPT_PARAM *param,
SEL_TREE *tree, bool index_read_must_be_used,
bool update_tbl_stats,
enum_order order_direction,
bool skip_records_in_range,
const double cost_est, Key_map *needed_reg) {
...
// 遍历每个索引
for (idx = 0; idx < param->keys; idx++) {
key = tree->keys[idx];
if (key) {
ha_rows found_records;
Cost_estimate cost;
uint mrr_flags = 0, buf_size = 0;
uint keynr = param->real_keynr[idx];
if (key->type == SEL_ROOT::Type::MAYBE_KEY || key->root->maybe_flag)
needed_reg->set_bit(keynr);
// 判断读这个索引是否需要回表
bool read_index_only =
index_read_must_be_used
? true
: (bool)param->table->covering_keys.is_set(keynr);
Opt_trace_object trace_idx(trace);
trace_idx.add_utf8("index", param->table->key_info[keynr].name);
bool is_ror_scan, is_imerge_scan;
// 获取需要读多少行以及cost
found_records = check_quick_select(
thd, param, idx, read_index_only, key, update_tbl_stats,
order_direction, skip_records_in_range, &mrr_flags, &buf_size, &cost,
&is_ror_scan, &is_imerge_scan);
...
if (found_records != HA_POS_ERROR && thd->opt_trace.is_started()) {
Opt_trace_array trace_range(&thd->opt_trace, "ranges");
...
// 如果index dive被跳过则不计算cost
/// No cost calculation when index dive is skipped.
if (skip_records_in_range)
trace_idx.add_alnum("index_dives_for_range_access",
"skipped_due_to_force_index");
else
trace_idx.add("index_dives_for_eq_ranges",
!param->use_index_statistics);
trace_idx.add("rowid_ordered", is_ror_scan)
.add("using_mrr", !(mrr_flags & HA_MRR_USE_DEFAULT_IMPL))
.add("index_only", read_index_only)
.add("in_memory", cur_key.in_memory_estimate());
if (skip_records_in_range) {
trace_idx.add_alnum("rows", "not applicable")
.add_alnum("cost", "not applicable");
} else {
trace_idx.add("rows", found_records).add("cost", cost);
}
}
if ((found_records != HA_POS_ERROR) && is_ror_scan) {
tree->n_ror_scans++;
tree->ror_scans_map.set_bit(idx);
}
// 根据cost决定是否选择这个index range scan方式,并且记录Optimizer Trace
if (found_records != HA_POS_ERROR &&
(read_cost > cost.total_cost() ||
/*
Ignore cost check if INDEX_MERGE hint is used with
explicitly specified indexes or if INDEX_MERGE hint
is used without any specified indexes and no best
index is chosen yet.
*/
(force_index_merge &&
(!use_cheapest_index_merge || !key_to_read)))) {
...
} else {
...
}
}
}
// 生成Access Path
...
return path;
}在这里,我们重点说一下对于Index Range Scan是如何计算行数的,先前的行数计算基本都是来自于统计信息中保存的records和records_per_key,而Index Range Scan使用一种能够更精确获得行数的方法:Index Dive。
在给定在某个index上的一个区间后,可以通过InnoDB提供的接口
ha_rows ha_innobase::records_in_range(keynr, min_key, max_key)来估计在第keynr个索引中,min_key到max_key之间的记录数。这个函数的大致原理就是通过在B+树上对min_key和max_key进行检索,根据在B+树上的两条搜索路径来估计之间有多少条记录,一般来说,当min_key和max_key之间的区间记录数过多时,估计是不精确的,当min_key和max_key之间记录数较少,最终落到同一个B+树叶子结点上时,估计是精确的。
通过Index Dive的方式估计行数明显是十分耗时的,在MySQL中,可以通过eq_range_index_dive_limit参数来控制优化过程中,用Index Dive方式来估计单点区间内记录数的次数。
当Index Dive不可用时,MySQL还是使用records_per_key统计信息来估计行数。
最后就是cost计算,Index Range Scan的cost需要根据是否需要回表分别计算;
不需要回表:
根据读取到的行数来计算得到需要读取到页数,再用页数乘以读取每页产生的IO cost,这部分计算流程与覆盖索引的cost计算相同(实际上,也调用的是同一个函数):
需要读取索引页数 * 读每个索引页的cost
= (需要读取的记录数 + 每页多少记录 - 1) / 每页多少记录 * 读每个索引页的cost最后,再加上evaluate的cost和0.01的CPU cost修正值。
小结:
行数:使用统计信息或者Index Dive方式来估计区间内有多少条记录
cost:读取索引页的IO cost + evaluate的cpu cost + 0.01 (修正值)
需要回表:
当需要回表时,cost其实主要在每次回表,因此IO cost按照如下公式计算:
(rows + ranges) * 读每个聚簇索引页的cost最后,再加上evaluate的cost
小结:
行数:使用统计信息或者Index Dive方式来估计区间内有多少条记录
cost:回表产生的IO cost + evaluate的cpu cost
Roworder Intersect & Index Merge Union
前面提到的所有Access Path其实有一个共同点:最多访问一个二级索引。但其实有可能可以通过访问多个二级索引找到更好的Access Path。Roworder Intersect & Index Merge Union其实都是需要访问多个二级索引的Access Path。从他们的名字可以看出来,Roworder Intersect是检索多个二级索引后,将得到的记录主键取交集,再回表。Index Merge Union恰恰相反,是取并集。
举个简单的例子方便理解:
CREATE TABLE t1 (
id INT PRIMARY KEY,
col1 INT,
col2 INT,
KEY inedx_col1_id (col1, id),
KEY index_col2_id (col2, id)
) ENGINE=InnoDB;
# 1
SELECT * FROM t1 WHERE col1 = 1 OR col2 = 1;
#2
SELECT * FROM t1 WHERE col1 = 1 AND col2 = 1;第一条SQL可以使用Index Merge Union,在inedx_col1_id上获取到col1 =1的记录的主键,在index_col2_id获取到col1=2的记录的主键,然后再Merge得到主键集合,最后在主键索引上回表得到完整记录。
第二条SQL可以使用Roworder Intersect,在inedx_col1_id上获取到col1 =1的记录的主键,在index_col2_id获取到col1=2的记录的主键,然后取交集得到主键集合,最后在主键索引上回表得到完整记录。
讲到这里可以发现,Index Merge Union和Roworder Intersect都依赖一个取交集或者取并集的集合操作,但想要实现这个集合操作并不是很简单的。首先需要分类讨论的就是:从各个索引上获取到的记录是不是按照主键有序的?如果是,那么无论取交集和取并集都很简单,就是一个多路归并。如果不是,就还需要额外的排序。在MySQL中,对一个索引上的Scan返回的记录是按照主键有序的称为Rowid-Ordered Retrieval(ROR)。对一个index scan是否是ROR的判定也很简单,假设有主键索引 <a1,a2,...,aM,b1,b2,...,bk> 二级索引 <kp1,kp2,...,kpN,a1,a2,...,aM> ,那么只要我的SQL存在一个从 kp1=c1,kp2=c2,...,kpN=cN,[a1=cN+1,...] 的过滤条件,那么在该二级索引上得到的记录其实按照主键有序的,这个scan也就是ROR scan。
Roworder Intersect和Index Merge Union的cost计算也很复杂,这里以Index Merge Union为例简单介绍一下,不做过多深入。
Index Merge Union的cost主要分为以下几部分(这里假设存在非ROR Scan,如果全是ROR Scan,cost计算会更简单):
- 多次Index Range Scan所产生的cost
- 如果存在聚簇索引上的Index Range Scan,则对于二级索引上的Index Range Scan得到的记录可以提前通过聚簇索引上的过滤条件进行去重,因此会有key比较的cost。
- 所有在二级索引上通过Index Range Scan得到的主键都需要用SortBuffer进行排序和去重,如果记录数过多,还涉及多个SortBuffer读写磁盘的产生IO cost和合并产生的CPU cost。
- 所有在二级索引上通过Index Range Scan得到的主键都需要回表,回表过程是一次在聚簇索引上的顺序随机读。
总结
以上就是MySQL优化器的所有单表Access Path的代价估计。本文介绍Access Path的顺序是依据MySQL源码中bool JOIN::estimate_rowcount()中对Access Path的枚举顺序 。在这篇文章中,其实还有很多相关的东西没有介绍清楚,例如:我们一直在说records_per_key之类的统计信息,那MySQL中关于统计信息是怎么维护的?Index Range Scan中提到的SEL_TREE具体是怎么生成的?等等问题。除此之外,MySQL优化器也还有相当多的内容,例如SQL的transform,JOIN reorder算法等。如果有时间,我会对MySQL优化器其他相关模块进行浅析。最后,本文有任何问题,也欢迎大家指出。
参考
index merge的数据结构和成本评估 – orczhou.com
https://15721.courses.cs.cmu.edu/spring2023/slides/16-optimizer1.pdf



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











