










概叙
科普文:Java基础之算法系列【一文搞懂哈希Hash、及其应用】_hash 方法无内存计算和内存计算的差别-CSDN博客
科普文:Java基础之算法系列【一文搞懂CRC32哈希、及其应用】_crc32.getvalue()的长度-CSDN博客
科普文:Java基础之算法系列【再哈希法(Rehashing):用SHA256+CRC32来手搓一个HashTable】-CSDN博客
科普文:Java基础之算法系列【升级版:再哈希法(Rehashing)+链地址法(Chaining):用SHA256+CRC32来手搓一个HashTable】-CSDN博客
前面把哈希相关的梳理了一遍,这里重点将常用哈希函数做一个汇总。
哈希算法的主要应用场景包括数据结构(如哈希表)、密码学(如消息摘要和数字签名)、数据完整性验证(如文件校验)等。
选择合适的哈希算法时,需要考虑应用场景、性能需求、冲突处理等因素。
算法的速度取决于具体的实现和应用场景, 但通常来说,简单的哈希函数(如BKDRHash, APHash, DJBHash等)会比复杂的加密哈希函数(如MD5, SHA系列)更快。
这是因为简单的哈希函数通常使用较少的位运算和更简单的逻辑,而复杂的加密哈希函数则涉及更多的数学运算和安全性考虑。
- 简单散列:加权和,移位,异或等操作。
- 散列函数:MD5, SHA-1, SHA-256等。
- 哈希算法:如MurmurHash, FNV等。
哈希算法的主要应用场景
哈希算法的主要应用场景包括数据结构(如哈希表)、密码学(如消息摘要和数字签名)、数据完整性验证(如文件校验)等。
选择合适的哈希算法时,需要考虑应用场景、性能需求、冲突处理等因素。希望以上信息能帮助您更好地理解和应用字符串转哈希的常用算法。
常用字符串转Hash的算法
字符串转哈希的常用算法在信息安全、数据结构和密码学等领域中有着广泛的应用。
字符串转Hash(哈希)的常用算法有多种,每种算法都有其特点和适用场景。
以下是一些常用的字符串转Hash的算法:
-
MD5(Message Digest Algorithm 5):
- 是一种广泛使用的Hash算法,可以将任意长度的字符串映射为128位的Hash值。
- 安全性较高,但由于其长度固定且算法公开,存在被暴力破解的风险。
- 适用于需要校验数据完整性的场景。
-
SHA-1(Secure Hash Algorithm 1):
- 是一种比MD5更安全的Hash算法,可以将任意长度的字符串映射为160位的Hash值。
- 安全性较高,但由于其长度固定且算法公开,也存在被暴力破解的风险。
- 适用于需要较高安全性的场景,如数字签名。
-
SHA-256:
- 是SHA-1的继任者,可以将任意长度的字符串映射为256位的Hash值。
- 安全性更高,适用于需要高安全性的场景,如密码存储和验证。
-
CRC(Cyclic Redundancy Check):
- 是一种用于检测数据传输或存储中错误的算法,也可以用于字符串转Hash。
- 不同的CRC算法使用不同的多项式和参数,可以生成不同长度的Hash值。
- 适用于需要校验数据完整性的场景。
-
自定义Hash算法:
- 根据具体需求,可以设计自定义的Hash算法。
- 自定义算法可以灵活控制Hash值的长度、计算速度和碰撞率。
- 适用于需要特殊处理的场景,如分布式系统中的数据分布。
-
hashCode()方法:
- 在Java等编程语言中,Object类提供了hashCode()方法,用于返回对象的哈希码。
- 对于字符串来说,这个方法可以根据字符串的内容生成一个整数哈希值。
- 适用于需要快速比较字符串是否相等的场景,但生成的哈希值范围有限,且可能存在哈希碰撞。
-
BKDRHash、APHash、DJBHash等:
- 这些是常见的字符串Hash算法,各有其特点和适用场景。
- 例如,BKDRHash在编码实现和实际效果中表现突出,而APHash也具有较高的分布性。
- 适用于需要高效字符串Hash计算的场景。
在选择字符串转Hash的算法时,需要根据具体需求考虑算法的安全性、计算速度、Hash值长度和碰撞率等因素。同时,也需要注意算法的适用场景和限制条件。
工具类HashUtils
在编程中,字符串转hash是一个常见且重要的操作。
为了简化这一过程,我们可以创建一个工具类HashUtils,其中包含了多种常用的字符串转hash算法,如CRC、MD5、SHA系列(SHA-1、SHA-256等)、BKDR hash、APHash、DJB Hash、JSHash、RSHash、SDBM Hash、PJWHash和ELFHash。
这些字符串转哈希算法简介如下:
- BKDR Hash:以131为底的对数计算,适用于字符串哈希。
- APHash:通过加法、位操作和乘法计算哈希值,适用于字符串键的哈希表。
- DJB Hash:通过一系列位操作和加法计算哈希值,适用于快速哈希计算。
- JSHash:基于乘法哈希和加法哈希的混合算法,适用于字符串键的哈希表。
- RSHash:利用乘法哈希和异或操作计算哈希值,适用于字符串匹配。
- SDBM Hash:通过对字符串的字符值进行累加和模运算计算哈希值,适用于字符串去重。
- PJWHash:通过混合使用加法、位操作和乘法计算哈希值,适用于大量数据的哈希计算。
- ELFHash:通过位操作和加法计算哈希值,适用于字符串去重。
HashUtils中哪个算法最快?
在HashUtils中,算法的速度取决于具体的实现和应用场景,但通常来说,简单的哈希函数(如BKDRHash, APHash, DJBHash等)会比复杂的加密哈希函数(如MD5, SHA系列)更快。
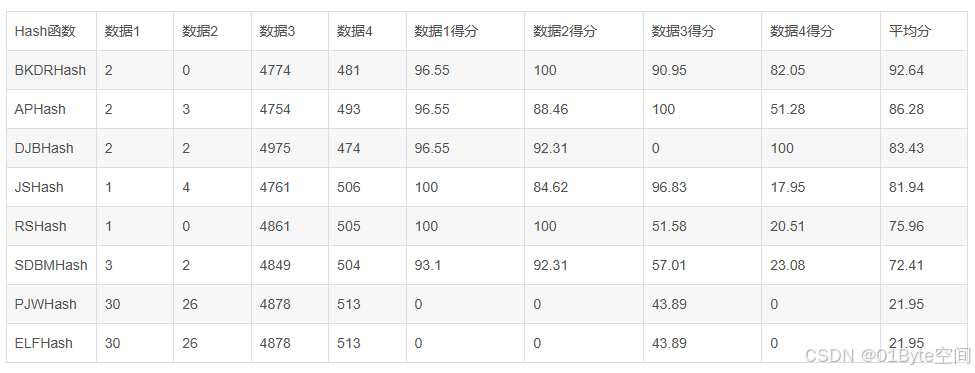
这是因为简单的哈希函数通常使用较少的位运算和更简单的逻辑,而复杂的加密哈希函数则涉及更多的数学运算和安全性考虑。
然而,速度并不是选择哈希函数的唯一标准。
在选择哈希函数时,还需要考虑哈希值的分布性、冲突率、安全性以及是否满足特定应用的需求。例如,MD5和SHA系列哈希函数虽然速度较慢,但它们提供了很高的安全性和低冲突率,适用于需要加密或安全性要求较高的场景。
对于HashUtils中的具体算法速度比较,可以参考相关评测数据或根据实际应用进行性能测试。
根据搜索结果中的一项评测,BKDRHash在实际效果和编码实现中效果突出,这可能意味着它在某些场景下具有较好的性能和较低的冲突率。但请注意,这并不意味着BKDRHash在所有场景下都是最快的或最适合的哈希函数。
因此,在选择HashUtils中的算法时,应根据具体需求和应用场景进行权衡和测试,以找到最适合的哈希函数。
HashUtils工具类
package com.zxx.study.algorithm.hash.crc;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.math.BigInteger;
import java.util.zip.Adler32;
import java.util.zip.CRC32;
/**
* 哈希算法的主要应用场景包括数据结构(如哈希表)、密码学(如消息摘要和数字签名)、数据完整性验证(如文件校验)等。
* 选择合适的哈希算法时,需要考虑应用场景、性能需求、冲突处理等因素。希望以上信息能帮助您更好地理解和应用字符串转哈希的常用算法。
*
* 在HashUtils中,算法的速度取决于具体的实现和应用场景,
* 但通常来说,简单的哈希函数(如BKDRHash, APHash, DJBHash等)会比复杂的加密哈希函数(如MD5, SHA系列)更快。
* 这是因为简单的哈希函数通常使用较少的位运算和更简单的逻辑,而复杂的加密哈希函数则涉及更多的数学运算和安全性考虑。
*
* 简单散列:加权和,移位,异或等操作。
* 散列函数:MD5, SHA-1, SHA-256等。
* 哈希算法:如MurmurHash, FNV等。
*
* CRC哈希系列:如CRC-8、CRC-16、CRC-32等。其中,CRC-32是最常用的一种,能够快速生成32位的Hash值,常用于数据库系统和数据传输中。因此CRC32快速但主要用于数据传输中的完整性校验。
* BKDR Hash:以131为底的对数计算,适用于字符串哈希。
* APHash:通过加法、位操作和乘法计算哈希值,适用于字符串键的哈希表。
* DJB Hash:通过一系列位操作和加法计算哈希值,适用于快速哈希计算。
* JSHash:基于乘法哈希和加法哈希的混合算法,适用于字符串键的哈希表。
* RSHash:利用乘法哈希和异或操作计算哈希值,适用于字符串匹配。
* SDBM Hash:通过对字符串的字符值进行累加和模运算计算哈希值,适用于字符串去重。
* PJWHash:通过混合使用加法、位操作和乘法计算哈希值,适用于大量数据的哈希计算。
* ELFHash:通过位操作和加法计算哈希值,适用于字符串去重。
* MurmurHash:MurmurHash是一种由Austin Appleby在2008年发明的非加密型哈希函数,以其快速计算和低碰撞率著称。MurmurHash算法基于混合和旋转两个核心思想,通过多个步骤将输入数据混合在一起,生成一个哈希值。具体过程包括初始化哈希值、分块哈希、混合哈希和最终哈希等步骤。
* FNV:FNVHash,全称为Fowler-Noll-Vo哈希算法,是一种非加密型哈希函数,由Glenn Fowler、Landon Curt Noll和Phong Vo在1991年提出。它以其简单、快速和良好的散列效果而闻名,适用于需要快速计算哈希值的场景,如数据去重、文件指纹生成等。FNVHash算法基于混合和旋转两个核心思想,通过多个步骤将输入数据混合在一起,生成一个哈希值。具体过程包括初始化哈希值、对每个数据块进行哈希计算、混合哈希值等步骤。
* FNVHash算法有三个版本:FNV-0(已废弃)、FNV-1和FNV-1a。其中,FNV-1a是推荐的版本,因为它在散列分布上表现更好。
* 双哈希:doubleHash双哈希,也称为双重哈希或再哈希法,是一种在哈希表中解决哈希冲突的策略。它通过使用两个不同的哈希函数来计算哈希值,从而在发生冲突时找到新的存储位置。这种方法能够有效地减少聚集现象,提高查找效率。
* 原理
* 哈希函数:将输入数据映射到哈希表中的一个索引位置。
* 冲突解决:当发生冲突时,使用第二个哈希函数生成一个新的探测步长,依次检查新的位置,直到找到一个空位。
* 优缺点
* 优点:减少冲突,使得哈希表中的空位分布更加均匀,提高查找效率。
* 缺点:需要设计多个有效的哈希函数,增加了实现复杂度。
*
* @author zhouxx
* @create 2025-01-04 19:23
*/
public class HashUtils {
// CRC8
public static byte crc8(String input) {
byte[] data = input.getBytes();
int crc = 0xFF;
for (byte b : data) {
crc ^= (b & 0xFF);
for (int i = 0; i < 8; i++) {
if ((crc & 0x80) != 0) {
crc = (crc << 1) ^ 0x07;
} else {
crc <<= 1;
}
crc &= 0xFF;
}
}
return (byte) crc;
}
// CRC16 (CRC-16/IBM)
public static short crc16(String input) {
byte[] data = input.getBytes();
int crc = 0xFFFF;
for (byte b : data) {
crc ^= (b & 0xFF);
for (int i = 0; i < 8; i++) {
if ((crc & 0x8000) != 0) {
crc = (crc << 1) ^ 0x8005;
} else {
crc <<= 1;
}
crc &= 0xFFFF;
}
}
return (short) crc;
}
// CRC32
public static long crc32(String input) {
CRC32 crc32 = new CRC32();
crc32.update(input.getBytes());
return crc32.getValue();
}
// CRC64 (Adler-32)
public static long crc64(String input) {
Adler32 adler32 = new Adler32();
adler32.update(input.getBytes());
return adler32.getValue();
}
/**
* MD5:生成128位的哈希值,速度快但不安全
* SHA-1:生成160位的哈希值,比MD5更安全,但同样存在安全漏洞,现已逐渐被淘汰。
* SHA-2:包括SHA-224、SHA-256、SHA-384和SHA-512等算法,生成不同长度的哈希值,安全性更高,广泛应用于密码学和数字签名等领域。
* SHA-3:是SHA-2之后的新一代安全散列算法,具有更高的安全性和抗碰撞性。
* SM3:SM3是中国国家密码管理局发布的密码散列函数标准,其安全性及效率与SHA-256相当。
*/
public static BigInteger securityHash(String input, MessageDigestName messageDigestName) {
try {
MessageDigest md = MessageDigest.getInstance(messageDigestName.getMessageDigestName());
byte[] messageDigest = md.digest(input.getBytes());
return new BigInteger(1, messageDigest);
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException(e);
}
}
public static BigInteger securityHash(String input) {
return securityHash(input, MessageDigestName.SHA256);
}
// BKDR Hash算法的实现
public static int bkdrHash(String input) {
int seed = 131; // 31 131 1313 13131 131313 etc..
int hash = 0;
for (int i = 0; i < input.length(); i++) {
hash = hash * seed + input.charAt(i);
}
return hash;
}
public static int bkdrHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// APHash算法的实现
public static int apHash(String input) {
int hash = 0;
for (int i = 0; i < input.length(); i++) {
if ((i & 1) == 0) {
hash = ((hash << 7) ^ input.charAt(i) ^ (hash >> 3));
} else {
hash = (~((hash << 11) ^ input.charAt(i) ^ (hash >> 5)));
}
}
return hash;
}
public static int apHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// DJB Hash
public static int djbHash(String input) {
int hash = 5381;
for (char c : input.toCharArray()) {
hash = ((hash << 5) + hash) + c;
}
return hash;
}
public static int djbHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// JSHash算法的实现
public static int jsHash(String input) {
int hash = 1315423911;
for (int i = 0; i < input.length(); i++) {
hash ^= ((hash << 5) + input.charAt(i) + (hash >> 2));
}
return hash;//
}
public static int jsHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// RSHash
public static int rsHash(String input) {
int hash = 0;
for (char c : input.toCharArray()) {
hash = (hash << 5) - hash + c;
}
return hash;
}
public static int rsHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// SDBM Hash
public static int sdbmHash(String input) {
int hash = 0;
for (char c : input.toCharArray()) {
hash = c + (hash << 6) + (hash << 16) - hash;
}
return hash;
}
public static int sdbmHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// PJWHash
public static int pjwHash(String input) {
int hash = 0;
int test = 0;
for (char c : input.toCharArray()) {
hash = (hash << 4) + c;
if ((test = hash & 0xF0000000) != 0) {
hash = ((hash ^ (test >> 24)) & 0x0FFFFFFF) ^ 0x9849AD34;
}
}
return hash;
}
public static int pjwHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
// ELFHash
public static int elfHash(String input) {
int hash = 0;
int x = 0;
for (char c : input.toCharArray()) {
hash = (hash << 4) + c;
if ((x = hash & 0xF0000000) != 0) {
hash ^= (x >> 24);
hash &= ~x;
}
}
return hash;
}
public static int elfHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
private static final int C1 = 0xcc9e2d51;
private static final int C2 = 0x1b873593;
private static final int R1 = 15;
private static final int R2 = 13;
private static final int M = 5;
private static final int N = 0xe6546b64;
//MurmurHash是一种由Austin Appleby在2008年发明的非加密型哈希函数,以其快速计算和低碰撞率著称。
//MurmurHash算法基于混合和旋转两个核心思想,通过多个步骤将输入数据混合在一起,生成一个哈希值。具体过程包括初始化哈希值、分块哈希、混合哈希和最终哈希等步骤。
//它适用于一般的哈希检索操作
public static int murmurHash(String input) {
byte[] bytes = input.getBytes();
int seed = 0;
int hash = seed;
for (int i = 0; i < bytes.length; i += 4) {
int k = getLittleEndian(bytes, i);
k *= C1;
k = Integer.rotateLeft(k, R1);
k *= C2;
hash ^= k;
hash = Integer.rotateLeft(hash, R2);
hash = hash * M + N;
}
hash ^= bytes.length;
hash ^= hash >>> 16;
hash *= 0x85ebca6b;
hash ^= hash >>> 13;
hash *= 0xc2b2ae35;
hash ^= hash >>> 16;
return hash;
}
public static int murmurHash(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
/**
* MurmurHash是一种非加密的哈希函数,以其高效和良好的散列分布特性而闻名。
* 它经常用于需要快速且冲突率较低的哈希计算的场景,如哈希表、数据库索引等。
*
* 以下是一个使用Java实现的MurmurHash3(32位版本)的示例代码
*
* murmurHash32方法接受一个字节数组key和一个种子值seed,并返回计算得到的32位MurmurHash3哈希值。
* main方法中提供了一个使用字符串作为输入的示例,它首先将字符串转换为字节数组,然后调用murmurHash32方法计算哈希值,并将结果打印到控制台。
*
* 请注意,MurmurHash有多个版本(如MurmurHash2、MurmurHash3的32位和64位版本等),并且每个版本都有其特定的实现细节和参数。
*
* */
private static final int SEED = 42; // 可以根据需要更改的种子值
public static int murmurHash32(byte[] key, int seed) {
int length = key.length;
int h = seed;
int roundedEnd = (length & ~0x3) + 4; // 计算最接近length且是4的倍数的数
for (int i = 0; i < roundedEnd - 4; i += 4) {
int k = ((key[i] & 0xff) << 24)
| ((key[i + 1] & 0xff) << 16)
| ((key[i + 2] & 0xff) << 8)
| (key[i + 3] & 0xff);
k *= 0xcc9e2d51;
k = (k << 15) | (k >>> 17);
k *= 0x1b873593;
h = k;
h = (h << 13) | (h >>> 19);
h = (h * 5) + 0xe6546b64;
}
// 处理剩余的字节(如果有的话)
switch (length % 4) {
case 3:
h = ((key[roundedEnd - 3] & 0xff) << 24)
| ((key[roundedEnd - 2] & 0xff) << 16)
| ((key[roundedEnd - 1] & 0xff) << 8);
h = 0x80000000;
h *= 0xcc9e2d51;
h = (h << 15) | (h >>> 17);
h *= 0x1b873593;
break;
case 2:
h = ((key[roundedEnd - 2] & 0xff) << 16)
| ((key[roundedEnd - 1] & 0xff) << 8);
h = 0x40000000;
h *= 0xcc9e2d51;
h = (h << 15) | (h >>> 17);
h *= 0x1b873593;
break;
case 1:
h = (key[roundedEnd - 1] & 0xff) << 8;
h = 0x20000000;
h *= 0xcc9e2d51;
h = (h << 15) | (h >>> 17);
h *= 0x1b873593;
break;
}
h = (length << 3);
h = h >>> 16;
h *= 0x85ebca6b;
h = h >>> 13;
h *= 0xc2b2ae35;
h = h >>> 16;
return h & 0xffffffff; // 确保结果是一个32位的无符号整数
}
public static int murmurHash32(String key) {
return murmurHash32(key.getBytes(), SEED);
}
private static int getLittleEndian(byte[] bytes, int offset) {
int value = (bytes[offset] & 0xff);
if (offset + 1 < bytes.length) {
value |= ((bytes[offset + 1] & 0xff) << 8);
}
if (offset + 2 < bytes.length) {
value |= ((bytes[offset + 2] & 0xff) << 16);
}
if (offset + 3 < bytes.length) {
value |= ((bytes[offset + 3] & 0xff) << 24);
}
return value;
}
/**
* FNVHash算法基于混合和旋转两个核心思想,通过多个步骤将输入数据混合在一起,生成一个哈希值。具体过程包括初始化哈希值、对每个数据块进行哈希计算、混合哈希值等步骤。FNVHash算法有三个版本:FNV-0(已废弃)、FNV-1和FNV-1a。其中,FNV-1a是推荐的版本,因为它在散列分布上表现更好。
* */
private static final int FNV_OFFSET_BASIS = 0x811c9dc5;
private static final int FNV_PRIME = 0x01000193;
// FNVHash算法基于混合和旋转两个核心思想,通过多个步骤将输入数据混合在一起,生成一个哈希值。具体过程包括初始化哈希值、对每个数据块进行哈希计算、混合哈希值等步骤。FNVHash算法有三个版本:FNV-0(已废弃)、FNV-1和FNV-1a。其中,FNV-1a是推荐的版本,因为它在散列分布上表现更好。
// FNVHash,全称为Fowler-Noll-Vo哈希算法,是一种非加密型哈希函数,由Glenn Fowler、Landon Curt Noll和Phong Vo在1991年提出。它以其简单、快速和良好的散列效果而闻名,适用于需要快速计算哈希值的场景,如数据去重、文件指纹生成等。
public static int fnv1(String input) {
byte[] bytes = input.getBytes();
int hash = FNV_OFFSET_BASIS;
for (byte b : bytes) {
hash *= FNV_PRIME;
hash ^= b & 0xff;
}
return hash;
}
public static int fnv1a(String input) {
byte[] bytes = input.getBytes();
int hash = FNV_OFFSET_BASIS;
for (byte b : bytes) {
hash ^= b & 0xff;
hash *= FNV_PRIME;
}
return hash;
}
public static int fnv1(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
public static int fnv1a(int hash) {
return hash & 0x7FFFFFFF;//消除负数
}
/**
* FNV-1 和 FNV-1a 是两种由 Glenn Fowler, Landon Curt Noll, 和 Phong Vo 在 1991 年提出的非加密哈希函数,
* 它们以简单和快速而著称。FNV-1 是基础版本,而 FNV-1a 是对 FNV-1 的一个改进,主要区别在于对输入字节的处理方式。
*
* fnv1_32 方法实现了 FNV-1 32位哈希函数,而 fnv1a_32 方法实现了 FNV-1a 32位哈希函数。两者之间的主要区别在于处理每个字节时乘法和异或操作的顺序。在 FNV-1 中,先乘法后异或;而在 FNV-1a 中,先异或后乘法。
* 请注意,FNV 哈希函数虽然简单且快速,但它们不是加密哈希函数,不提供安全性保证,因此不适用于需要加密或安全哈希的场景。它们更适合用于需要快速哈希计算且对安全性要求不高的场合,如哈希表、快速查找等。
* */
// FNV-1 32位初始值
private static final int FNV1_32_INIT = 0x811c9dc5;
// FNV-1 32位质数
private static final int FNV1_32_PRIME = 0x01000193;
// FNV-1a 32位初始值
private static final int FNV1A_32_INIT = 0x811c9dc5;
// FNV-1a 使用的另一个质数(与FNV-1不同)
// 实际上,FNV-1a通常也使用与FNV-1相同的质数,但这里的实现为了区分,使用了一个不同的质数
// 这不是标准规定,只是为了展示区别
private static final int FNV1A_32_PRIME = 0x1e3779b9;
// FNV-1 32位哈希函数
public static int fnv1_32(byte[] data) {
int hash = FNV1_32_INIT;
for (byte b : data) {
hash *= FNV1_32_PRIME;
hash = b & 0xFF;
}
return hash;
}
// FNV-1a 32位哈希函数
public static int fnv1a_32(byte[] data) {
int hash = FNV1A_32_INIT;
for (byte b : data) {
hash = b & 0xFF;
hash *= FNV1A_32_PRIME;
}
return hash;
}
// 辅助方法,用于将字符串转换为字节数组并计算FNV-1哈希
public static int fnv1_32(String str) {
return fnv1_32(str.getBytes());
}
// 辅助方法,用于将字符串转换为字节数组并计算FNV-1a哈希
public static int fnv1a_32(String str) {
return fnv1a_32(str.getBytes());
}
//请注意,选择适当的质数和模数对于哈希函数的性能和冲突率至关重要
/**
* 定义了两个质数P1和P2,
* 以及两个模数MOD1和MOD2。
* singleHash方法用于计算字符串的单个哈希值,它接受字符串s、质数p和模数mod作为参数,并返回计算得到的哈希值。
* doubleHash方法则调用singleHash两次,分别使用不同的质数和模数来计算字符串的两个哈希值,并将它们作为一个二元组(数组)返回。
*
* */
//哈希基数: 选择两个不同的质数
private static final int P1 = 31;
private static final int P2 = 37;
//哈希模数: 选择两个不同的模数,通常是较大的质数
/**
* int类型的数据范围是-2^31 到 2^31-1,即-2147483648到2147483647。
* 在这个范围内,最大的两个质数分别是:
* 2147483647(这是int类型能表示的最大值,它本身也是一个质数)
* 2147483587(这是小于2147483647的最大的质数)
* */
private static final int MOD1 = 2147483587;
private static final int MOD2 = 2147483647;
// 计算字符串的单个哈希值
private static int singleHash(String s, int p, int mod) {
int hash = 0;
for (char c : s.toCharArray()) {
hash = (hash * p + c) % mod;
}
return hash;
}
// 计算字符串的双哈希值
public static int[] doubleHash(String s) {
return new int[]{singleHash(s, P1, MOD1), singleHash(s, P2, MOD2)};
}
}
执行结果:
package com.zxx.study.algorithm.hash.crc;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
/**
* @author zhouxx
* @create 2025-01-04 20:57
*/
public class Test {
// 主方法用于测试
public static void main(String[] args) {
String testString = "Hello, World!";
System.out.println("CRC8: " + HashUtils.crc8(testString));
System.out.println("CRC16: " + HashUtils.crc16(testString));
System.out.println("CRC32: " + HashUtils.crc32(testString));
System.out.println("CRC64: " + HashUtils.crc64(testString));
System.out.println("MD5: " + HashUtils.securityHash(testString,MessageDigestName.MD5));
System.out.println("SHA-1: " + HashUtils.securityHash(testString,MessageDigestName.SHA1));
System.out.println("SHA-256: " + HashUtils.securityHash(testString,MessageDigestName.SHA256));
System.out.println("SHA-512: " + HashUtils.securityHash(testString,MessageDigestName.SHA512));
System.out.println("BKDR Hash: " + HashUtils.bkdrHash(testString));
System.out.println("AP Hash: " + HashUtils.apHash(testString));
System.out.println("DJB Hash: " + HashUtils.djbHash(testString));
System.out.println("JS Hash: " + HashUtils.jsHash(testString));
System.out.println("RS Hash: " + HashUtils.rsHash(testString));
System.out.println("SDBM Hash: " + HashUtils.sdbmHash(testString));
System.out.println("PJW Hash: " + HashUtils.pjwHash(testString));
System.out.println("ELF Hash: " + HashUtils.elfHash(testString));
System.out.println("murmur Hash: " + HashUtils.murmurHash(testString));
//System.out.println("murmur32 Hash: " + HashUtils.murmurHash32(testString));
System.out.println("fnv1 Hash: " + HashUtils.fnv1(testString));
System.out.println("fnv1a Hash: " + HashUtils.fnv1a(testString));
System.out.println("fnv1_32 Hash: " + HashUtils.fnv1_32(testString));
System.out.println("fnv1a_32 Hash: " + HashUtils.fnv1a_32(testString));
System.out.println("double Hash: " + Arrays.toString(HashUtils.doubleHash(testString)));
/**
* CRC8: 85
* CRC16: -10048
* CRC32: 3964322768
* CRC64: 530449514
* MD5: 135128927216837525056571091452533082836
* SHA-1: 57326780443051672195294049065733477490599812609
* SHA-256: 101313441018496298855616188252934726526525012911655317211406949275718146758767
* SHA-512: 2896433859368351216030254251658037554450257777058785385848879478643702192412807262948475775832223447401819728165378517360531399240543248560696154074579847
* BKDR Hash: -1279654011
* AP Hash: 968846394
* DJB Hash: -1763540338
* JS Hash: -851087695
* RS Hash: 1498789909
* SDBM Hash: 167331861
* PJW Hash: -1828058379
* ELF Hash: 1542798529
* murmur Hash: -827966720
* fnv1 Hash: 1116842118
* fnv1a Hash: 1525479220
* fnv1_32 Hash: 33
* fnv1a_32 Hash: -450449191
* double Hash: [1498789909, 4052569]
*
* Process finished with exit code 0
* */
}
}


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











