










概叙
科普文:算法和数据结构系列【算法和数据结构概叙】-CSDN博客
科普文:算法和数据结构系列【排序算法:常见10种排序算法的原理、应用、以及java实现】-CSDN博客
前面梳理完10种排序算法,我们再看看常用的7种查找算法:线性查找、二分查找、二叉搜索树查找、插值查找、斐波那契查找、哈希查找、分块查找等。
7种查找算法
查找算法是在数据集合中查找某一特定元素的算法,是计算机科学中的一项基本操作。
不同的查找算法适用于不同的数据结构和应用场景,以下是几种常见的查找算法:
-
线性查找(Linear Search)
- 简介:线性查找是最基本的查找算法,它按照数据序列的顺序,逐个比较每个元素,直到找到目标元素或查找完整个序列。
- 特点:实现简单,但查找效率较低,特别是在数据量较大的情况下。
-
二分查找(Binary Search)
- 简介:二分查找是一种高效的查找算法,它要求数据必须是有序的。通过每次将查找范围缩小一半,可以快速定位目标元素或确定目标元素不存在。
- 特点:查找效率高,时间复杂度为O(log n),但要求数据必须是有序的。
-
二叉搜索树查找(Binary Search Tree Search)
- 简介:二叉搜索树查找是利用二叉搜索树数据结构实现的查找算法。二叉搜索树是一种特殊的二叉树,其中每个节点的左子树所有节点的值都小于该节点的值,右子树所有节点的值都大于该节点的值。
- 特点:平均查找效率高,时间复杂度为O(log n),但最坏情况下可能退化为O(n)(当树退化成链表时)。
-
插值查找(Interpolation Search)
- 简介:插值查找是一种改良版的二分查找算法。它根据要查找的值在有序数组中的大致位置进行估计,从而缩小搜索范围,提高查找效率。
- 特点:特别适用于有序且均匀分布的数据集,时间复杂度在最优情况下可以达到O(log log n),但在不均匀分布的数据上可能退化为线性查找。
-
斐波那契查找(Fibonacci Search)
- 简介:斐波那契查找是一种基于斐波那契数列的搜索算法。它利用斐波那契数列的特性,在有序序列中快速定位目标元素的位置。
- 特点:适用于有序序列,时间复杂度为O(log n),且不需要直接访问数组的中间元素,因此在某些情况下比二分查找更灵活。
-
哈希查找(Hash Table Search)
- 简介:哈希查找是利用哈希表数据结构实现的查找算法。它通过计算目标元素的哈希值,将元素映射到哈希表中的一个位置,从而实现快速查找。
- 特点:查找效率高,平均时间复杂度为O(1),但需要额外的空间来存储哈希表,且需要处理哈希冲突。
-
分块查找(Block Search)
- 简介:分块查找是顺序查找和二分查找的一种改进方法。它将数据序列分成若干块,块内元素无序,但块间有序。查找时先在索引表中进行查找,确定目标元素所在的块,然后在块内进行顺序查找。
- 特点:查找速度比顺序查找快,同时不需要对全部节点进行排序,但实现相对复杂,需要维护一个索引表。
7种查找算法对比
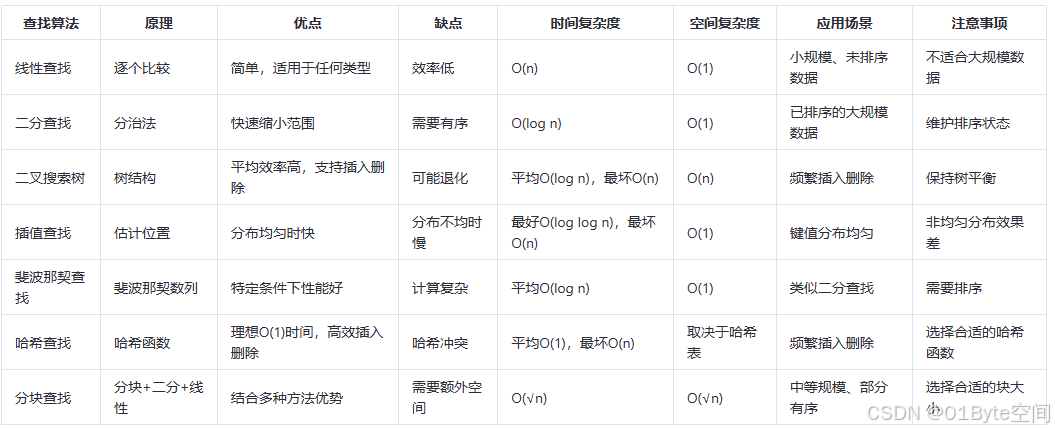
7种查找算法的性能排序(从高到低):
-
哈希查找(Hash Table Search)
- 平均时间复杂度:O(1)
- 特点:在理想情况下,哈希查找可以在常数时间内找到目标元素,是性能最高的查找算法之一。但需要额外的空间来存储哈希表,并需要处理哈希冲突。
-
二分查找(Binary Search)
- 时间复杂度:O(log n)
- 特点:二分查找要求数据必须是有序的,通过每次将查找范围缩小一半,可以快速定位目标元素。时间复杂度为对数级别,性能非常高效。
-
斐波那契查找(Fibonacci Search)
- 时间复杂度:O(log n)
- 特点:斐波那契查找利用斐波那契数列的特性,在有序序列中快速定位目标元素。时间复杂度与二分查找相似,但在某些情况下可能更快。
-
插值查找(Interpolation Search)
- 平均时间复杂度:O(log log n)
- 特点:插值查找是二分查找的改进版本,特别适用于有序且均匀分布的数据集。其性能优于二分查找,但要求数据分布均匀。
-
二叉搜索树查找(Binary Search Tree Search)
- 平均时间复杂度:O(log n)
- 特点:在平衡二叉搜索树中,查找效率与二分查找相似。但在不平衡的树中,查找效率可能退化为O(n)。
-
分块查找(Block Search)
- 平均时间复杂度:O(√n)
- 特点:分块查找将数据序列分成若干块,块内无序但块间有序。查找时先定位到块,再在块内查找,性能优于线性查找。
-
线性查找(Linear Search)
- 时间复杂度:O(n)
- 特点:线性查找逐个比较数据序列中的元素,直到找到目标元素或查找完整个序列。性能最低,适用于数据量较小或无法排序的情况。
请注意,上述性能排序是基于平均时间复杂度的理论比较。
在实际应用中,查找算法的性能还受到数据分布、数据结构的具体实现、硬件环境等多种因素的影响。因此,在选择查找算法时,需要综合考虑多种因素。
搜索前,排序的重要性:除了线性查找和哈希查找,其他五种查找算法,均要求有序;否则找不到数据。
public static void main(String[] args) {
//模拟产生100个待排序的数组
int[] arr = new int[10];
for (int i = 0; i < 10; i++) {
arr[i] = (int) (Math.random() * 8000); // 生成一个[0, 8000000) 数
}
int target=(int) (Math.random() * 8000);
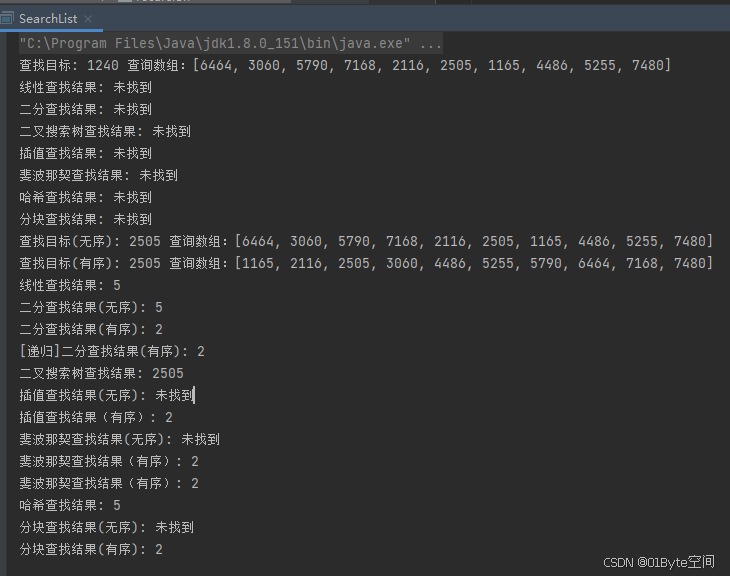
System.out.println("查找目标: " + target +" 查询数组:"+ Arrays.toString(arr));
int result = linearSearch(arr, target);
System.out.println("线性查找结果: " + (result != -1 ? result : "未找到"));
result = binarySearch(arr, target);
System.out.println("二分查找结果: " + (result != -1 ? result : "未找到"));
TreeNode treeNode = binarySearchTreeSearch(arr, target);
System.out.println("二叉搜索树查找结果: " + (treeNode != null ? treeNode.val : "未找到"));
result = interpolationSearch(arr, target);
System.out.println("插值查找结果: " + (result != -1 ? result : "未找到"));
result = FibonacciSearch.fibSearch(arr, target);
System.out.println("斐波那契查找结果: " + (result != -1 ? result : "未找到"));
result = hashSearch(arr, target);
System.out.println("哈希查找结果: " + (result != -1 ? result : "未找到"));
result = blockSearch(arr, 3, target);
System.out.println("分块查找结果: " + (result != -1 ? result : "未找到"));
// 查一定存在
target=arr[5];
System.out.println("查找目标(无序): " + target +" 查询数组:"+ Arrays.toString(arr));
int[] arr1=Arrays.copyOf(arr,arr.length);
SortList.bubbleSort(arr1);//排序
System.out.println("查找目标(有序): " + target +" 查询数组:"+ Arrays.toString(arr1));
result = linearSearch(arr, target);
System.out.println("线性查找结果: " + (result != -1 ? result : "未找到"));
result = binarySearch(arr, target);
System.out.println("二分查找结果(无序): " + (result != -1 ? result : "未找到"));
result = binarySearch(arr1, target);
System.out.println("二分查找结果(有序): " + (result != -1 ? result : "未找到"));
result = binarySearch1(arr1, target);
System.out.println("[递归]二分查找结果(有序): " + (result != -1 ? result : "未找到"));
treeNode = binarySearchTreeSearch(arr, target);
System.out.println("二叉搜索树查找结果: " + (treeNode != null ? treeNode.val : "未找到"));
result = interpolationSearch(arr, target);
System.out.println("插值查找结果(无序): " + (result != -1 ? result : "未找到"));
result = interpolationSearch(arr1, target);
System.out.println("插值查找结果(有序): " + (result != -1 ? result : "未找到"));
result = FibonacciSearch.fibSearch(arr, target);
System.out.println("斐波那契查找结果(无序): " + (result != -1 ? result : "未找到"));
result = FibonacciSearch.fibSearch(arr1, target);
System.out.println("斐波那契查找结果(有序): " + (result != -1 ? result : "未找到"));
result = fibonacciSearch(arr1, target);
System.out.println("斐波那契查找结果(有序): " + (result != -1 ? result : "未找到"));
result = hashSearch(arr, target);
System.out.println("哈希查找结果: " + (result != -1 ? result : "未找到"));
result = blockSearch(arr, 3, target);
System.out.println("分块查找结果(无序): " + (result != -1 ? result : "未找到"));
result = blockSearch(arr1, 3, target);
System.out.println("分块查找结果(有序): " + (result != -1 ? result : "未找到"));
}
7种查找算法总结
1. 线性查找(顺序查找)
顺序查找是最基本的查找算法,按照序列原有顺序对数组进行遍历比较查询。
//线性查找(顺序查找)
public static int linearSearch(int[] arr, int target) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == target) {
return i;
}
}
return -1; // 如果未找到目标值,返回-1
}- 原理:从数组的第一个元素开始,逐个与给定值进行比较,直到找到目标或遍历完整个数组。
- 优点:实现简单。适用于任何类型的列表。
- 缺点:效率低下,在最坏的情况下需要检查每个元素。
- 时间复杂度:O(n)
- 空间复杂度:O(1)
- 应用场景:数据集较小。未排序的数据集。
- 注意事项:不适合大规模数据的高效搜索、在数据量较大时,顺序查找的效率会非常低,应尽量避免使用 。
2. 二分查找
二分查找是一种高效的查找算法,前提是数据必须是有序的。
//二分查找
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {// todo 必须
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1; // 如果未找到目标值,返回-1
}
//二分查找:递归
public static int binarySearch1(int[] arr, int target) {
return binarySearch(arr,0,arr.length-1,target);
}
public static int binarySearch(int[] arr, int left, int right, int findVal) {
// 当 left > right 时,说明递归整个数组,但是没有找到
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (findVal > midVal) { // 向 右递归
return binarySearch(arr, mid + 1, right, findVal);
} else if (findVal < midVal) { // 向左递归
return binarySearch(arr, left, mid - 1, findVal);
} else {
return mid;
}
}- 原理:基于有序数组,每次都将待查区间分为两半,并确定下一步在哪个子区间继续查找。
- 优点:非常快速地缩小搜索范围。
- 缺点:要求输入必须是有序序列。
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
- 应用场景:已排序的大规模数据集。
- 注意事项:确保数组已经排序。对于动态变化的数据集,维护排序状态可能会消耗额外资源。
3. 二叉搜索树查找
二叉搜索树查找是利用二叉搜索树数据结构实现的查找算法,具有较高的查找效率。
//二叉搜索树查找:依赖二叉树数据结构
public static TreeNode binarySearchTreeSearch(int[] arr, int target) {
TreeNode root = null;
root= BinarySearchTree.insert(root,arr[0]);
for(int i=1;i<arr.length;i++){
BinarySearchTree.insert(root,arr[i]);
}
return BinarySearchTree.search(root, target);
}- 原理:利用二叉搜索树的性质(左子树的所有节点小于根节点,右子树的所有节点大于根节点)进行递归查找。
- 优点:平均情况下查找效率较高,为O(log n)。支持高效的插入和删除操作。
- 缺点:如果树不平衡,最坏情况下的查找效率可能退化到O(n)。
- 时间复杂度:平均O(log n),最坏O(n)
- 空间复杂度:O(n)
- 应用场景:频繁插入删除操作且支持快速查找的场合。
- 注意事项:保持树的平衡可以提高性能,如使用AVL树或红黑树。
4. 插值查找
二叉搜索树查找是利用二叉搜索树数据结构实现的查找算法,具有较高的查找效率。
//插值查找
public static int interpolationSearch(int[] arr, int target) {
int low = 0;
int high = arr.length - 1;
while (low <= high && target >= arr[low] && target <= arr[high]) {
if (low == high) {
if (arr[low] == target) {return low;}
return -1;
}
int pos = low + ((target - arr[low]) * (high - low)) / (arr[high] - arr[low]);
if (arr[pos] == target) {
return pos;
} else if (arr[pos] < target) {
low = pos + 1;
} else {
high = pos - 1;
}
}
return -1; // 如果未找到目标值,返回-1
}- 原理:改进版的二分查找,通过估计目标值的位置来选择分割点,而不是固定地取中间位置。
- 优点:对于分布均匀的数据可以更快定位到目标值附近。
- 缺点:如果数据分布不均,则可能比二分查找更慢。需要维护二叉搜索树的结构。
- 时间复杂度:最好情况下为O(log log n),最坏情况下退化至O(n)。
- 空间复杂度:O(1)
- 应用场景:键值分布较为均匀的情况。
- 注意事项:对非均匀分布的数据效果不佳。
5. 斐波那契查找
斐波那契查找是一种基于斐波那契数列的搜索算法。它利用斐波那契数列的特性,在有序序列中快速定位目标元素的位置。
//斐波那契查找
public static int fibonacciSearch(int[] arr, int target) {
// 获取大于或等于数组长度的最小的斐波那契数
int fibMMm2 = 0; // (m-2)'th Fibonacci No.
int fibMMm1 = 1; // (m-1)'th Fibonacci No.
int fibM = fibMMm2 + fibMMm1; // m'th Fibonacci
while (fibM < arr.length) {
fibMMm2 = fibMMm1;
fibMMm1 = fibM;
fibM = fibMMm2 + fibMMm1;
}
// 将数组扩展到斐波那契数的长度
int[] extendedArray = new int[fibM];
for (int i = 0; i < arr.length; i++) {
extendedArray[i] = arr[i];
}
for (int i = arr.length; i < fibM; i++) {
extendedArray[i] = arr[arr.length - 1]; // 填充最后一个元素
}
// 开始斐波那契查找
int offset = -1;
while (fibM > 1) {
int i = Math.min(offset + fibMMm2, arr.length - 1);
if (target < extendedArray[i]) {
fibM = fibMMm2;
fibMMm1 = fibMMm1 - fibMMm2;
fibMMm2 = fibM - fibMMm1;
} else if (target > extendedArray[i]) {
fibM = fibMMm1;
fibMMm1 = fibMMm2;
fibMMm2 = fibM - fibMMm1;
offset = i;
} else {
return Math.min(i, arr.length - 1); // 返回实际数组中的索引
}
}
// 如果未找到目标值,返回-1
if (fibMMm1 == 1 && extendedArray[offset + 1] == target) {
return Math.min(offset + 1, arr.length - 1);
}
return -1;
}- 原理:利用斐波那契数列作为索引间隔来进行跳跃式搜索。
- 优点:相比二分查找,在某些特定条件下性能更好。
- 缺点:计算过程稍微复杂一些。
- 时间复杂度:平均O(log n)
- 空间复杂度:O(1)
- 应用场景:类似于二分查找,但可以在某些特定类型的数据上提供更好的性能。
- 注意事项:同样需要数据预先排序。
6. 哈希查找
哈希查找是利用哈希表数据结构实现的查找算法。它通过计算目标元素的哈希值,将元素映射到哈希表中的一个位置,从而实现快速查找。
//哈希查找:依赖哈希表
public static int hashSearch(int[] arr, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < arr.length; i++) {
map.put(arr[i], i);
}
return map.getOrDefault(target, -1); // 如果未找到目标值,返回-1
}- 原理:通过哈希函数将键转换成固定范围内的索引来访问元素。
- 优点:理想情况下能够达到O(1)的时间复杂度。支持高效的插入和删除操作。
- 缺点:存在哈希冲突问题。设计良好的哈希函数较难。
- 时间复杂度:平均O(1),最坏O(n)
- 空间复杂度:取决于哈希表大小及负载因子
- 应用场景:需要频繁插入删除操作且支持快速查找的场合。
- 注意事项:合理设置哈希表大小以减少碰撞概率。选择合适的哈希函数至关重要。
解决冲突常用的手法
当两个不同的数据元素的哈希值相同时,就会发生冲突。
解决冲突常用的手法有2种:开放地址法、链接法
- 开放地址法:如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。
- 链接法(哈希表采用这种方法):将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
科普文:Java基础之算法系列【一文搞懂哈希Hash、及其应用】_哈希算法-CSDN博客
科普文:Java基础之算法系列【一文搞懂CRC32哈希、及其应用】_java中计算sha-3-CSDN博客
科普文:Java基础之算法系列【再哈希法(Rehashing):用SHA256+CRC32来手搓一个HashTable】-CSDN博客
科普文:Java基础之算法系列【升级版:再哈希法(Rehashing)+链地址法(Chaining):用SHA256+CRC32来手搓一个HashTable】-CSDN博客
7. 分块查找
分块查找是顺序查找和二分查找的一种改进方法。它将数据序列分成若干块,块内元素无序,但块间有序。查找时先在索引表中进行查找,确定目标元素所在的块,然后在块内进行顺序查找。
//分块查找
public static int blockSearch(int[] arr, int blockSize, int target) {
int n = arr.length;
int numBlocks = (n + blockSize - 1) / blockSize;
// 创建块的最大值数组
int[] maxOfBlock = new int[numBlocks];
for (int i = 0; i < n; i++) {
if (i % blockSize == 0) {
maxOfBlock[i / blockSize] = arr[i];
} else {
maxOfBlock[i / blockSize] = Math.max(maxOfBlock[i / blockSize], arr[i]);
}
}
// 在块的最大值数组中进行二分查找
int blockIndex = -1;
int left = 0;
int right = numBlocks - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (maxOfBlock[mid] >= target) {
blockIndex = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
if (blockIndex == -1) {
return -1;
}
// 在找到的块内进行线性查找
int start = blockIndex * blockSize;
int end = Math.min(start + blockSize - 1, n - 1);
for (int i = start; i <= end; i++) {
if (arr[i] == target) {
return i;
}
}
return -1; // 如果未找到目标值,返回-1
}- 原理:将数据分成多个小块,每个块内部有序。首先在块间进行二分查找,确定目标值所在的块,然后在该块内进行线性查找。
- 优点:结合了二分查找和线性查找的优点,减少了整体查找时间。
- 缺点:需要额外的空间存储块的最大值信息。
- 时间复杂度:O(√n)
- 空间复杂度:O(√n)
- 应用场景:中等规模的数据集。数据部分有序时。
- 注意事项:块的大小需要适当选择,以平衡查找时间和额外空间开销。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











