







一、图的入门
1.1 图的定义及分类
定义:图是由一组顶点和一组能够将两个顶点相连的边组成的
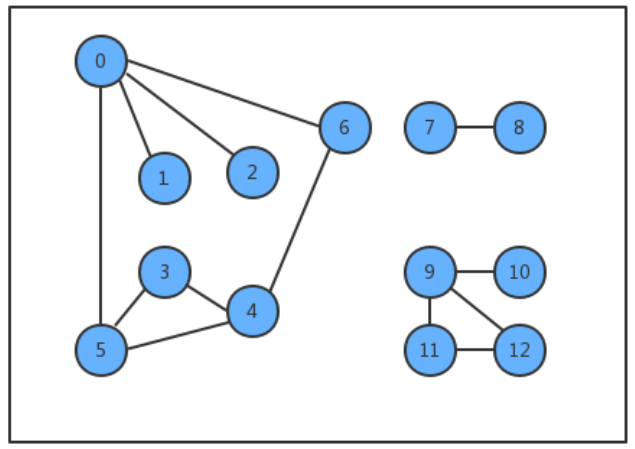
特殊的图:
- 自环:即一条连接一个顶点和其自身的边;
- 平行边:连接同一对顶点的两条边;
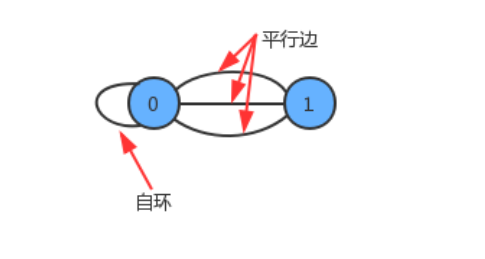
图的分类:
按照连接两个顶点的边的不同,可以把图分为以下两种:
- 无向图:边仅仅连接两个顶点,没有其他含义;
- 有向图:边不仅连接两个顶点,并且具有方向;
1.2 无向图
1.2.1 图的相关术语
相邻顶点:当两个顶点通过一条边相连时,我们称这两个顶点是相邻的,并且称这条边依附于这两个顶点。
度:某个顶点的度就是依附于该顶点的边的个数
子图:是一幅图的所有边的子集(包含这些边依附的顶点)组成的图;
路径:是由边顺序连接的一系列的顶点组成
环:是一条至少含有一条边且终点和起点相同的路径
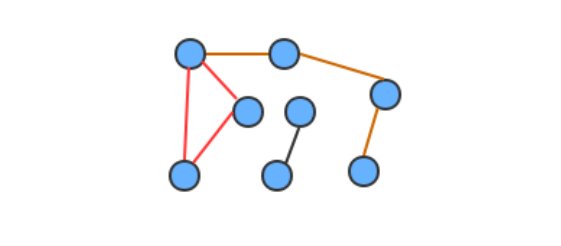
连通图:如果图中任意一个顶点都存在一条路径到达另外一个顶点,那么这幅图就称之为连通图
连通子图:一个非连通图由若干连通的部分组成,每一个连通的部分都可以称为该图的连通子图
1.2.2 图的存储结构
要表示一幅图,只需要表示清楚以下两部分内容即可:
- 图中所有的顶点;
- 所有连接顶点的边;
常见的图的存储结构有两种:邻接矩阵和邻接表
1.2.2.1 邻接矩阵
- 使用一个V*V的二维数组int[V] [V] adj,把索引的值看做是顶点;
- 如果顶点v和顶点w相连,我们只需要将adj[v] [w]和adj[w] [v]的值设置为1,否则设置为0即可。
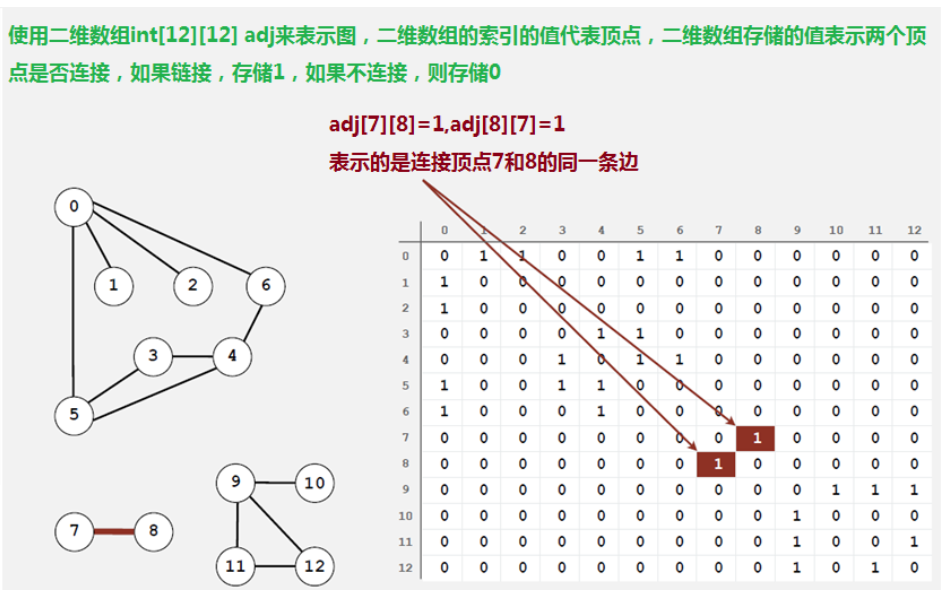
很明显,邻接矩阵这种存储方式的空间复杂度是V^2的,如果我们处理的问题规模比较大的话,内存空间极有可能不够用。
1.2.2.2 邻接表 (重点)
- 使用一个大小为V的数组 Queue[V] adj,把索引看做是顶点;
- 每个索引处adj[v]存储了一个队列,该队列中存储的是所有与该顶点相邻的其他顶点 。
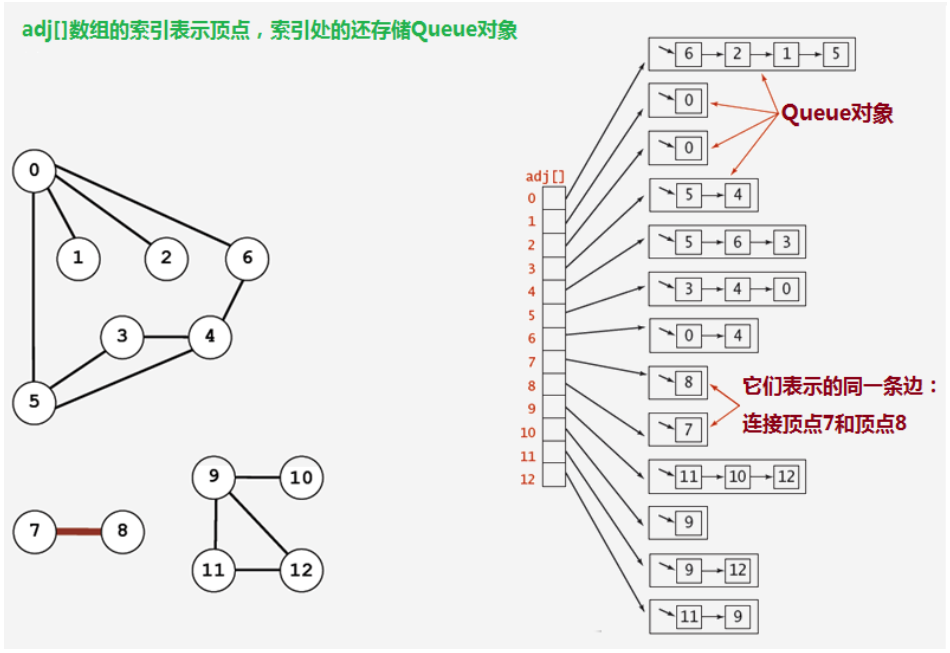
很明显,邻接表的空间并不是是线性级别的,所以后面我们一直采用邻接表这种存储形式来表示图,空间复杂度相较于邻接矩阵要小很多。
1.2.3 图的实现
1.2.3.1 图的API设计

1.2.3.2 代码实现
对图采用邻接表的方式实现
package Graph;
import LinkTable.Queue;
/**
* @author Fantic
* @create 2021-08-22 13:44
*/
public class Graph {
//图中顶点的数量
private final int V;
//图中边的数量
private int E;
//顶点对应的邻接表
private Queue<Integer>[] adj;
//初始化成员变量
public Graph(int V) {
//初始化顶点数量
this.V = V;
//初始化边的数量,刚开始图中顶点都没有相连为0
this.E = 0;
//初始化顶点的邻接表,每个顶点建立一个邻接表
this.adj = new Queue[V];
//初始化各邻接表中的内容,刚开始为空队列
for (int i = 0; i < adj.length; i++) {
adj[i] = new Queue<Integer>();
}
}
//获取顶点的数量
public int V(){
return V;
}
//获取边的数量
public int E(){
return E;
}
//像图中增加一条边v--m
public void addEdge(int v,int w){
//把w添加到v的队列中,顶点v就有一个相邻点w
adj[v].enqueue(w);
//把v添加到w的队列中,顶点w就有一个相邻点v
adj[w].enqueue(v);
//边的数量加1
E++;
}
//获取和顶点相邻的所有连接点
public Queue<Integer> adj(int v){
return adj[v];
}
}
1.2.4 图的搜索
在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求。有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法。
1.2.4.1 深度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找子结点,然后找兄弟结点。
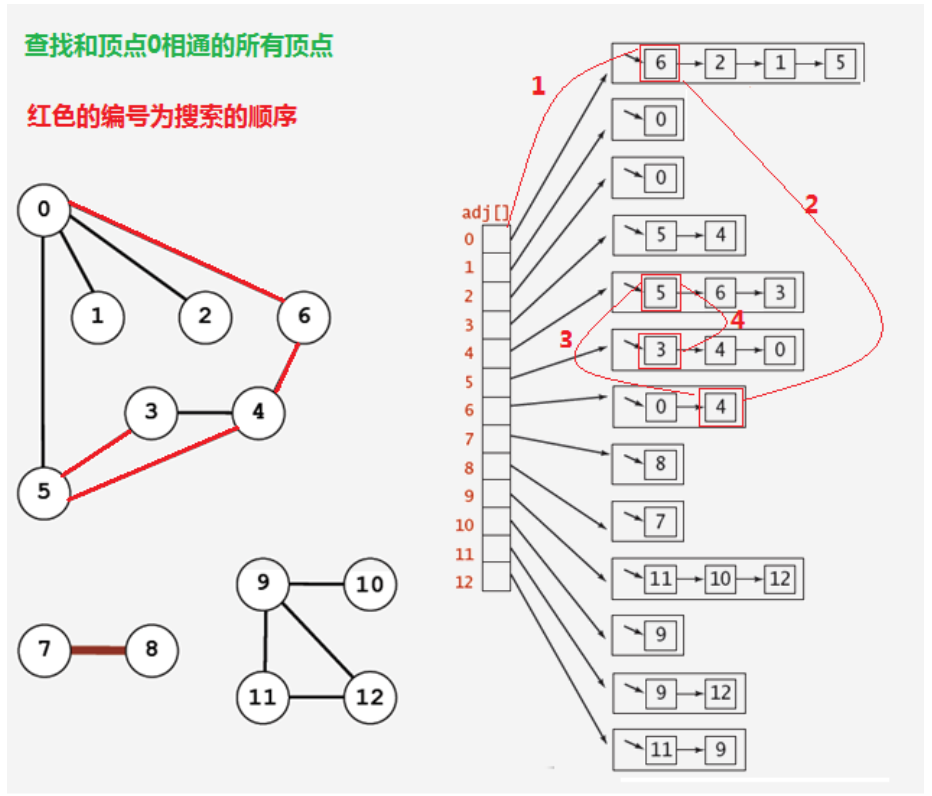
很明显,在由于边是没有方向的,所以,如果4和5顶点相连,那么4会出现在5的相邻链表中,5也会出现在4的相邻链表中,那么为了不对顶点进行重复搜索,应该要有相应的标记来表示当前顶点有没有搜索过,可以使用一个布尔类型的数组 boolean[V] marked,索引代表顶点,值代表当前顶点是否已经搜索,如果已经搜索,标记为true,如果没有搜索,标记为false;
API设计:

深度优先搜索代码实现
package Graph;
/**
* @author Fantic
* @create 2021-08-22 13:44
*/
public class DepthFirstSearch {
private int count;//记录有多少个顶点与s顶点相通
private boolean[] marked;//索引代表顶点,对应值表示当前顶点是否已经被搜索
//构建深度优先搜索对象,使用深度优先搜索找到G图中s顶点的所有相邻顶点,s顶点为深度优先搜索的起始顶点
public DepthFirstSearch(Graph G,int s) {
//创建一个和图顶点数一样大小的布尔数组,调用了图构成
this.marked = new boolean[G.V()];
//初始化与顶点s相通的顶点的数量
this.count = 0;
//搜素G图中与顶点s相同的所有顶点
dfs(G,s);
}
//使用深度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G,int v) {
//把当前顶点标记为已搜索顶点
marked[v] = true;
//遍历v顶点的邻接表,得到与v顶点连接的所有顶点w
for(Integer w : G.adj(v)){
//如果当前结点w没有被搜索过,则递归搜索与w顶点相同的其它顶点,以此类推
if (!marked[w]){
dfs(G,w);
}
}
//相同的顶点数+1
count++;
}
//判断w顶点与s顶点是否相同
public boolean marked(int w){
return marked[w];
}
//获取与顶点s相通的顶点的数量
public int count(){
return count;
}
}
1.2.4.2 广度优先搜索
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么==先找兄弟结点,然后找子结点==。
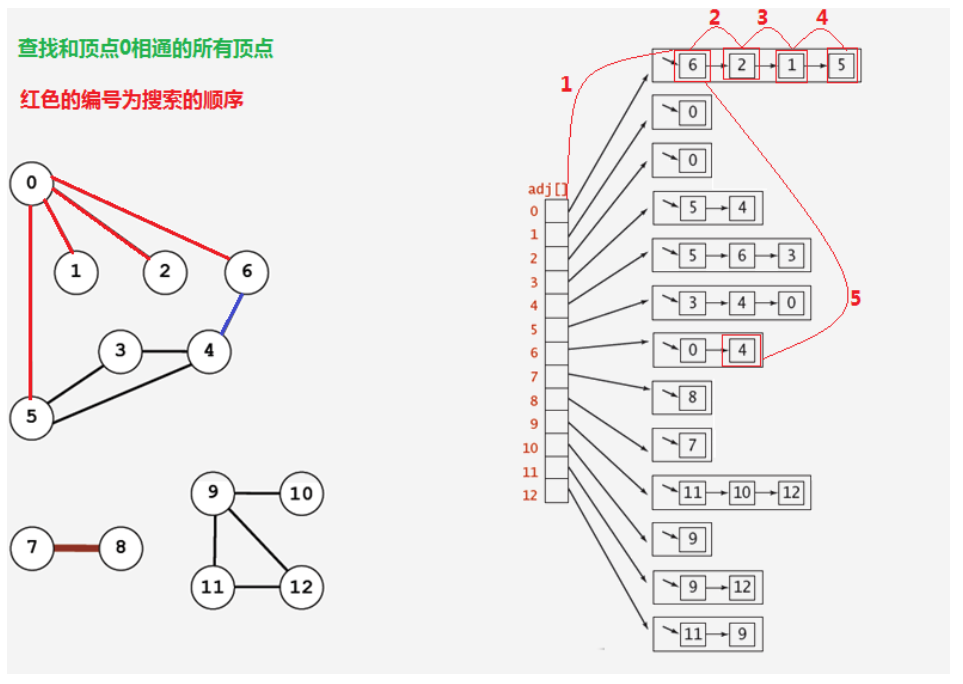
API设计:
广度优先搜索代码实现
package Graph;
import LinkTable.Queue;
/**
* @author Fantic
* @create 2021-08-22 13:45
*/
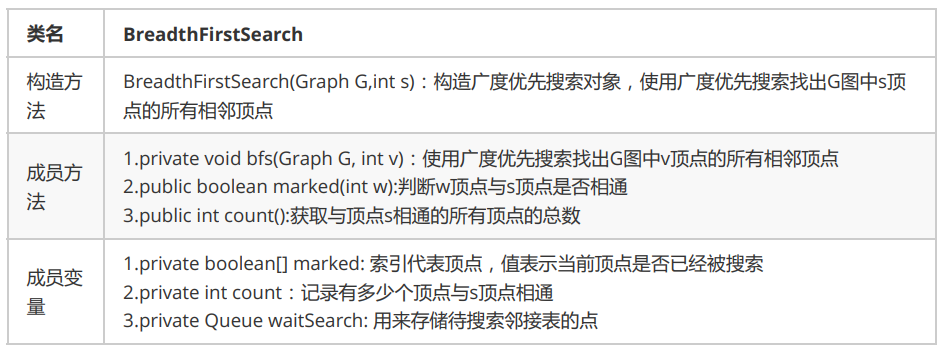
public class BreadthFirstSearch {
//索引代表当前顶点,对应的值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与顶点s相连通,s顶点为起始顶点
private int count;
//用来存储待搜索的邻接表的顶点
private Queue waitSearch;
//构造广度优先搜索对象,使用广度优先搜索做出G图中与s顶点的所有相邻顶点
public BreadthFirstSearch(Graph G,int v) {
//创建一个和图的顶点数一样的布尔数组
marked = new boolean[G.V()];
//初始化待搜索的顶点的队列
waitSearch = new Queue<Integer>();
//搜索与顶点s相同的所有顶点
bfs(G,v);
}
//使用广度优先搜索找出G图中v顶点的所有相邻顶点
private void bfs(Graph G,int v){
//把当前顶点v标记为已搜索
marked[v] = true;
//把当前顶点的v放入到队列中,等待搜索它的邻接表
waitSearch.enqueue(v);
//使用while循环从队列中拿出待搜索的顶点w,搜索其邻接表
while (!waitSearch.isEmpty()) {
Integer wait = (Integer) waitSearch.dequeue();
//如果当前顶点没有被搜索过,则递归搜索与w顶点相同的其它顶点
for (Integer w:G.adj(wait)){
if (!marked[w]){
//这一步可以使用递归也可以使用迭代
//递归
//bfs(G,w);
//迭代的方法
marked[w] = true;
waitSearch.enqueue(w);
count++;
}
}
}
//相同的顶点数+1
count++;
}
//判断w顶点与s顶点是否相连通
public boolean marked(int w){
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count() {
return count;
}
}
1.2.5 案例-畅通工程续
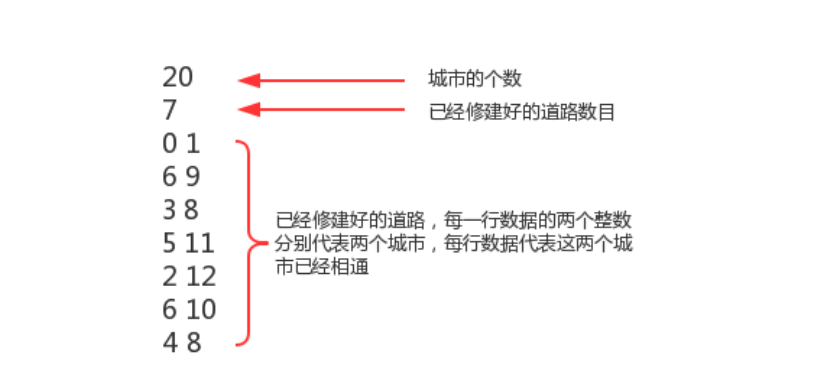
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。省政府“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。目前的道路状况,9号城市和10号城市是否相通?9号城市和8号城市是否相通?
在我们的测试数据文件夹中有一个trffic_project.txt文件,它就是诚征道路统计表,下面是对数据的解释:
解题思路:
- 创建一个图Graph对象,表示城市;
- 分别调用addEdge(0,1),addEdge(6,9),addEdge(3,8),addEdge(5,11),addEdge(2,12),addEdge(6,10),addEdge(4,8),表示已经修建好的道路把对应的城市连接起来;
- 通过Graph对象和顶点9,构建DepthFirstSearch对象或BreadthFirstSearch对象;
- 调用搜索对象的marked(10)方法和marked(8)方法,即可得到9和城市与10号城市以及9号城市与8号城市是否相通。
使用图实现畅通工程
package Graph;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 13:46
*/
public class Traffic_Project {
public static void main(String[] args) throws Exception {
//构建缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("traffic_project.txt"))));
//读取城市数目,初始化Graph图
int totalCity = Integer.parseInt(reader.readLine());
Graph graph = new Graph(totalCity);
//读取已经修建好的道路数量
int roadNumber = Integer.parseInt(reader.readLine());
//循环读取已经修建好的道路
for (int i = 0; i < roadNumber; i++) {
String line = reader.readLine();
String[] str = line.split(" ");
int p = Integer.parseInt(str[0]);
int q = Integer.parseInt(str[1]);
graph.addEdge(p,q);
}
//根据图G和顶点9构建的图搜索对象
DepthFirstSearch search = new DepthFirstSearch(graph, 9);
//BreadthFirstSearch search = new BreadthFirstSearch(graph, 9);
//调用搜索对象的mark()和marked(8)
boolean s1 = search.marked(10);
boolean s2 = search.marked(8);
System.out.println("9号城市和10号城市是否相同:" + s1);
System.out.println("9号城市和8号城市是否相同:" + s2);
}
}
1.2.6 路径查找
在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市。这类问题翻译成专业问题就是:从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径。
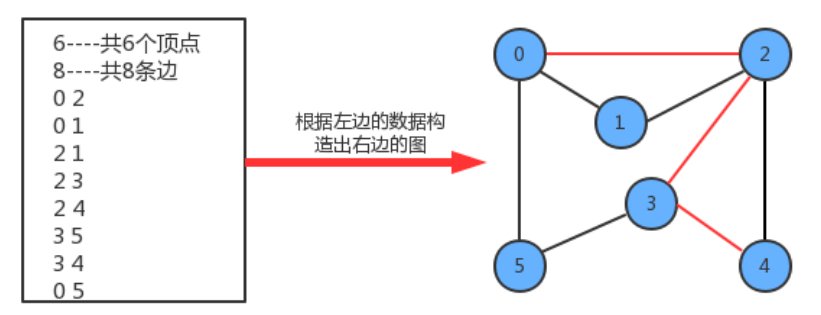
例如在上图上查找顶点0到顶点4的路径用红色标识出来,那么我们可以把该路径表示为 0-2-3-4。
1.2.6.1 路径查找API设计

1.2.6.2 路径查找实现
实现路径查找,最基本的操作还是得遍历并搜索图,所以,我们的实现暂且基于深度优先搜索来完成。其搜索的过程是比较简单的。我们添加了edgeTo[]整型数组,这个整型数组会记录从每个顶点回到起点s的路径。
如果我们把顶点设定为0,那么它的搜索可以表示为下图:
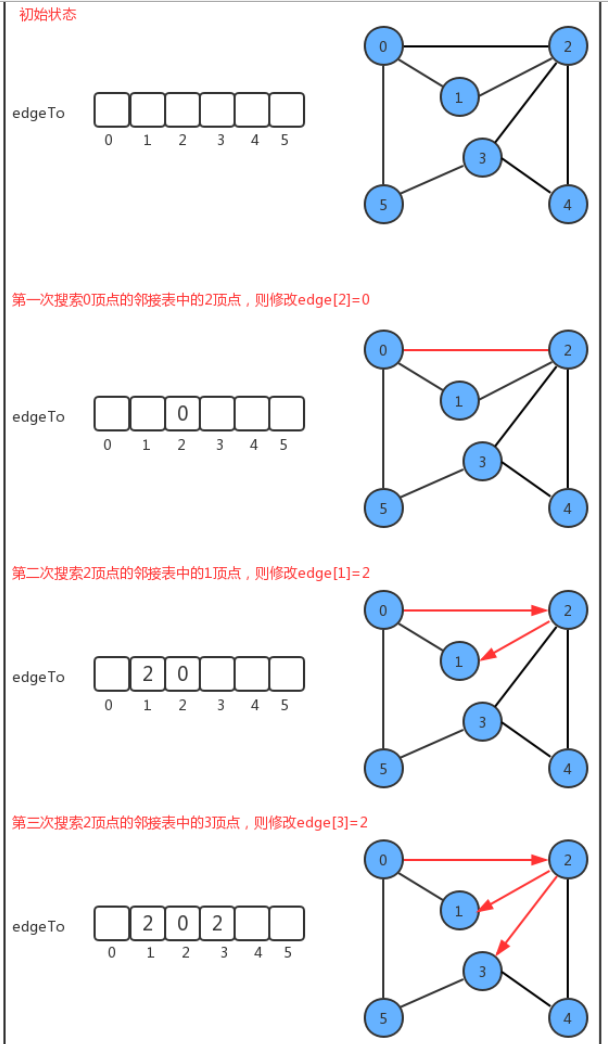
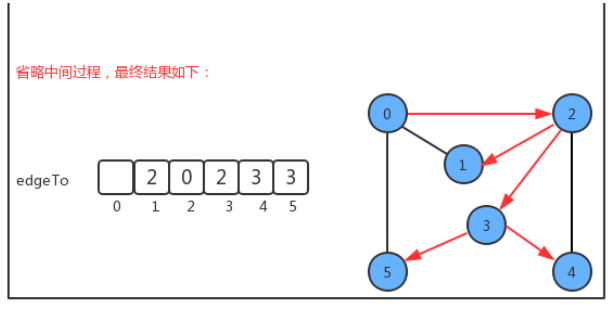
根据最终edgeTo的结果,我们很容易能够找到从起点0到任意顶点的路径;
路径查找代码实现
package Graph;
import LinkTable.Stack;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
/**
* @author Fantic
* @create 2021-08-22 13:45
*/
public class DepthFirstPaths {
private boolean[] marked;//索引代表顶点,对应的值表示当前定点是否已经被搜索
private int s;//起始顶点
private int[] edgeTo;//索引代表顶点,对应值代表从起点s到当前顶点的路径上的最后一个顶点
//构造深度优先搜索对象,使用深度优先搜索找出graph中起点为s的所有路径
public DepthFirstPaths(Graph graph,int s) {
//创建一个和图的顶点数一样大小的布尔数组
marked = new boolean[graph.V()];
//创建一个和图顶点数一样大小的整形数组
edgeTo = new int[graph.V()];
//初始化顶点
this.s = s;
//搜索graph图中起点为s的所有路径
dfs(graph,s);
}
//使用深度优先找出graph图中v顶点的所有相邻顶点
private void dfs(Graph graph,int v) {
//把当前顶点标记为已搜索
marked[v] = true;
//遍历v顶点的邻接表,得到每一个相邻顶点w
for (Integer w : graph.adj(v)) {
if (!marked[w]){
//如果当前顶点没有被搜索,则将edgeTo[w]设置为v,并递归搜索与顶点w相通的点
edgeTo[w] = v;
dfs(graph,w);
}
}
}
//判断v顶点与s顶点之间是否存在路径
public boolean hasPath(int v){
return marked[v];
}
//找出从起点s到顶点v的路径
public Stack pathTo(int v){
//当前顶点v与顶点s不连通,所以直接返回null,没有路径
if (!hasPath(v)) {
return null;
}
//创建路径中经过的顶点
Stack<Integer> path = new Stack<>();
//第一次把当前顶点存进去,然后将x变换为到达当前顶点的前一个顶点edgeTo[x],
// 把前一个顶点存进去,继续将x变换为到达前一个的顶点的前一个顶点,继续存,一直到x的值是s位置,
// 然后对栈进行调用,就会出现基于起点s的路径
for (int x = v;x != s;x = edgeTo[x]){
//把当前顶点放入到栈中
path.push(x);
}
//最后把起点s放到栈中
path.push(s);
return path;
}
public static void main(String[] args) throws Exception {
//构建缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader
(new FileInputStream(new File("road_find.txt"))));
//读取城市数目,初始化Graph图
int total = Integer.parseInt(reader.readLine());
Graph graph = new Graph(total);
//读取已经修建好的道路数量
int number = Integer.parseInt(reader.readLine());
//循环读取已经修建好的道路
for (int i = 0; i < number; i++) {
String line = reader.readLine();
String[] str = line.split(" ");
int p = Integer.parseInt(str[0]);
int q = Integer.parseInt(str[1]);
graph.addEdge(p,q);
}
reader.close();
//根据图graph和起点顶点0找寻对应路径
DepthFirstPaths paths = new DepthFirstPaths(graph, 0);
//查找对象的pathTo(4)的路径
Stack<Integer> path = paths.pathTo(4);
/*
String、StringBuffer、StringBuilder三者的异同?(重点)
String:不可变的字符序列;底层使用char[]存储
StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储
StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
源码分析:
String str = new String();//char[] value = new char[0];
String str1 = new String("abc");//char[] value = new char[]{'a','b','c'};
StringBuffer sb1 = new StringBuffer();//char[] value = new char[16];底层创建了一个长度是16的数组。
System.out.println(sb1.length());//
sb1.append('a');//value[0] = 'a';
sb1.append('b');//value[1] = 'b';
StringBuffer sb2 = new StringBuffer("abc");//char[] value = new char["abc".length() + 16];
//问题1. System.out.println(sb2.length());//3
//问题2. 扩容问题:如果要添加的数据底层数组盛不下了,那就需要扩容底层的数组。
默认情况下,扩容为原来容量的2倍 + 2,同时将原有数组中的元素复制到新的数组中。
指导意义:开发中建议大家使用:StringBuffer(int capacity) 或 StringBuilder(int capacity)
*/
StringBuilder builder = new StringBuilder();
for (Integer v : path) {
builder.append(v + "-");
}
builder.deleteCharAt(builder.length() - 1);
System.out.println(builder.toString());
}
}
















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











