










文章目录
一、效果展示
CCF推荐会议共有363个,本文通过爬虫把信息全部收集到一个xlsx表格中。图中我们按投稿DDL排序,可以轻松找到最近可投的会议。也可按专业类型、ccf等级排序,各取所需。
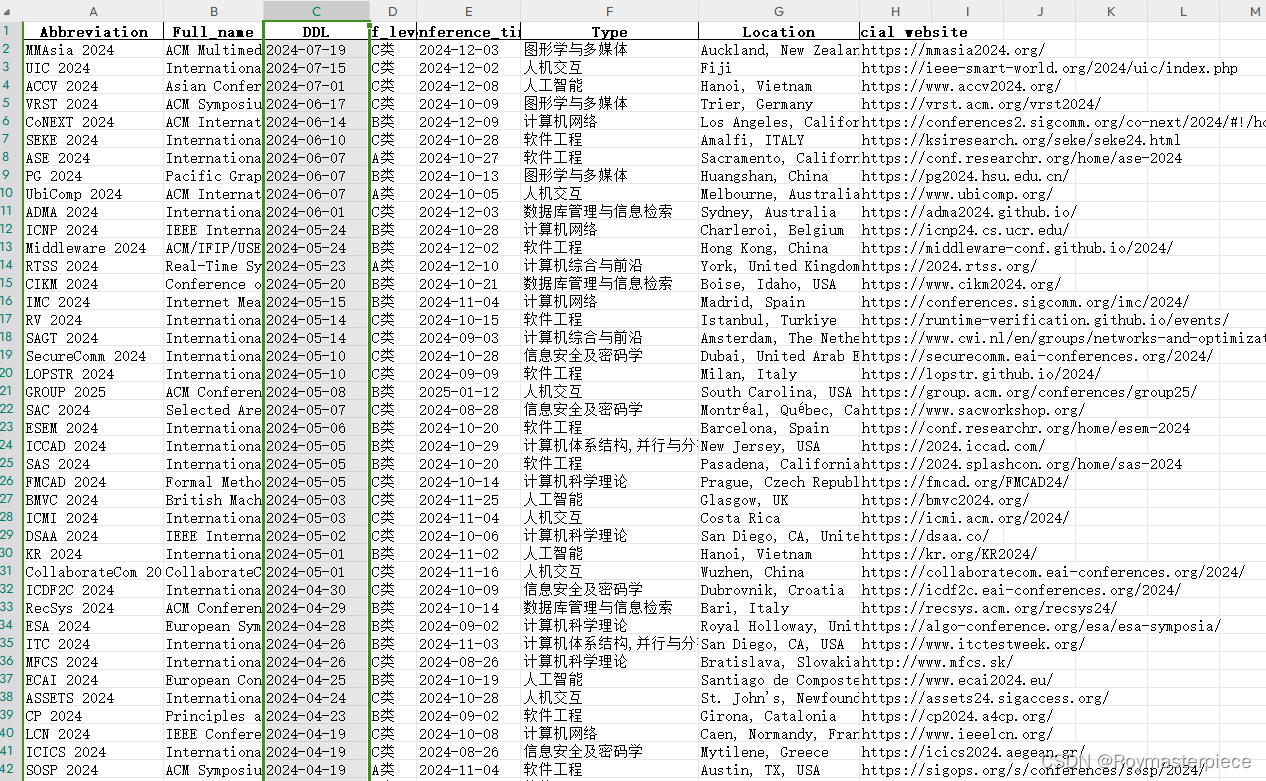
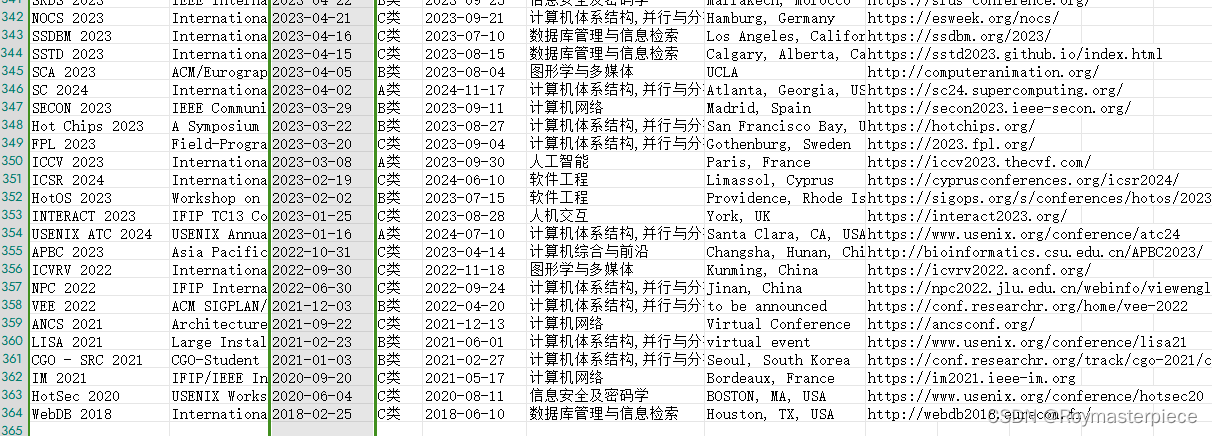
二、代码区
运行代码会生成一个表格文件all_ccf_conference_info.xlsx,用以存放所有会议信息。
import requests
from lxml import etree
import pandas as pd
def get_info(url,header):
response_c = requests.get(url=url,headers=header).text
tree_c=etree.HTML(response_c)
leaf_type=tree_c.xpath('/html/body/div[2]/div/div/h5')
type=(leaf_type[0].text).replace("\t","").replace("\r","").replace("\n","")
leaf_short_name=tree_c.xpath('/html/body/div[2]/div/div/h3')
short_name=leaf_short_name[0].text
leaf_full_name=tree_c.xpath('/html/body/div[2]/div/div/h4')
full_name=leaf_full_name[0].text
leaf_text_ddl=tree_c.xpath('/html/body/div[2]/div/div/div[2]/h5[2]')
text_ddl=leaf_text_ddl[0].text
leaf_conference_time=tree_c.xpath('/html/body/div[2]/div/div/div[2]/h5[3]')
conference_time=leaf_conference_time[0].text
leaf_ccf_level=tree_c.xpath('/html/body/div[2]/div/div/div[2]/h5[5]')
ccf_level=leaf_ccf_level[0].text
leaf_place=tree_c.xpath('/html/body/div[2]/div/div/div[2]/h5[6]')
place=leaf_place[0].text
leaf_guanwang=tree_c.xpath('/html/body/div[2]/div/div/div[5]/input')
guanwang=leaf_guanwang[0].attrib['onclick']
return type,short_name, full_name, text_ddl[-10:], ccf_level[-2:], conference_time[-10:], place[6:], guanwang[9:-2]
def paccf(url,info_dic):
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0'}
response = requests.get(url=url,headers=header).text
tree=etree.HTML(response)
for table in range(3):
father_div=f'/html/body/div[2]/div[2]/div[{table+1}]'
count_of_child_divs = tree.xpath('count(' + father_div + '/div)')
number_of_child_divs = int(count_of_child_divs)
for j in range(1,number_of_child_divs):
leaf=tree.xpath(f'/html/body/div[2]/div[2]/div[{table+1}]/div[{j+1}]/div[2]/h4/a')
#leaf=tree.xpath('/html/body/div[2]/div[2]/div[1]/div[3]/div[2]/h4/a')
print(leaf[0].attrib['href'][-10:])
C_num=leaf[0].attrib['href'][-10:]
c = 'http://123.57.137.208/detail.jsp?url='+C_num
type, short_name, full_name, text_ddl, ccf_level, conference_time, place, guanwang=get_info(c,header)
info_dic['Abbreviation'].append(short_name)
info_dic['Full_name'].append(full_name)
info_dic['DDL'].append(text_ddl)
info_dic['ccf_level'].append(ccf_level)
info_dic['Conference_time'].append(conference_time)
info_dic['Type'].append(type)
info_dic['Location'].append(place)
info_dic['Official website'].append(guanwang)
print(short_name, full_name, text_ddl, ccf_level, conference_time,type, place, guanwang)
print("")
return info_dic
info_dic={}
info_dic['Abbreviation']=[]
info_dic['Full_name']=[]
info_dic['DDL']=[]
info_dic['ccf_level']=[]
info_dic['Conference_time']=[]
info_dic['Type']=[]
info_dic['Location']=[]
info_dic['Official website']=[]
for i in range(1,11):
url=f'http://123.57.137.208/ccf/ccf-{i}.jsp'
info_dic=paccf(url,info_dic)
df = pd.DataFrame(info_dic)
df.to_excel('all_ccf_conference_info.xlsx', index=False)三、原理详解
如果看到这说明你不是个单纯的白嫖党,想必是有bear来
首先定义一个字典,预存所有的信息,最后要保存到一个表格里。
info_dic={}
info_dic['Abbreviation']=[]
info_dic['Full_name']=[]
info_dic['DDL']=[]
info_dic['ccf_level']=[]
info_dic['Conference_time']=[]
info_dic['Type']=[]
info_dic['Location']=[]
info_dic['Official website']=[]然后去Call4Paper首页看看。Call4Papers - CCF推荐列表
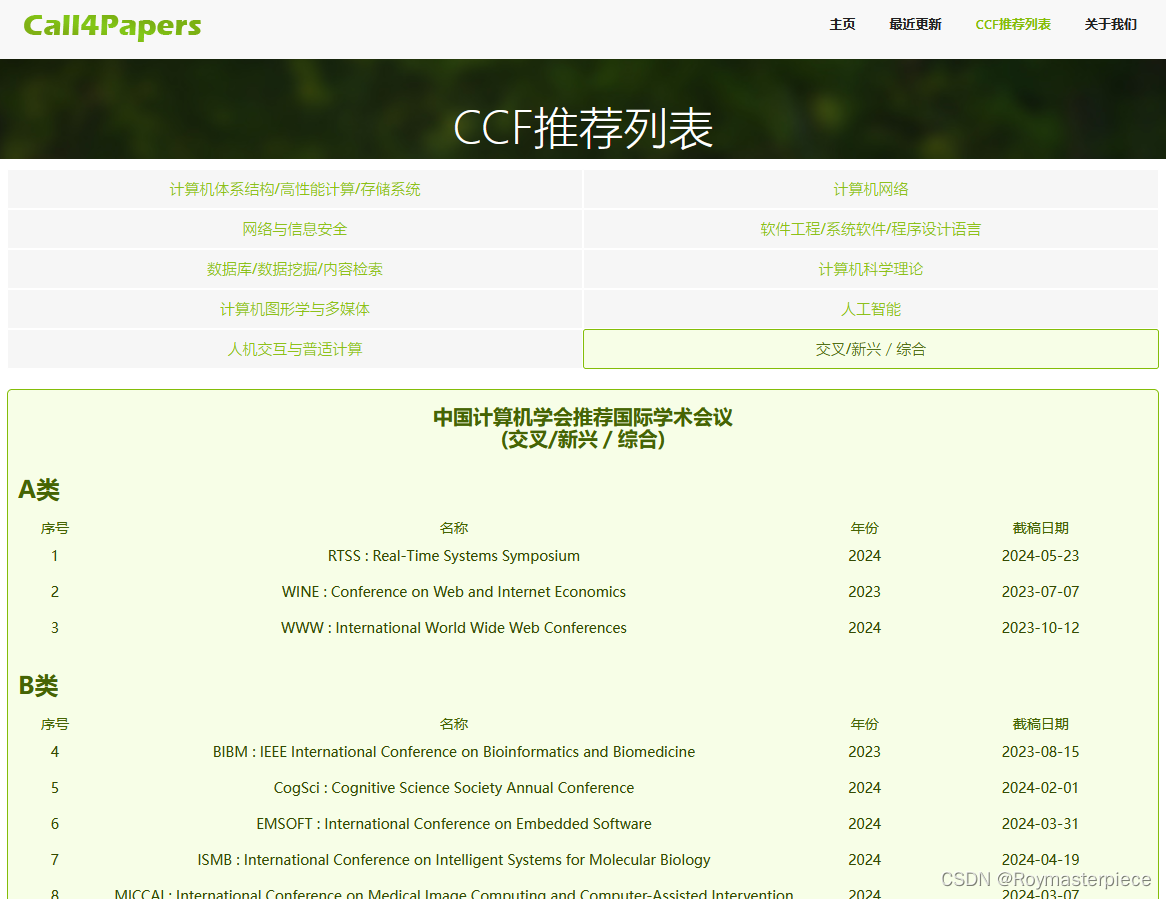
网站上没有排序的功能,而且十种专业类型没有合并在一起,想找到最近能投稿的会议劳神费眼。
可以发现计算机体系结构的url是
http://123.57.137.208/ccf/ccf-1.jsp
计算机网络的url是
http://123.57.137.208/ccf/ccf-2.jsp
交叉/新兴/综合的url是
http://123.57.137.208/ccf/ccf-10.jsp
每种类型的链接只是替换了ccf-后面的数字,所以可以这样遍历十个类型:
for i in range(1,11):
url=f'http://123.57.137.208/ccf/ccf-{i}.jsp'
info_dic=paccf(url,info_dic)接下来要完成paccf函数,将每一个url的会议列表信息都爬下来,存到info_dic中。在首页,每个会都分为了A,B,C三类table。

按f12查看A类table的xpath(右击标签,复制->Xpath),是/html/body/div[2]/div[2]/div[1],B类是/html/body/div[2]/div[2]/div[2],C类是/html/body/div[2]/div[2]/div[3]
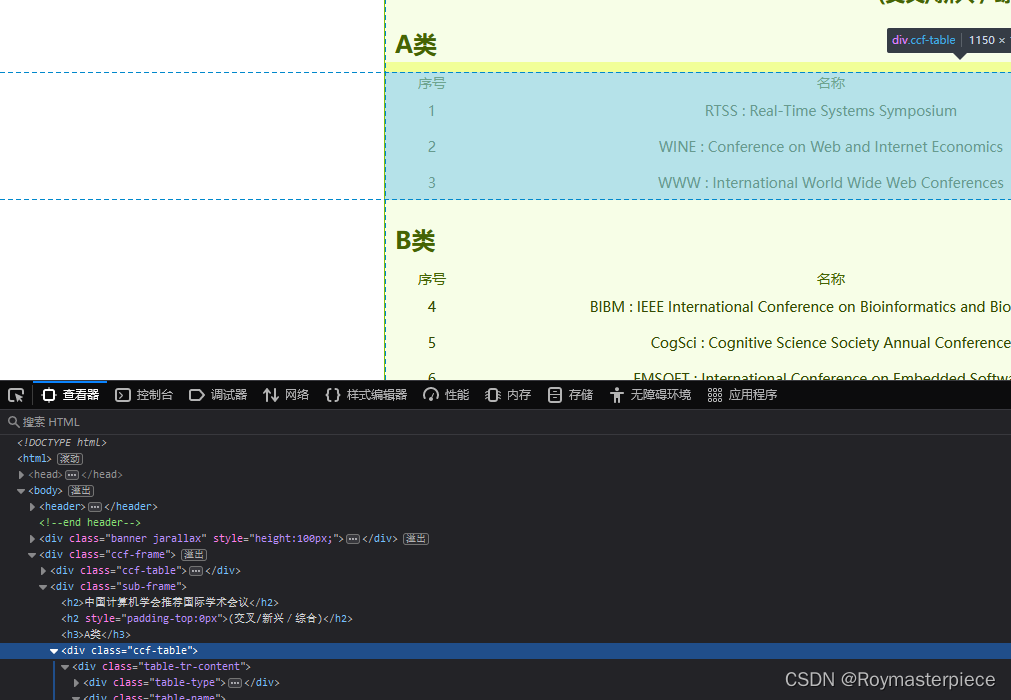
所以可以用下面的代码遍历table。而不同table一级的div标签下有不同数量的会议,所以要用xpath的count函数查看这个div标签下有几个div子标签。
for table in range(3):
father_div=f'/html/body/div[2]/div[2]/div[{table+1}]'
count_of_child_divs = tree.xpath('count(' + father_div + '/div)')
number_of_child_divs = int(count_of_child_divs)接下来随便进入一个会议的页面,用同样的方法找这些信息的xpath:会议名称,截稿日期,开会时间,ccf分类,地点,官网,专业分类。再用一些字符串截断来获取标签下的信息。
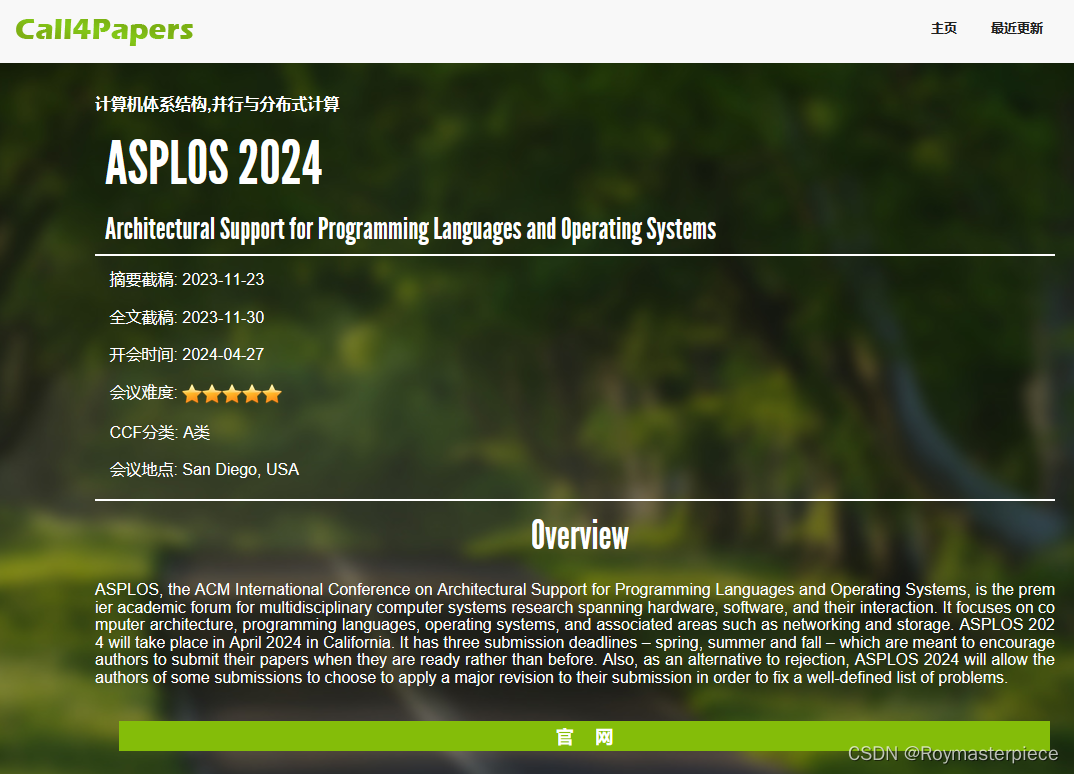
for j in range(1,number_of_child_divs):
leaf=tree.xpath(f'/html/body/div[2]/div[2]/div[{table+1}]/div[{j+1}]/div[2]/h4/a')
#leaf=tree.xpath('/html/body/div[2]/div[2]/div[1]/div[3]/div[2]/h4/a')
print(leaf[0].attrib['href'][-10:])
C_num=leaf[0].attrib['href'][-10:]
c = 'http://123.57.137.208/detail.jsp?url='+C_num
type, short_name, full_name, text_ddl, ccf_level, conference_time, place, guanwang=get_info(c,header)
info_dic['Abbreviation'].append(short_name)
info_dic['Full_name'].append(full_name)
info_dic['DDL'].append(text_ddl)
info_dic['ccf_level'].append(ccf_level)
info_dic['Conference_time'].append(conference_time)
info_dic['Type'].append(type)
info_dic['Location'].append(place)
info_dic['Official website'].append(guanwang)
print(short_name, full_name, text_ddl, ccf_level, conference_time,type, place, guanwang)
print("")总结
在网页里搜索太慢,还是在表格里筛选快速一些。直接附上表格供大家使用。
















 2504
2504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











