







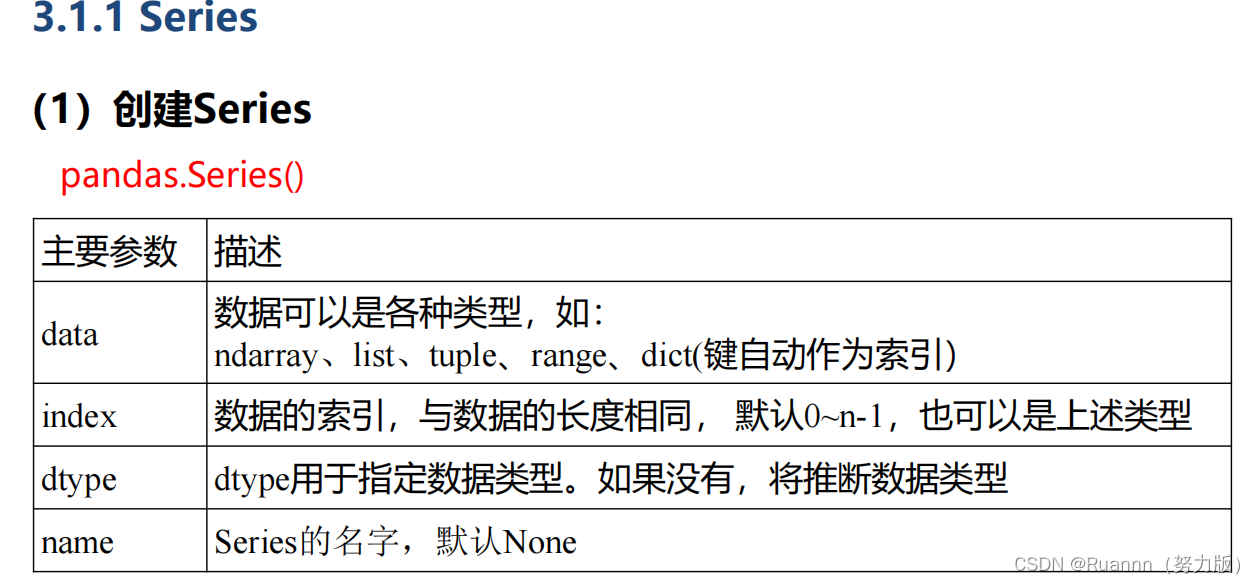
Pandas有两种主要的数据结构:系列(Series)、数据帧(DataFrame)。
系列(
Series
)
是一种具有
索引
的类似于
一维数组
的数据结构。
数据帧(
DataFrame
)
是一种既有
行索引
又有
列索引
的类似于
二维
数组的数
据结构。
 根据索引值获取数据
根据索引值获取数据
height=[1,2,3,4]
names = ['吴明', '王毅', '陈辉', '魏云'] # 创建一个列表
s2 = pd.Series(height, index=names) # 作为index参数
print(s2['吴明'], sep='')字典创建Series 【key作为行索引】
dict={'A':1,'B':(2,3)}
a=pd.Series(dict)
print(a)A 1
B (2, 3)
dtype: object
(2)Series的数据和索引
series.values
series的值(数组类型)
series.index
series的索引(索引对象类型)
series.items()
(索引,值)对

(3)通过Series的索引取值
位置索引
通过0 ~ n-1进行索引
名称索引
通过传入指定的index名称来进行索引
点索引
通过"series.index名称"的形式进行索引
(注意:index类型为非数值类型才可以使用)
布尔索引
通过series[布尔表达式]取数



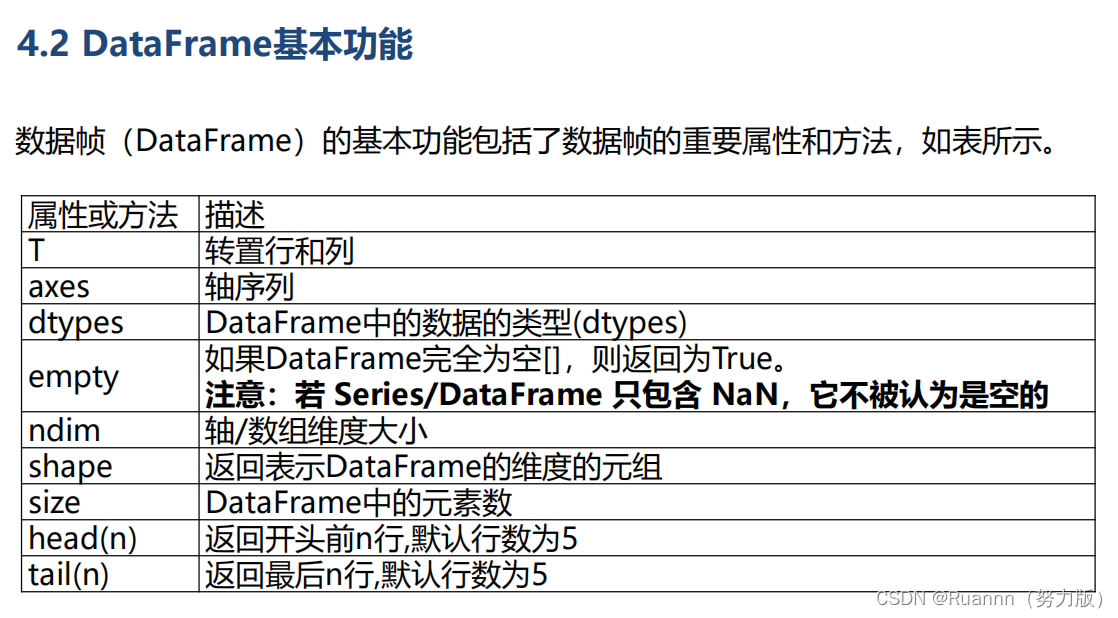
DataFrame数据帧
数据帧(DataFrame)是一种
既有行索引又有列索引的二维数组
。
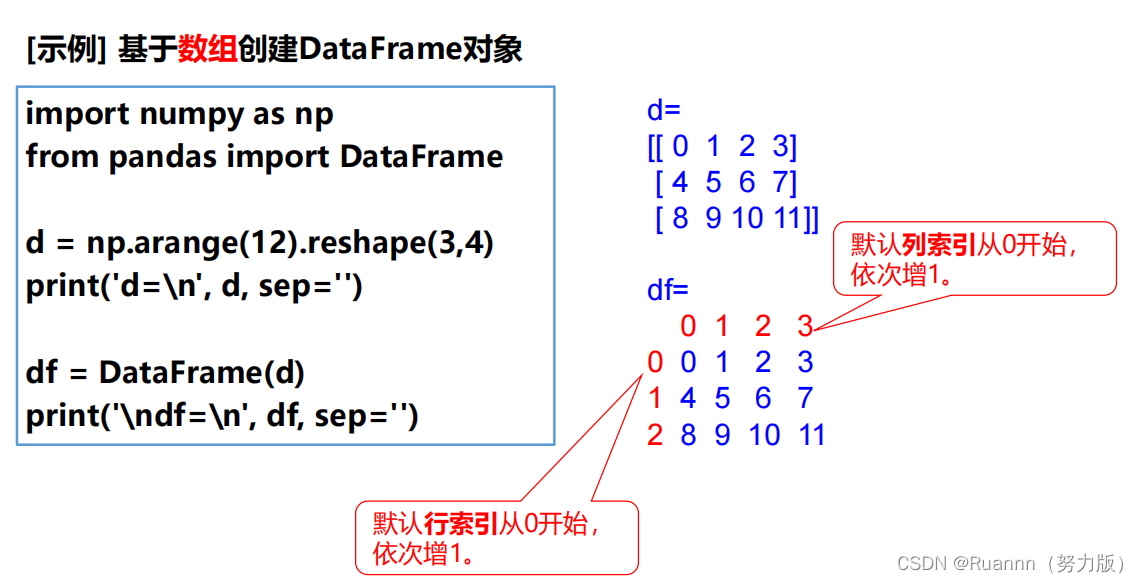
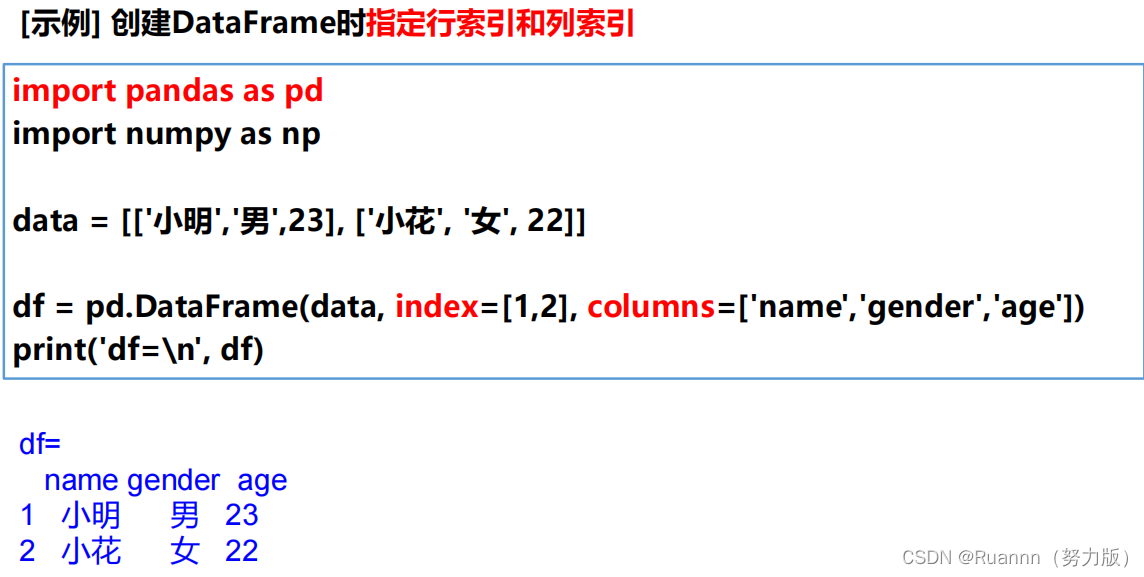
(1)创建DataFrame
Pandas.DataFrame()




(2)DataFrame的数据和索引
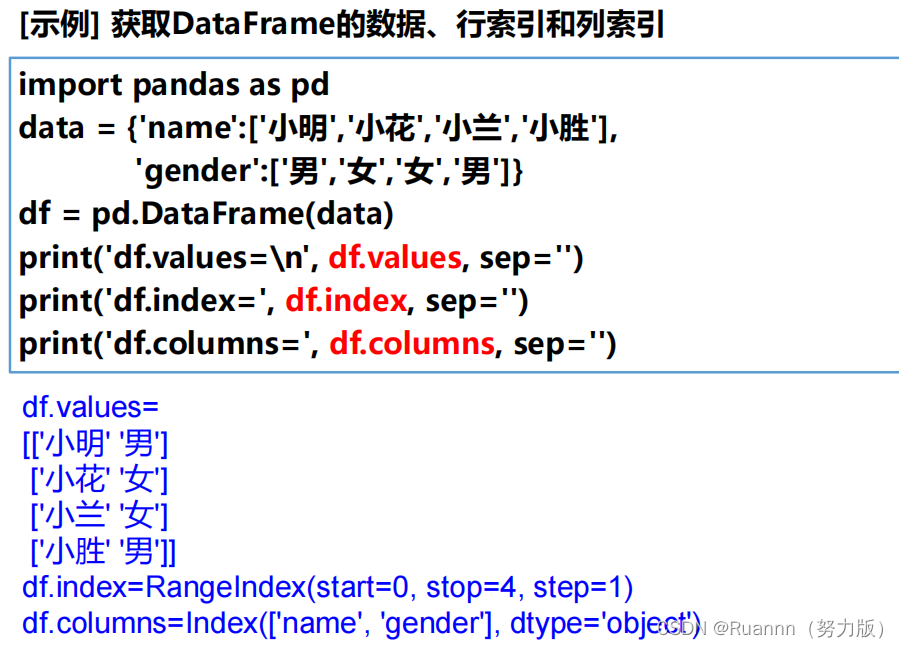
dataframe.values
dataframe的数据(二维数组类型)
dataframe.index
dataframe的行索引
df.columns
dataframe的列索引
在创建dataframe时缺值
自动填充NaN(
Not a Number
)
(4)pandas中NaN的处理
主要有以下几个方法:
查看是否是nan: isnull() 、notnull()、 isna()、notna()
丢弃有nan的索引项:dropna()
将nan填充为其他值:fillna()




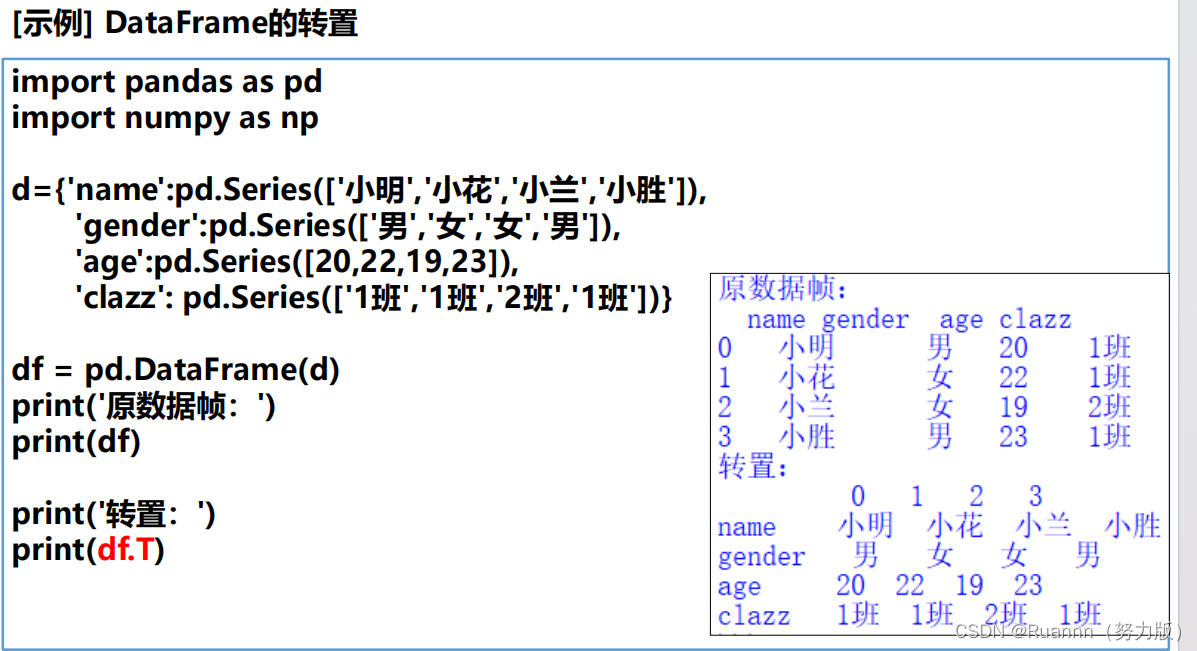

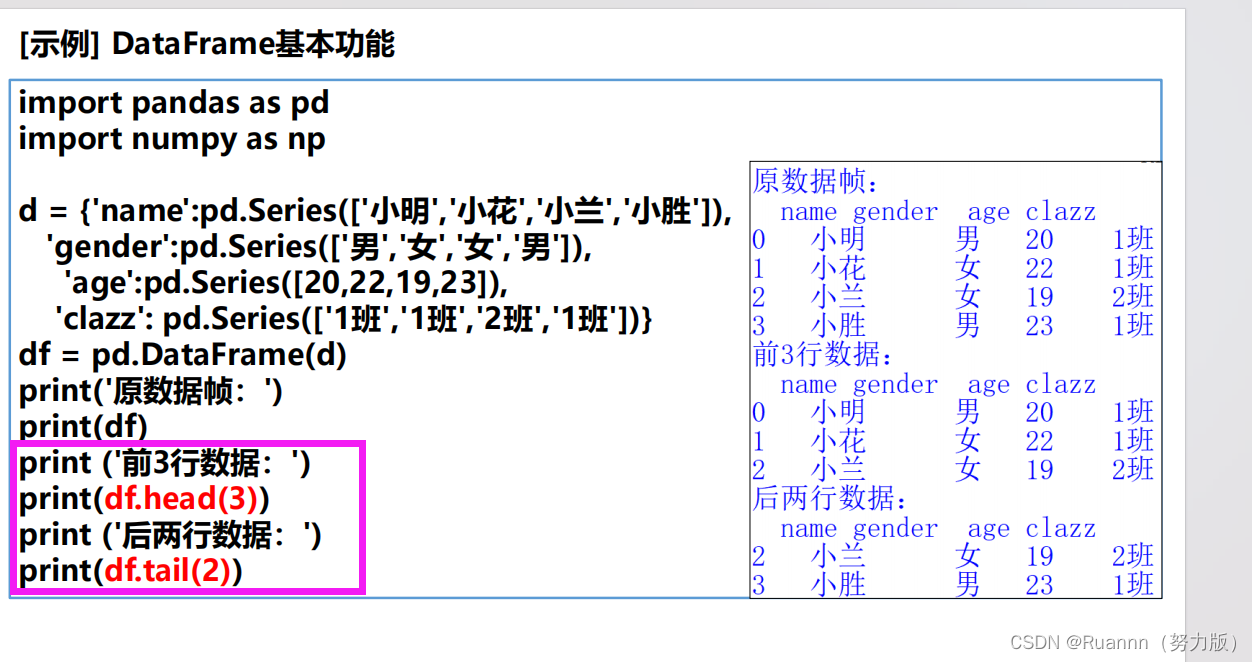
读取文件
读取外部数据分为读取
文件
、
数据库
和
网络
中的数据。
•
保存数据的文件主要有CSV、Excel、txt和 json,本节主要介绍使用较多的
CSV和Excel文件,txt文件和json的使用与CSV和Excel的使用相似。
•
数据库数据读取分为两部分:建立连接、执行SQL语句。本部分介绍如何读
取Sqlite数据库。
•
网络数据的读取使用最多的是网络爬虫,Pandas提供了read_htlm函数读取
网页数据(read_html() 函数是最简单的爬虫,可以爬取静态网页表格数据)。
3.3.1 读写csv文件
(1)read_csv
CSV(Comma-Separated Values)格式的文件是指以纯文本形式存储的表格数
据,巨量的数据常使用CSV格式。
(2)read_table
函数read_table与read_csv大同小异,不同处是read_table默认分隔符为制表符,
而read_csv默认的分隔符为英文逗号。
(3)to_csv
函数to_csv用来把DataFrame数据保存数据到CSV文件。
(4)read_Excel
(5)to_excel
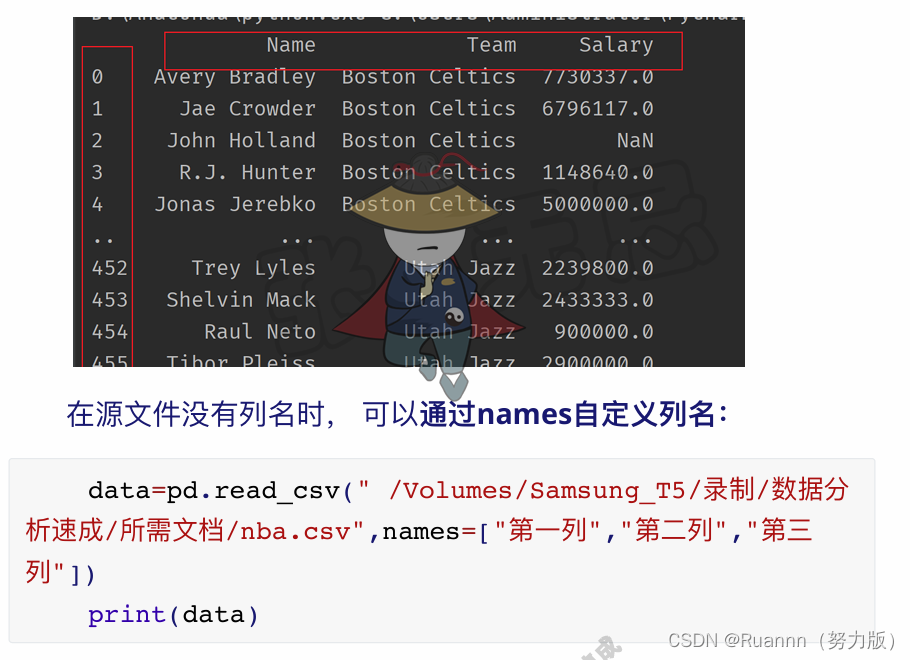
















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









