







Mysql约束
顾名思义就是对表中的数据进行限定, 目的是保证数据的正确性, 有效性和完整性
主键约束primary key
什么是主键?
关系表中记录的唯一标识(不能为null, 不可重复)
选取和业务无关的字段, 常用的主键就是自增id
数据库引擎会通过主键建立索引, 索引是一个有序结构, 我们希望当前主键的值不要改变, 避免重新建立索引, 影响性能.
添加主键
CREATE TABLE store_perf(
id int PRIMARY KEY auto_increment,
store_name varchar(255)
)主键的长度限制
767bytes, 对应的长度为767/4=191
bytes表示字节, 一个utf8mb4按四个字节算, 所以长度最大为191
自增键必须为主键
若设定了自增键,则其必须为主键,否则就会报错
Incorrect table definition; there can be only one auto column and it must be defined as a key联合主键
主键其实只能有一个, 如果在图形界面当中选择多个字段作为主键, 那么程序会自动帮我们创建联合主键
主键操作
- 添加主键
ALTER TABLE store_perf ADD PRIMARY KEY (`id`)- 移除主键
ALTER TABLE store_perf DROP PRIMARY KEY- 添加联合主键
ALTER TABLE store_perf ADD PRIMARY KEY (`id`, `store_name`)非空约束
NOT NULL
只能约束程序层面上没有操作该表中的某个字段, 不能约束人行为上对其赋值为空白字符.
唯一约束
UNIQUE
NULL可以重复
比如统计店铺业绩, 该店铺不可以重复, 那就可以使用唯一约束
外键约束foreign key
- 外键的作用
保持数据的一致性和完整性, 通过外键来表达主表和从表的关系, 避免冗余字段.
- 为什么现在不用外键了?
- 性能问题:插数据需要校验。
- 并发问题:在高并发的事务场景下, 使用外键容易造成死锁。
- 扩展性问题:外键就相当于把对象之间的关系交给数据库来维护, 如果遇到分库分表, 外键是不生效的。作数据迁移时, 触发器, 存储过程和外键都很难迁移, 增加了维护成本。
- 维护成本:需要有专业的DBA来维护庞大的数据库关系。
default
默认约束, 默认会填充当前字段.
如果我们没有给一个有默认约束的字段create_time值, 那么该字段会默认填充CURRENT_TIMESTAMP
分组查询GROUP BY
将数据按某个字段进行分组, 配合SUM, AVG, COUNT, MAX, MIN等聚合函数做统计使用
这里我讲使用一个例子进行记录:
首先在数据库中插入数据:
INSERT INTO store_perf(store_name, amount, department) values ("男装_店铺1", 34543123.23, "男装事业部"), ("男装_店铺2", 41232373.12, "男装事业部"),("男装_店铺3", 62135632.22, "男装事业部"), ("男装_店铺4", 612356123.26, "男装事业部"), ("女装_店铺1", 78716237854.3, "女装事业部"), ("女装_店铺2", 89123565741.23, "女装事业部"), ("女装_店铺3", 831235769.23, "女装事业部"), ("女装_店铺4", 1912312345.13, "女装事业部"), ("女装_店铺5", 87324234712.92, "女装事业部"), ("女装_店铺6", 12754547457.93, "女装事业部")使用Navicat可视化工具查看一下:
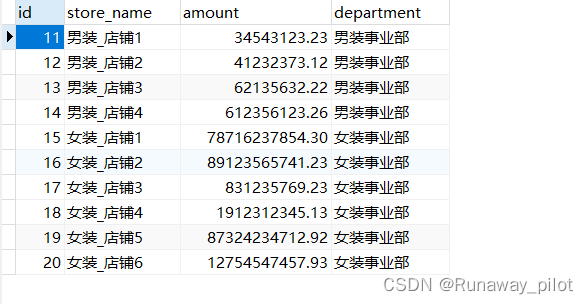
可以看到,刚刚的命令生成了十条数据,
分别是店铺的名称(store_name),营业额(amount),和所属部门(department)。
然后我们遇到了多个需求并实现它:
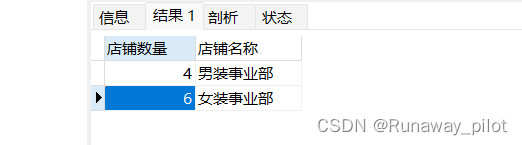
1. 统计各个部门的总店铺数:
使用 count() 统计数量
SELECT count(*) as 店铺数量,department as 店铺名称
FROM store_perf GROUP BY department;其中,as 起到了为查询结果起别名的作用。
查询结果为:
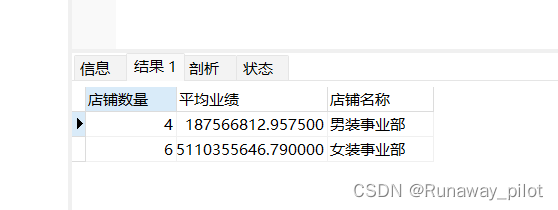
2. 统计各个部门店铺的平均业绩:
使用 avg() 统计平均数
SELECT
count(*) as 店铺数量,
AVG(amount) as 平均业绩,
department as 店铺名称
FROM store_perf GROUP BY department;查询结果为:
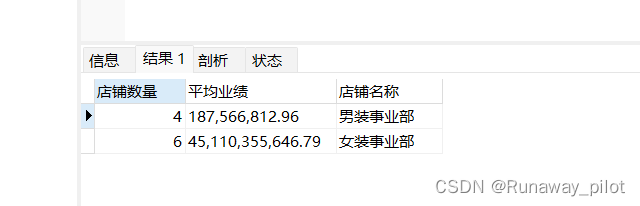
可以用 format() 来设置显示几位小数:
SELECT
count(*) as 店铺数量,
FORMAT(AVG(amount),2) as 平均业绩,
department as 店铺名称
FROM store_perf GROUP BY department;结果为:
3. 查看各个部门店铺的总业绩,最大业绩,最小业绩:
SELECT
count(*) as 店铺数量,
FORMAT(AVG(amount),2) as 平均业绩,
SUM(amount) as 总业绩,
MAX(amount) as 最大业绩,
MIN(amount) as 最小业绩,
department as 店铺名称
FROM store_perf GROUP BY department;结果为:

变量声明
服务器系统变量
通过 @@来调用系统变量
# 列出mysql所有系统变量
SHOW VARIABLES
SELECT @@date_format用户变量
通过@来调用用户变量
# 输出变量yesterday
SELECT @yesterday
# 对变量yesterday进行赋值
SET @yesterday=subdate(CURRENT_DATE, 1);
# 日期的格式化
SET @yesterday=DATE_FORMAT(@yesterday, "%Y/%m/%d");
# 小数的格式化
SET @amount=0.4;
SET @amount=CAST(@amount as DECIMAL(15, 3));
SELECT @amount局部变量
不需要@前缀
需要事先进行变量类型的声明和初始化
存储过程
简单地认为是SQL中的函数
声明一个存储过程
创建存储过程
CREATE PROCEDURE stat_store_perf(days INT)
BEGIN
DECLARE t_date VARCHAR(255);
set t_date = DATE_FORMAT(subdate(CURRENT_DATE, days), '%Y-%m-%d');
SELECT count(*) as 店铺数,
FORMAT(AVG(amount), 2) as 平均业绩,
SUM(amount) as 总业绩,
MAX(amount) as 最大业绩,
MIN(amount) as 最小业绩,
department as 部门
FROM store_perf WHERE sta_date=t_date
GROUP BY department;
END每一句语句结束之后都要添加分号;
调用存储过程
CALL stat_store_perf(1)删除存储过程
DROP PROCEDURE stat_store_perf触发器
和存储过程一样, 都是嵌入到mysql中的一段程序, 区别就是存储过程需要显式调用, 而触发器式根据对表的相关操作自动激活执行。
创建触发器
CREATE TRIGGER 触发器名
BEFORE[AFTER] [INSERT, UPDATE, DELETE]
CREATE TRIGGER check_department
BEFORE INSERT
ON store_perf
FOR each row
BEGIN
IF new.department not in ("男装事业部", "女装事业部") THEN
SET new.department 'unknow';
END IF;
END查看触发器
建议通过客户端查看
SHOW TRIGGERS FROM store_perf删除触发器
建议通过客户端删除
DROP TRIGGERS check_department索引和优化
创建索引
CREATE INDEX 索引名 ON 表名(字段1, 字段2...)
CREATE INDEX store_name_index ON store_perf(store_name)设置索引的字段不可以超过191个字符长度, 也就是767个bytes
创建联合索引
CREATE INDEX store_name_sta_date_department_index ON store_perf(store_name, sta_date, department)查看索引
SHOW INDEX FROM store_perf删除索引
ALTER TABLE store_perf DROP INDEX store_name_index查看当前查询语句有没有命中索引
EXPLAIN SELECT * from store_perf WHERE store_name = "店铺_224123"- EXPLAIN语句查看当前语句执行性能
- 如果key有值, 说明命中了索引, 且key值为索引名
单个字段可以命中联合索引吗?
联合索引涉及到一个叫左缀查询的规则
如果想命中索引, 查询语句中涉及到字段必须是联合索引创建时从左到右顺序
- 原理:在
a_b_c_index这样一个联合索引当中, 实质执行中是先查出a的结果集, 然后再查b或c的结果集
索引的实现原理
B+树, 一种特殊的链表, 用来实现二分查找。
如何优化mysql
合理地建立索引
-
频繁作为查询条件的字段应该建立索引
-
唯一性太差的字段不适合单独建立索引
-
更新非常频繁的字段不适合建立索引
-
避免不经过索引的操作
-
not in,!=等反向逻辑 -
BETWEEN范围查找 -
or逻辑两边都必须命中索引才会走索引 -
联合索引, 不按左缀查询规则
-
加缓存
-
数据库缓存
show VARIABLES LIKE '%query_cache%'
-
用redis做缓存
请求 -> redis -> 未命中 -> mysql -> 返回
使用钞能力,换固态硬盘
事务
事务的提交, 回滚
START TRANSACTION;
INSERT INTO store_perf(store_name, amount, department, sta_date) VALUES ('店铺_1764', 753294.41, '事业部_8', '2021-02-05');
ROLLBACK;
COMMIT;在python业务中使用事务
将class_2中的同学转移到class_1, 如果SQL_2报错, 会导致class_2中的同学丢失.
def transaction():
try:
SQL = "DELETE FROM class_2 where name='name_13'"
mysql_cursor.execute(SQL)
SQL_2 = "INSERT INTO class_1 VALUES(name)"
mysql_cursor.execute(SQL_2)
except Exception as e:
print("raise Exceptions", e.args[0])
print("rollback")
mysql_con.rollback()
finally:
mysql_con.commit()














 2738
2738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









