







因工作需要识别限长字符串中中文个数,且需要识别字符串最后两个字节为中文,因长度限制只能识别为乱码,需要截断乱码部分。搜了几篇文章,发现这篇写的最简便:https://blog.csdn.net/weixin_44001521/article/details/95035977,但存在部分bug,故写此文优化一下。
UTF-8字节编码规则
编码范围
- 一字节编码范围:0x00-0x7F
- 二字节编码范围:0xC2-0xDF 0x80-0xBF
- 三字节编码范围:
0xE0 0xA0-0xBF 0x80-0xBF
0xE1-0xEC 0x80-0xBF 0x80-0xBF
0xED 0x80-0x9F 0x80-0xBF
0xEE-0xEF 0x80-0xBF 0x80-0xBF - 四字节编码范围:
0xF0 0x90-0xBF 0x80-0xBF 0x80-0xBF
0xF1-0xF3 0x80-0xBF 0x80-0xBF 0x80-0xBF
0xF4 0x80-0x8F 0x80-0xBF 0x80-0xBF
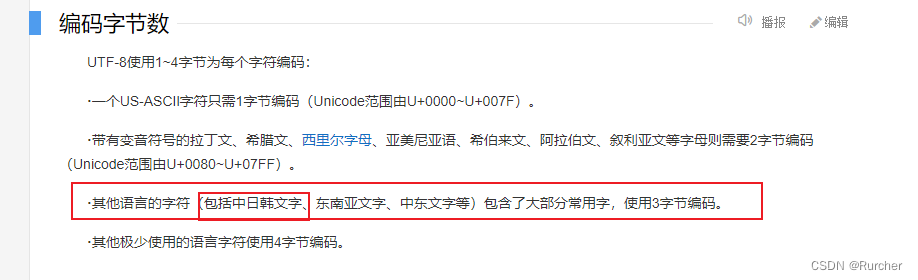
中文字节规则
参考UTF-8百度百科:
代码实现
#include <iostream>
#include <cstring>
#include <string>
#include <vector>
using namespace std;
bool check(unsigned char c){
//通过utf-8字节码进行判断
return c >= 0xE0;
}
int main()
{
string str = " 的2df.dasf为 d啊 ";
int LowerCase, UpperCase; //大写,小写
int space = 0;
int digit, character; //数字,字符
int chinese = 0; //中文
digit = character = LowerCase = UpperCase = 0;
for (int i = 0; i < str.size(); )
{
if (str[i] >= 'a' && str[i] <= 'z')
{
LowerCase ++;i++;
}
else if (str[i] >= 'A' && str[i] <= 'Z')
{
UpperCase ++;i++;
}
else if (str[i] >= '0' && str[i] <= '9')
{
digit ++;i++;
}
else if (check(str[i])){
char c[3];
strncpy(&c[0], &str[i], 3);
cout << c << endl;
i+=3;
chinese++;
}
else if (str[i] == ' ')
{
space++;i++;
}
else
{
character++;i++;
}
}
printf("大写%d个,小写%d个,数字%d个,字符%d个,汉字%d个,空格%d个\n", UpperCase, LowerCase, digit, character, chinese, space);
return 0;
}
运行结果
字符串为:“ 的2df.dasf为 d啊 ”
输出结果:

参考与转载:
[1]: https://baike.baidu.com/item/UTF-8/481798?fr=aladdin
[2]: https://blog.csdn.net/weixin_44001521/article/details/95035977

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









