






ARM学习之路–数据的存储
ANSI C标准为我们提供了32个关键字,除了一些控制结构的关键字之外,绝大多数都与数据类型和存储相关:

C99/C11新增了一些关键字,也大都与数据类型和存储有关:

数据类型与存储
大端模式与小端模式
字节(byte)是一个最基本的存储单位,也是最小的寻址单元。
我们使用int关键字定义一个变量:int i = 0x12345678;编译器根据变量i的类型,在内存中分配4字节存储。一个数据在内存中有两种存储方式:高地址存储高字节数据;或者高地址存储低字节数据。根据不同的存储模式一般分为大端模式和小端模式。
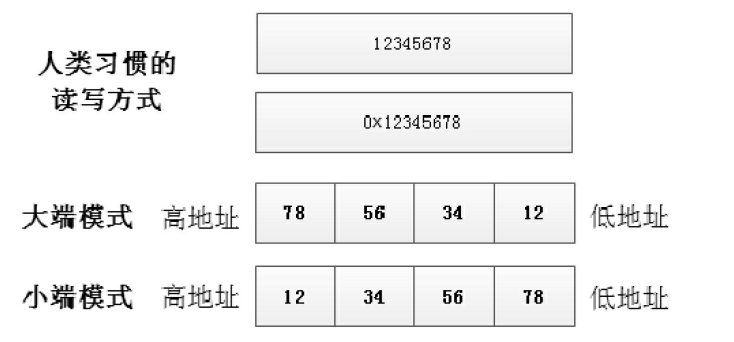
不不同架构的处理器,存储的模式一般也不同。ARM,X86,DSP一般都采用小端模式,而IBM,SUN,PowerPC架构的处理器一般都采用大端的模式。我们通常可以采用一个这样的程序去判断是处理器是大端存储还是小端存储:
大端:数据的高字节存储在内存的低地址
小端:数据的高字节存储在内存的高地址
对于以上的例子来说,0x12就是数据的高字节,0x78为低字节。

这是因为:将一个整形变量赋值给一个字符型变量的时候,通常会发生"截断",将低8位的一字节赋值给字符型变量;我们就可以通过打印判断当前处理器是大端存储还是小端存储了。
对于在网络编程中:大端字节序被称为网络字节序,小端字节序被称为主机字节序。通常小端字节序更加符合人对数据的存储方式。
如何完成大小端模式的转换呢?可以使用这样一个宏:
#define swap_endian_u16(A) \ ((A & 0xFF00 >> 8) | (A & 0X00FF << 8))
有符号数一般有原码,反码。补码之说,反码即将原码的符号位保持不变,所有的数据位取反;
补码=反码+1;无符号数则没有反码和补码的说法。
CPU的硬件电路决定了只能对同类型的数据进行运算,但是往往我们会拿两种不同类型的数据进行运算,不管你是故意的还是不小心!数据的类型转换分为两种:隐式类型转换和强式类型转换。隐式类型转换一般由编译器自动进行。
转换一般从低精度向高精度转换,从有符号到无符号类型转换:

所以如果你在一段代码里面看到 -2 > 3,你也就不用赶到奇怪了!
在强制类型转换的时候,需要注意一个问题,即数据的值在转换的过程中可能会发生改变!
在将一个char类型强转为一个int类型数据时,值保持不变,但存储格式会发生变化,将char型数据保存在int的低8位地址空间,其余的高24位使用符号位填充。 而将一个int类型强转为一个char类型则会发生截断,将int的低8位赋值给char类型,其余的bit位丢掉,从而导致原来的值发生改变。
数据对齐
所谓的数据对齐原则:就是C语言中各种基本数据类型要按照自然边界对齐:
一个char 类型要按照一个字节对齐,一个short类型化的要按照sizeof(short int)字节对齐,而一个int 类型要按照sizeof(int)字节对齐。,每种数据类型的对齐字节数被称为对齐模数!
具体大家可以写一端代码去验证一下,这里不再多说了!那么数据为什么要对齐呢?
这主要由CPU硬件决定,有些CPU在设计的时候简化了地址访问,只支持边界对齐的地址访问,因此编译器也会根据处理器平台的不同,选择合适的地址对齐方式以保证CPU能够正常访问这些存储空间!例如int 或者 short 类型从奇数地址开始存储,那么CPU的一个指令周期就不能完全获取到数据,需要将两个指令周期读取到的数据进行合并,这样对CPU来说就降低了效率!
常量和变量
汇编语言是没有数据类型的概念的,当我们使用DCB和DCD指令去为一个数据对象分配存储空间时,主要考虑的是存储地址,存储大小和存储内容三个基本要素!
变量
在C语言中,一块可以存储数据的内存区域,我们称之为对象,操作这篇内存的表达式,我们称之为左值,如a=1;我们可以通过变量名a去修改这边内存,即通过左值改变对象。
当一个变量作为左值的时候。通常用来表示对象的地址。我们对变量名的引用其实就是对地址区域进行操作。而当变量名作为右值的时候,通常用来表示变量的内容,此时对变量的引用相当于取该地址上的内容!
不同类型的变量有不同的存储方式,作用域和生命周期。在定义一个变量的时候,我们使用char,int,float,double等关键字来指定变量的类型。再加上short,long来确定变量存储空间大小。我们还可以使用auto,register,static,extern,const,volatile,restrict,typedef来改变变量的存储方式。以上共同决定了变量的位置,作用域和生命周期,我们称之为存储类关键字。

上图中可以看到:已经初始化的全局变量存放在data段,未初始化的全局变量存放在bss段;局部变量一般存放在栈区。其中:
bss:(可读可写)用来存放程序中未初始化的全局变量的一块内存,在程序载入时由内核清0,属于静态内存分配。
text:(只读)用来存放程序执行代码的区域
data:(可读可写)存放所有有初始值的全局变量和static静态变量,属于静态内存分配

#include <stdio.h>
int g_a = 10;
int g_b;
void sum(int a,int b)
{
return a+b;
}
int main(void)
{
int a = 10;
static int b = 10;
return 0;
}


数据段中保存的 g_a 和 b 的初值都是 0x0a,也就是10.你可能会好奇为什么变量a不再这里面? 因为前面说了,a是具备非static变量,是在栈中存储的,属于动态内存啦!
常量
我们通过一个栗子来看下常量在内存中如何存储的吧!
#include <stdio.h>
int g_a = 10;
int g_b;
#define HELLO "hello"
char *p = "hgj is a good man";
int main(void)
{
printf("hello %d",HELLO);
printf("p %s",p);
printf("hello world!!!\n");
return 0;
}

可以看见,字符串常量都保存在了只读数据段中!
总结
~1.数据的大小端存储模式,尤其在网络编程的网络字节序和主机字节序中尤为重要,一定不能忘记转换!
~2.数据对齐:对于CPU来说是一种提高工作效率的手段!
~3.了解变量和常亮在内存中的存储位置和生命周期以及存储内容!
更多内容请关注微信公众号:学习学个der














 5080
5080











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









