







CEP 是什么
所谓
CEP
,其实就是“复杂事件处理(
Complex Event Processing
)”的缩写;而
Flink CEP
,
就是
Flink
实现的一个用于复杂事件处理的库(
library
)。
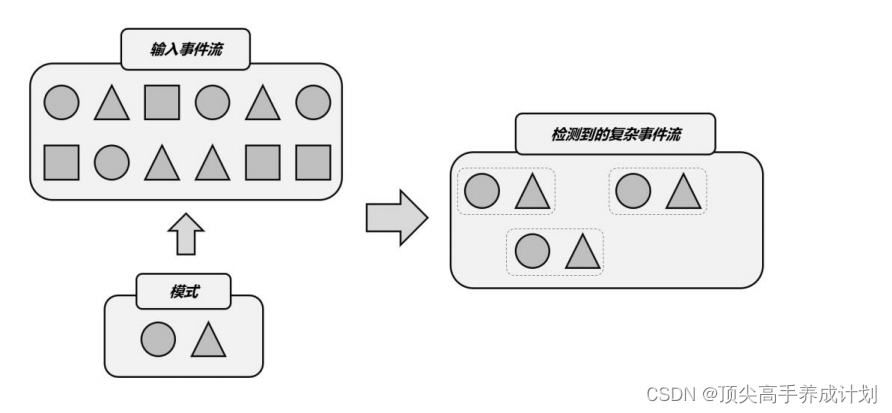
那到底什么是“复杂事件处理”呢?就是可以在事件流里,检测到特定的事件组合并进行
处理,比如说“连续登录失败”,或者“订单支付超时”等等。
具体的处理过程是,把事件流中的一个个简单事件,通过一定的规则匹配组合起来,这就
是
“
复杂事件
”
;然后基于这些满足规则的一组组复杂事件进行转换处理,得到想要的结果进行
输出。
总结起来,复杂事件处理(
CEP
)的流程可以分成三个步骤:
(
1
)定义一个匹配规则
(2)将匹配规则应用到事件流上,检测满足规则的复杂事件
(3)对检测到的复杂事件进行处理,得到结果进行输出
入门
引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>把连续3次登录失败的用户查询出来
public class LoginEvent {
public String userId;
public String ipAddress;
public String eventType;
public Long timestamp;
public LoginEvent(String userId, String ipAddress, String eventType, Long
timestamp) {
this.userId = userId;
this.ipAddress = ipAddress;
this.eventType = eventType;
this.timestamp = timestamp;
}
public LoginEvent() {
}
@Override
public String toString() {
return "LoginEvent{" +
"userId='" + userId + '\'' +
", ipAddress='" + ipAddress + '\'' +
", eventType='" + eventType + '\'' +
", timestamp=" + timestamp +
'}';
}
}应用程序
public class FlinkApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取登录事件流,并提取时间戳、生成水位线
KeyedStream<LoginEvent, String> stream = env
.fromElements(
new LoginEvent("user_1", "192.168.0.1", "fail", 2000L),
new LoginEvent("user_1", "192.168.0.2", "fail", 3000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 4000L),
new LoginEvent("user_1", "171.56.23.10", "fail", 5000L),
new LoginEvent("user_2", "192.168.1.29", "success", 6000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 7000L),
new LoginEvent("user_2", "192.168.1.29", "fail", 8000L)
)
.assignTimestampsAndWatermarks(
//处理乱序的情况
WatermarkStrategy.<LoginEvent>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner(
new SerializableTimestampAssigner<LoginEvent>() {
@Override
public long extractTimestamp(LoginEvent loginEvent, long l) {
return loginEvent.timestamp;
}
}
)
)
.keyBy(r -> r.userId);
// 1. 定义 Pattern,连续的三个登录失败事件
Pattern<LoginEvent, LoginEvent> pattern = Pattern
.<LoginEvent>begin("first") // 以第一个登录失败事件开始
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("second") // 接着是第二个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})
.next("third") // 接着是第三个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
});
// 2. 将 Pattern 应用到流上,检测匹配的复杂事件,得到一个 PatternStream
PatternStream<LoginEvent> patternStream = CEP.pattern(stream, pattern);
// 3. 将匹配到的复杂事件选择出来,然后包装成字符串报警信息输出
patternStream
.select(new PatternSelectFunction<LoginEvent, String>() {
@Override
public String select(Map<String, List<LoginEvent>> map) throws
Exception {
//根据上面定义的模式的名称依次得到和模式匹配得到的数据过滤出来进行处理
LoginEvent first = map.get("first").get(0);
LoginEvent second = map.get("second").get(0);
LoginEvent third = map.get("third").get(0);
return first.userId + " 连续三次登录失败!登录时间:" +
first.timestamp + ", " + second.timestamp + ", " + third.timestamp;
}
})
.
print("warning");
env.execute();
}
}输出的结果
warning> user_1 连续三次登录失败!登录时间:2000, 3000, 5000模式API
个体模式
基本形式
.<LoginEvent > begin("first") // 以第一个登录失败事件开始
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})如果在后面追加规则,那么如下
.next("second") // 接着是第二个登录失败事件
.where(new SimpleCondition<LoginEvent>() {
@Override
public boolean filter(LoginEvent loginEvent) throws Exception {
return loginEvent.eventType.equals("fail");
}
})量词
⚫ .oneOrMore ()匹配事件出现一次或多次,假设 a 是一个个体模式, a.oneOrMore() 表示可以匹配 1 个或多个 a 的事件组合。我们有时会用 a+ 来简单表示。⚫ .times ( times )匹配事件发生特定次数( times ),例如 a.times(3) 表示 aaa ;⚫ .times ( fromTimes , toTimes )指定匹配事件出现的次数范围,最小次数为 fromTimes ,最大次数为 toTimes 。例如 a.times(2,4) 可以匹配 aa , aaa 和 aaaa 。⚫ .greedy()只能用在循环模式后,使当前循环模式变得“贪心”( greedy ),也就是总是尽可能多地去匹配。例如 a.times(2, 4).greedy() ,如果出现了连续 4 个 a ,那么会直接把 aaaa 检测出来进行处理,其他任意 2 个 a 是不算匹配事件的。⚫ .optional()使当前模式成为可选的,也就是说可以满足这个匹配条件,也可以不满足。
使用示例
// 匹配事件出现 4 次
pattern.times(4);
// 匹配事件出现 4 次,或者不出现
pattern.times(4).optional();
// 匹配事件出现 2, 3 或者 4 次
pattern.times(2, 4);
// 匹配事件出现 2, 3 或者 4 次,并且尽可能多地匹配
pattern.times(2, 4).greedy();
// 匹配事件出现 2, 3, 4 次,或者不出现
pattern.times(2, 4).optional();
// 匹配事件出现 2, 3, 4 次,或者不出现;并且尽可能多地匹配
pattern.times(2, 4).optional().greedy();
// 匹配事件出现 1 次或多次
pattern.oneOrMore();
// 匹配事件出现 1 次或多次,并且尽可能多地匹配
pattern.oneOrMore().greedy();
// 匹配事件出现 1 次或多次,或者不出现
pattern.oneOrMore().optional();
// 匹配事件出现 1 次或多次,或者不出现;并且尽可能多地匹配
pattern.oneOrMore().optional().greedy();
// 匹配事件出现 2 次或多次
pattern.timesOrMore(2);
// 匹配事件出现 2 次或多次,并且尽可能多地匹配
pattern.timesOrMore(2).greedy();
// 匹配事件出现 2 次或多次,或者不出现
pattern.timesOrMore(2).optional()
// 匹配事件出现 2 次或多次,或者不出现;并且尽可能多地匹配
pattern.timesOrMore(2).optional().greedy();条件
简单条件(Simple Conditions)
pattern.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return value.user.startsWith("A");
}
});迭代条件(Iterative Conditions)
middle.oneOrMore()
.where(new IterativeCondition<Event>() {
@Override
public boolean filter(Event value, Context<Event> ctx) throws Exception {
// 事件中的 user 必须以 A 开头
if (!value.user.startsWith("A")) {
return false;
}
int sum = value.amount;
// 获取当前模式之前已经匹配的事件,求所有事件 amount 之和
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.amount;
}
// 在总数量小于 100 时,当前事件满足匹配规则,可以匹配成功
return sum < 100;
}
});终止条件(Stop Conditions)
对于循环模式而言,还可以指定一个“终止条件”(Stop Condition),表示遇到某个特定事 件时当前模式就不再继续循环匹配了。 终 止 条 件 的 定 义 是 通 过 调 用 模 式 对 象 的 .until() 方 法 来 实 现 的 , 同 样 传 入 一 个 IterativeCondition 作为参数。需要注意的是,终止条件只与 oneOrMore() 或 者 oneOrMore().optional()结合使用。因为在这种循环模式下,我们不知道后面还有没有事件可以 匹配,只好把之前匹配的事件作为状态缓存起来继续等待,这等待无穷无尽;如果一直等下去, 缓存的状态越来越多,最终会耗尽内存。所以这种循环模式必须有个终点,当.until()指定的条 件满足时,循环终止,这样就可以清空状态释放内存了。
组合模式
一个组合模式有以下形式:
Pattern<Event, ?> pattern = Pattern
.<Event>begin("start").where(...)
.next("next").where(...)
.followedBy("follow").where(...)
...近邻条件(Contiguity Conditions)
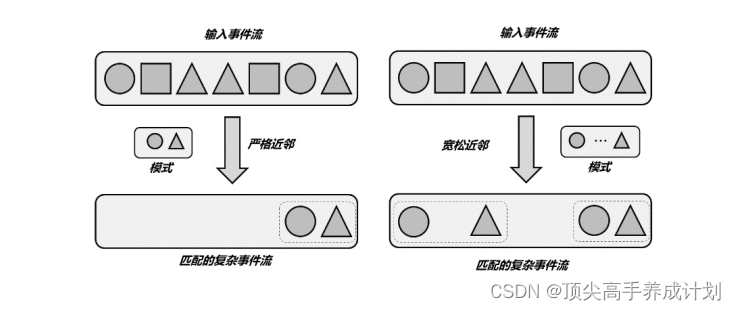
Flink CEP 中提供了三种近邻关系:⚫ 严格近邻( Strict Contiguity )匹配的事件严格地按顺序一个接一个出现,中间不会有任何其他事件。代码中对应的就是 Pattern 的 .next() 方法,名称上就能看出来,“下一个”自然就是紧挨着的。⚫ 宽松近邻( Relaxed Contiguity )宽松近邻只关心事件发生的顺序,而放宽了对匹配事件的“距离”要求,也就是说两个匹配的事件之间可以有其他不匹配的事件出现。代码中对应 .followedBy() 方法,很明显这表示“跟在后面”就可以,不需要紧紧相邻。
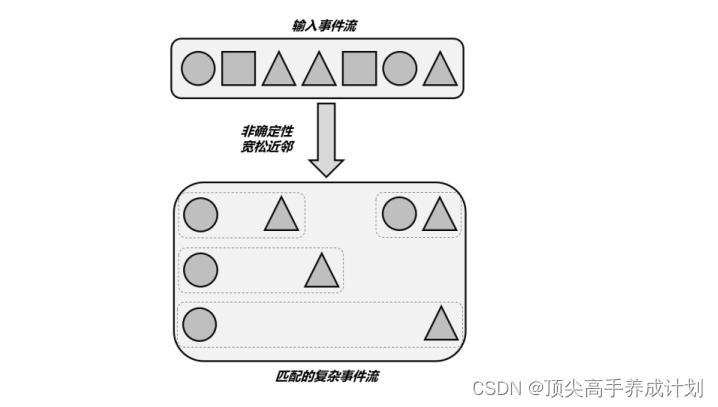
⚫ 非确定性宽松近邻( Non-Deterministic Relaxed Contiguity )这种近邻关系更加宽松。所谓“非确定性”是指可以重复使用之前已经匹配过的事件;这种近邻条件下匹配到的不同复杂事件,可以以同一个事件作为开始,所以匹配结果一般会比宽代码中对应 .followedByAny() 方法。
// 严格近邻条件
Pattern<Event, ?> strict = start.next("middle").where(...);
// 宽松近邻条件
Pattern<Event, ?> relaxed = start.followedBy("middle").where(...);
// 非确定性宽松近邻条件
Pattern<Event, ?> nonDetermin =
start.followedByAny("middle").where(...);
// 不能严格近邻条件
Pattern<Event, ?> strictNot = start.notNext("not").where(...);
// 不能宽松近邻条件
Pattern<Event, ?> relaxedNot = start.notFollowedBy("not").where(...);
// 时间限制条件
middle.within(Time.seconds(10));模式组
// 以模式序列作为初始模式
Pattern<Event, ?> start = Pattern.begin(
Pattern.<Event>begin("start_start").where(...)
.followedBy("start_middle").where(...)
);
// 在 start 后定义严格近邻的模式序列,并重复匹配两次
Pattern<Event, ?> strict = start.next(
Pattern.<Event>begin("next_start").where(...)
.followedBy("next_middle").where(...)
).times(2);
// 在 start 后定义宽松近邻的模式序列,并重复匹配一次或多次
Pattern<Event, ?> relaxed = start.followedBy(
Pattern.<Event>begin("followedby_start").where(...)
.followedBy("followedby_middle").where(...)
).oneOrMore();
//在 start 后定义非确定性宽松近邻的模式序列,可以匹配一次,也可以不匹配
Pattern<Event, ?> nonDeterminRelaxed = start.followedByAny(
Pattern.<Event>begin("followedbyany_start").where(...)
.followedBy("followedbyany_middle").where(...)
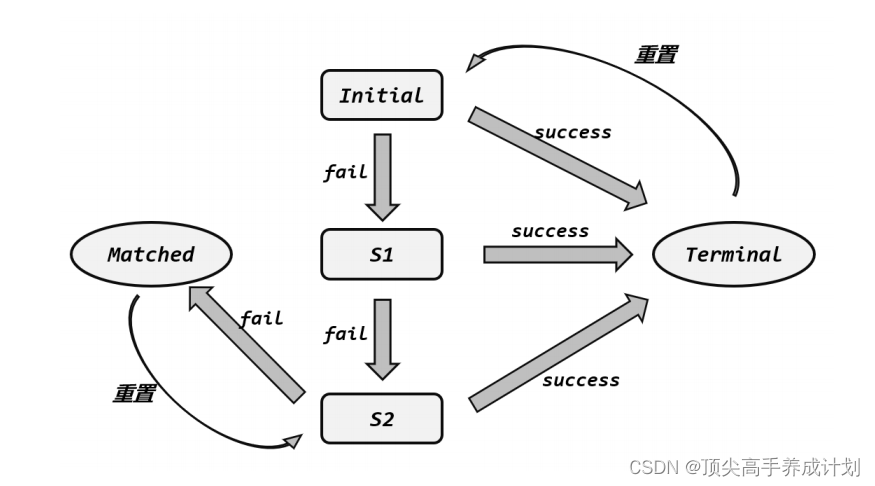
).optional();CEP的状态机实现
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











