






软工个人实践项目-文本词频统计
Github项目地址:
https://github.com/MercuialC/personal-project
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 620 | 1010 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 20 |
| · Coding | · 具体编码 | 180 | 210 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 600 |
| Reporting | 报告 | 160 | 155 |
| · Test Repor | · 测试报告 | 120 | 100 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 790 | 1175 |
代码组织:
031602501
|- src
|- WordCount.sln
|- WordCountUnitTest
|- WordCount
|- File.h
|- File.cpp
|- pch.cpp
|- pch.h
|- Problem.h
|- Problem.cpp
|- WordCount.cpp
|- WordCount.vcxproj解题思路:
刚看到作业的时候是有点熟悉的,正巧在这次作业发布的前几天,选修的现代搜索引擎技术及应用这门课也讲了一点关于文本词频搜索的内容。简单的来说这次作业的要求是给定文本输出其中字符总数、行数、“单词”总数及其中出现频率最高的十个并写入指定名称的文本中。对于这个要求,首先我决定采用C++实现,既然是读取文件,那么在读文件的过程中解决字符总数和行数的统计应该是不难解决的,所以首先思考了如何解决统计“单词”总数以及其中出现频率最靠前的十个。这里需要存下每个“单词”及其出现的频率还需要比较其中出现频率最高的十个(有相同的按字典序输出)并将其写入文件,我首先想到的是数据结构这门课上学的有哪些适合于解决这样问题的,第一个想到的应该是堆排序,快排(省时间)、哈希起来存储。正巧打开博客园看到了以前的四则运算计算器让我想到了map这个结构,有着(key,value)这样的键值对正巧可以实现“单词”及对应出现频率的存储。频率高的前十个输出同频率按字典序输出,这点要求可能需要排列两次,查阅了资料发现map的key是按照升序排列的,所以就决定选择map来解决了。对于“单词”的划分,一般这类都是以空格为分割将单词分割出来,但是这里的“单词”另有要求,所以想到了正则表达式,但是后来又想到了另外精巧的方式。
综上,
刚开始的思路及查阅资料过程如下:
- 决定了用C++实现,首先查阅回顾了文件读写的函数方法
- 查找资料文本中内容读入有哪些函数(发现了getline和get)决定使用getline(按行读取写起来方便并且适合统计行数)(使用getline后遇到难题)
- 查阅关于map的资料,了解其结构、函数方法
- 分析如何划分“单词”(使用正则表达式)(后来使用其他方法)
- 分析如何排序“单词”频率(使用排序算法(堆排序、快排),vector存储前十个)
- 看要求有接口封装一开始还没想,先解决主要功能实现
设计实现过程:
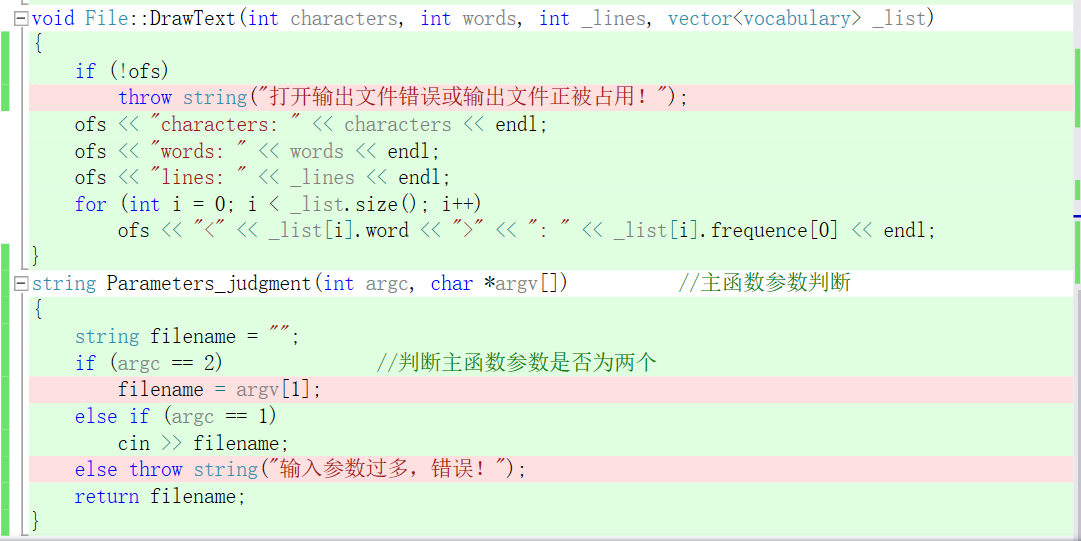
代码分多文件:其中共有两个类,文件读写类3个函数,计算核心类8个函数,他们之间的关系图如下图所示:
- 其中左边两个函数属于File.h(文件读写类)剩下的属于Problem.h(计算核心类)
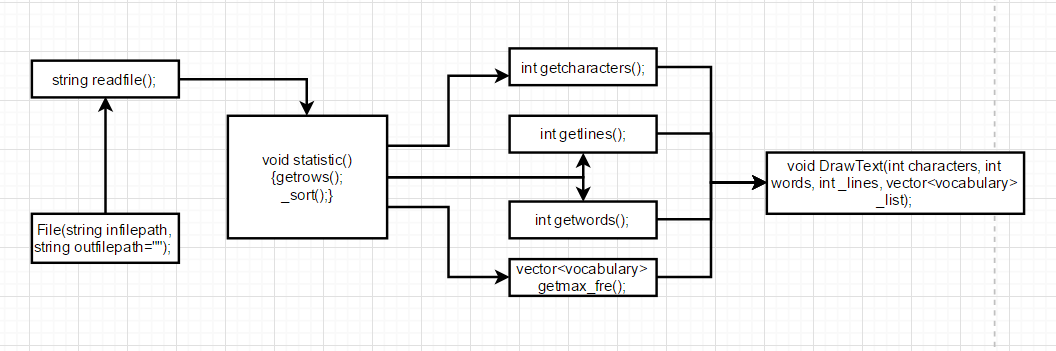
计算模块接口的设计与实现过程
文件读写类读出文本内容并将其传给计算模块进行计算。
计算模块遍历一遍文本内容将其中的各个值以接口供调用。
计算模块核心算法及其独到之处:
. 行划分算法: 首先将文件读写类传入的文本内容划分为行,以文本内容这个string的总长度(size)来设置循环并设置string型的变量作为行缓冲,以换行符为判断,但是这里要注意的是题目要求空白行不能算做一行,所以这里利用下面要说到的单词分割函数的返回值来判断是否为空行。但是在这里要注意行缓冲的清空:
- 遇到换行要将行缓冲变量送给单词分割函数进行单词分割及空白行判断
- 当跳出循环(遍历完所有的文本内容)也要调用单词分割函数
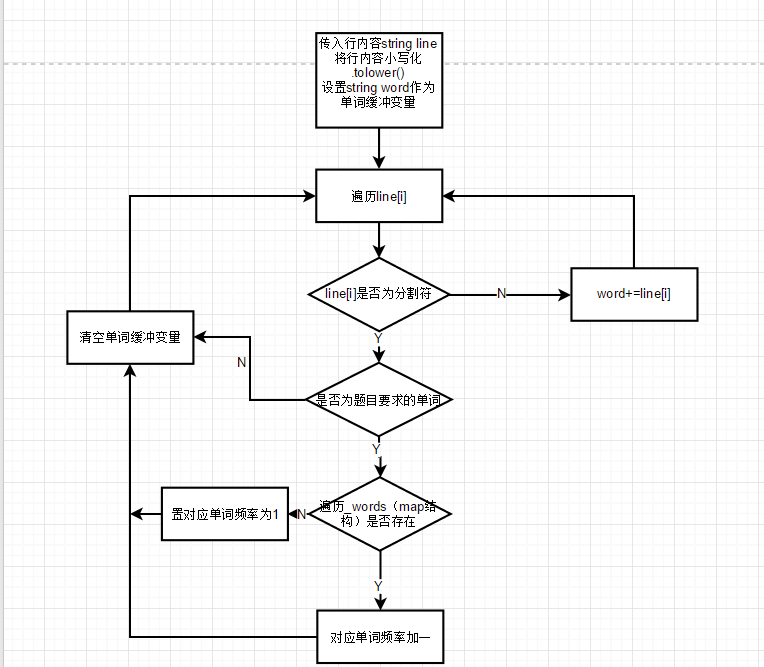
. 单词分割算法 :
单词分割算法调用了两个外部函数(判断是否为分割符;判断是否为字母),单词分割的算法是将行划分函数传入的每行的内容进行单词分割,返回值为本行是否为空白行。首先以传入行内容string的长度设置循环并设置string变量单词缓冲,遍历行内容,在遇到分割符(上述函数判断)将缓冲变量进行遍历判断。
- 题目要求不少于四个字母的为单词,并且不能以数字开头,这里很简单的思想是,只需要判断单词缓冲变量的前四个字符是否均为字母(上述函数判断),均为字母的则为单词。
- 空白行的判断也很简单,如果传入的行内容的遍历过程中出现一个非空字符(Ascill码大于空格的Ascill码(32))则为非空白行,返回值为1。
- 单词分割函数流程图如下:
. 词频排序算法:
单词及其频率的存储采用了map结构,单词的排序则需要对迭代器进行遍历,这里巧妙利用了题目中只输出频率最高的前十个,采用遍历十次输出频率最高的前十个。
就算法复杂度来看遍历十遍只要O(n)的算法复杂度,而快排堆排这样的算法也要O(nlogn)的算法复杂度,相对与来说这样是更优的。
独到之处:
- 和一开始的思路有很大的不同,并没有采用正则表达式和哈希存储的方法,因为对于题目要求单词的判断相对来说是简单的,可以很快地想到思路。而存储方面map为字典序升序排列,所以不需要进行相同频率按字典序输出这个判断。
在利用单词分割来判断一行是否为空白行。
- 在排序方面题目要求的数量级小,在大的文本内容量的情况下遍历十遍的算法复杂度想比于其他的排序算法是更优的。
- 排序后得到的频率最高的前十个单词及其对应频率的存储采用了结构体的vector容器来存储,这样代码的可扩展性更强,代码不仅适用于输出前十个还能调整。(改变传入参数(不输入则为默认参数10))
- 采用了一些函数默认参数的设置(例如上面那一点)方便测试及实际运行,增加代码可扩展性
避免了重复计算(计算核心自动调用无需手动调用)只需进行一次计算核心的调用(设置了used变量来判断这一点)
警告消除:

- 结构体中变量未初始化

性能分析:
计算模块接口部分的性能改进:
由于只跑一遍的main函数所得到的性能分析图不明显,所以这里讲main函数循环调用1000次得到下面的性能分析图:
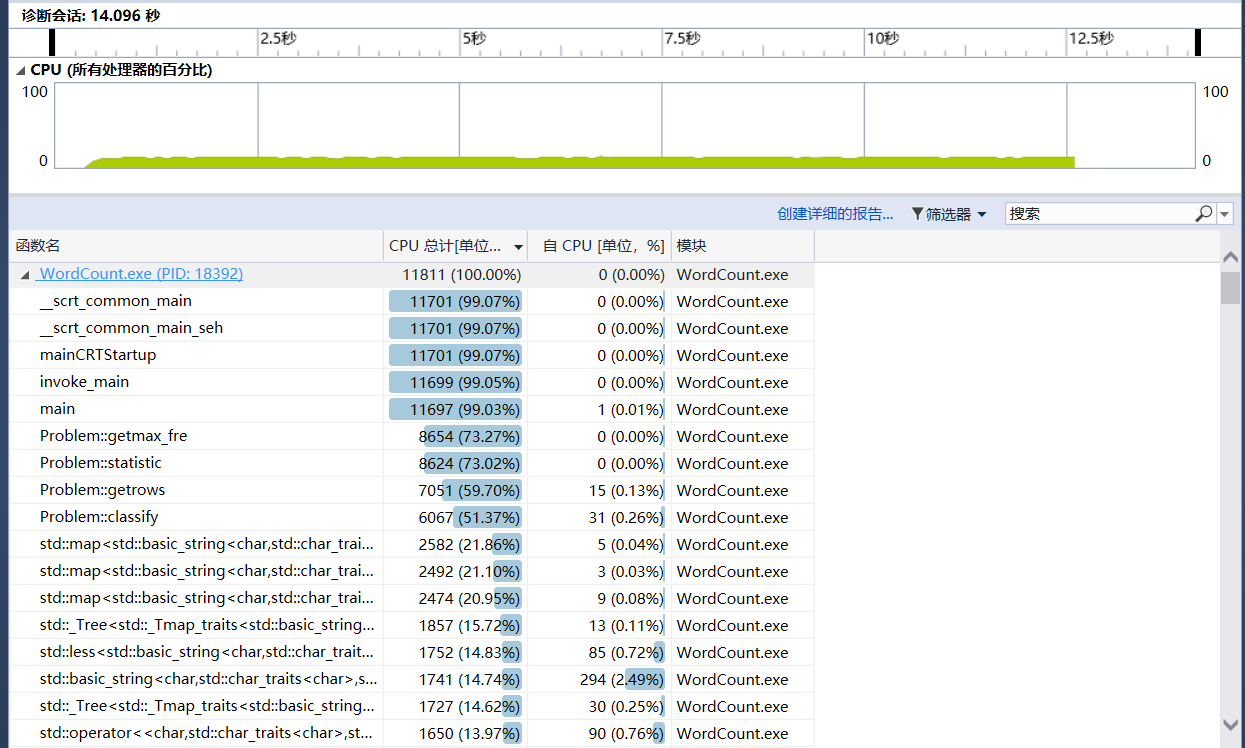
- 图片显示main函数消耗了很大一部分,返回频率最高的前十个单词也占用很大的时间,尝试着将一些输入输出改为c语言风格的scanf和printf性能得到一些优化,将文件读写的ifstream和ofstream改为c语言风格的fopen性能又有很大提升,消耗的时间降低了很多。其次vector的使用和结构体vector的使用改为数组性能也有提升,但是可拓展性下降了,所以不使用数组。还有一些小细节的优化之后。(函数传参用引用会更加快但是这里没有改)
vector<vocabulary> Problem::getmax_fre()
{
if (used == 1) return last_list;
else
{
statistic();
return last_list;
}
}
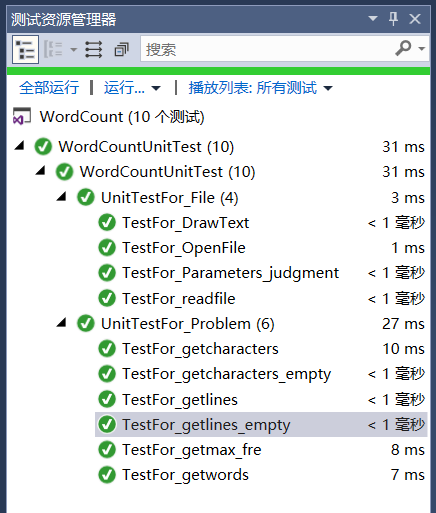
计算模块部分单元测试展示:
十个单元测试:(若要运行单元测试请以DebugX86形式运行)
- 说明:
| 传入(或输出)文件名 | 测试文件 | 测试函数 | 期待输出 |
|---|---|---|---|
| aaa.txt(不存在的文件名) | File.h | File::OpenFile() | 输入错误的文件名(异常处理) |
| empty.txt(传入)\//\//(输出) | File.h | File::DrawText() | 输出文件名错误(异常处理) |
| 无 | File.h | Parameters_judgment() | 主函数参数过多(异常处理) |
| input.txt | File.h | File::readfile() | 文本中的内容 |
| characters_empty_test.txt | Problem.h | File::getcharacters() | 正确统计文本中的Ascill码小于32的字符 |
| characters_test.txt | Problem.h | Problem::getcharacters() | 正确统计文本中的字符数(无空白字符) |
| words_test.txt | Problem.h | Problem::getwords() | 正确统计单词数 |
| lines_empty_test.txt | Problem.h | Problem::getlines_empty() | 正确统计空白行(不计入行数) |
| lines_test.txt | Problem.h | Problem::getlines() | 正确统计行数(不含空白行) |
| max_fre_test.txt | Problem.h | Problem::getmax_fre() | 正确输出频率最高的十个单词 |
- 截图:
测试覆盖率:
这里展示其中一个样例的结果(所有单元测试代码覆盖率是接近100%)



分析原因:代码覆盖率相对低的原因是一些异常处理的代码并没有被调用。另外不同的测试样例部分代码的代码覆盖率也会不同。(有些没有被调用(样例过于简单))
部分单元测试代码展示:
测试打开错误输出文件:
TEST_METHOD(TestFor_DrawText) //测试DrawText函数(打开错误的输出文件)异常处理
{
auto fun = [this]
{
vocabulary tem;
tem.frequence[0] = 1;
tem.word = "aa";
vector<vocabulary> test;
test.push_back(tem);
string inputfile = "empty.txt";
string outputfile = "\\//\\//";
File f(inputfile, outputfile);
f.OpenFile();
f.DrawText(1, 1, 1, test);
};
Assert::ExpectException<string>(fun);
}测试频率最高的十个单词(网上统计好的范例):
TEST_METHOD(TestFor_getmax_fre) //测试getmax_fre函数
{
string tmp[10] = { "image","crowd","dataset","proposed","with","arbitrary","density","mcnn","method","model" };
int num[10] = { 5,4,4,4,4,3,3,3,3,3 };
string filename = "max_fre_test.txt";
File f(filename);
f.OpenFile();
Problem p(f.readfile());
for (int i = 0; i < 10; i++)
{
vocabulary tem= p.getmax_fre()[i];
Assert::IsTrue(tem.word == tmp[i]&& tem.frequence[0] == num[i]);
}
}计算模块部分异常处理说明:
- 抛出异常:
string Parameters_judgment(int argc, char *argv[]) //主函数参数判断函数
{
string filename = "";
if (argc == 2) //判断主函数参数是否为两个
filename = argv[1];
else if (argc == 1)
cin >> filename;
else throw string("输入参数过多,错误!");
return filename;
}void File::OpenFile()
{
ifs.open(_infilepath.c_str(), ios::in);
if (!ifs)
throw string("读取输入文件错误!");
if (_outfilepath != "")
{
ofs.open(_outfilepath.c_str(), ios::out);
if (!ofs)
throw string("打开输出文件错误或输出文件正被占用!");
}
}- 捕获异常(异常处理)
try
{
string infilepath;
infilepath = Parameters_judgment(argc,argv);
File f(infilepath, "result.txt");
f.OpenFile();
Problem p(f.readfile());
f.DrawText(p.getcharacters(), p.getwords(), p.getlines(), p.getmax_fre());
} catch (string Err)
{
cout << Err << endl;
}- 对应单元测试:
TEST_METHOD(TestFor_OpenFile) //测试OpenFile函数(打开不存在的文件)异常处理
{
auto fun = [this]
{
string inputfile = "aaa.txt";
string outputfile = "result_test.txt";
File f(inputfile, outputfile);
f.OpenFile();
};
Assert::ExpectException<string>(fun);
}
TEST_METHOD(TestFor_DrawText) //测试DrawText函数(打开错误的输出文件)异常处理
{
auto fun = [this]
{
vocabulary tem;
tem.frequence[0] = 1;
tem.word = "aa";
vector<vocabulary> test;
test.push_back(tem);
string inputfile = "empty.txt";
string outputfile = "\\//\\//";
File f(inputfile, outputfile);
f.OpenFile();
f.DrawText(1, 1, 1, test);
};
Assert::ExpectException<string>(fun);
}
TEST_METHOD(TestFor_Parameters_judgment) //测试Parameters_judgment(主函数参数判断:参数过多)异常处理
{
auto fun = [this]
{
char **acgv = NULL;
Parameters_judgment(3, acgv);
};
Assert::ExpectException<string>(fun);
代码说明:
关键代码展示:
-关键算法函数:
int Problem::classify(string lines_buf)
{
int flag = 0;
string word;
int _length = lines_buf.length();
characters += _length;
for (int i = 0; i < _length; i++)
{
lines_buf[i] = tolower(lines_buf[i]); //同一变成小写字母
if (lines_buf[i] > ' ')flag = 1; //判断是否为空字符
if (_ischar(lines_buf[i]) == false)
{
if (_nonumber(word[0]) == true && _nonumber(word[1]) == true && _nonumber(word[2]) == true && _nonumber(word[3]) == true)
//判断前四位是否为字母(该单词是否为单词)
{
if (_word.find(word) == _word.end()) //查找单词是否出现过
_word[word] = 1;
else _word[word]++; //对应单词频率加一
}
word = "";
}
else word += lines_buf[i];
}
if (_nonumber(word[0]) == true && _nonumber(word[1]) == true && _nonumber(word[2]) == true && _nonumber(word[3]) == true)
//判断前四位是否为字母(该单词是否为单词)
{
if (_word.find(word) == _word.end()) //查找单词是否出现过
_word[word] = 1;
else _word[word]++; //对应单词频率加一
}
return flag;
}
void Problem::getrows()
{
string line;
char a;
for (int i = 0; i < content.size(); i++)
{
a = content[i];
line += a;
if (a == '\n')
{
int flag = classify(line); //调用单词分割
if (flag != 0) lines++;
line = "";
}
}
int flag = classify(line);
if (flag != 0) lines++;
}
void Problem::_sort() //找出出现频率最高的前几个
{
int min_rage = min(_word.size(),rage); //可拓展性(改变输出范围)
for (int i = 0; i < min_rage; i++)
{
vocabulary tem;
for (auto my_Itr = _word.begin(); my_Itr != _word.end(); ++my_Itr)//遍历文本中出现的所有单词及其频率
{
if (my_Itr->second > tem.frequence[0])
{
tem.frequence[0] = my_Itr->second;
tem.word = my_Itr->first;
}
if (i == 0)
words += my_Itr->second;
}
_word[tem.word] = -1;
last_list.push_back(tem);
}
}
void Problem::statistic() //统计功能
{
getrows();
_sort();
used = 1;
}心得体会:
这次作业学到知识:
- 功能独立成模块进行接口封装
- map的结构及其函数
- 文件读写的函数及其参数和效率对比
- getline()函数默认以换行符为终止判断,会自动丢弃换行符,所以在一开始的采用getline()发生答案错误的时候改用了get()函数
- 巧合之下发现了函数参数的调用是从右往左的,因为我的代码中有这样的一个函数:
f.DrawText(p.getcharacters(), p.getwords(), p.getlines(), p.getmax_fre());
而我的计算核心只需执行一次并且不需要手动调用,所以在运行代码的过程中发现了这一点。结合函数默认参数的设置(默认值必须从右向左摆)就懂了。
- 单元测试的实现及其优势,《构建之法》这本书里解释了什么才算好的单元测试,“单元测试应该准确、快速地保证程序基本模块的正确性”“单元测试要从系统中的最基本的功能点(由一个类及其方法实现),而单元测试则要测试API中的每一个方法及每一个参数”,学会做单元测试,做好的单元测试,在今后的项目实现以及以后的工作中都是很关键的。
- 性能分析等等对于代码的优化
这次的作业是软工实践的第一个项目作业,并且是一次个人作业,总体对于这次作业的第一印象应该是规范性,对比于以往的很多编程作业,这次的作业显然花在代码封装,性能测试,单元测试等等方面的时间是占整个项目的很大一部分的,完成功能并且输出题目要求的内容相对来说只是一小部分。这次的项目更能锻炼对于代码的测试和优化能力。其次很重要的一点就是规划设计和实现的过程,这次是第一次接触到PSP表格这个东西,相对比与以前的很多作业(埋头打代码)整个过程都是很乱的,缺乏条理性,往往就会出现很多的bug又在解决这些问题上花了不少,测试优化方面又不好做。所以落实计划开发报告各个环节对于一份好的工程项目是至关重要的。
对于测试和优化方面,《构建之法》这本书说的,“效能测试,分析,改进,再效能测试”代码的优化是需要循环进行的,不断地改进再测试才能做到更优。














 2572
2572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









