







简介
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]该函数用于将 RDD[K,V] 中每个K对应的V值,合并到一个集合 Iterable[V] 中,
参数numPartitions用于指定分区数;
参数partitioner用于指定分区函数;上手使用
scala> var rdd = sc.makeRDD(Array(('A',0),('A',2),('B',1),('C',4)))
rdd: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[4] at makeRDD at <console>:27
scala> rdd.groupByKey().collect
res2: Array[(Char, Iterable[Int])] = Array((A,CompactBuffer(0, 2)), (B,CompactBuffer(1)), (C,CompactBuffer(4)))原理图
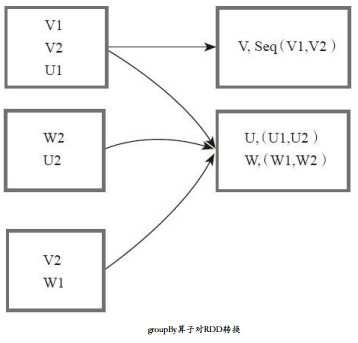
将元素通过函数生成相应的Key,数据就转化为Key-Value格式,之后将Key相同的元素分为一组。
图中,方框代表一个RDD分区,相同key的元素合并到一个组。 例如,V1,V2合并为一个Key-Value对,其中key为“ V” ,Value为“ V1,V2” ,形成V,Seq(V1,V2)。
源码
/**
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] =
groupBy[K](f, defaultPartitioner(this))
/**
* Return an RDD of grouped elements. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](f: T => K, numPartitions: Int)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] =
groupBy(f, new HashPartitioner(numPartitions))
/**
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*/
def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null)
: RDD[(K, Iterable[T])] = {
val cleanF = sc.clean(f)
this.map(t => (cleanF(t), t)).groupByKey(p)
}














 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









