






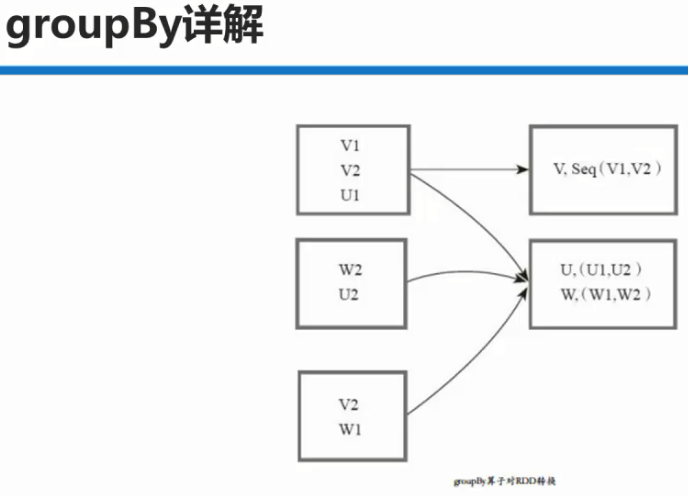
先对每个RDD中的数据进行分组,如:
V1,V2会分为一组, 形成K,依次类推。
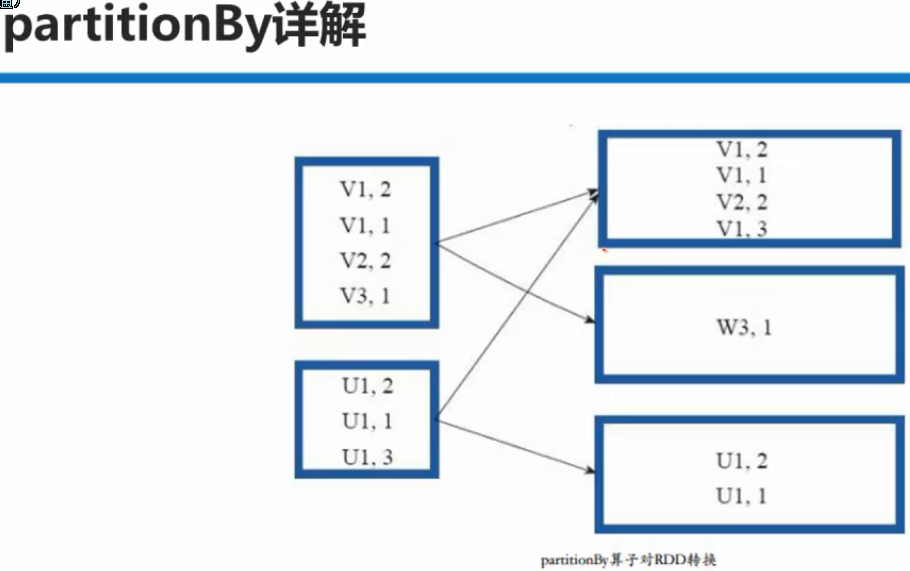
对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,
否则会生成ShuffleRDD.
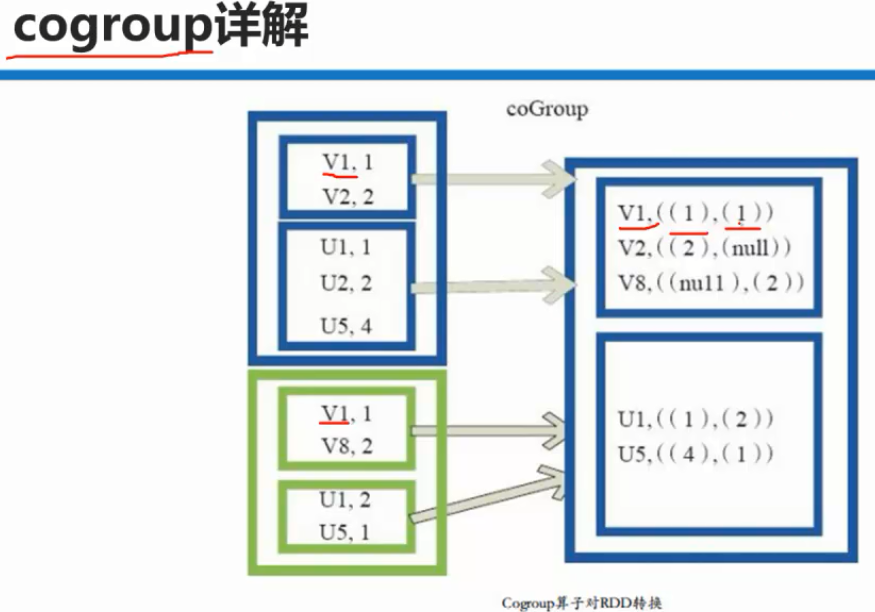
把相同K,后面的V合并成一个集合。
Spark RDD中Transformation的groupBy、partitionBy、cogroup详解

先对每个RDD中的数据进行分组,如:
V1,V2会分为一组, 形成K,依次类推。
对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,
否则会生成ShuffleRDD.
把相同K,后面的V合并成一个集合。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























