






函数
目录
什么是函数
维基百科上解释:在计算机科学中,子程序是一个大型程序中的某部分代码,由一个或者多个语句块组成。它负责完成某项特定的任务,而且相较于其他代码,具备相对的独立性。这个子程序,通常被称为函数。
通俗来讲,函数就是为了实现某些特定功能而被创建出来的独立子程序。
库函数
一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数,也就是编译器自带的函数,但是调用时,需要引用对应的头文件。
常见的库函数有这么几种:IO函数(输入输出函数)如:scanf、printf、getchar、putchar。
字符串函数 strcmp、strlen
字符操作函数 toupper(大小写转化函数)
内存操作函数(memcpy、memcmp、memset)
时间日期函数(time)
数学函数 如:sqrt(开平方)、pow(次方)
.............
自定义函数
顾名思义就是程序员自己定义的函数,而非编译器自带的函数。 有人可能要问了,既然编译器都自带了那么多库函数了,为什么我们还要自定义函数呢?这是因为很多情况下,库函数没法完全满足我们的需求,这时就要我们自己设计符合项目要求的函数。
自定义函数和库函数一样,也有函数名、返回类型和参数。
函数参数
函数参数有两种形式: 形式参数和实际参数。
我们先看一段代码来了解一下其中的差别
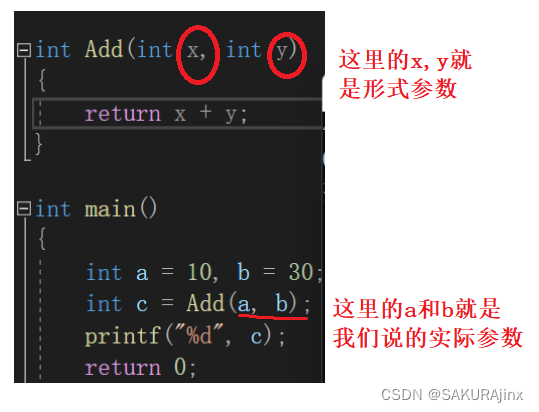
实际参数是在函数调用时的真实存在的参数,它可以是常量、变量、表达式、函数,但必须有确定的值。而形式参数可以理解为函数传参的过程中实参的一份临时拷贝,是“假的”。
下面一段代码会帮助你更好的理解。
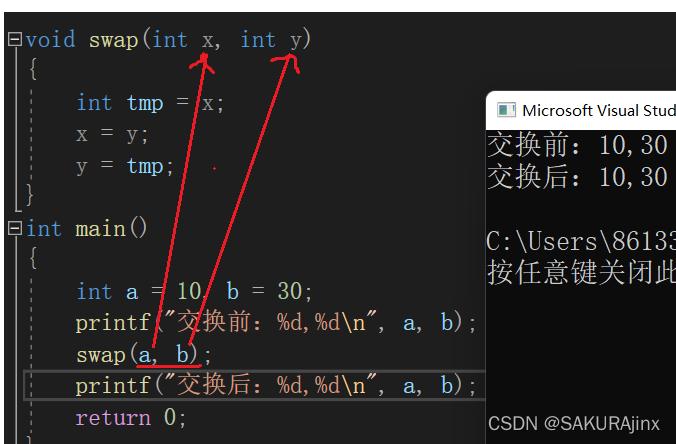
可以看到,我们定义了一个函数对a和b进行交换,但是结果并不像我们预料的一样。
调试一下来看看为什么:
我们在开始进入的时候打开监视窗口,找到要交换的a和b的地址
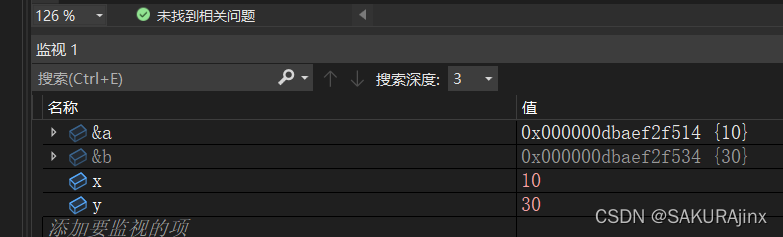
在进入swap函数至运行结束,我们看到a和b的地址完全没有变
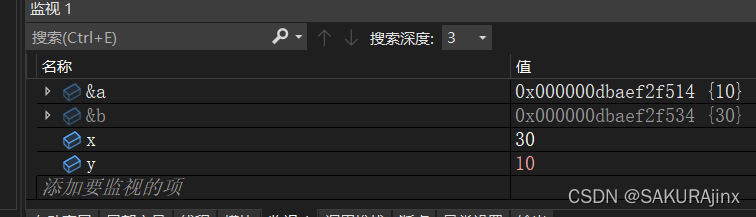
说明函数调用的时候,只传递了它的数值,而没有传过去地址,所以只是形参完成了交换,对外面的a和b没有一点影响。
举个例子来说,就像A教室和B教室里各有个苹果,你吃了A教室的半个苹果,这对B教室的没有丝毫影响,因为它们所处的空间、地址不同。
因此,上面一种函数调用叫传值调用,下面的叫传址调用。传值调用不会改变实参,而传址调用可以真正操纵外部函数。
那我们这里应该怎么办呢?肯定是要找到变量a和b的地址,然后将地址作为参数传过去。
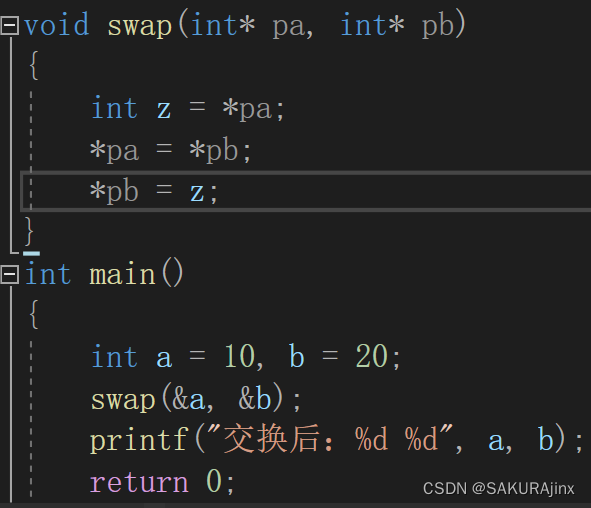
首先将a和b的地址传给swap函数,用指针变量pa,pb来接收。
注意:这里交换时不能直接写a和b,要对它们的地址解引用,写成*pa,*pb 。
不能直接交换地址,不能写成
int z=pa;
pa=pb;
pb=z;这对a和b没有任何影响,并且地址不是你想改就能改的,它在开辟内存的时候就固定在那了,不能轻易更改。
数组传参
数组传参传过去的是数组首元素的地址,不是整个数组的。
这点很多人都知道,但是不太清楚为什么,下面我来解释一下:
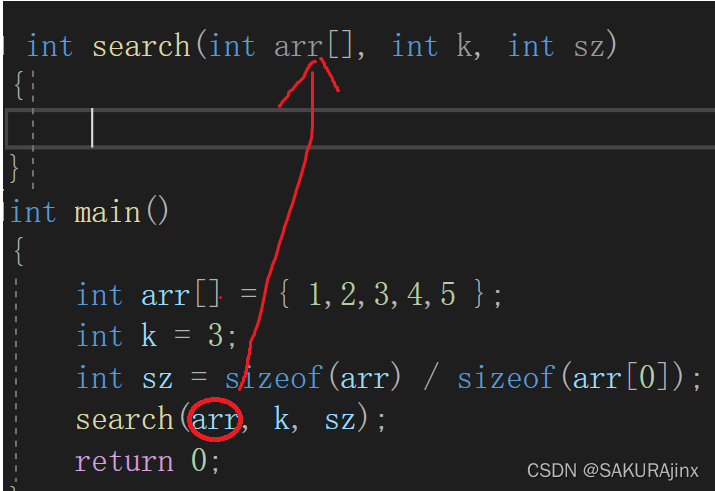
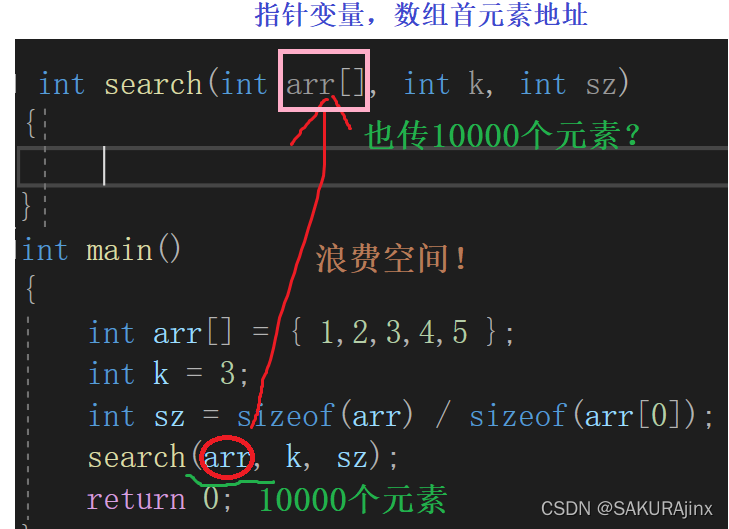
这里search函数具体内容就不写了,主要来看,我们在main函数里声明了search函数,要将arr数组传参过去,想象一下,如果我么这里的arr数组不是5个元素,而是10000个呢?
那我们也要将这10000个元素传过去,给它们开辟空间吗?这太浪费内存了,所以这里我们实际接收arr的是指针变量,也就是数组arr首元素地址,只要找到了arr首元素地址,后面用到时就可以回到arr数组处直接调用了。
函数调用
函数调用就是在main函数内部再调用一个函数。
如:
void test()
{
;
}
int main()
{
test();
return 0;
}为了更好地理解,我们来看几道简单的题目小试牛刀:
//题目1:打印100~200之间的素数
如果用我们之前讲过的循环法来做,就是:
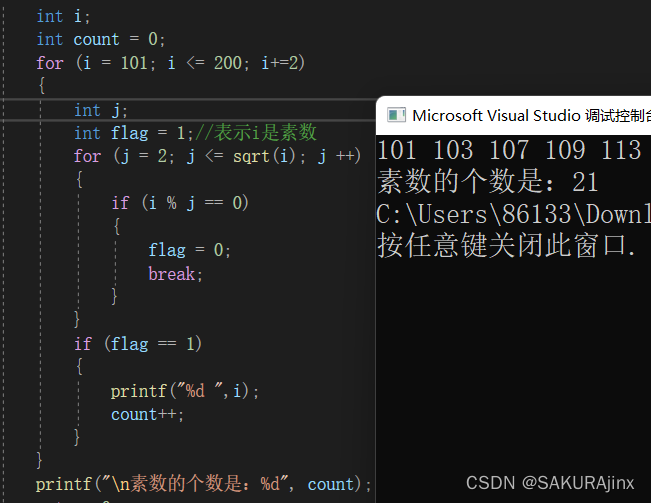
如果用我们今天讲的函数调用的方法,就可以改写成这种形式:

使用一个is_prime函数来查找素数,但其只负责找素数,打印等其他工作还是由main函数来完成。
所以我们说,一个函数的功能越单一越好,要做到 “高内聚低耦合 ” 。
//题目2:打印1000到2000之间的闰年
这道题我们直接使用函数调用的方法来做:
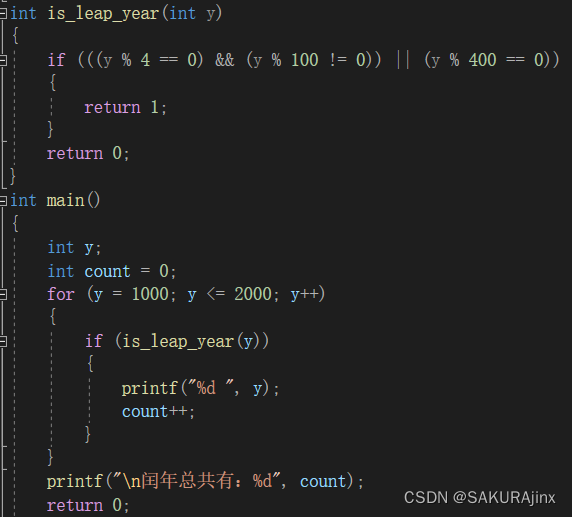
与上一题类似,也是创建一个is_leap_year函数查找闰年,功能单一、简洁。
这里说一下,有的同学会问break和return的差别,其实在这里,return的功能要远远强于break,break只能跳出一层循环、嵌套,而return直接代表了函数的结束,这里出现了return 1。return 0就说明函数结束了。
//题目3:调用一次num,num+1
写法1:
void Add(int* p)
{
(*p)++;
}
int main()
{
int num = 0;
Add(&num);
printf("%d\n", num);
Add(&num);
printf("%d\n", num);
return 0;
}要想改变变量num,就得找到它,就需要它的地址,将num的地址拿给Add函数,在内部让(*p)每次+1,这里不需要返回值,所以给void就行。
写法2:
int Add(int n)
{
return ++n;
//return n + 1;
}
int main()
{
int num = 0;
num=Add(num);
printf("%d\n", num);
num=Add(num);
printf("%d\n", num);
return 0;
}这种写法与上一种不同,是传值调用,每次在main函数内部用num接收Add函数的值。因此这里需要返回值,需要注意的是,这里return ++n,不能写成n++,因为n++是先使用后++,n的值没有发生改变,所以要先++再使用,也就是++n。
//题目4:二分查找
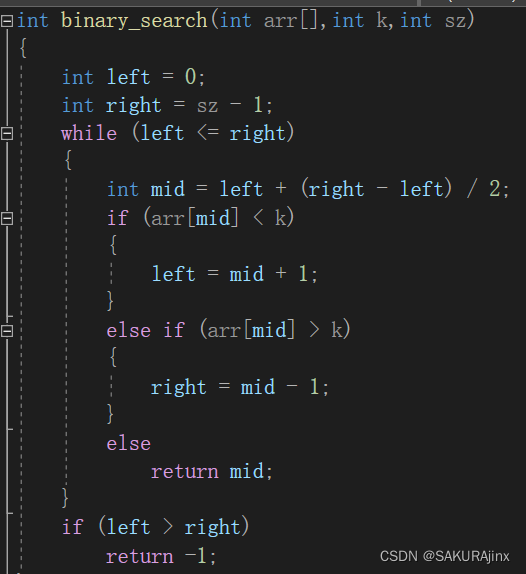
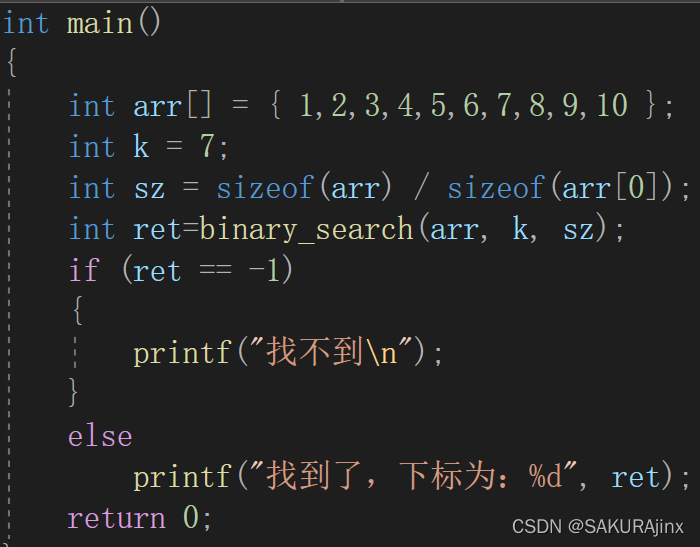
函数的嵌套调用和链式访问
嵌套调用
嵌套调用就是在函数调用的基础上多了层嵌套,就像循环嵌套一样,这里简单举个例子:

首先在main函数里调用了three_line函数,然后在three_line函数中又调用了new_line 函数。
这就是函数的嵌套调用,可以有多层嵌套。
这里要注意,函数可以嵌套调用,但是不能嵌套定义。
如:
void test()
{
int Add(int x, int y)
{
return x + y;
}
}
int main()
{
test();
return 0;
}类似这种,在test函数定义中,又嵌套定义了Add函数,这是绝对不行的!
链式访问
什么是链式访问? 通俗来讲,就是将函数像链条一样串起来进行访问。看个例子能更好的帮助理解:
int main()
{
char arr[] = "1234";
printf("%zu", strlen(arr));
return 0;
}这里的strlen函数的返回值做了printf函数的参数,它们被串到了一起,这就是链式访问。
它依赖的是函数的返回值。
函数的声明和定义
我们要调用一个函数,那么首先得有这么个函数,就需要定义这个函数。
用到这个函数的时候,如果事先没有定义它的话,需要声明一下,告诉编译器这个函数的名字、返回类型和参数。
就好比,班上新来了一个同学,现在要安排大扫除,要调动他的话需要事先声明一下这个同学是新来的,是本班的,不然大家不认识就没法调用。
代码解释如下:

这是函数定义声明的两种情形,第一种是在前面定义后直接在main函数中调用;
第二种是先声明有Add函数,在main函数中调用,最后再进行定义。
这里要注意:函数的声明只是告诉编译器有这么个函数,但是具体存不存在它决定不了,还得由函数定义来决定。所以说,函数声明有可能发布一个假的声明,这种情况也是存在的。
函数的声明一般放在头文件中,这怎么理解呢?我们来看具体案例(还是以上述加法为例):
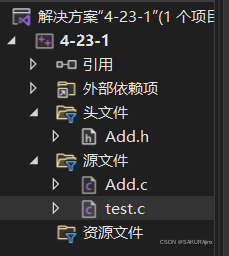
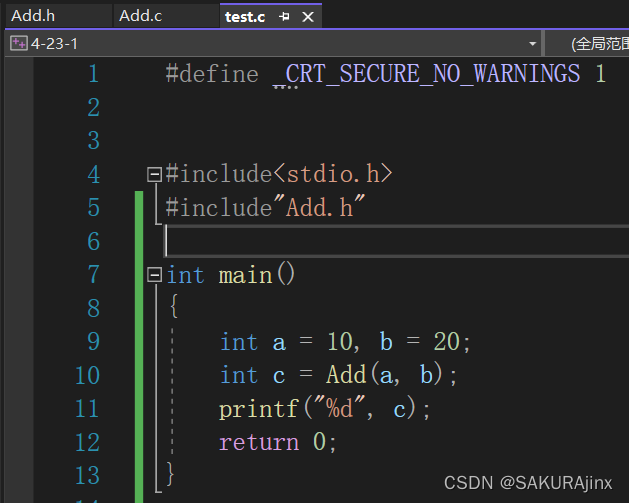
在工程项目里,我们创建两个源文件,一个是实现主函数的test.c文件,一个是实现加法Add函数的Add.c文件,当然,需要再创建一个头文件Add.h 。 我们把上述Add函数的声明放在头文件里,把函数定义放在Add.c中,具体运行则是在主函数里,这样一个加法模块就完成了。当想用时,包含一下头文件Add.h就行了。
这时可能有人就会问了,像刚才一样把函数的声明、定义和执行都放在一个文件里不就行了,为什么还分三个文件,不麻烦吗?
其实在初学C语言时,我们也许会觉得把所有东西都放一起会方便一些,但是在后面做项目或是进入公司团队协作时,如果都把代码放一个文件里面,那就乱套了。
你能想象一个500名程序员共同去写的程序,只用一个test.c文件,那谁写的bug也找不到,会乱成一锅粥,效率也极差。
所以我们写程序,都是分模块去写的,比如一个计算器,程序员A写 加法 程序,B写 减法 程序,C写 乘法 ,D写......
这样的话日后维护也方便,也容易找bug,总之就是清晰明了。
回到上面,所以说头文件的包含就是将头文件里面的东西拷贝到我们的 test.c中,也就是实现函数的声明。
函数递归
终于讲到递归了,网上不是流传着一句话嘛“人理解迭代,神理解递归 ” ,其实说的确实有些夸张了,不可否认,递归的思想是不太容易理解,但是只要我们多画图多思考,也不是不能实现。
由于篇幅问题,这里先简单说下递归是什么,关于递归详细的讲解和例题练习,我会放到后面的博客中与大家分享(包括大家熟知的汉诺塔等问题)
先来看一下递归的概念:

递归简单来说就是程序自己调用自己,本着大事化小的思维去解决问题。
具体来看一个例子:
例题1:接收一个整型值(正整数),按顺序打印它的每一位。
这边采用刚刚讲的递归的思想,大事化小:比如接收1234,要打印它的每一位1 2 3 4,我们可以看做是打印123的每一位和4,接着这种思路,打印12的每一位和3 4,再打印1的每一位和2 3 4 。
代码如下:

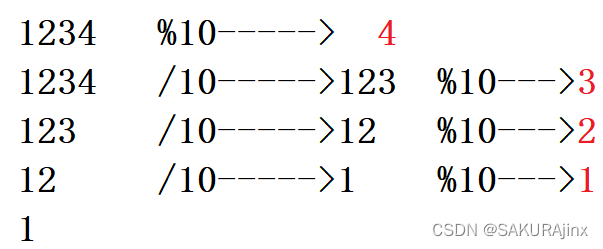
首先我们先封装一个print函数,将n的值传给它。
按照上面的思路,将1234拆分,最后是print(1)和2 3 4,到1的时候就不用拆了,所以这里输入的值如果是至少是两位数的话(n>9),先将其拆分print(n/10),拆分完了打印最后一位,也就是printf(n%10)

上面print(n/10)打印的是123的每一位,下面printf(n%10)打印最后一位4 。
然后打印123的每一位也是同样的操作,这边我们画图来看一下便于理解。
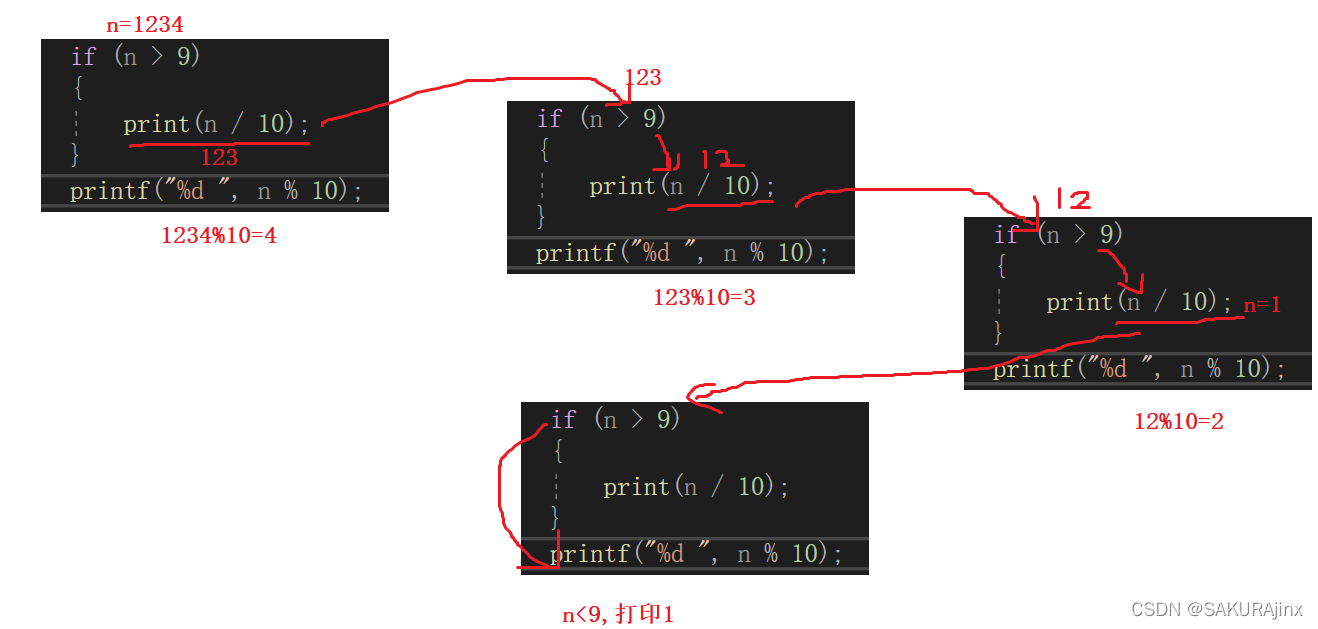
首先,n=1234进入print函数,>9执行 i f 语句,print(n/10),这时因为语句还没有执行完,所以不会执行下一条打印语句,而是print函数继续调用自身。
走到n=1时,<9执行下一条语句,打印n%10=1,这时print调用自身结束,要返回,从哪里来回哪里去,就回到
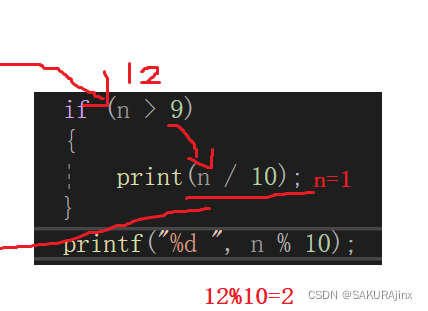 这里n进来是12, 12%10=2,打印2,再返回上一条语句,123%10=3......直到屏幕上将1234 每一位打印出来为止。
这里n进来是12, 12%10=2,打印2,再返回上一条语句,123%10=3......直到屏幕上将1234 每一位打印出来为止。
递归也是有条件的:

什么意思呢?我们还是以刚才的代码为例。
如果这里我们将 if 语句去掉:

我们会发现,递归一直在进行,因为没有了限制条件,递归就是死递归了,会一直进行下去。
同理,如果print(n/10)改为printf(n)也是一样的,它不会接近限制条件,就会死递归。
调试来看一下:
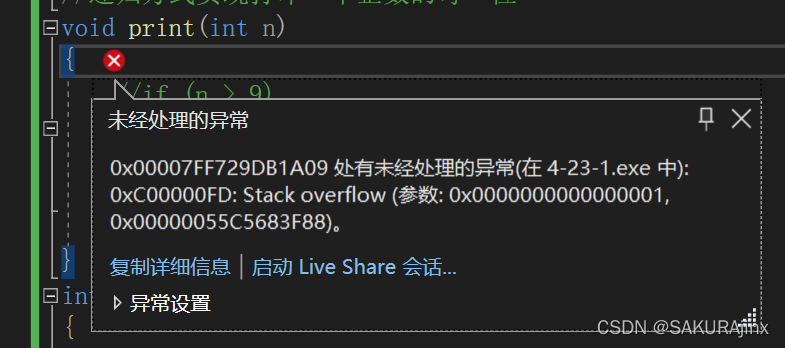
这里看到,出现了一个错误:Stack Overflow,栈溢出了,也就是说栈上的空间不够了,每次一递归都会在栈上申请开辟一块空间,如果空间被耗干了,也就会出现栈溢出的现象。
其他情形下递归的栈溢出
就算满足了递归的两个必要条件,也有可能会栈溢出,就是递归层次太多或太深时。
如:
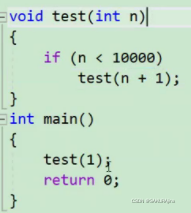
这边递归了10000次,那么层次太多太深,也会栈溢出。
例题2:编写函数不允许创建临时变量,求字符串长度
这道题的关键就在于不允许创建临时变量,因此使用变量count计数的方法就不行了,这边就需要用到递归的思想。
同样的,先进行分析,大事化小。假设有字符串“abcd”,首先看第一个字符,!='\0' ,就+1,此时字符串长度可以看做是1+str(“bcd”),str(“bcd”)同样的可以看成1+str(“cd”),最后str(“abcd”)可以拆成1+1+1+1+str(" "),大概就是这么个思路,接下来就是写成代码了。
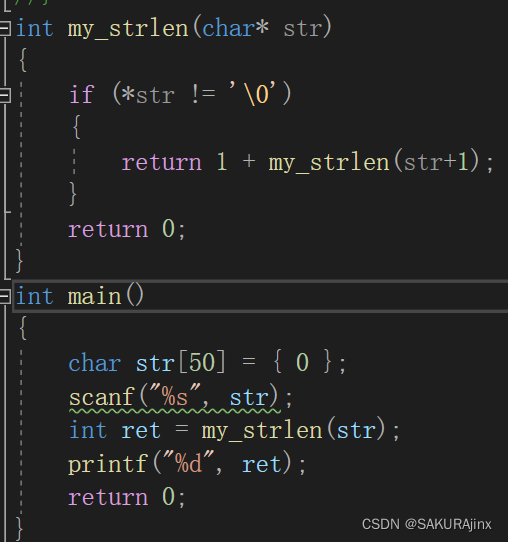
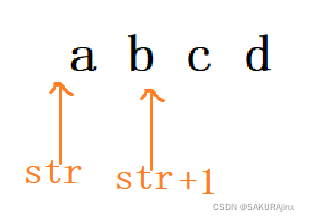
依据我们上面的分析,很容易就写出上面的代码。
这边需要注意的是:
1、判断字符是不是' \0 ' 时,要找到str指向的那个字符,所以解引用操作,找到对应的字符。
2、my_strlen(str+1) 中是跳过一个字符,所以是str+1 。 不能写成str++,否则str值不改变,建议也不要写成++str,会改变str的值。
这边我们也画个图来帮助大家理解吧:

递归与迭代
说到递归就不得不说一下迭代。 有人错误地把迭代就理解为循环,其实迭代不仅仅是循环。
我们写代码可以写成递归的方式,当然也可以写成迭代的形式,具体看场景而定。
比如阶乘问题中,就可以分别用这两种方式来写。
迭代法:
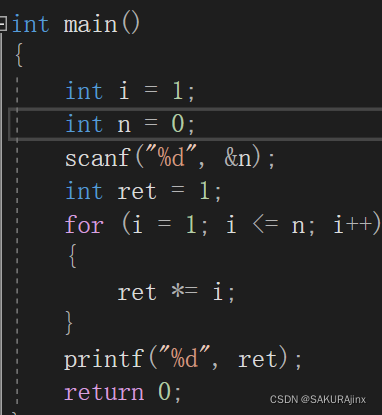
递归法:

其实这里的话,用迭代的方式要更为简单一些。
下面再来看斐波那契数列问题,这里将会向你揭示两者的区别
斐波那契数列:1,1,2,3,5,8,13,21,........ 求第n个斐波那契数。
观察数列,可以发现其规律:前两个数相加就是第三个数的值。
递归法:
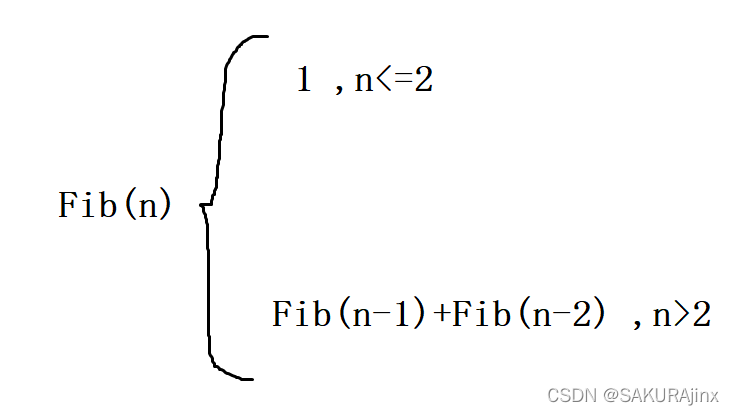
代码实现如下:
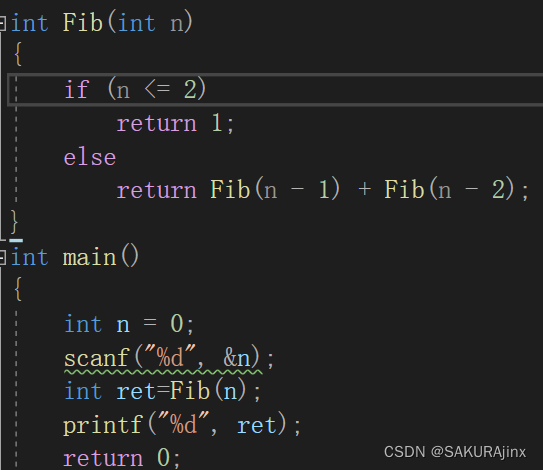
但是可以发现这里有个问题,我们要看第50个斐波那契数的值,ctrl+F5,发现:
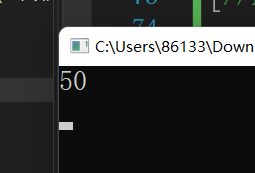
它一直在计算,算了很久都得不出结果,于是我们决定测一下在这个递归过程中第三个斐波那契数被调用了几次
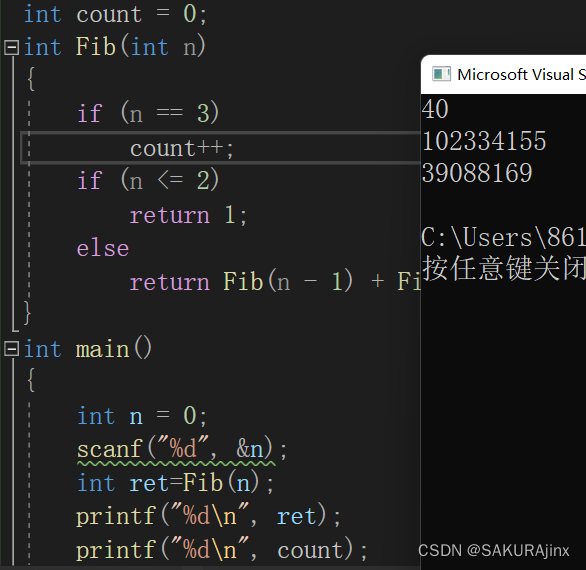
可以看到,算第40个斐波那契数时,第三个斐波那契数被调用了3900万次,这就是为什么运算会如此之慢的原因。
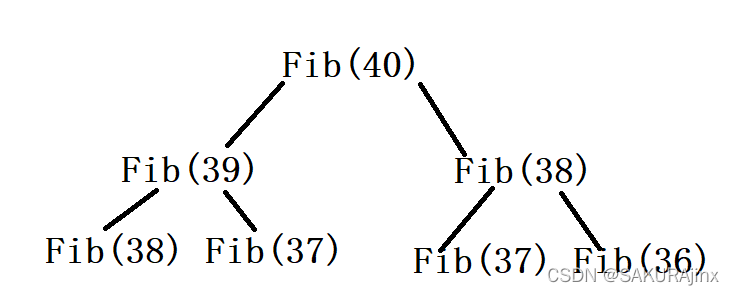
有点类似二叉树,这样一直向下延伸,越往下的数字调用的次数就越多。所以这种递归的方式运算量是非常大的。
迭代法:
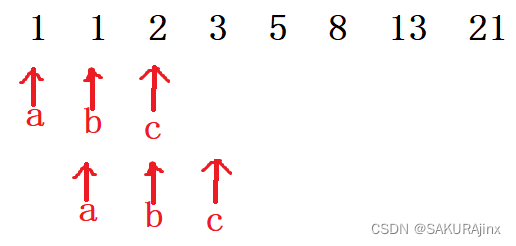
同样的,n<=2时,斐波那契数为1,n>2时,c=a+b。
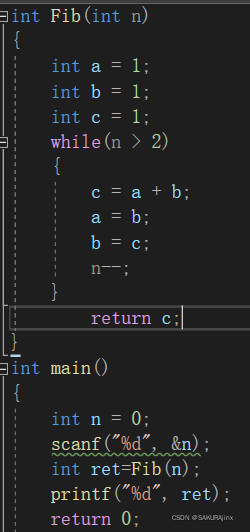
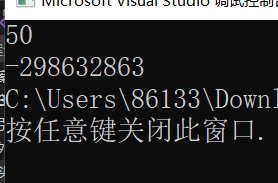
我们来看第50个斐波那契数:虽然结果超出整型范围了,但是它瞬间就算出来了,运行结果非常快。所以,在合适的场景下,迭代也是种很好的解题方法。
其实递归的内容还远不止于此,这里只是浅显的简单介绍一下,后续我还会专门写博客来讲解递归,感谢各位老铁的支持!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









