







转自http://blog.csdn.net/piaocoder/article/details/47836559
字典树
字典树,又称单词查找树,Trie树,是一种树形结构,哈希表的一个变种。用于统计,排序和保存大量的字符串(也可以保存其
的)。
优点就是利用公共的前缀来节约存储空间。在这举个简单的例子:比如说我们想储存3个单词,nyist、nyistacm、nyisttc。如果只是
单纯的按照以前的字符数组存储的思路来存储的话,那么我们需要定义三个字符串数组。但是如果我们用字典树的话,只需要定义
一个树就可以了。在这里我们就可以看到字典树的优势了。
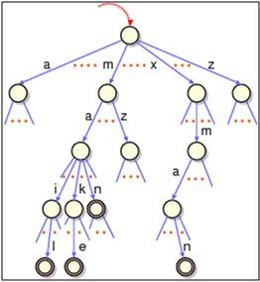
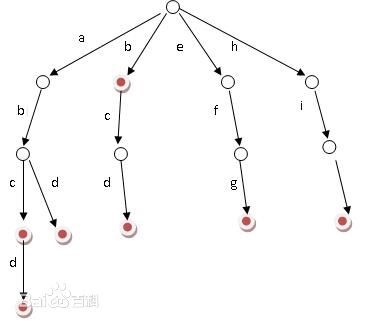
基本的操作
1.定义(即定义结点)
struct node{
int cnt;
struct node *next[26];
node(){
cnt=0;
memset(next,0,sizeof(next));
}
}; 据题意来确定。
cnt可以表示一个字典树到此有多少相同前缀的数目,这里根据需要应当学会自由变化。
2.插入(即建树过程)
构建Trie树的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则
创建对应的节点和边。比如要插入单词add(已经插入了单词“ad”),就有下面几步:
考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
<pre name="code" class="cpp">void buildtrie(char *s){
node *p = root;
node *tmp = NULL;
int l = strlen(s);
for(int i = 0; i < l; ++i){
if(p->next[s[i]-'a'] == NULL){
tmp = new node;
p->next[s[i]-'a'] = tmp;
}
p = p->next[s[i]-'a'];
p->cnt++;
}
}3.查找
(1)每次从根结点开始进行搜索;
(2)取要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3)在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索;
(4)迭代刚才过程。。。
(5)直到在某个结点处:
——关键词的所有字母都被取出,则读取附在该结点上的信息,即完成查找。
——该结点没有任何信息,则输出该关键词不在此字典树里。
void findtrie(char *s){
node *p = root;
int l = strlen(s);
for(int i = 0; i < l; ++i){
if(p->next[s[i]-'a'] == NULL){
printf("0\n");
return;
}
p = p->next[s[i]-'a'];
}
printf("%d\n",p->cnt);
}4.释放内存
有些题目,数据比较大,需要查询完之后释放内存(比如:hdu1671 Phone List)
递归释放内存
void del(node *root){
for(int i = 0; i < 10; ++i)
if(root->next[i])
del(root->next[i]);
delete(root);
}注意事项:
1.用G++交会出现Memory Limit Exceeded(就算释放了内存,还是Memory Limit Exceeded)
2.根结点要初始化root=new node;
练习:
hdu 1251 统计难题
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1251
解题思路:http://blog.csdn.net/piaocoder/article/details/41552691
hdu 2072 单词数
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2072
解题思路:http://blog.csdn.net/piaocoder/article/details/41902793
hdu 1671 Phone List
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1671
解题思路:http://blog.csdn.net/piaocoder/article/details/47951011
POJ 2001 Shortest Prefixes
题目链接:http://poj.org/problem?id=2001
解题思路:http://blog.csdn.net/piaocoder/article/details/47731321
POJ 2418 Hardwood Species
题目链接:http://poj.org/problem?id=2418
解题思路:http://blog.csdn.net/piaocoder/article/details/47731453
POJ 2503 Babelfish
题目链接:http://poj.org/problem?id=2503
解题思路:http://blog.csdn.net/piaocoder/article/details/47731701
| Time Limit: 10000MS | Memory Limit: 65536K | |
| Total Submissions: 23210 | Accepted: 9032 |
Description
America's temperate (温和的) climates produce forests with hundreds of hardwood species -- trees that share certain biological characteristics. Although oak, maple and cherry all are types of hardwood trees, for example, they are different species. Together, all the hardwood species represent 40 percent of the trees in the United States.
On the other hand, softwoods, or conifers (针叶树), from the Latin word meaning "cone-bearing," have needles. Widely available US softwoods include cedar, fir, hemlock (铁杉), pine, redwood, spruce (云杉) and cypress. In a home, the softwoods are used primarily as structural lumber such as 2x4s and 2x6s, with some limited decorative applications.
Using satellite imaging technology, the Department of Natural Resources has compiled an inventory of every tree standing on a particular day. You are to compute the total fraction of the tree population represented by each species.
Input
Output
Sample Input
Red Alder Ash Aspen Basswood Ash Beech Yellow Birch Ash Cherry Cottonwood Ash Cypress Red Elm Gum Hackberry White Oak Hickory Pecan Hard Maple White Oak Soft Maple Red Oak Red Oak White Oak Poplan Sassafras Sycamore Black Walnut Willow
Sample Output
Ash 13.7931 Aspen 3.4483 Basswood 3.4483 Beech 3.4483 Black Walnut 3.4483 Cherry 3.4483 Cottonwood 3.4483 Cypress 3.4483 Gum 3.4483 Hackberry 3.4483 Hard Maple 3.4483 Hickory 3.4483 Pecan 3.4483 Poplan 3.4483 Red Alder 3.4483 Red Elm 3.4483 Red Oak 6.8966 Sassafras 3.4483 Soft Maple 3.4483 Sycamore 3.4483 White Oak 10.3448 Willow 3.4483 Yellow Birch 3.4483
Hint
#include<stdio.h>
#include<string.h>
using namespace std;
struct node
{
int cnt;
struct node *next[130];
node()
{
cnt=0;
memset(next,0,sizeof(next));
}
};
struct node *root=NULL;
int n;
void build(char *s)
{
struct node *p=root,*tmp;
int i,len =strlen(s);
for(i=0;i<len;i++)
{
if(p->next[s[i]]==NULL)
{
tmp=new node;
p->next[s[i]]=tmp;
}
p=p->next[s[i]];
}
p->cnt++;
}
void dfs(struct node *root)
{
static int pos;
static char word[31];
int i;
if(root->cnt)
{
word[pos]='\0';
printf("%s %.4lf\n",word,root->cnt*100*1.0/n);
}
for(i=0;i<130;i++)
{
if(root->next[i])
{
word[pos++]=i;
dfs(root->next[i]);
pos--;
}
}
}
int main()
{
char str[31];
n=0;
root=new node;
while(gets(str)&&str[0]!='\0')
{
build(str);
n++;
}
dfs(root);
return 0;
}















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









