







 本文介绍了如何使用Python的Camelot库处理PDF文件中的单独一页和跨页表格,包括读取单页表格并保存为Excel,以及合并跨越多页的表格。展示了如何使用`read_pdf`函数和Pandas数据处理来提取和整理数据。
本文介绍了如何使用Python的Camelot库处理PDF文件中的单独一页和跨页表格,包括读取单页表格并保存为Excel,以及合并跨越多页的表格。展示了如何使用`read_pdf`函数和Pandas数据处理来提取和整理数据。
参考资料链接:Python解析pdf表格 | Camelot库(完胜) VS Pdfplumber库
一、表格在单独一页的情况
import camelot
pdf=r"C:\Users\ziyao\Desktop\python for work\办公\work1\2018年10月全国城市空气质量报告.pdf"
table=camelot.read_pdf(pdf, pages='11')
print(table)#查看该页的表格数量
print(table[0])#查看表格的规格
df=table[0].df#将提取出的数据转换为dataframe
df.to_excel('tables.xlsx')原文件的表格:
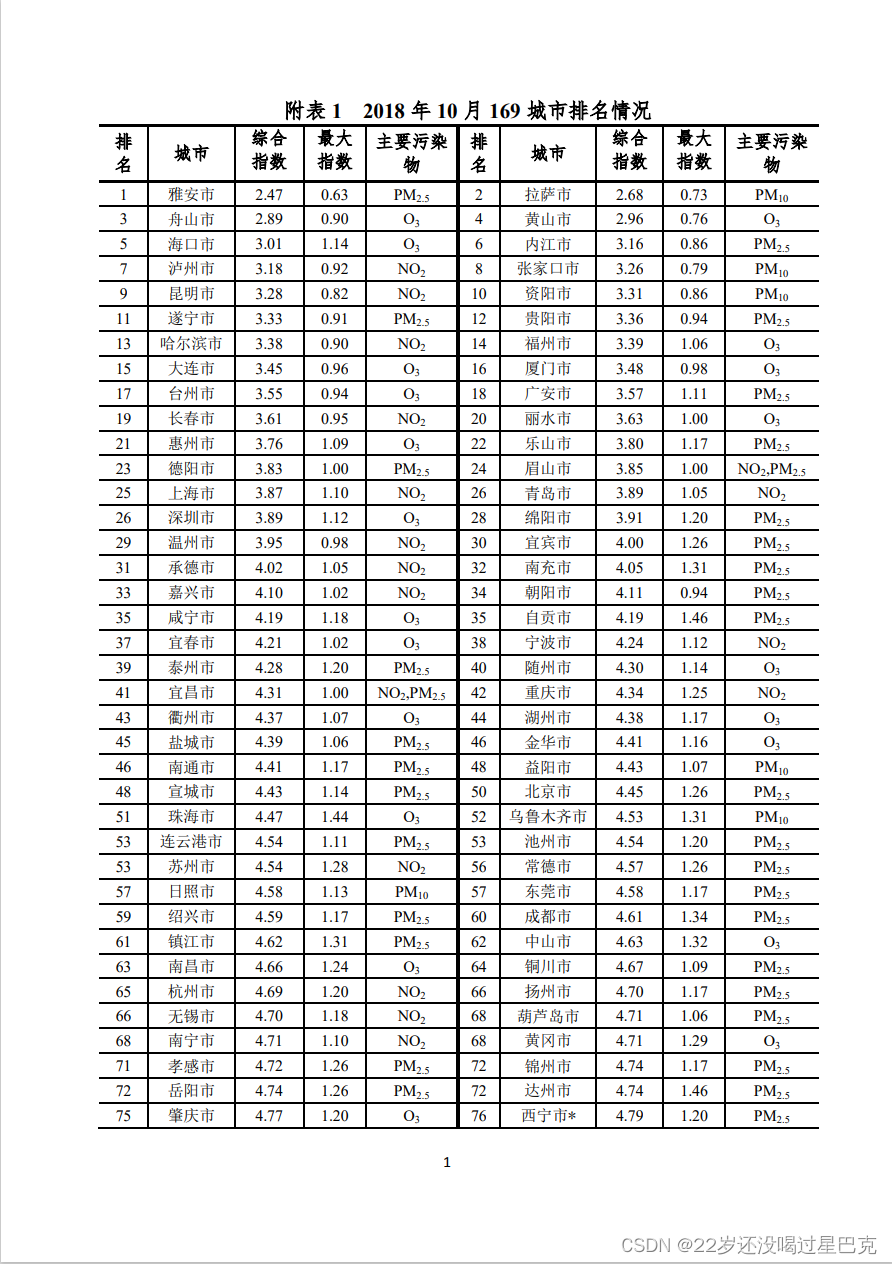
提取出来的Excel表格:
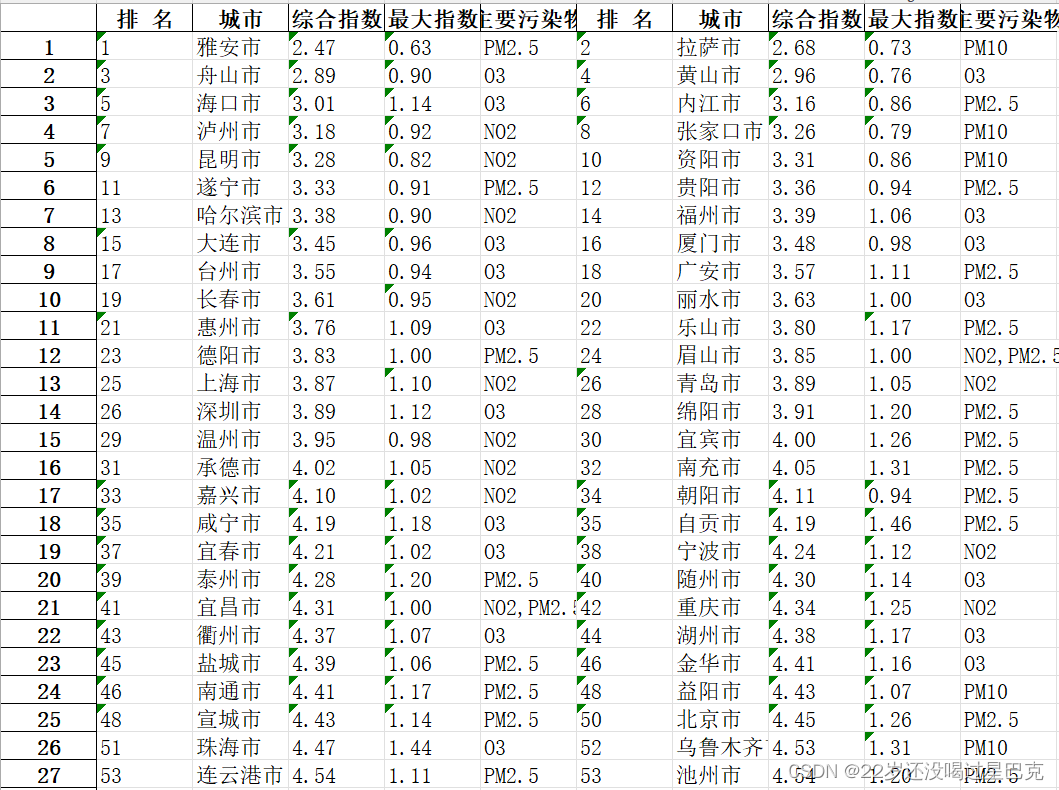
二、表格横跨多个不同页面
考虑到篇幅过长,所以不放原表格
import camelot
import pand 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4025
4025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









